👉 배경
자바 언어를 사용하다 보면 다양한 데이터를 활용하기 위해서 List, Set, Map을 활용하는 경우가 많다. 이때 종류가 많기 때문에 사용을 할 때 현 상황에 맞는 Collection을 찾기 어렵다는 것을 느낀다. 상황에 맞게 Collection을 잘 선택하기 위해 글을 작성해 보았다.
🤔 자바 Collection은 무엇이 있을까?
List
- 순서가 있는 데이터의 집합, 데이터의 중복을 허용한다.
- 구현 클래스: ArrayList, LinkedList, Stack, Vector 등
Queue
- 선입선출을 기본으로 한다.
- 구현 클래스: Priority Queue, ArrayDeque 등
Set
- 순서를 유지하지 않는 데이터의 집합. 데이터의 중복을 허용하지 않는다.
- 구현 클래스: HashSet, TreeSet 등
Map
- 키와 값의 쌍으로 이루어진 데이터의 집합. 순서는 유지되지 않으며, 키는 중복을 허용하지 않고, 값은 중복을 허용한다.
- Map은 Collection 인터페이스를 상속하지 않음에도 불구하고, 일반적으로 Collection을 이야기 할때 항상 포함된다.
- 구현 클래스: HashMap, TreeMap, Hashtable, LinkedHashMap 등
🔗 자바 Collection 구조
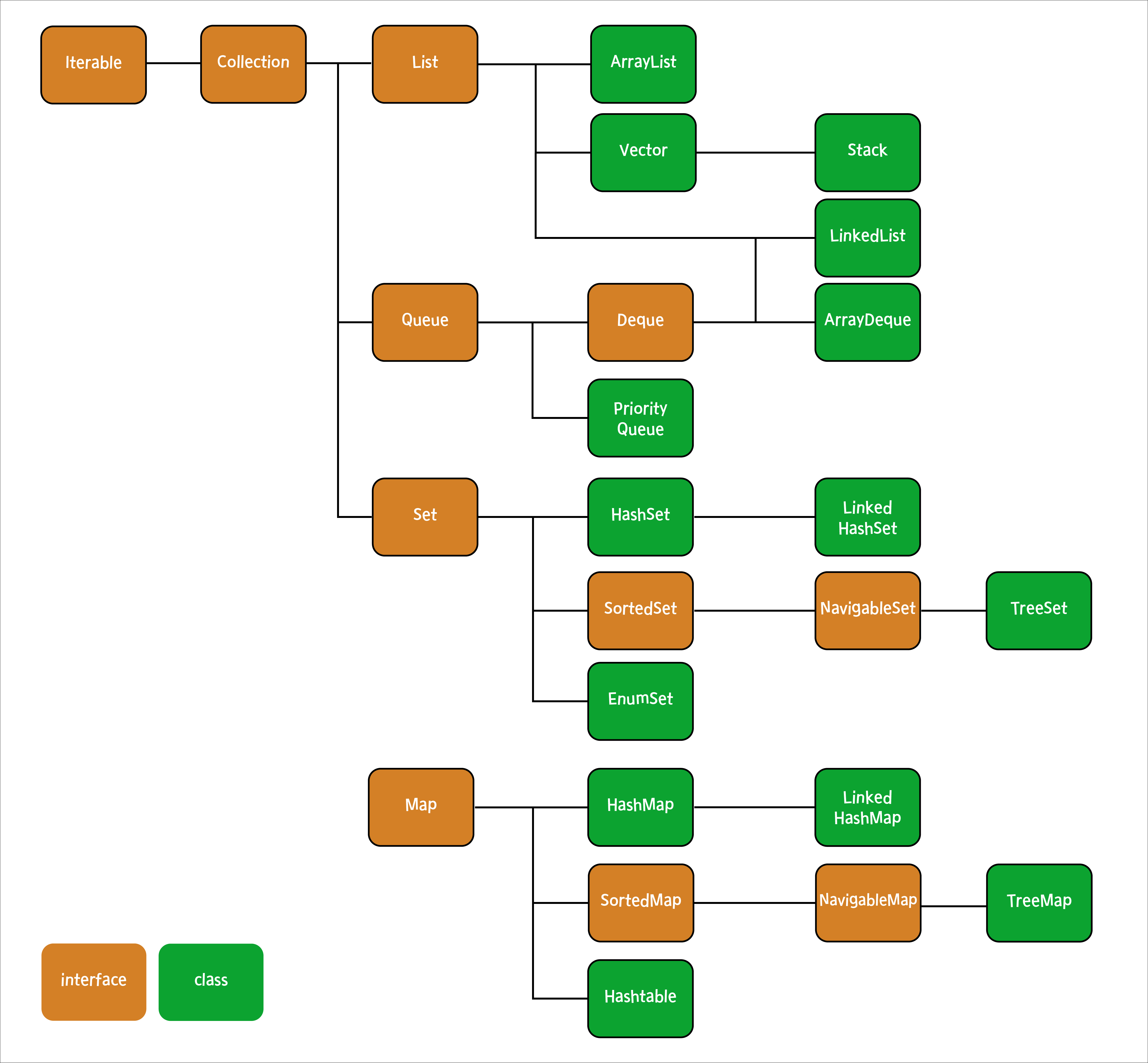
📝 구현 클래스들의 특징
List
ArrayList
- 배열을 활용한 클래스이지만 사이즈에 대해서 좀 더 자유롭다. 그 이유는 정해진 크기보다 더 많은 요소가 들어가야 한다면, 새롭게 큰 배열을 만들어서 기존의 데이터를 복사하는 방식을 사용하기 때문이다.
