Performance
Outline
세상에는 정말 많은 컴퓨터와 시스템이 존재합니다. 누구나 그렇듯 다들 빠르고 정확한 컴퓨터를 원할 것입니다. Performace 챕터에서는 시스템 간의 성능 비교를 하는 방법을 정리할 것입니다. 그렇다면 성능을 측정하는 방법에는 무엇이 있을까요?
- Latency(대기시간) vs Throughput(처리량)
- CPU Execution Time/MIPS/Benchmark
이러한 지표들이 있습니다.
또한 성능 개선의 정도를 나타낼 수도 있습니다.
- Amdahl's law
- Gustafson's law
Importance
컴퓨터 시스템의 구조를 설계할 때, 어떤 시스템이 더 나은지 알아야합니다.
구조 설계는 반복적인 작업입니다.
- 설계 가능한 공간 찾기
- 선택
- 선택 평가
선택을 정확하게 평가하기 위해서는 좋은 측정 방법론이나 도구가 필요합니다.
Types
성능을 평가하는 지표로는 3개의 타입이 있습니다.
- Time(Latency): 시작과 끝 사이의 시간
- Execution time(Response time, latency)
- 사용자가 관심있음. (사용자 입장에서는 빨리만 실행되면 ok)
- Rate: 단위 시간 당 일 처리량
- Throughput: MIPS, MFLOPS/Bandwidth: Mbps
- 시스템 관리자나 서버가 관심있음. (사용자는 한 번에 몇개씩 처리되는지는 상관 X)
- Ratio: A가 B보다 N배 빠르다
- Time과 Rate의 관계
그럼 여기서 질문을 하나 던져볼 수 있습니다.
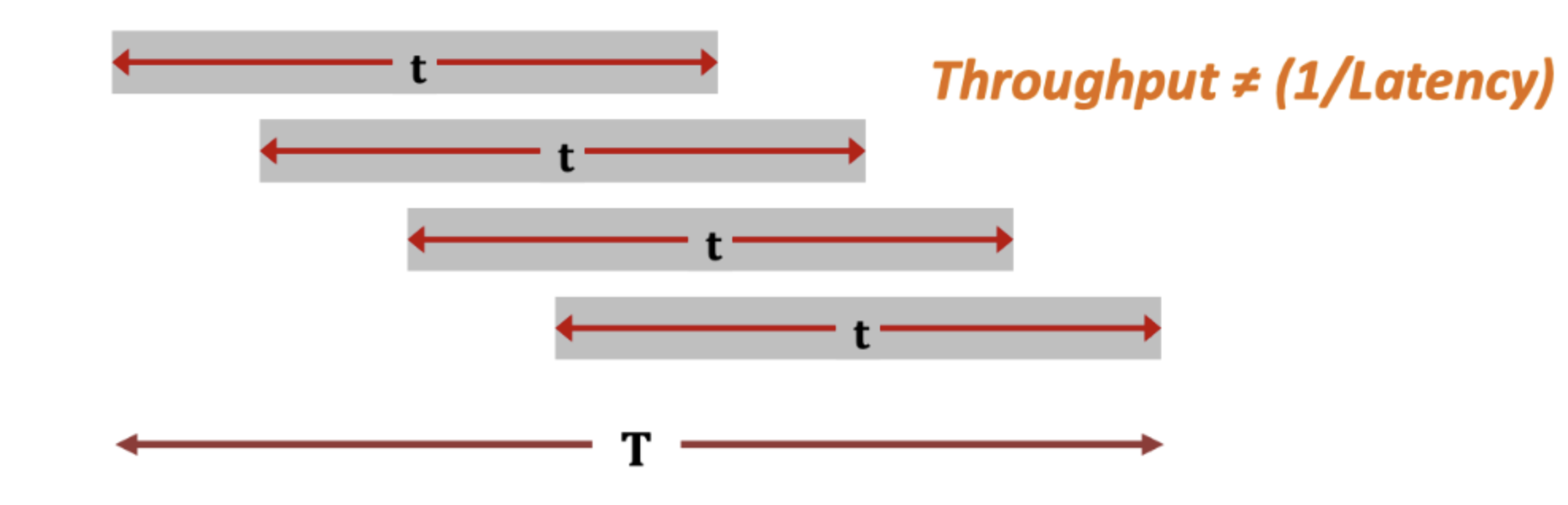
Latency가 하나의 일을 수행하는 데 걸리는 시간이고, Throughput이 시간 당 일 처리량이라면 항상 둘은 역수 관계인가?
얼핏 보면 맞는 말일 수 있지만, 그럴 때도 있고 아닐 때도 있습니다.
하나의 일을 처리할 때 t만큼의 시간이 걸린다면, 4개의 일은 4t만큼의 시간이 걸려야합니다.
하지만 아래 그림과 같은 상황이라면, 시간이 눈에 띄게 줄어든 것을 볼 수 있죠.
