SPS LAB 2025.02.17 논문 세미나
- 본 내용은 Learning Fast and Slow for Online Time Series Forecasting 논문을 읽고 정리한 내용입니다.
- 논문 원본은 해당 링크에서 다운받으실 수 있습니다.
Contribution
- deep model을 사용한 online time series forecasting에서의 fast learning을 continual learning 문제로 혁신적으로 공식화함
- CLS 이론에서 영감을 얻어 time series의 fast changing and long-term knowledge를 다루기 위해 fast-and-slow learing paradigm인 FSNet을 제안함
- 실제 및 합성 데이터셋을 모두 사용한 광범위한 실험을 통해 FSNet의 efficacy와 robustness를 입증함
Introduction
- time series forecasting이 연구나 산업에 있어서 중요한 역할을 함
- 정확하게 time series를 예측하는 것이 교통 관리 및 전력 소비와 같은 다양한 비즈니스 부문에서 큰 도움이 될 수 있으므로 더 나은 예측 모델을 발전하기 위해 많은 노력을 기울이고 있음
- deep neural network가 계층적 잠재 표현과 복잡한 종속성을 발견하는 뛰어난 능력 덕분에 많이 사용되고 있으나, 이러한 연구는 전체 학습 데이터셋을 사전에 제공해야 하는 배치 학습 설정에 초점을 맞추고 있으며, 입력과 출력 간의 관계가 전체적으로 정적으로 유지된다는 것을 의미함
- 이러한 가정은 실제 응용 환경에 제한적이며, 데이터가 스트림에 도달하면 입력-출력 관계가 시간이 지남에 따라 변할 수 있음
- 그렇다고 다시 처음부터 모델을 재훈련하는 것은 시간이 굉장히 많이 소요될 수 있으므로 환경에 따라 동적으로 변화하는 것을 포착하기 위해 new sample에 대해서만 online으로 deep forecaster를 학습시키는 것이 적절한 방법임
- 많은 실제 응용 분야에서 online learning이 보편화되어 있음에도 불구하고, deep foreaster를 online으로 학습하는 것은 2가지 이유로 어려움을 겪고 있음
- data stream에서 DNN을 순진하게 훈련하면 천천히 수렴함
- mini-batche나 multiple epoch에 걸친 훈련과 같은 offline training 혜택이 제공되지 않기 때문
- distribution shift가 발생하면 새로운 개념을 학습하기 위해 더 많은 훈련 샘플을 필요로 함
- 전반적으로 심층 신경망은 강력한 표현 학습 능력을 가지고 있지만 데이터 스트림에서 성공적인 학습을 촉진할 수 있는 메커니즘이 부족함
- 시계열 데이터는 종종 하나의 패턴이 비활성화되어 미래에 다시 등장할 수 있는 반복적인 패턴을 가짐
- deep network는 catastrophic forgetting 현상을 겪고 있고, prior knowledge를 유지할 수 없으며 반복되는 패턴의 비효율적인 학습을 초래하여 전체 성과를 저해함
- data stream에서 DNN을 순진하게 훈련하면 천천히 수렴함