- 일단 확장하고 나면 요소들을 삭제해도 배열의 크기는 줄어들지 않는다.
- 배열이기 때문에 요소들에 인덱스를 통한 접근이 가능하다.
- List 중간에 추가 및 삭제가 이루어진다면 탐색을 해야하기 때문에 부하가 존재한다.
LinkedList
- 배열을 이용하지 않고 양방향 포인터 구조로 다음 노드를 지정하는 방식을 사용한다.
- 중간 데이터의 삽입, 삭제가 수월하다.
- 스택, 큐, 덱을 만들기 위한 용도로 자주 사용된다.
- 배열을 사용하지 않기 때문에 인덱스를 통한 접근이 불가능하다.
Vector
- 동적 배열을 제공하고, 표준 배열보다 느리지만 많은 움직임이 필요한 프로그램에서 유용하다.
- 현재는 잘 쓰이지 않고, ArrayList를 사용하는 것이 권장된다.
Stack
- 후입선출을 기반
- Collection 프레임워크 이전부터 존재했기 때문에 Vector로부터 상속받아 구현된다.
Queue
PriorityQueue
- 저장한 순서에 관계없이 우선순위가 높은 것부터 리턴한다.
- null은 저장할 수 없다.
- 배열을 사용하여 각 요소를 힙 형태로 저장한다.
ArrayDeque
- 마치 Stack과 Queue를 합쳐 놓은 양방향 큐이다.
- 크기가 조정되는 배열이고 양쪽 끝에서 요소를 추가하고 제거하는 구조이다.
Set
HashSet
- 요소들을 저장할 때 동일한 순서로 삽입되는 것을 보장하지 않는다.
- 만약 중복된 요소를 저장하려고 한다면 false를 반환하며 실패를 알린다.
- null을 저장할 수 있다.
LinkedHashSet
- HashSet과 유사한 특징을 가지지만 저장순서를 유지한다는 점이 다른 특징이다.
TreeSet
- 이진 검색 트리 자료구조의 형태로 데이터를 저장한다.
- 중복된 데이터의 저장을 허용하지 않으며, 구현된 정렬된 위치에 저장하므로 저장순서를 유지하지도 않는다.
- 저장되는 객체가 Comparable을 구현하던지, TreeSet에게 Comparator를 제공하여 정렬하는 방법을 알려주어야 한다.
- 데이터를 저장하는데 정렬 방법을 따라야 하기 때문에 시간이 걸리지만, 저장한 데이터에 대해서는 검색과 정렬에서 성능이 좋다.
EnumSet
- 데이터를 Enum 타입으로 사용하기 위한 Set이다.
Map
Hashtable
- Hashtable은 최초로 등장한 Map이기에 이전 Java 결과물들의 지원을 위해 존재하는 이상의 의미를 현재는 가지질 않는다.
- Hashtable과 HashMap의 관계는 Vector와 ArrayList의 관계와 같아서 새로운 버전인 HashMap을 사용하는 것이 권장된다.
HashMap
- 데이터를 키(key)&값(value) 형태로 저장한다.
- 키와 값 모두 Object 타입으로 모든 객체가 저장될 수 있지만 일반적으로 키는 주로 String을 사용한다.
- 키값은 중복이 허용되지 않지만, 값은 중복을 허용한다.
- hashing(키에 산술적인 연산을 적용하여 항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근하는 방식)을 사용하므로 많은 양의 데이터를 검색하는데 뛰어난 성능을 보인다.
LinkedHashMap
- HashMap을 상속하여 구현되었다.
- HashMap과 같은 특징을 지니지만 저장순서를 유지한다는 점이 다른 점이다.
TreeMap
- 이진 검색 트리를 활용하여 데이터를 저장한다.
- Key의 Natural ordering에 따라 순서가 정해지며, 필요할 경우 생성자에 제공된 Comparator에 의하여 정렬 순서가 정해지도록 할 수 있다.
EnumMap
- key 값을 Enum 타입으로 사용하는 Map이다.
- Enum 클래스의 index 순서에 따라서 Map의 저장 순서가 결정된다.
- value 값에 접근할 때 Enmun의 ordinal()를 사용하여 index로 접근하기에 성능이 좋다.
✏️ 요약
기본적으로 배열을 활용하기 보다는 더 많은 메서드를 활용할 수 있는 Collection을 이용하자!
Collection을 선택할 수 있는 간단한 기준은 다음과 같다.
List 사용
- 기본적 사용: ArrayList
- 후입선출의 기능이 필요하면?: Stack
- 추가, 삭제기능 향상을 위해선?: LinkedList
- List에서 검색기능을 향상 시키고 싶을 때 Set과 Map을 사용
Set, Map 사용
- 데이터 삽입 시 중복을 피하고 싶다면?: Set
- Key, Value 구조의 형태가 필요하다면?: Map
- 해쉬 기능을 사용하며, 다른 부가기능이 필요 없는 경우: HashMap, HashSet
- Tree 구조를 활용하여 데이터 입력 시 정렬이 필요하다면?: TreeMap, TreeSet
- 저장 순서를 유지하고 싶다면?: LinkedHashMap, LinkedHashSet
Enum을 사용 중이라면?
- EnumSet, EnumMap 사용을 고려하자
📎 Reference
- 자바의 정석(남궁 성 저): Chapter 11 컬렉션 프레임웍
- 프로그래밍/JAVA [JAVA] 컬렉션(Collection)이란?
- 조금 늦은, IT 관습 넘기 (JS.Kim) : Collection
- [자료구조] 코드로 알아보는 java의 EnumMap

하루하루 조금씩 발전하려는 개발자 입니다.