Little's Law
- 추가 예정
Time
위에서 짧게 정리했듯이, 시간은 성능의 첫번째 타입이며 이 시간이라는 지표에도 여러가지가 있습니다.
-
Wall-clock, response time(latency), or elapsed time
- 위의 세가지는 실제로 사용자가 느끼는 시간 입니다.
- CPU time
- memory and disk access time
- communication and channel delay
- Operating System overhead ...
- 이렇게 다양한 과정을 거쳐 사용자가 느끼는 시간이라고 할 수 있습니다.
- 위의 세가지는 실제로 사용자가 느끼는 시간 입니다.
-
CPU (execution) time
- response time 중 하나인 CPU time은 프로그램에 소요된 CPU시간을 의미합니다.
- User CPU time + System CPU time
CPU Time
성능을 측정할 수 있는 지표가 되는 CPU Time을 측정하는 방법을 알아보겠습니다.
-
CPU execution time @ 1 instruction
= (# of clock cycles for instruction) x (Clock cycle time)
= (# of clock cycles for instruction) / (Clock Rate(=Frequency)) -
CPU execution time @ program
- IC(Instruction Count): 프로그램당 실행하는 명령어의 개수
- CPI(Clock cycles Per Instruction): 명령어당 평균 사이클
- 따라서 IC x CPI = CPU clock cycles
Example
Quesion 1.
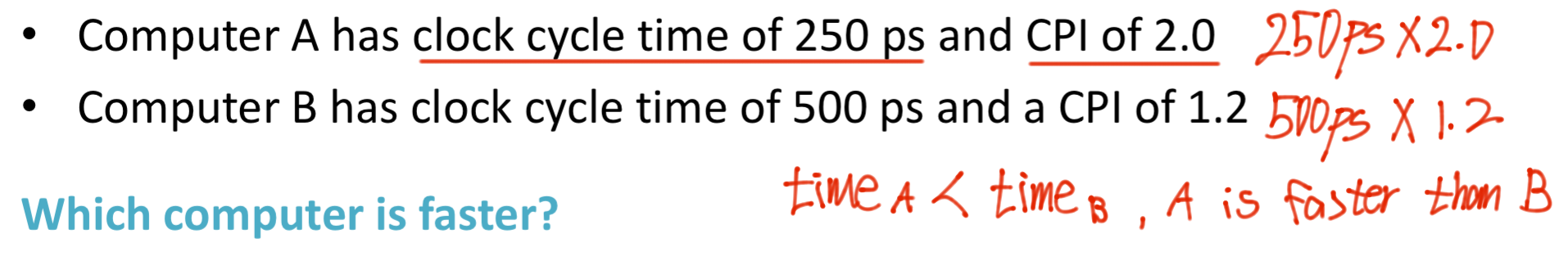
Question 2.
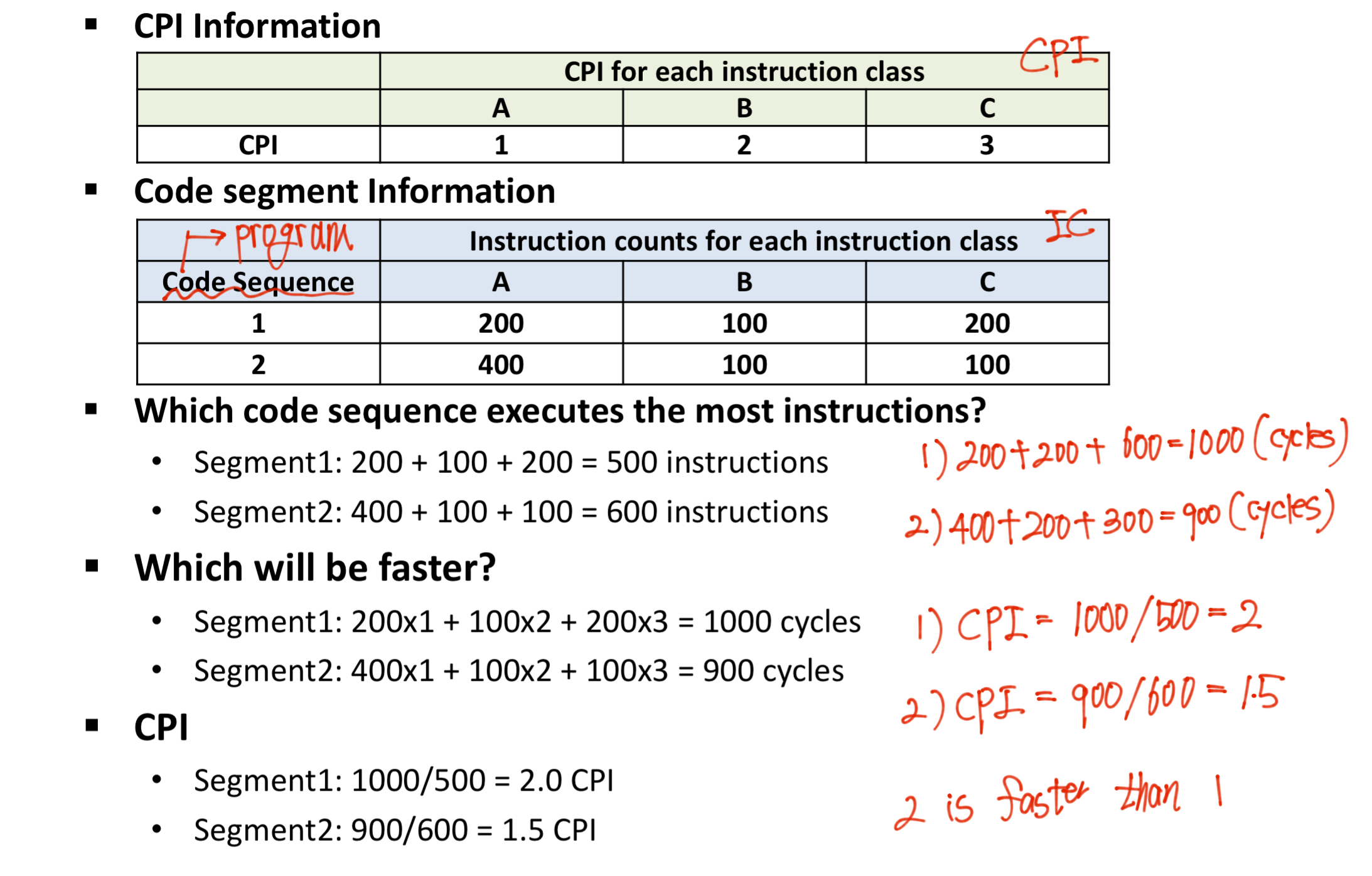
Question 3.

Question 4.
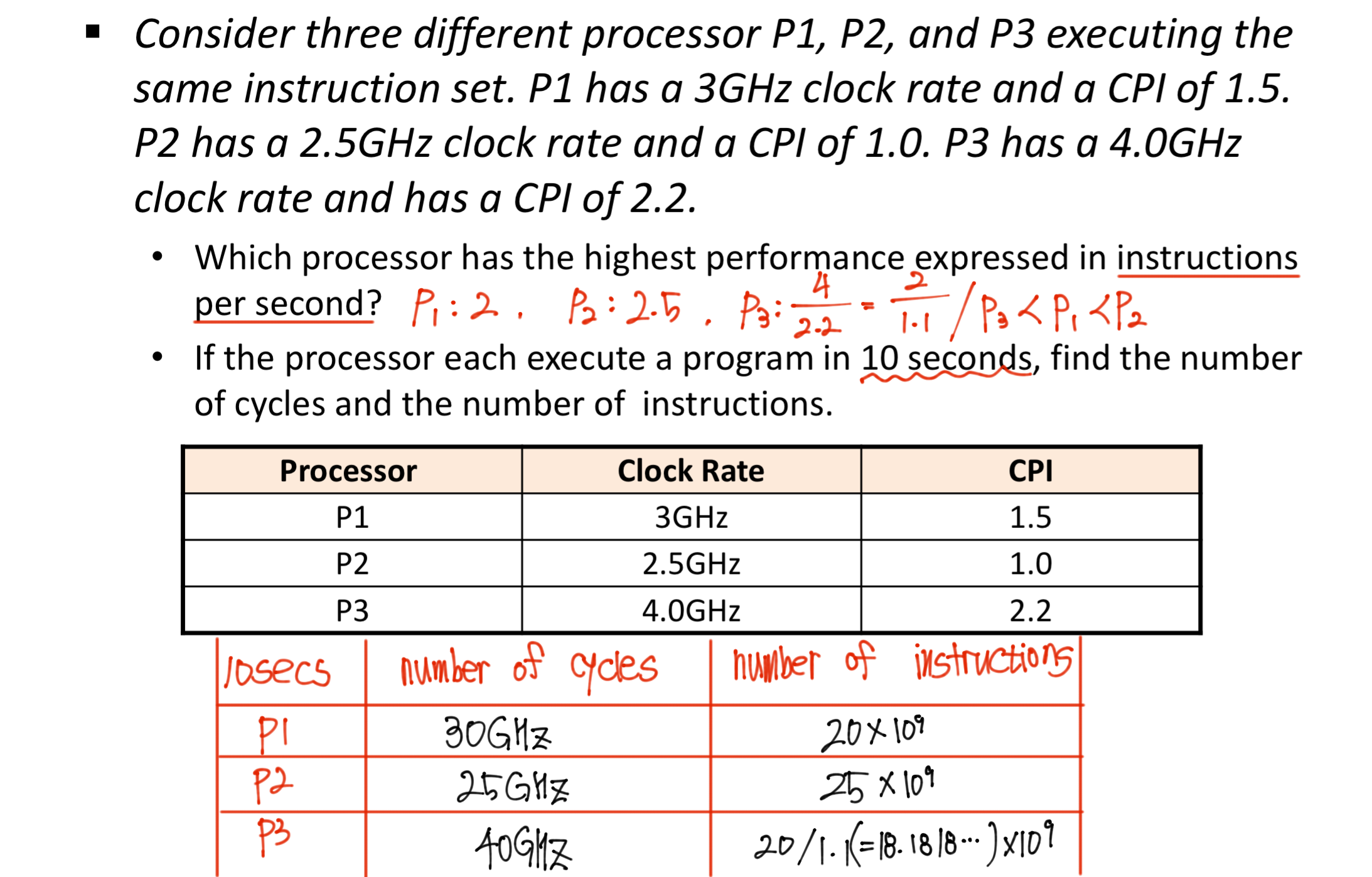
Factors Involved In the Cpu Time
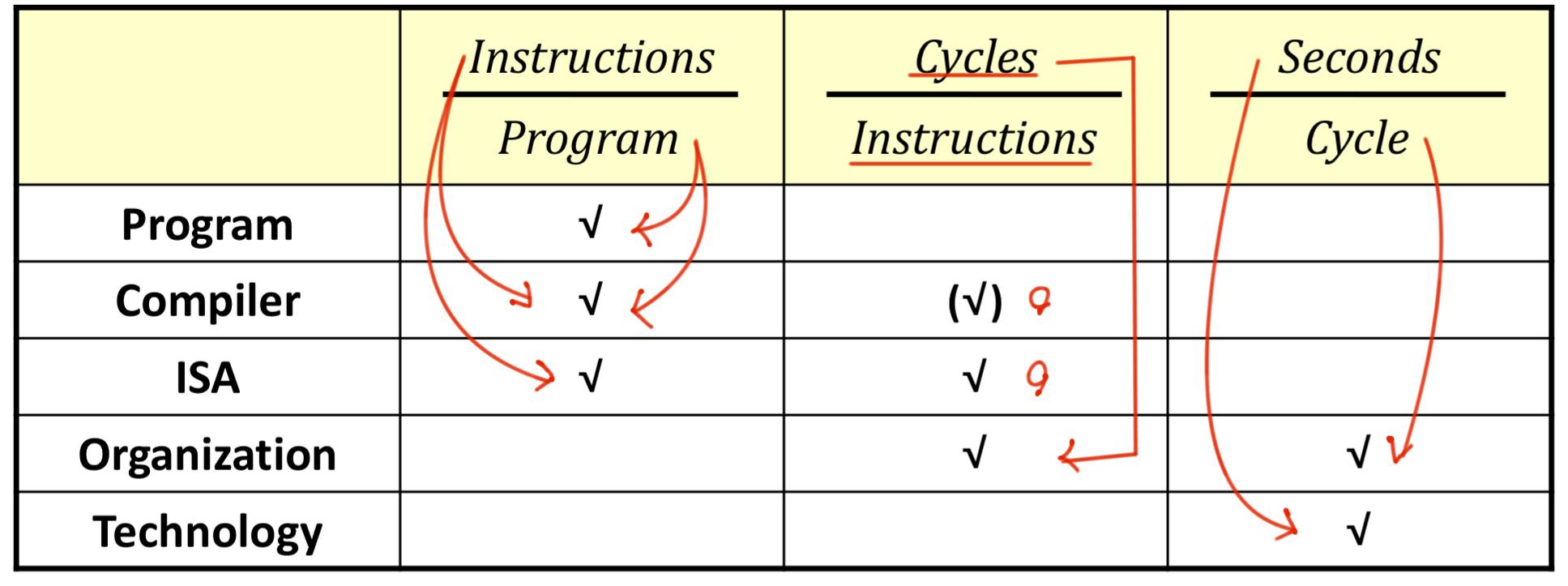
-
Program: 프로그램의 설계나 명령어 수는 CPU Time에 영향을 주지만, 직접적으로 사이클 수(CPI)나 클록 사이클 시간에는 영향을 미치지 않습니다.
-
Compiler: 컴파일러는 명령어 수와 CPI에 영향을 줍니다. 컴파일러가 얼마나 최적화되었느냐에 따라 프로그램이 더 적은 명령어로 수행되거나, 더 효율적인 명령어 세트를 사용할 수 있습니다.
-
ISA: ISA는 명령어 수(Instructions/Program)와 명령어당 사이클 수(CPI)에 영향을 미칩니다. 특정 ISA는 더 많은 명령어를 필요로 하거나, 더 복잡한 명령어를 포함할 수 있습니다.
-
Organization: CPU의 조직적 구조(예: 파이프라이닝, 캐시 설계)는 CPI에 큰 영향을 줍니다.
-
Technology: 반도체 기술 등 하드웨어 발전은 주로 클록 사이클 시간(Seconds/Cycle)에 영향을 줍니다.
MIPS (Million Instructions Per Seconds)
성능을 체크하는 방법 중에 CPU Time은 실행시간, MIPS는 백만개의 명령어를 실행하는데 얼마나 걸리는 지를 측정하는 기준입니다.