- 앞에서 언급한 한계를 해결하기 위해 online time series forecassting을 공식화하여 task-free continual learning problem으로 만듦
- 구체적으로 continual learning은 2가지 objective를 balancing하는 것이 필요함
- past knowledge를 활용하여 현재 패턴의 빠른 학습을 촉진
- acquired knowledge을 유지하고 업데이트하기
- CLS 이론에 따르면 인간은 hippocampus와 neocortex 사이의 상호작용 덕분에 지속적으로 학습할 수 있다고 함
- 해마는 신피질과 상호작용하여 이러한 경험을 통합, 회상 및 업데이트하여 보다 일반적인 표현을 형성하며, 이는 새로운 경험으로의 일반화를 지
- 두 objective의 연결을 위해 Complementary Learning Systems (CLS) theory에 영감을 받은 효율적인 online time series forecasting framework인 FSNet(Fast and Slow learing Network)를 개발
- FSNet의 fast learning의 key idea는 distribution shift를 명시적으로 감지하지 않고 항상 현재 샘플의 학습을 개선 (새로운 데이터에 대해 이전의 데이터와 비교하여 변화를 감지하기보다는, 현재의 데이터 패턴을 최대한 잘 학습하는 것에 집중)
- 이를 위해, FSNet은 레이어별 어댑터를 사용하여 연속 샘플 간의 시간 정보를 모델링하여 각 중간 레이어가 더 나은 학습을 위해 스스로 조정할 수 있도록 함
- FSNet은 훈련 중 관찰되는 중요한 반복 패턴을 저장하기 위해 associative memory를 추가로 사용함
- 반복되는 이벤트가 발생하면 어댑터는 메모리와 상호 작용하여 이전 작업을 검색하고 업데이트하여 이러한 패턴을 빠르게 학습할 수 있도록 함
- 따라서 어댑터는 시계열의 시간적 매끄러움을 모델링하여 학습을 용이하게 할 수 있으며, 연관 메모리와의 상호 작용을 통해 모델이 반복 패턴의 학습을 빠르게 기억하고 계속 개선
- FSNet은 task switch에 대한 정보가 필요하지 않기 때문에 task-free method임을 강조
- 대신 FSNet은 시계열의 temporal smoothness과 반복 패턴의 특성을 활용하여 현재 샘플을 학습하는 데 중점을 둠
Proposed Framework
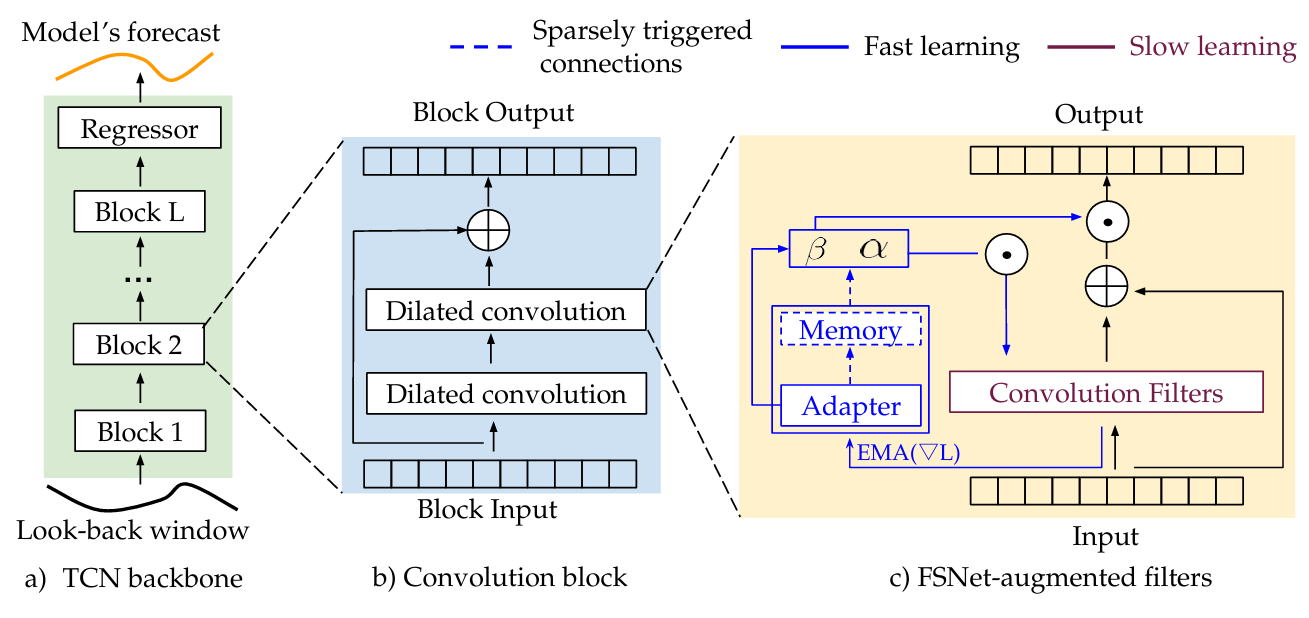
Online time series forecasting as a continual learning problem
- 온라인 시계열 예측을 지속적 학습 문제로 공식화하는 것은 시간에 따라 변화하는 시계열 데이터를 효과적으로 모델링하고 예측하기 위한 접근 방식
- 해당 공식화는 시계열을 일련의 정지된 세그먼트로 나눌 수 있는 locally stationary stochastic processes observation에 기반
- 시계열 데이터를 분석하기 위한 가정으로, 전체적으로 비정상적인 시계열 데이터도 짧은 시간 구간으로 나누어 보면 각 구간 내에서는 정상적인 특성을 나타낸다고 보는 것
- 전체 시계열 데이터를 국소적으로 정상적인 여러 개의 세그먼트로 나누고, 각 세그먼트에서 시계열 데이터를 예측하는 것을 하나의 학습 태스크로 정의함
