[DL 15강] Object Detection
SPS LAB 2025.02.20 신입생 세미나 5주차
- 본 내용은 Michigan University의 Deep Learning for Computer Vision 15강 Object Detection 강의를 듣고 정리한 내용입니다.
- 강의의 원본은 해당 링크에서 확인하실 수 있습니다.
Computer Vison Tasks
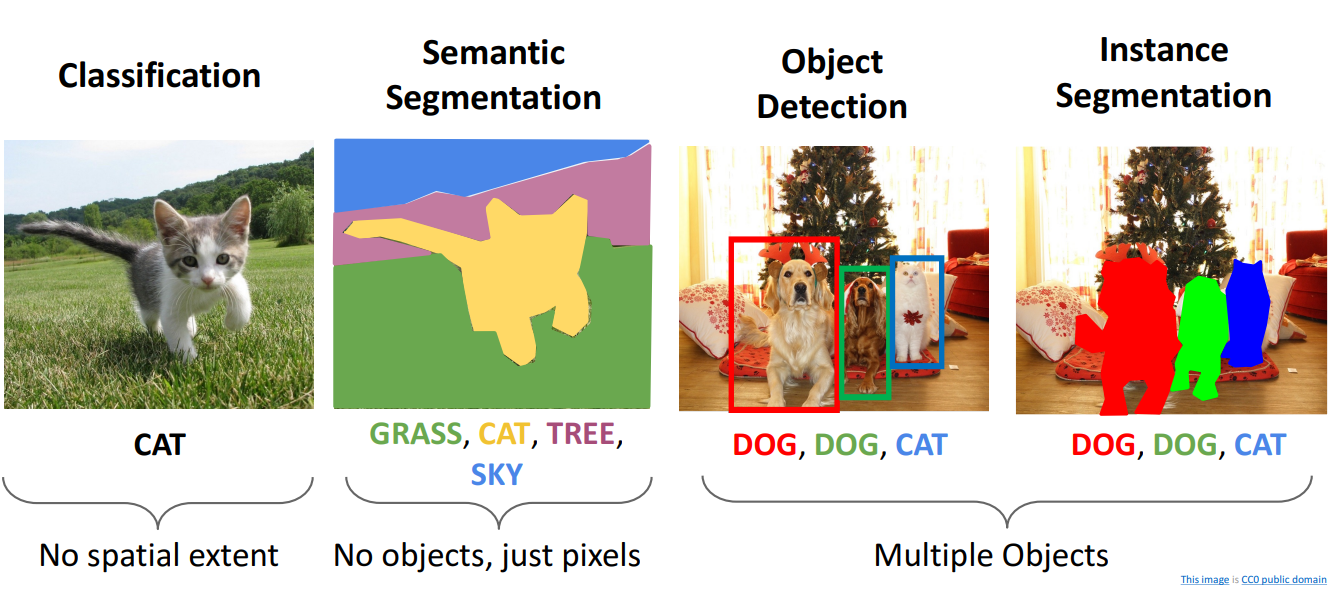
- Classification
- 단일 이미지에 단일 전체 레이블을 붙이는 것
- 이미지의 어떤 픽셀이 범주 레이블에 해당하는지 고려하지 않음
- Semantic Segmentation
- 이미지에 나타나는 다양한 범주로 이미지의 부분부분에 레이블을 지정하는 것
Object Detection

- Task Definition
- 단일 RGN 이미지를 입력으로 함
- 출력은 감지된 객체 세트가 되는 작업
- 객체의 범주를 제공하는 Category label (카테고리를 미리 지정)
- 해당 객체의 공간적 범위를 제공하는 Bounding Box (4개의 숫자: x, y, width, height)
- Challenges
- Multiple outputs
- Multiple types of output
- category label과 bounding box 2가지 다른 유형의 출력이 존재함
- Large images
- Classification은 비교적 낮은 해상도인 224x224에서도 가능 하지만, Object Detection은 800x600 등의 고해상도 이미지에서 작업해야 함
3. Detecting a single object
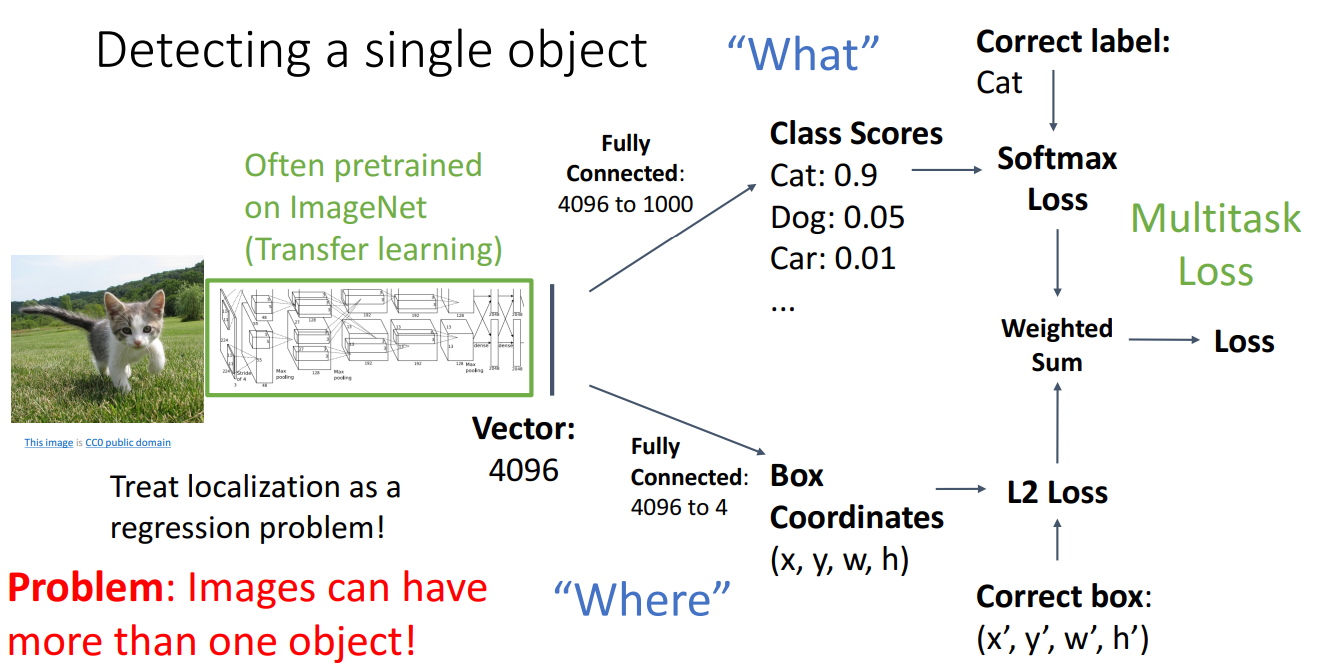
- 순서
- CNN을 거쳐서 벡터 표현을 생성함
- 벡터 표현을 가지고 이미지 분류를 수행하여 Category label 제공 (기존 하던 이미지 분류)
- Class score를 출력하고 실제 범주에 대한 SoftMax Loss로 학습