=
=
-
장점
- rough하게 성능을 실행시간에 반비례하게 지정
- MIPS는 값이 크면 성능이 더 좋다는 것을 나타냅니다.
-
단점
- 명령어의 능력을 고려하지 않음
- 동일한 컴푸터에서도 프로그램 간에 변동이 있음
- 심지어 성능과 반비례하는 경우도 생김
MFLOPS(million floating-point operations per second)
- 과학 프로그램과 게임에서 중요
- 정확하지 않음
Example
Question 1.
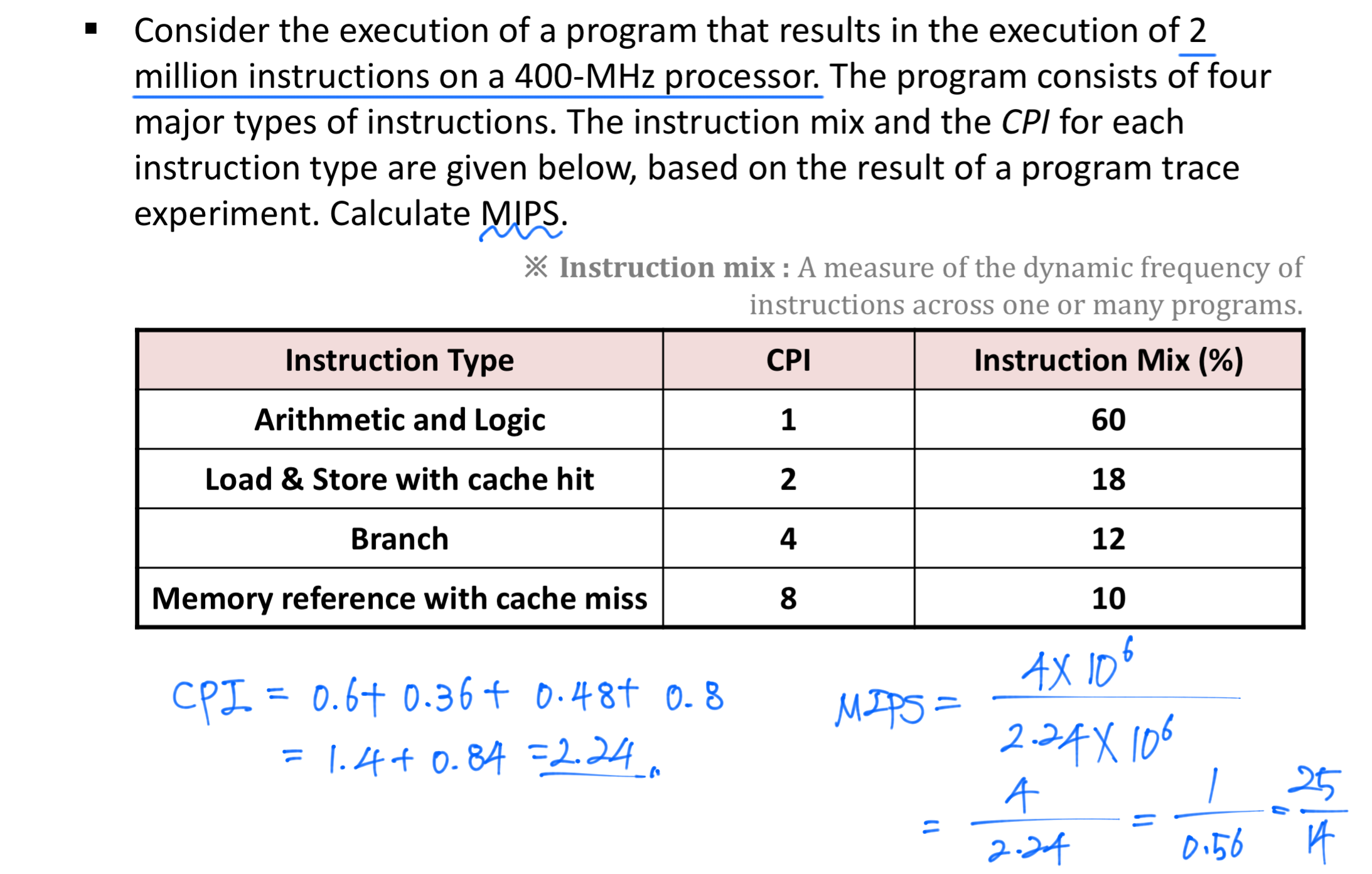
Question 2.

Ratio
성능 측정의 마지막 세번째 타입은 ratio입니다. 두 개의 비교군이 있을 때, A가 B 보다 n배(%) 빠르다/느리다 로 표현할 수 있습니다.
+) n order of manitude faster than 이라는 표현은 배 차이를 나타냅니다.
Benchmarks
시간을 측정해서 성능을 비교하는 방법도 있지만, 각 환경에서 동일한 프로그램을 실행해서 비교를 하는 방법도 있습니다.