- 또한 많은 continual learning에서 흔히 사용되는 설정과 동일하게 작업 전환 시점이 모델에 주어졌다고 가정하지 않음
- 실제 데이터에서 이러한 정보를 수동으로 얻는 것은 누락되거나 불규칙하게 샘플링된 데이터로 인해 비용이 많이 들 수 있음
- 따라서 데이터가 여러 작업으로 구성되어 있다고 가정하지만, task-changing points는 제공되지 않으며, 이는 online continual learning formulation에 해당
- 기존 연구와의 본 논문 공식의 차이
- 시계열은 진화하며 오래된 패턴은 미래에 정확히 나타나지 않을 수 있으므로, 오래된 패턴을 정확하게 예측하는 것이 아니라 어떻게 진화할지 예측하는 데 관심이 있음
- 예를 들어 지난 겨울의 전력 소비량을 예측할 필요는 없지만, 지난 겨울과 같은 패턴을 보일 가능성이 높다고 가정하면 이번 겨울의 전력 소비량을 예측하는 것이 더 중요
Fast and Slow Learning Networks (FSNet)
- per-layer adapter를 통해 갑작스러운 변화에 대한 fast adaptation을 함
- sparse associative memory interaction을 통해 recurring patterns의 학습을 촉진
- simple forward architecture와 유망한 결과로 인해 Temporal Convolutional Network(TCN)를 backbone deep neural network로 사용
- 해당 network는 파라미터 와 함꼐 개의 Layer를 가지고 있음
- FSNet은 2가지 보완적인 구성 요소로 TCN backnone을 개선
- per-layer adapter 와 per-layer associative memory 로 구성
- 전체 trainable parameter는
- 전체 associative memory는
Fast-adaptation mechanism
- 최근 연구들은 얕은 네트워크가 데이터 스트림의 변화에 빠르게 적응하거나 제한된 데이터에 대해 더 효율적으로 학습할 수 있는 Shallow-to-deep principle를 입증함
- 그러므로 얕은 네트워크를 가진 시나리오에서 먼저 학습한 다음 multi-exit 아키텍처를 통해 깊이를 점진적으로 늘리는 것이 더 유익함
- fast adaptation mechanism은 네트워크의 깊이에 국한되지 않고 각 계층이 독립적으로 적응할 수 있도록 함으로써 이러한 접근 방식을 일반화
- 빠른 레이어별 적응을 가능하게 하는 것은 편미분(각 레이어의 예측 손실 기여도) 이 forecasting loss 에 대한 레이어 의 기여도를 특성화한다는 것
- 온라인 훈련에서는 시계열 데이터의 노이즈와 비정상적인 특성 때문에 단일 샘플의 기울기가 크게 변동하여 adaptation coefficient에 노이즈를 도입할 수 있음
- 우리는 온라인 훈련의 노이즈를 완화하고 시계열적으로 시간 정보를 캡처하기 위해 백본 기울기의 EMA를 사용
- = l-th layer의 gradient
- = EMA gradient
- = adaptation coefficient로, 2가지 요소로 구성 (