- 새로운 2번째 분기로, bounding box 좌표 제공
- 2개의 loss를 weighted sum하여 최종 손실을 제공
- 문제점
- 단일 객체만 감지한다면 합리적이지만, 감지해야 할 여러 객체가 존재하면 좋지 않음
4. Detecting Multiple Object

- 이미지당 다양한 개수의 output이 필요
ex) 개 1마리 = 4개의 숫자, 개 3마리 = 12개의 숫자
- 접근 방식 1: Sliding Window

- Possible position
- (W - w + 1) * (H - h + 1)
- Total possible boxes
- ∑h=1H∑w=1W(W−w+1)(H−h+1) = 2H(H+1)⋅2W(W+1)
ex) 800 x 600 image = 58M (5800만개) 서로 다른 경계 상자가 있다는 것으로, 이걸 전부 평가하는 건 무리
- 접근 방식 2: Region Proposals
- 이미지의 후보 영역 집합을 생성하는 방법
ex) 이미지에서 blob-like(얼룩 유형), 모서리, 다른 종류의 저수준 이미지 등을 찾아 객체일 확률이 높은 이미지 영역을 찾음
- Selective Search
- 매우 유명한 방법 중 하나로, CPU에서 처리하여 이미지당 약 2000개의 객체 제안을 제공
5. R-CNN: Region-Based CNN
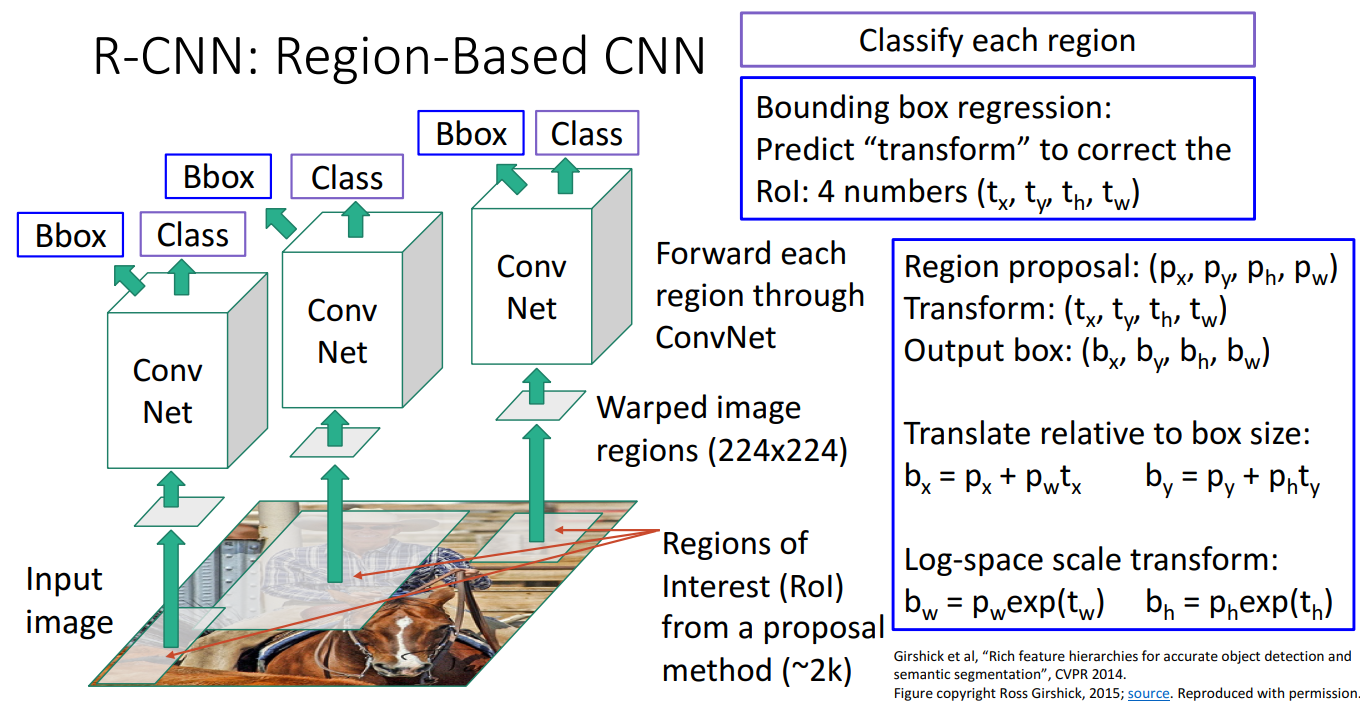
- 정의
- Object Detection을 위한 영역 기반 합성 신경망
- 순서
- 입력 이미지를 받고, Region Proposal method를 활용하여 Region of Interest(RoI)을 얻음
- 크기가 다른 RoI를 224x224 고정된 크기로 Warp시킴
- 워핑된 이미지 영역을 독립적으로 CNN에 입력
- CNN은 이러한 영역 각각에 대해 분류 점수 출력
- background 포함해서 c + 1 범주에 대한 분류 진행
- 문제
- region proposal로 얻은 영역이 이미지에서 감지하려는 객체와 정확히 일지하지 않는다면?
