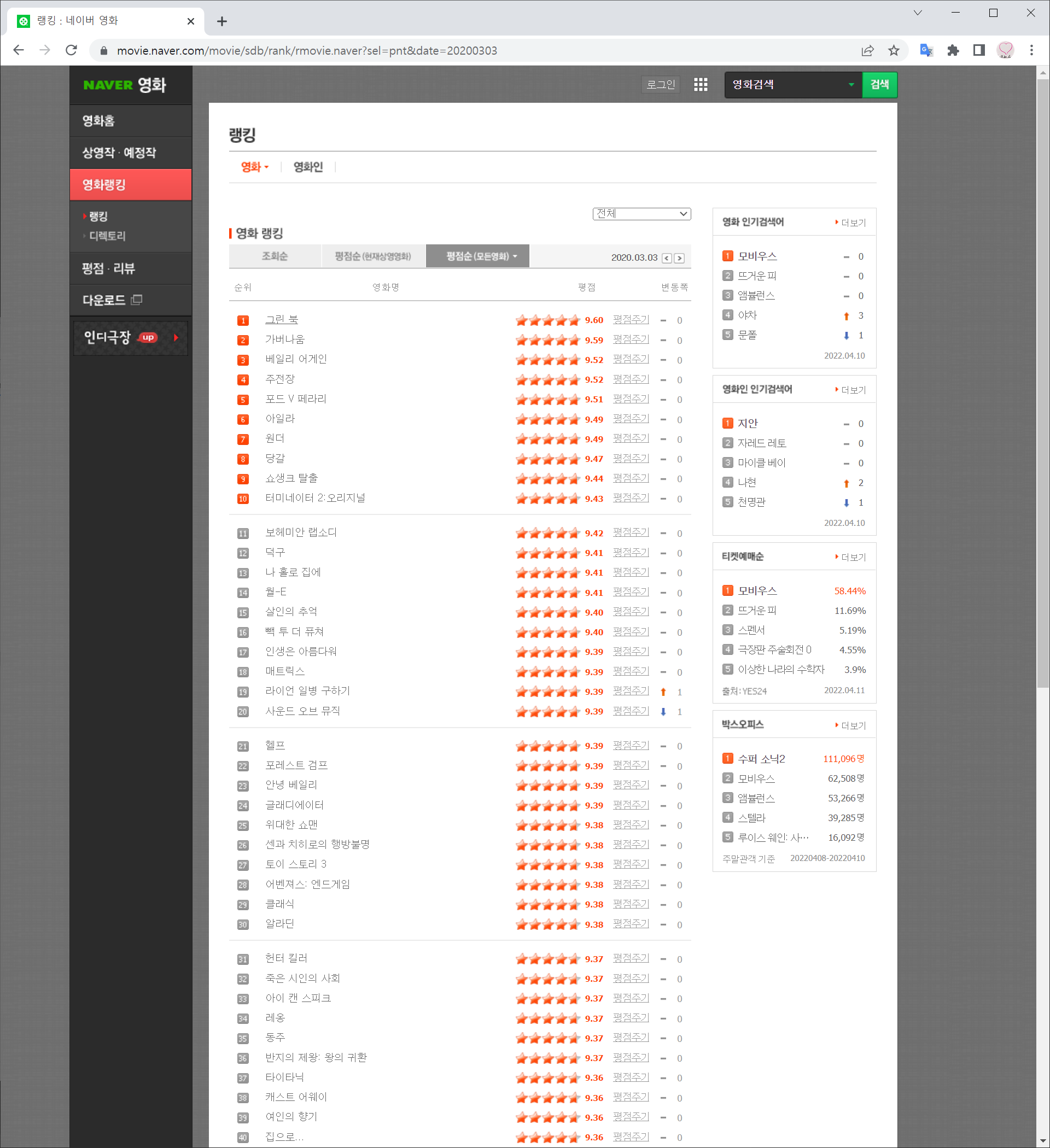
- beautifulsoup4 패키지 설치
패키지 설치는 -> https://velog.io/@yh271/webbase17 참조
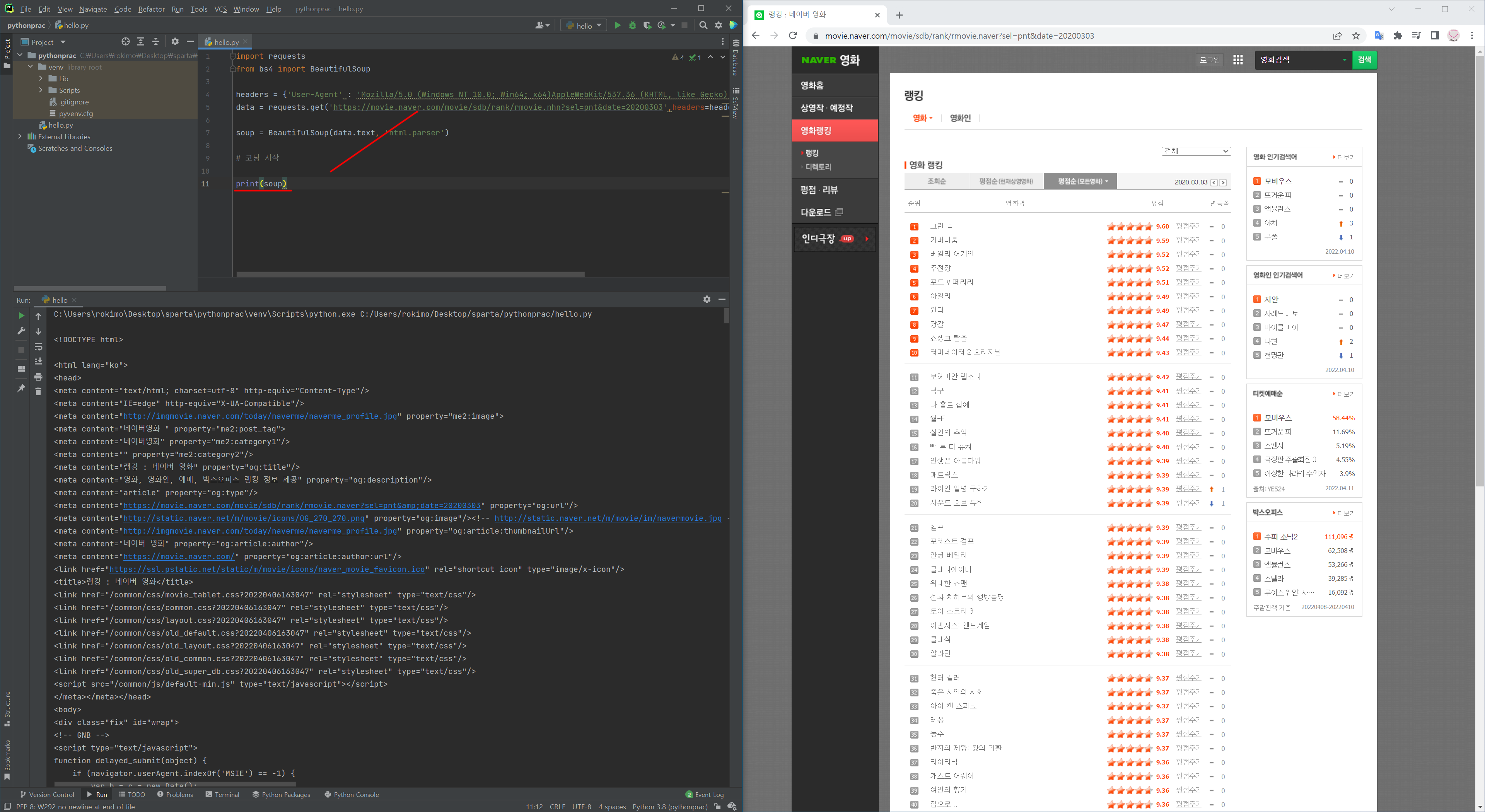
requests로 요청하고, beautifulsoup으로 솎아낸다.
- 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 코딩 시작- print(soup)
요청받은 url의 코드를 가져온다.