- = a weight adaptation coefficient
- = a feature adaptation coefficient
- 어댑터는 을 입력으로 받아 적응 계수 에 매핑하고, element-wise transformation의 단순성과 continual learning에서의 유망한 결과 덕분에 adaptation process로 채택
- layer 에서의 adaptation process는 weight transformation과 feature transformation 2가지 단계로 구성
- = channels C와 length Z를 가진 feature map의 stack
- = adapted weights
- = element-wise multiplication
- title(): 가중치 어댑터가 새로운 축을 따라 벡터를 반복하는 해당 함수를 통해 모든 필터에 채널별로 적용된다는 것
- = chunking operation, 해당 방정식의 구현은 모델의 기울기를 적응 계수에 직접 매핑하여 매우 높은 차원의 매핑을 초래하므로 기울기를 동일한 크기의 청크로 분할한 다음 각 청크를 적응 계수 요소에 매핑하는 chunking operation을 구현
Remembering recurring events with an associative memory
-
시계열 데이터는 오래된 패턴이 다시 등장할 수 있으며, 학습 성과를 향상시키기 위해 past action을 활용하는 것이 필수적임
-
FSNet은 FSNet은 각 레이어의 어댑터를 통해 학습 과정에서 얻은, repeating event를 학습하는 데 유용하다고 주장하는 계수 를 사용하여 패턴에 적응
- 는 과거의 특정 패턴에 어떻게 적응했는지를 나타내며, 적절한 를 저장하고 검색하는 것은 나중에 해당 패턴이 다시 나타날 때 학습에 도움이 될 수 있음
-
따라서 FSNet의 두 번째 핵심 요소로서 associative memory 를 활용하여 과거에 나타났던 반복 패턴에 대한 adaptation coefficient 를 저장
-
Sparse Adapter-Memory Interaction
-
계산 비용을 줄이고, 노이즈에 대한 민감도를 낮추기 위해 어댑터와 메모리 간의 상호작용은 모든 단계에서 발생하는 것이 아니라 representation에 큰 변화가 있을 때만 발생
-
상호작용 트리거
- 두 종류의 기울기 EMA를 사용하고, 두 EMA 기울기 사이의 코사인 유사도를 계산
- 코사인 유사도가 임계값 보다 작으면 메모리와의 상호작용이 트리거됨
- 는 하이퍼파라미터로, 메모리가 중요한 변화 패턴만 기억하도록 비교적 높은 값(0.7)으로 설정
- 코사인 유사도가 작다는 것은 현재와 과거의 기울기가 서로 다른 방향을 가리킨다는 의미이며, 이는 현재의 표현이 과거 표현과 크게 다르다는 것으로 새로운 패턴이 나타났거나 기존의 패턴이 크게 변화했다는 것을 의미함
-
-
The Adapter-Memory Interacting Mechansim
- 현재의 적응 계수가 일부 샘플에 걸쳐 있을 수 있는 전체 이벤트를 포착하지 못할 수 있으므로 현재 패턴을 완전히 포착하기 위해 adaptation coefficient의 EMA(coefficient 포함)를 사용하여 memory read write operation을 수행