특정 유형의 애플리케이션을 위해 다양한 칩/시스템 아키텍처에 접근(또는 비교)하도록 설계된 "프로그램"
- 구성 요소 또는 시스템에서 특정 유형와 "작업 부하"를 모방
- 도메인 특화
- 사용 및 기술의 변화를 반영하기 위해 몇 년마다 업데이트
- 고급 언어로 작성 및 쉽게 측정 가능한 타이밍을 위해 설계
- 바람직한 속성
- 관련성: 목표 도메인 내에서 의미가 있음
- 수용성: 공급업체와 사용자가 이를 수용
- 범위: 목표 도메인 내에서 중요한 요소를 과도하게 단순화하지 않음
- 이해 가능하고 확장 가능
두 가지의 산업 표준 벤치마크
- SPEC: CPU 성능
- TPC: OLTP(온라인 트랜잭션 처리) 성능
벤치마크가 완벽하지 않다는 것을 알고 있지만, 많은 사람들이 벤치마크로 장난질을 합니다.
Amdahl's Law
컴퓨터의 성능을 향상시키기 위해서 CPU 갯수를 늘리는 방법이 있을 수 있습니다. 하지만 CPU를 무작정 늘린다고 해서 드라마틱한 성능 차이가 나지 않음을 볼 수 있을겁니다. 그게 가능하다면 CPU를 1024개라도 붙여서 성능을 개선해보겠죠. 이를 증명하는 법칙이 바로 암달의 법칙입니다.
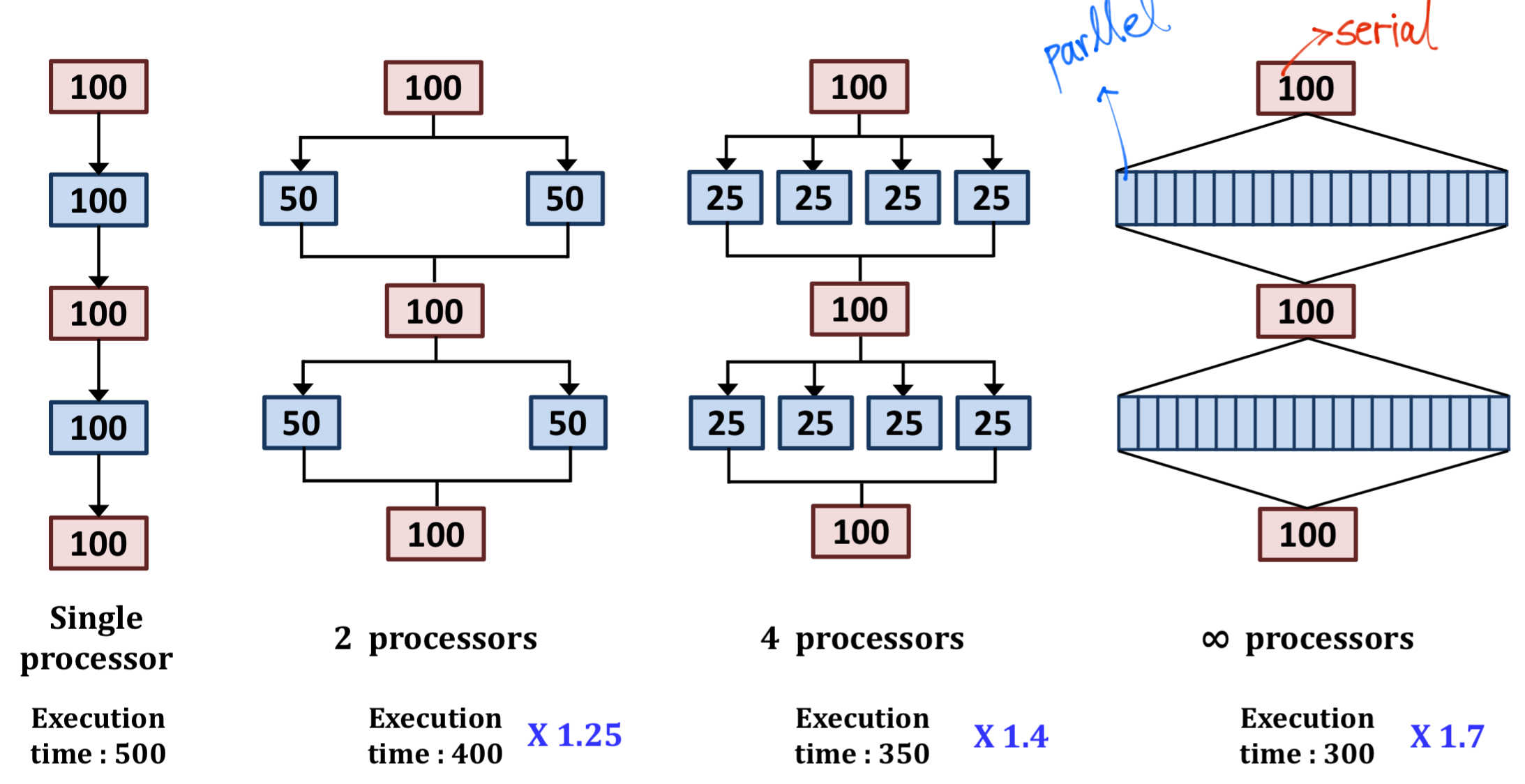
위의 그림이 사실 암달의 법칙의 전부라고 해도 무방합니다. 프로그램 내에서는 분명 병렬화가 되는 부분이 있고, 되지 않는 부분이 존재합니다. CPU가 아무리 많아도 병렬화가 되지 않는 부분의 성능을 개선할 수는 없죠.