- Bounding Box Regression
- RoI의 위치와 크기를 조정하여 객체와 더욱 정확하게 일치하도록 보정
- CNN의 마지막 계층에서 4개의 보정값 (tx,ty,th,tw)를 예측 (해당 값은 CNNN이 학습한 Bounding Box Regression 값)
- 기존 Region Proposal의 좌표와 크기(px,py,ph,pw)가 주어졌을 때, 보정된 바운딩 박스(bx,by,bh,bw는 다음과 같이 계산
- 중심 좌표 조정
bx=px+pwtx, by=py+phty
- 크기 조정(Log-space scale transform)
bw=pWexp(tw), bh=phexp(th)
- Test Time

- Region Proposal 방법(Selective Search 등)을 사용하여 약 2000개의 후보 영역을 추출
- 각 Region Proposal을 224×224 크기로 변환하고, 변환된 Region을 CNN에 개별적으로 입력하여 클래스 점수 및 바운딩 박스 변환(Regression) 수행
- CNN이 예측한 클래스 점수(객체 여부)를 기준으로 일부 영역을 선택
- 배경인지 여부(Threshold)
- 카테고리별 선택
- 최상위 K개의 Region 선택
- 모델이 예측한 바운딩 박스와 실제 Ground-Truth 바운딩 박스를 비교하여 정확도 평가
6. Comparing Boxes: Intersection Over Union (IoU)

- 두 상자 간의 유사도를 평가하는 방법으로, 합집합 영역에 대한 교집합 비율로 계산
7. Overlapping Boxes: Non-Max Suppression (NMS)

- 객체 주변에 겹치는 bounding box를 출력할 때 겹치는 상자를 제거하기 위한 알고리즘
- 가장 분류 점수가 높은 box를 선택하고, 그 다음 확률이 높은 box와 비교했을 떄 IoU가 threshold(ex) 0.7)보다 크면 같은 객체에 대한 중복 box라고 판단하여 box 제거 (아 작업 반복)