- 메모리 읽기: 메모리 상호작용이 트리거되면 어댑터는 memory item에 대한 weighted sum인 attention read operation을 통해 과거에 가장 유사한 transformation을 쿼리하고 검색
- = 의 i번째 element
- = 의 i번째 row
- 메모리가 conflicting pattern을 저장할 수 있기 때문에, 우리는 k = 2로 고정된 상위 k개의 가장 관련성 있는 메모리 항목을 검색하여 sparse attention을 사용
- 검색된 adaptation coefficient는 과거의 현재 패턴에 적응하는 데 있어 오래된 경험을 특징짓는 것으로, 와 같이 현재 매개변수를 weighted sum하여 현재 학습을 개선할 수 있음
- 메모리 쓰기: 현재 학습에서 얻은 변환 계수를 outer product 연산을 사용하여 새로운 정보를 가장 관련성이 높은 메모리 위치에 효율적으로 저장
- = outer-product operator로, 이를 통해 가장 관련성 있는 위치에 새로운 지식을 효율적으로 작성 가능
- memory는 기하급수적으로 증가하는 값을 피하기 위해 정규화
Experiments
3가지 가설을 조사하는 것을 목표로 함
- FSNet은 딥 모델을 사용하는 기존 전략에 비해 new concept과 recurring concept 모두에 더 빠르게 적응할 수 있도록 지원
- FSNet은 다른 모델에 비해 빠르고 우수한 수렴을 달성
- 편미분을 모델링하는 것은 빠른 적응을 위한 핵심 요소
Experimental Settings
- Datasets
- ETT: 2년 동안 오일 온도와 6가지 전력 부하 특성의 목표 값을 기록한 데이터로, 관측값이 각각 시간별 및 15분 간격으로 기록되는 ETTh2 및 ETTm1 벤치마크를 고려
- ECL (Electricity Consuming Load): 2012년부터 2014년까지 321명의 고객의 전기 소비량을 모은 데이터
- Traffic: 샌프란시스코 베이 지역 고속도로의 도로 점유율을 기록한 데이터
- Weather: 2010년부터 2013년까지 한 시간 간격으로 미국 내 약 1,600개 지역에서 11개의 기후 특징을 기록한 데이터
- S-Abrupt (S-A): 갑작스럽고 반복적인 개념이 포함되어 있고, 샘플은 AR0.1(1), AR0.4(1), AR0.6(1), AR0.1(1), AR0.3(1), AR0.6(1) 순서로 하나의 AR 프로세스에서 다른 AR 프로세스로 갑자기 전환됨
- S-Gradual (S-G): 점진적인 증분 이동이 포함되어 있고 이 시나리오에서 작업의 마지막 20% 샘플은 위의 순서로 두 개의 AR 프로세스의 평균임
- Baseline
- OnlineTCN
- ER (Eperience Replay)
- TFCK
- MIR
- DER++
- Informer
- Implementation Details
- 데이터를 warm-up phase와 training phase로 분리 (25:75)
- optimization details = AdamW optimizer를 사용하여 (MSE) loss를 최적화
- epoch와 batch size는 모두 online learning 설정을 따르기 위해 하나로 설정