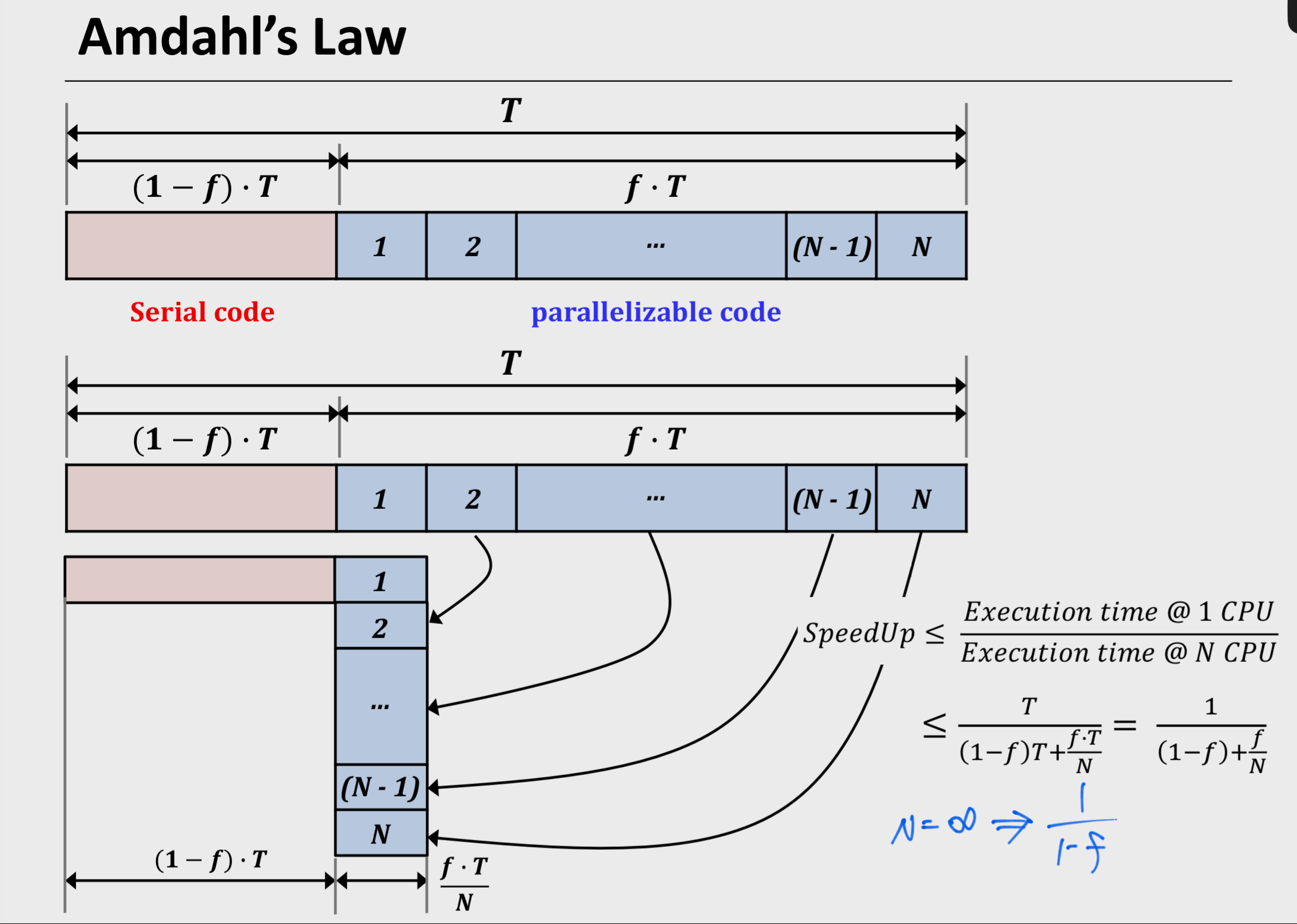
그런 맥락에서 암달의 법칙은 이러한 공식을 따릅니다.
S = 개선된 시간
f = 병렬화 가능한 프로그램의 (시간)비율
N = CPU의 개수
위의 공식에서 N을 무한대로 늘린다고 하여도 분모에 는 반드시 남는다는 사실을 알 수 있으며, 성능 향상의 최대치는 임을 알 수 있습니다.