- 많은 객체가 매우 겹쳐 있는 혼잡한 이미지의 경우, 중복 감지를 삭제하는 해당 알고리즘은 좋은 box도 삭제할 수 있음. 해당 문제에 대한 good solution이 현재 없음

8. Evaluating Object Detectors: Mean Average Precision (mAP)
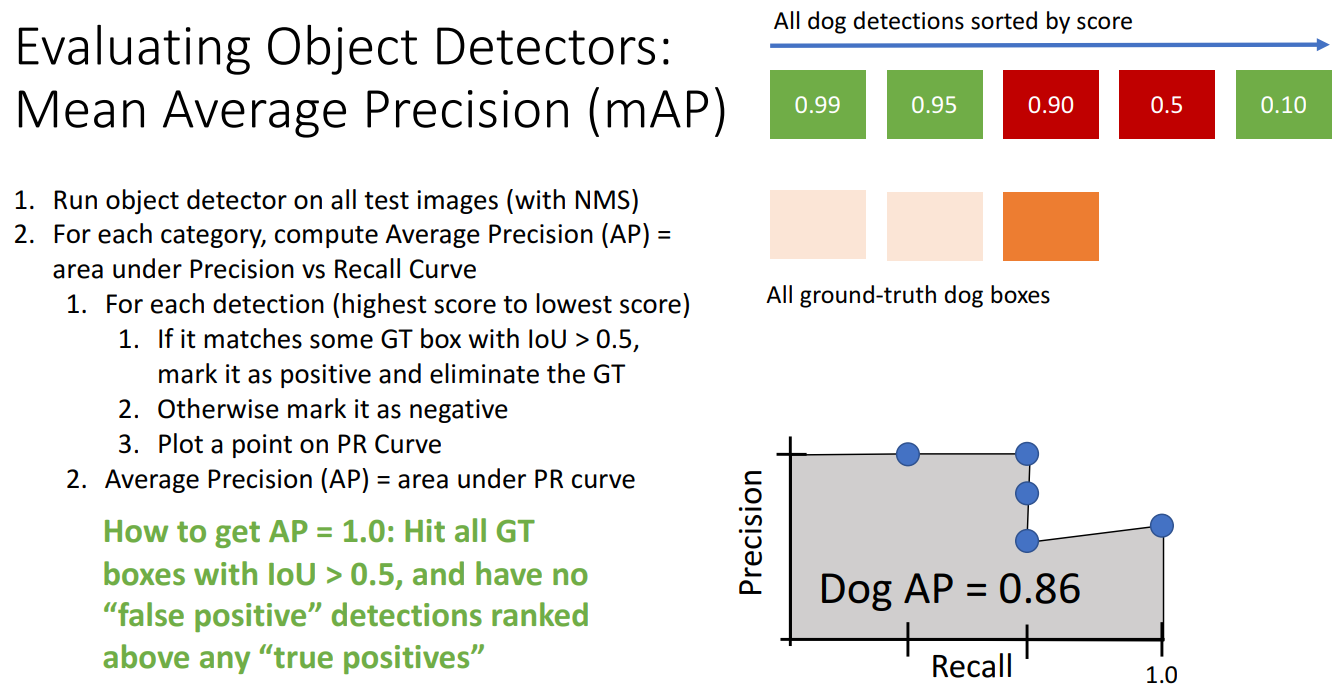
- 객체 탐지 모델의 성능을 평가하기 위해 사용되는 지표
- Precision-Recall 곡선 아래 면적(AUC, Area Under Curve)를 측정하여 Average Precision을 계산하고 여러 클래스에 대해 AP를 평균하여 mAP를 얻음
- 계산 방법
- 탐지된 객체를 Score 기준으로 내림차순 정렬
- 각 탐지 결과에 대해 다음 절차 수행
- 탐지 결과가 Ground Truth bounding box와 IoU(Intersection over Union) > 0.5이면 True Positive(TP)
- IoU <= 0.5이면 False Positive(FP)
- Precision-Recall Curve에 해당 점수(Precision, recall) 추가
- PR 곡선 아래 면적을 AP로 사용하고, 모든 클래스에 대해 AP를 평균하여 mAP 계산
- "COCO mAP"의 경우: 각 IoU 임계값(0.5, 0.55,..., 0.95)에 대해 mAP@thresh를 계산하고 평균을 구함
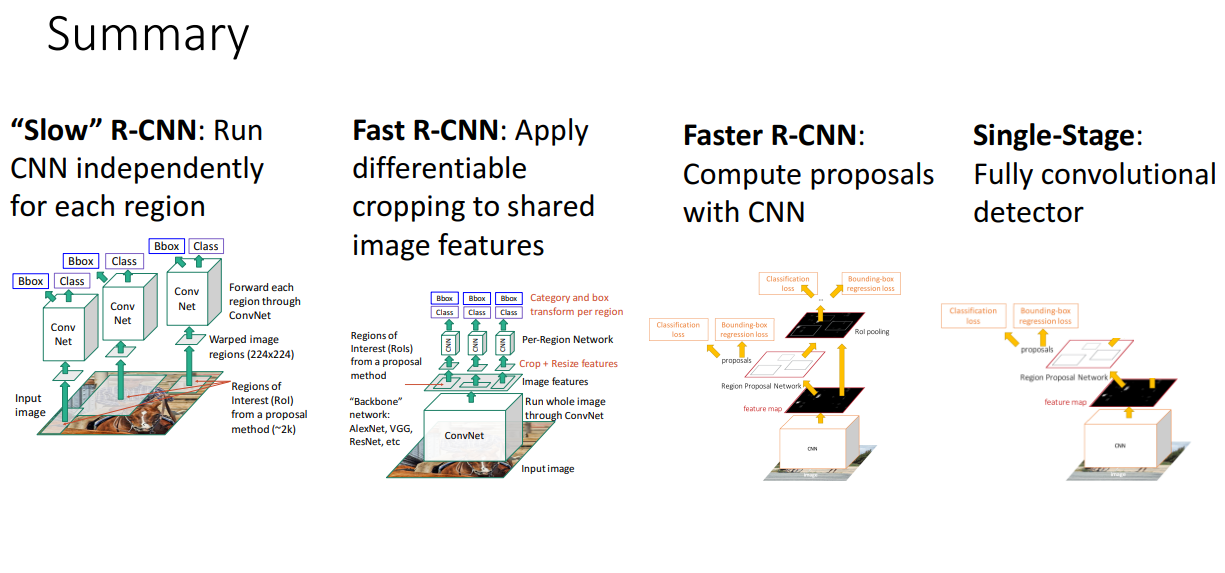
9. Fast R-CNN
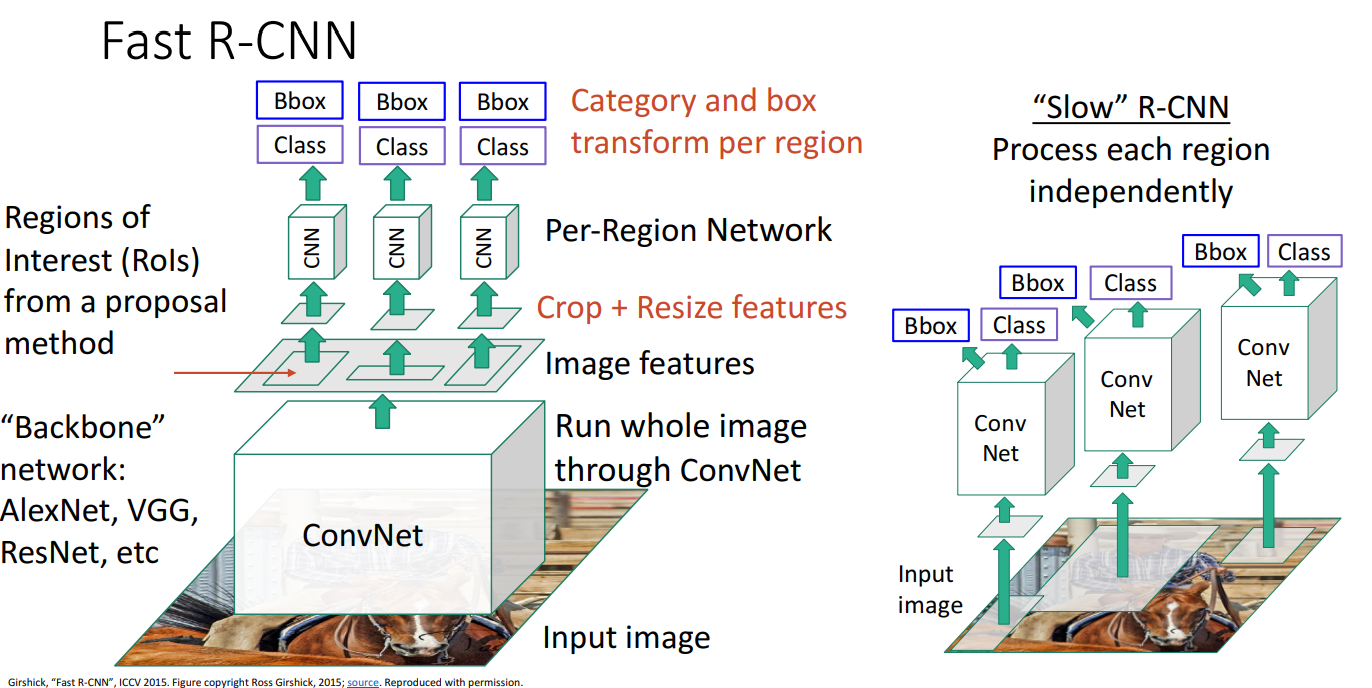
- Slow R-CNN의 문제점: 각 Region Proposal된 image에 대해 forward pass가 진행되어야 하므로 매우 느리다는 단점
- 해결책으로 Warping이 이루어지기 전에 CNN을 진행
- 순서