- 모든 baseline이 네트워크 크기의 세 배인 하나의 작업 모델과 두 개의 경사도 EMA를 포함하는 총 메모리 예산을 동일한 FSNet과 동일하게 사용하도록 하여 공정한 비교를 구현
- ER, MIR, DER++는 이 예산을 맞추기 위해 에피소드 메모리가 이전 샘플을 저장할 수 있도록 허용
-OnlineTCN과 Informer의 경우, 대신 backbone size를 늘림
- ER, MIR, DER++는 이 예산을 맞추기 위해 에피소드 메모리가 이전 샘플을 저장할 수 있도록 허용
- warm-up phase에 online training sample에 대해 정규화를 하기 위해 mean, standard deviation을 계산하고, cross-validation을 통해 hyper parameter 설정
- 모든 벤치마크에서, look-vack window size를 60으로 설정했고, forecast horizon은 {1, 24, 48}로 설정
Online Forecasting results
Cumulative Performance
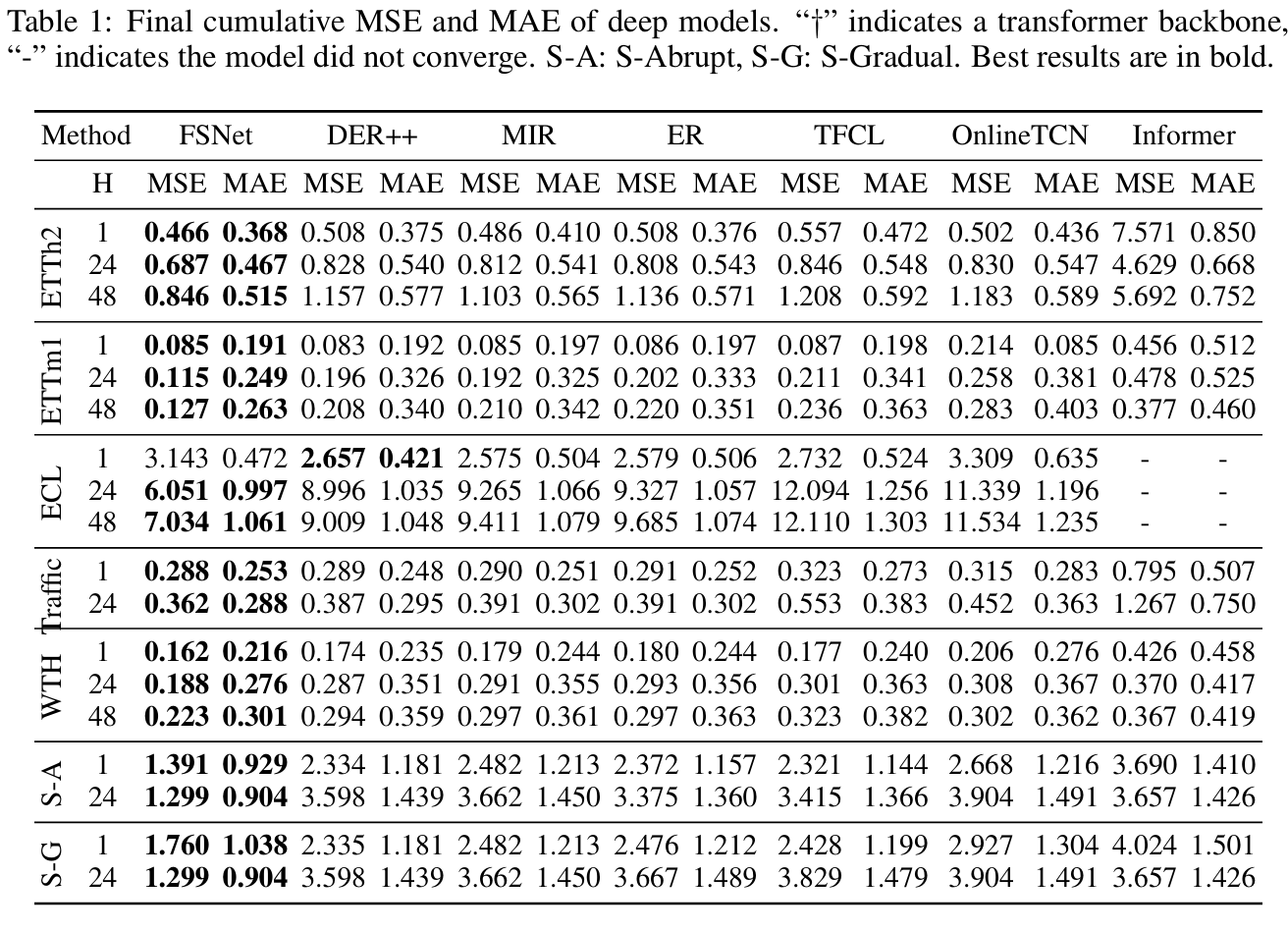
- mean-squared errors(MSE)와 Mean absolute error(MAE)를 나타냄
- 보고된 수치는 평균 5회 이상 실행
- ER과 그 변형(MIR, DER++)가 TCN strategies보다 향상된 성능을 가지고 있음을 관찰
- 그러나 이러한 방법은 multile task switches(S-Abrupt) 하에서 잘 작동하지 않고, no clear task boundaries(S-Gradual)에서 더 어려운 문제를 야기시키고 오류를 증가시킴
- Informer가 online setting에서 잘 수행되지 않으며, 다른 기준들보다 우수한 성능을 보인다는 유사한 결과도 관찰
- FSNet이 모든 데이터셋에서 우수한 성능을 보이고, 다양한 forecasting horizon에 대해서도 다른 baseline들을 능가하는 성능을 가짐
- 합성 데이터셋의 상당한 개선은 명확한 작업 경계 없이도 비정상적인 환경에 빠르게 적응하고 이전 지식을 회상할 수 있는 FSNet의 능력을 나타냄
Convergence behaviors of Different Learning Strategies
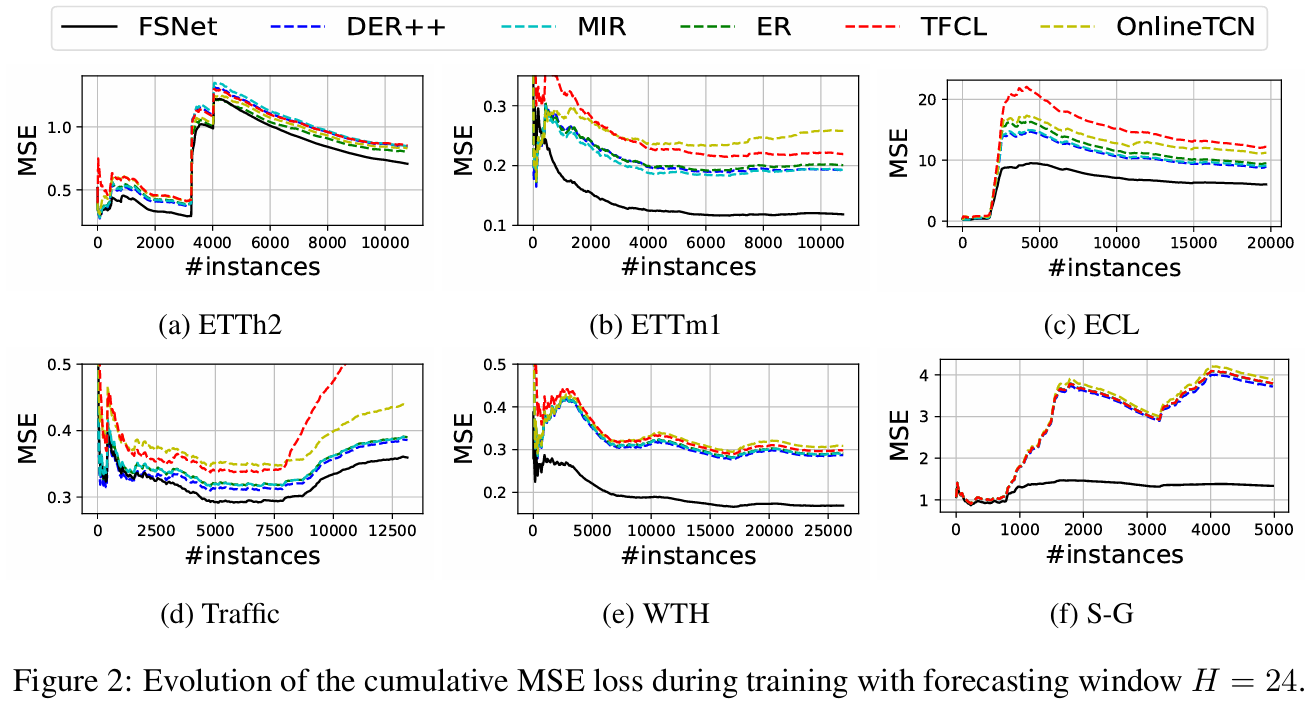
- 우리는 손실 곡선의 급격한 피크로 인해 대부분의 데이터셋에서 concept drift가 발생할 가능성이 높다는 것을 관찰
- 이러한 drift는 학습 초기 단계, 대부분 데이터의 처음 40%에서 나타나며, 나머지 절반의 데이터는 고정되어 있음
- 이 결과는 마지막 데이터 세그먼트에서만 모델을 테스트함으로써 전통적인 batch training이 종종 너무 낙관적임을 보여줌
- OnlineTCN에 비해 ER이 빠른 수렴을 제공한다는 것을 보여줌
- 그러나, 원본 데이터를 저장하는 것은 많은 도메인에 적용되지 않을 수 있다는 점에 유의하는 것이 중요
- S-Gradual에서 대부분의 baseline은 error curve의 증가 추세에 따라 concept drift에서 빠르게 회복할 수 없음을 보여줍니다.