이 때, f의 비율이 너무 작아도 CPU를 늘리는 것이 아무 의미가 없기 때문에, 코드는 병렬화가 가능해야한다는 결론을 낼 수 있습니다.
Example
Question 1.

Question 2.

Gustafuson's Law
- 구스타프슨 법칙은 암달의 법칙과 다르게 고정된 Task의 양이 아닌, CPU의 개수에 따라, 선형적으로 증가하는 Task에 대해서 선형적인 성능 개선을 보입니다.
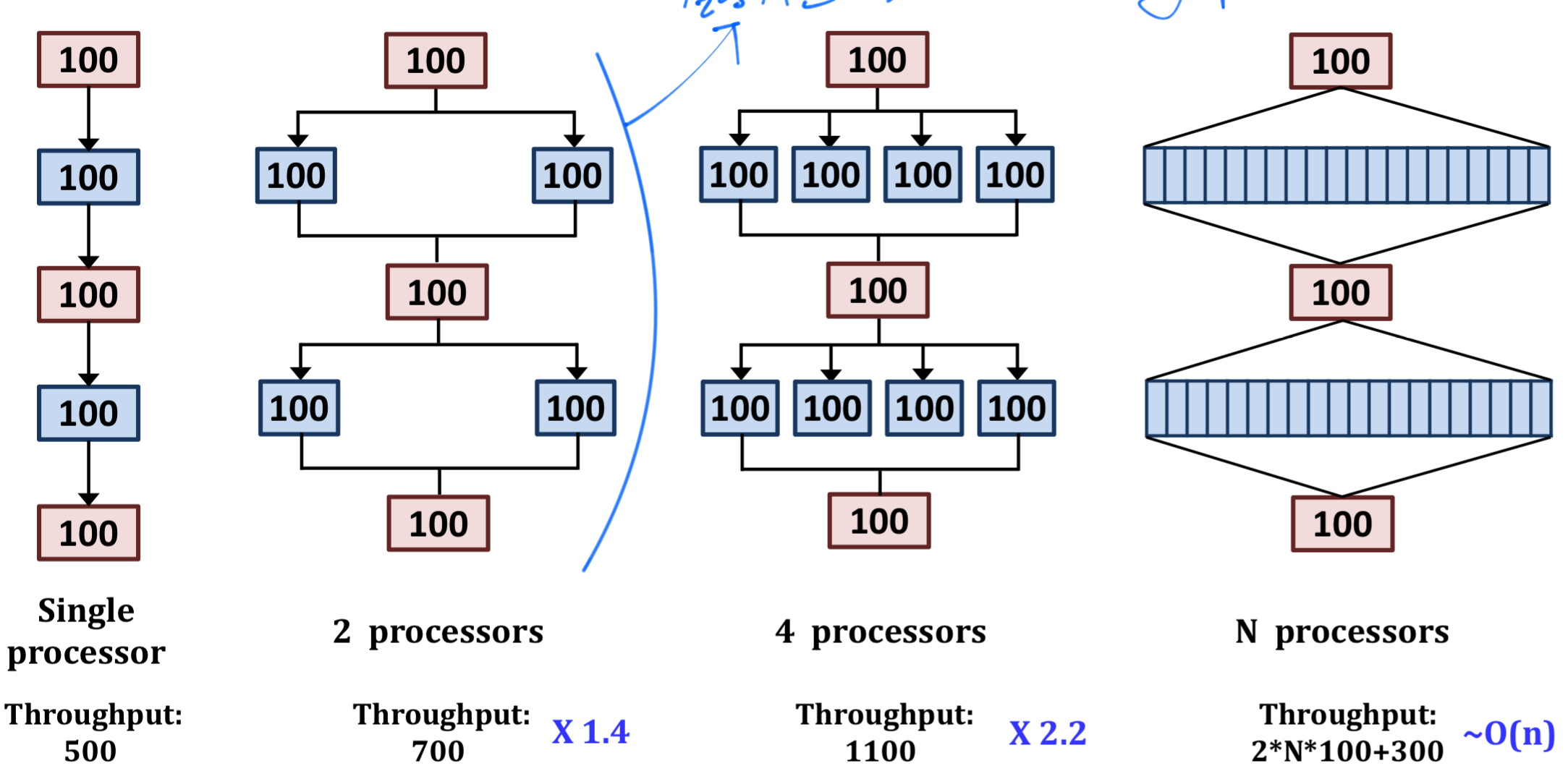
다만 암달의 법칙에서는 시간적인 성능 향상이 있는 반면에 구스타프슨의 법칙에서는 Throughput에 대한 성능 향상이 일어납니다.
그렇다고 물론 시간적 성능 향상이 일어나지 않는 것은 아닙니다. 처리할 일의 양이 늘어남에 따라 Throughput이 늘어나고, 동시에 처리할 수 있는 일의 양이 늘어나면 자연히 그에 비례하여 시간적 향상도 있기 마련입니다.
그러한 맥락으로 구스타프슨 법칙은 아래의 공식을 따릅니다.