- 입력 이미지를 가져와 단일 합성 신경망(AlexNet, VGG, ResNet과 같은 Backbone network 사용)으로 전체 이미지를 고해상도로 처리하여 Feature map을 얻음
- 대부분의 계산이 해당 backbone network에서 수행됨
- Resion Proposal로 Regions of Interest(RoIs) 선택
- Feature map에서 해당 영역만 잘라 Crop + Resize
- 각 RoI에 Per-Region Network를 활용하여 클래스 예측 및 바운딩 박스 조정 수행
- Network가 상대적으로 가볍기 때문에 매우 빠름
10. Cropping Features: RoI Pool
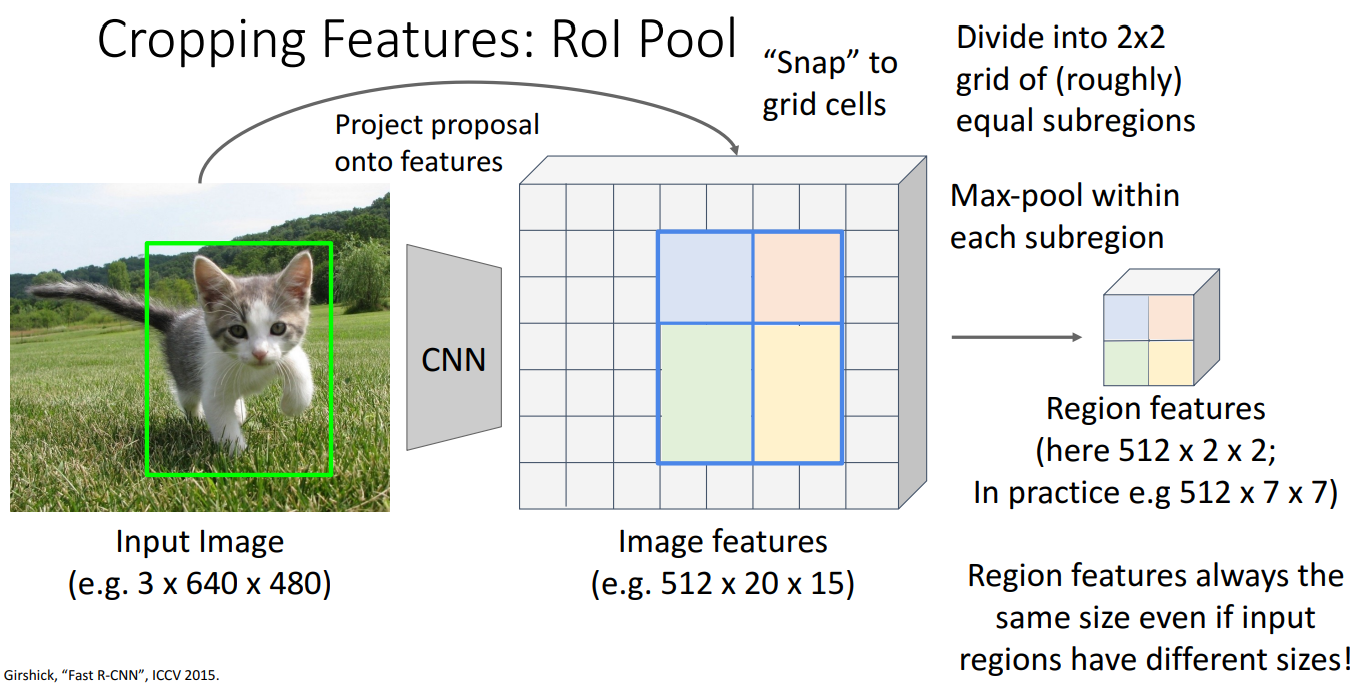
- 순서
- input image에서 얻은 RoI을 convolutional image feature를 얻기 위한 backbone network를 활용하여 image feature에 project 진행
- cnn을 통과한 Feature map에서 RoI에 해당하는 부분을 추출
- RoI가 Feature Map의 격자(Grid)와 완벽히 일치하지 않으므로 RoI를 격자(Grid)에 맞춰 정렬(Snap)
- subregion으로 나누기 위해 Max Pooling 진행
ex) 2 x 2 Max pooling을 수행하여 크기를 고정
- 최종적으로 512 x 2 x 2 형태의 feature map을 생성하고, FC Layer에 전달하여 클래스 분류 및 바운드 박스 보정 수행
- 문제점
- 녹색 및 파란색 영역의 크기가 다를 수 있어 feature에 대해 약간의 정렬 오류(misalignment)가 있을 수 있음
- snapping을 피하고, 선형 보간을 사용하여 정렬하는 방식인 RoI allign 사용
11. Fast R-CNN vs. Slow R-CNN
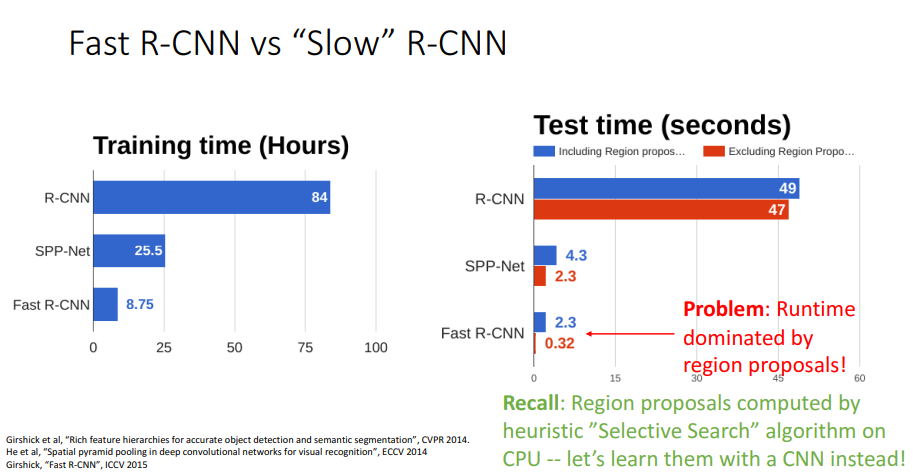