- 대부분의 데이터셋에서 FSNet의 성능이 baseline 대비하여 크게 개선됨 (특히, ETT, WTH, S-Gradual datasets에서)
- 나머지 데이터셋은 누락된 값과 차원 내 및 차원 간에 큰 차이가 있어 더 나은 데이터 정규화 계산을 하는 것이 필요
- 전반적으로, FSNet은 온라인 시계열 예측의 과제를 조명하고 FSNet의 유망한 결과를 입증함
Visualization
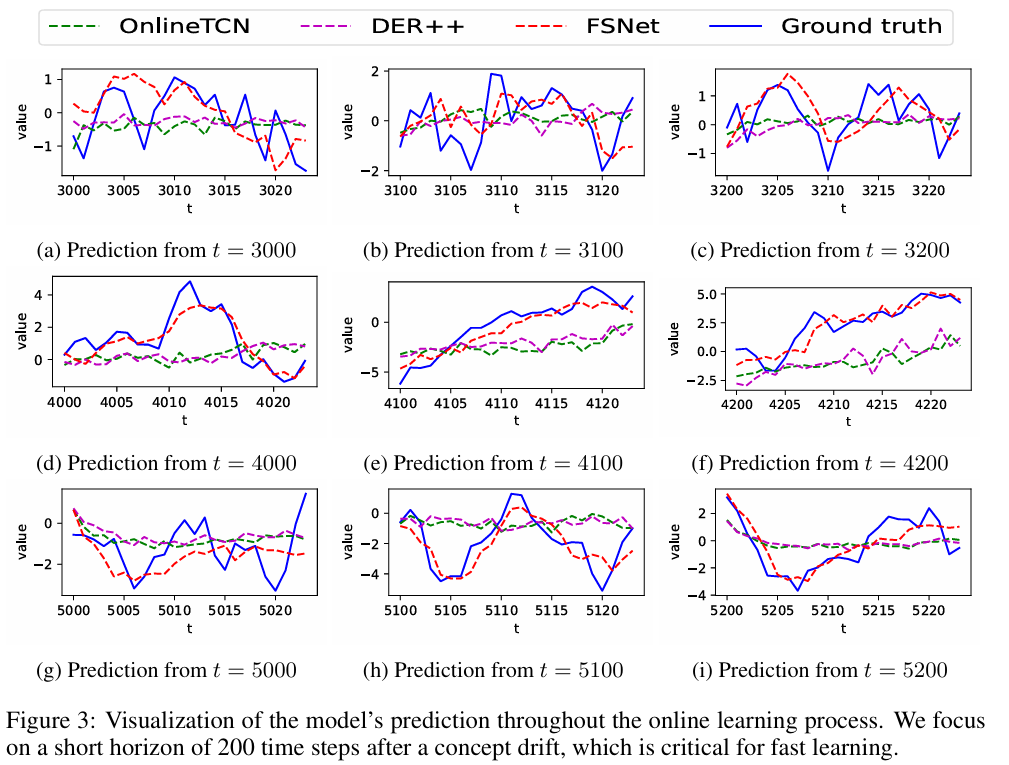
- 다른 데이터셋은 다변량이기 때문에 시각화하는 것이 어렵고 S-Abrupt가 단변량 시계열이기 때문에 모델의 예측 품질을 탐구
- old task가 다시 나타날 때 모델들의 behaviour에 관심이 있고, t=3000 이후 다양한 time points에 대해 예측을 그래프로 표시
- 모델이 몇 가지 샘플만 관찰한 초기 단계에서 학습하는 데 어려움을 겪는다는 점에서 online으로 deep neural network을 훈련하는 데 어려움을 겪을 수 있음
- 초기 단계의 task switches(처음 200개 샘플)에 초점을 맞추고 있으며, 이는 모델이 distribution shift에 빠르게 적응해야 함을 의미
- 작업당 샘플 수가 제한되고 여러 개념의 드리프트가 존재함에 따라 standard online optimization은 무작위 노이즈를 약 0으로 예측하는 순진한 해결책으로 전락
- 그러나, FSNet은 time series의 pattern을 성공적으로 포착하고, 학습 단계에서 더 잘 예측함
Ablation studies of FSNet's Design
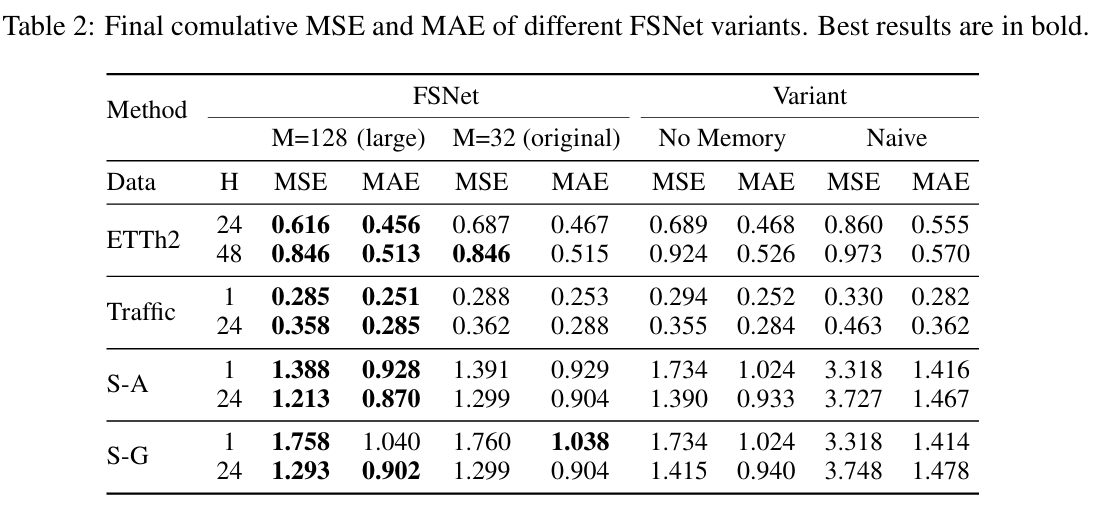
- FSNet의 요소들의 기여도를 분석
- memory를 사용하지 않고 adapter만 사용한 No Memory 변형을 구성하여 associative memory를 사용한 이점을 탐구
- 어댑터를 추가로 제거하여 백본과 함께 adaptation coefficients 를 직접 훈련하는 Naive 변형을 생성하여 fast adaptation의 핵심 아이디어인 layer's gradients를 monitoring하는 것의 이점을 탐구
- associative memory size를 32개의 항목에서 128개의 항목으로 확장하여 FSNet의 확장성을 탐구