- 문제점: Runtime의 약 90%가 Region proposal 계산하는 데 사용
12. Faster R-CNN: Learnable Region Proposals
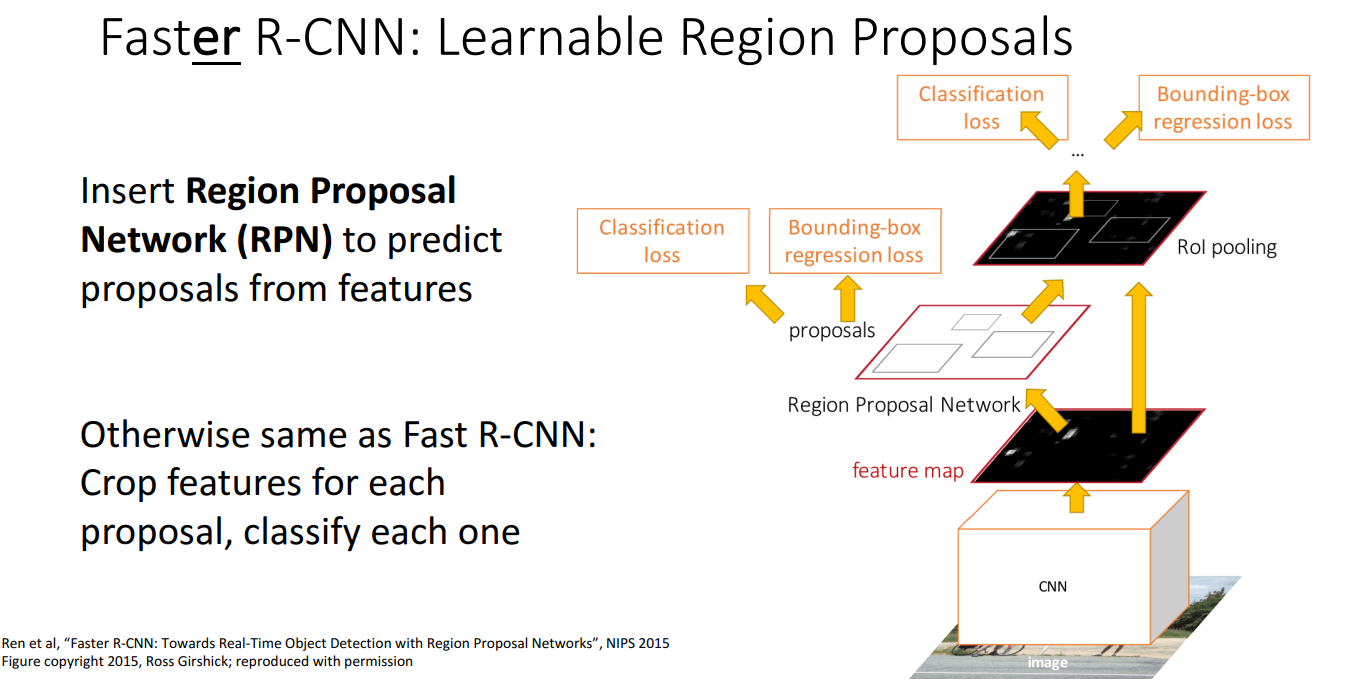
- 아이디어
- Selective Search와 같은 휴리스틱한 알고리즘을 제거하고 합성곱 신경망을 학습하여 Region Proposal을 예측하고 이를 수행하는 방법을 찾자
- 이를 위해 Region Proposal Network(RPN)을 삽입하는 것으로 영역 제안을 예측하는 역할을 함
- 순서
- 입력 이미지를 백본 네트워크로 실행하여 Image-level feature를 구함
- 해당 feature를 Region Proposal Network로 전달하여 Region Proposal을 구함
- 이후에는 fast R-CNN과 같은 방식으로 진행
- 학습해야 할 4가지 손실

- RPN classification loss: 앵커 상자를 객체인지 아닌지를 분류하는 것
- RPN regression loss: Anchor Box → Proposal Box로 변환하는 변형(Transformation) 예측, bounding box를 조정하는 regression 진행
- Object classification loss: proposal이 객체인지 배경인지 분류하는 것
- Object regression loss: Proposal Box → object Box로 변환하는 변형 예측
- 속도
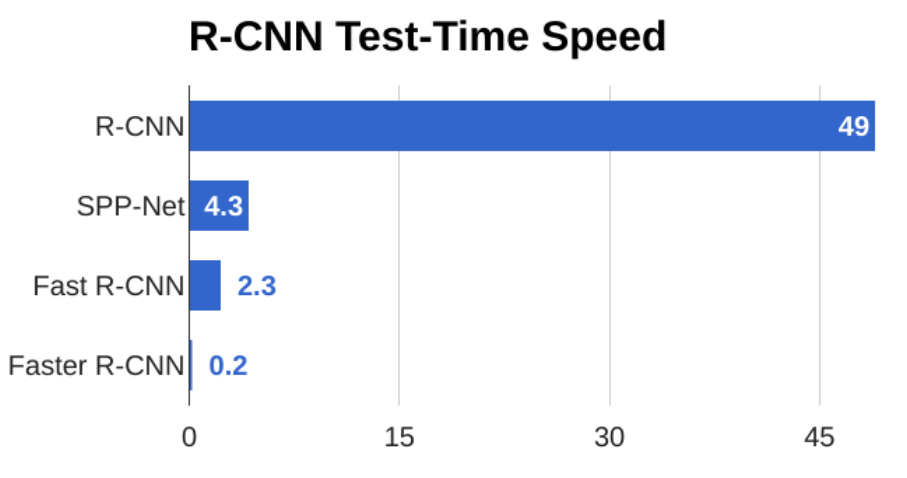
- Region Proposal을 계산하는 병목 현상을 제거하고, 대신 작은 합성 신경망을 사용하여 Region Proposal을 계산하기 때문에 빠르고 실시간으로 실행될 수 있음
- Faster R-CNN의 stage: Two-stage object detector
- First stage
- image 당 한 번씩 실행 (Backbone network, Region proposal network)
- Region Proposal을 얻음
- Second stage
- region 당 한 번씩 실행
- Crop feature 진행 (RoI pool, RoI align)
- object class, bbox offset를 예측 (최종 분류 점수와 회귀 매개변수 출력)
13. Region Proposal Network (RPN)
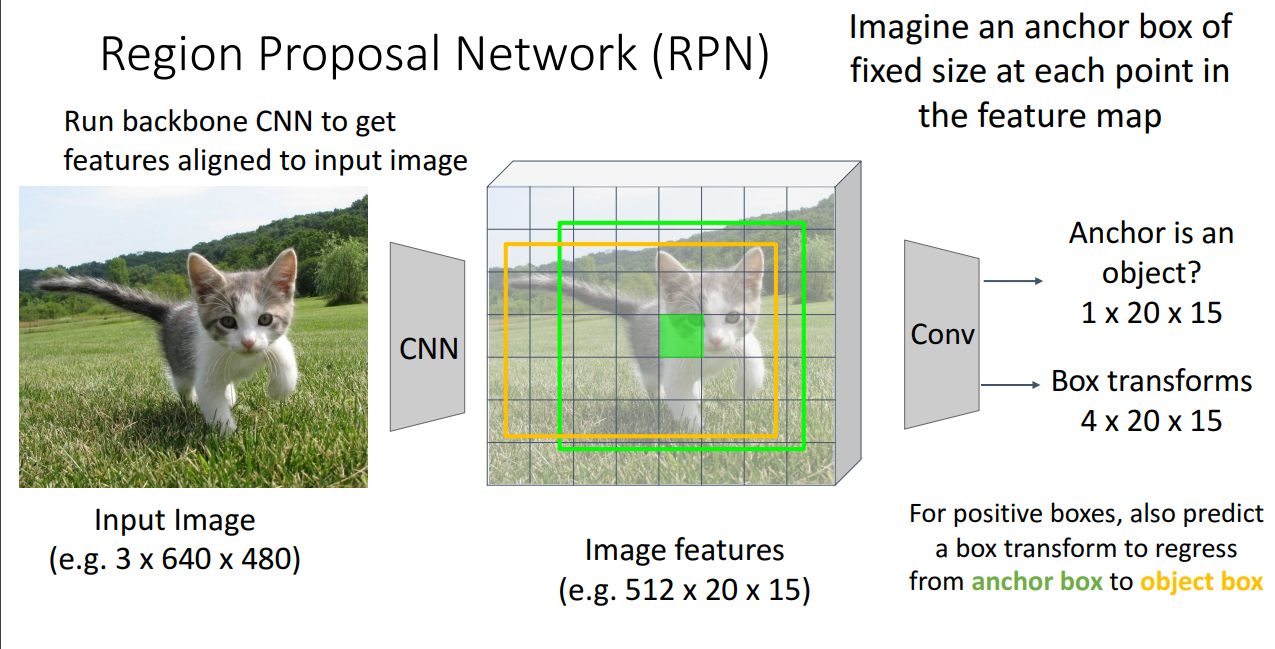
- 정의
- 객체가 존재할 가능성이 높은 영역을 찾는 역할로, CNN 기반으로 ROI를 생성하는 방식
- 순서
- Backbone CNN을 활용하여 Feature map 생성
- feature map의 각 Grid Cell 모든 위치에 Anchor Box를 배치
- CNN을 활용하여 각 Anchor box가 객체를 포함하는지 예측
- 이진 분류 문제 (Anchor box에 대해 postive score와 negative score를 출력)
- 1 × 20 × 15 크기의 출력 맵에서 per-cell logistic regression을 수행
- 특정 기준(예: IoU 0.5 이상)으로 객체를 포함하는지 판단, 0.5 넘으면 positive box로 간주
- Postive box에 대해 Box Transform을 적용하여 Anchor box를 실제 Object Box로 조정
- Negative box는 Box Transform 적용 없이 단순히 객체 없음, 배경으로 처리
- 문제점
- 나의 고정된 크기와 비율의 Anchor Box를 사용하면, 다양한 크기와 형태를 가진 객체를 정확하게 감지하기 어려움 (ex) 이미지 내에서 고양이, 자동차 등 다양한 크기의 객체가 존재할 경우)
- 이를 해결하기 위해, 하나의 위치에 대해 여러 개(K개)의 Anchor Box를 적용한다.