- 결과
- FSNet과 No Memory variant가 Traffic, S-Gradual 데이터셋에서 유사한 성능을 보이는 것으로 확인
- traffic 데이터셋에서 중요하지 않은 representation interference와 S-Gradual 데이터셋에서 천천히 변화하는 representation 때문
- representation change를 adapter 혼자서 쉽게 포착할 수 있고, memory interaction을 트리거하지 않을 수 있음을 의미
- 이와 다르게, Sudden drift가 존재하는 ETTH2와 S-Abrupt 데이터셋에서는 반복적인 이벤트의 학습을 촉진하기 위해 모델의 과거 동작을 저장하고 호출하는 이점을 분명히 관찰
- Naive varriant가 만족스러운 성과를 달성하지 못함
- gradient EMA를 사용함으로써 time series 데이터의 temporal smoothness를 모델링하는 것에 이점이 있음을 나타냄
- FSNet의 large memory variant는 대부분의 경우 개선을 보이며 확장성을 나타냄
- FSNet과 No Memory variant가 Traffic, S-Gradual 데이터셋에서 유사한 성능을 보이는 것으로 확인
Conclusion
- 새로운 패턴이나 반복되는 패턴에 빠르게 적응할 수 있는 능력이 부족한 비정상적인 환경에서 online time series forecasting을 위한 Deep neural network 훈련의 한계를 조사
- CLS 이론에서 확장한 fast and Slow learing Network (FSNet)을 제안
- FSNet은 신경망 백본을 두 가지 주요 구성 요소로 보강
- recent change에 적응하기 위한 adapter
- recurrent pattern을 처리하기 위한 associative memory
- 어댑터는 메모리와 상호작용하여 중요한 반복 패턴을 저장, 업데이트 및 검색하여 향후 이러한 이벤트에 대한 학습을 용이하게 함
- 광범위한 실험을 통해 FSNet이 다양한 유형의 concept drift를 처리하여 real-world data와 synthetic time series data 모두에서 유망한 결과를 얻을 수 있는 능력을 입증