- 즉, 각각 다른 크기(Scale)와 비율(Aspect Ratio)을 하이퍼파라미터로 가진 여러 개의 Anchor Box를 사용하여 다양한 형태의 객체를 감지할 수 있도록 함
14. Single-Stage Object Detection
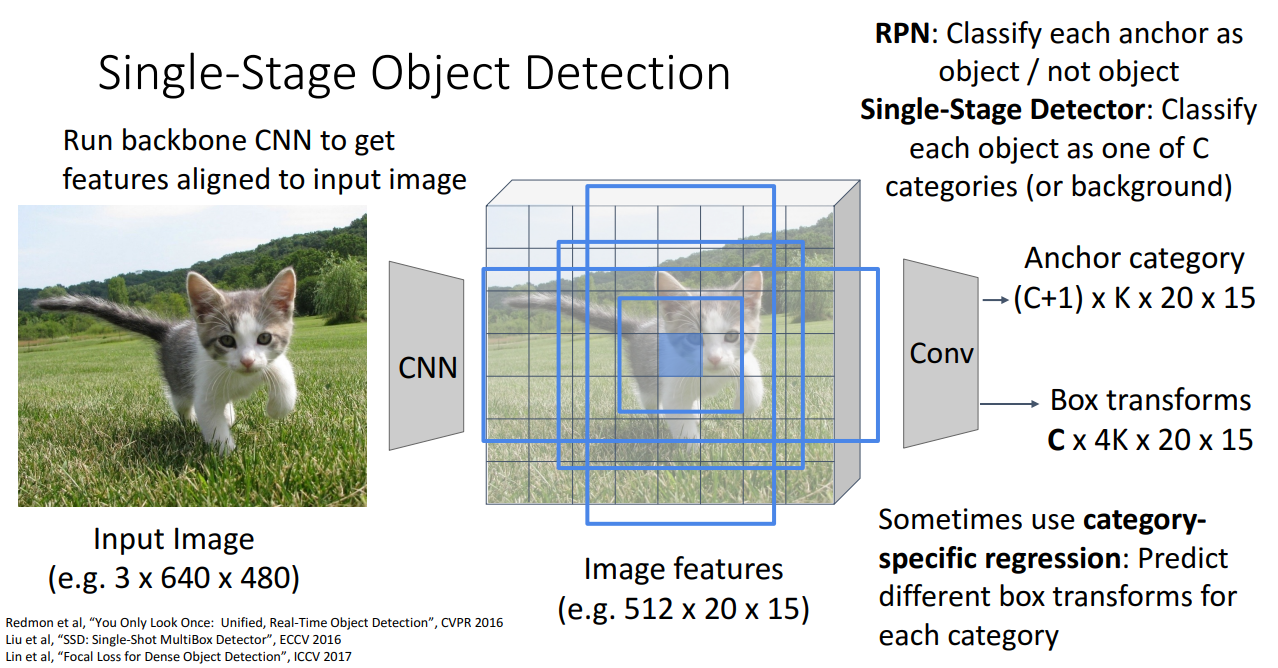
- 아이디어
- RPN에서처럼 앵커 상자를 객체로 분류하는 이진 분류 형식이 아니라 바로 객체 범주에 대한 전체 분류 손실을 사용하는 것
- 순서
- Backbone CNN을 통해 Feature Map 생성
- Feature Map의 각 위치에서 다양한 크기의 Anchor Box 배치
- 각 위치에서 여러 개(K개의) Anchor Box 사용 → 다양한 크기 & 종횡비 지원
- Classification & Regression 진행
- Classification
- 각 Anchor Box가 C개의 클래스 중 하나인지, 아니면 배경(Background)인지 분류
- 즉, (C+1) x K x 20 x 15 형태로 출력
- Regression (Box Transform)
- 예측된 Anchor Box를 실제 Object Box에 맞도록 조정
- C x 4K x 20 x 15 형태로 출력
- Category-Specific Regression: 모든 바운딩 박스에 동일한 변환을 적용하는 것이 아니라 클래스별로 다르게 박스를 조정할 수도 있음
15. Object Detection: Lots of variable!
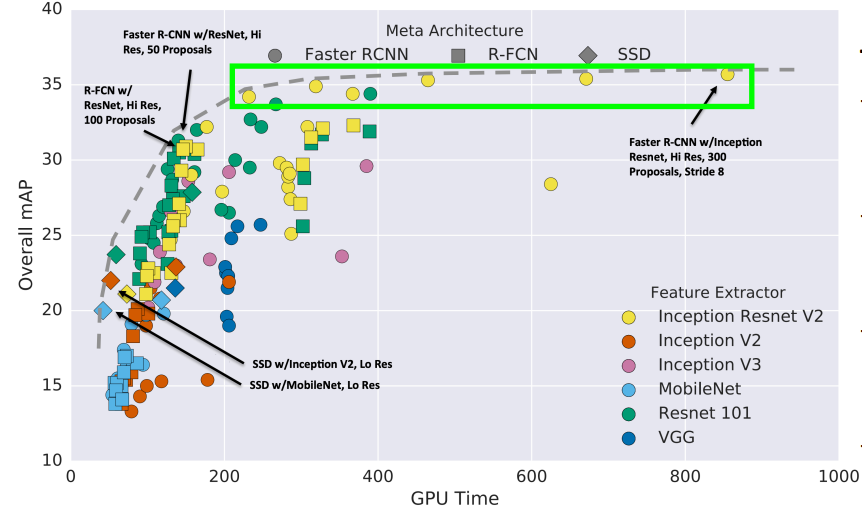
- plot 해석
- two-stage method가 더 잘 작동하는 경향이 있지만, 속도가 느림
- Single-stage method가 훨씬 더 빠른 경향이 있지만, 정확도가 떨어지는 경향이 있음
- bigger backnoe이 성능 향상시키지만, 속도가 느림
- 2017년 이후의 개선 방향
- 더 오랜 학습 (Train longer!)
- 멀티스케일 백본 사용 (Feature Pyramid Networks)
- 더 강력한 백본 네트워크 (ResNeXt 등)
- Single-Stage 모델 성능 개선
- 모델 크기 증가 (Very big models work better)
- Test-time Augmentation을 활용하여 성능 향상
- 앙상블 및 대량 데이터 학습 (Big ensembles, more data)
16. Summary