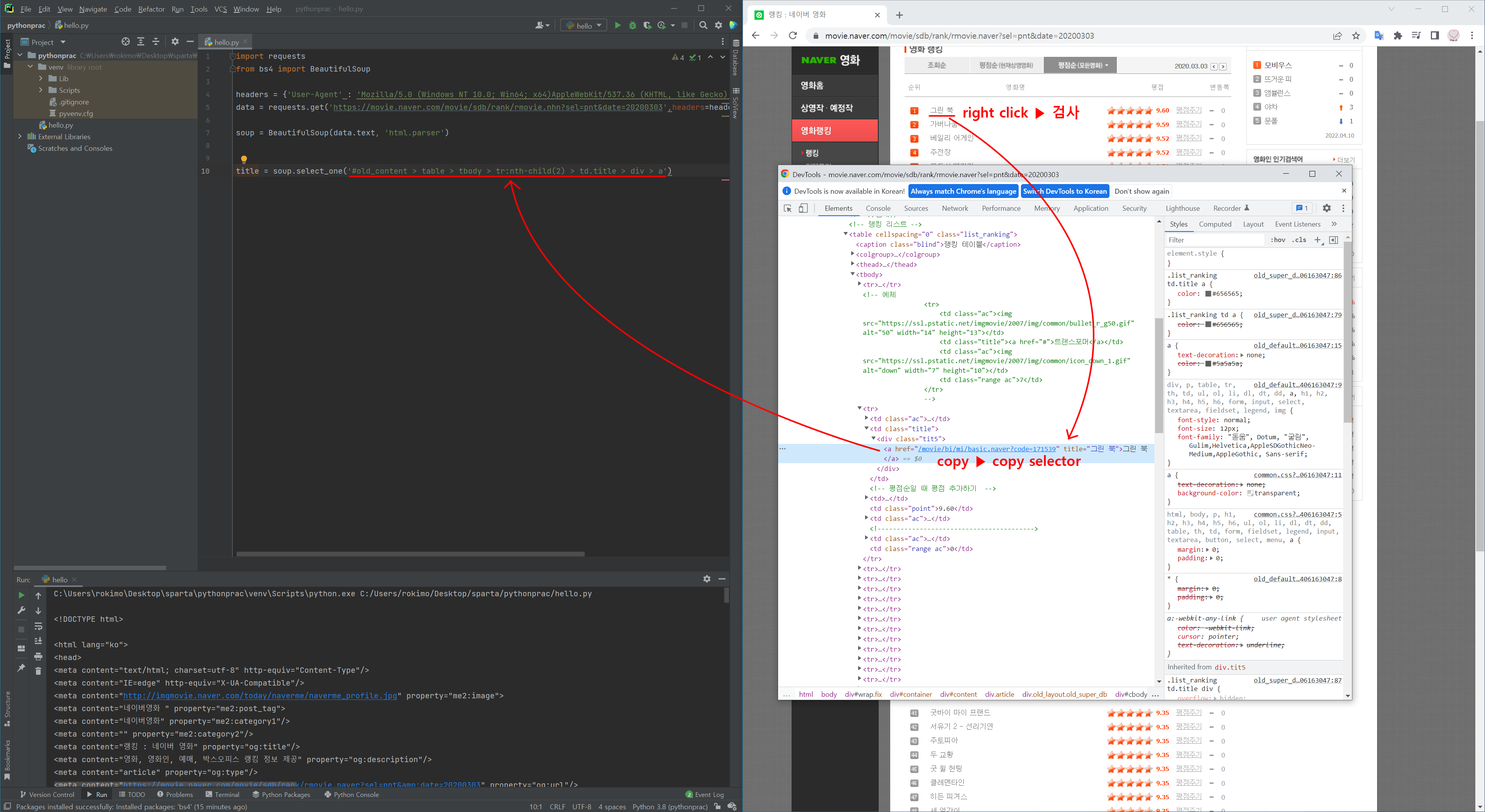
- 선택자(selector)
- hello.py
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
# 선택자
title = soup.select_one('#old_content > table > tbody > tr:nth-child(2) > td.title > div > a')
# 선택자가 선택한 내용 출력
print(title)
# 텍스트 출력
print(title.text)
# 태그 출력
print(title['href'])Run 결과
C:\Users\rokimo\Desktop\sparta\pythonprac\venv\Scripts\python.exe C:/Users/rokimo/Desktop/sparta/pythonprac/hello.py
<a href="/movie/bi/mi/basic.naver?code=171539" title="그린 북">그린 북</a>
그린 북
/movie/bi/mi/basic.naver?code=171539
Process finished with exit code 0
- 반복문
크롤링 전략 세우기: 한 줄씩 검사하며 동일한 종목을 반복하여 가져온다.
아래에서는<tr>...</tr>이 한 줄에 해당된다.
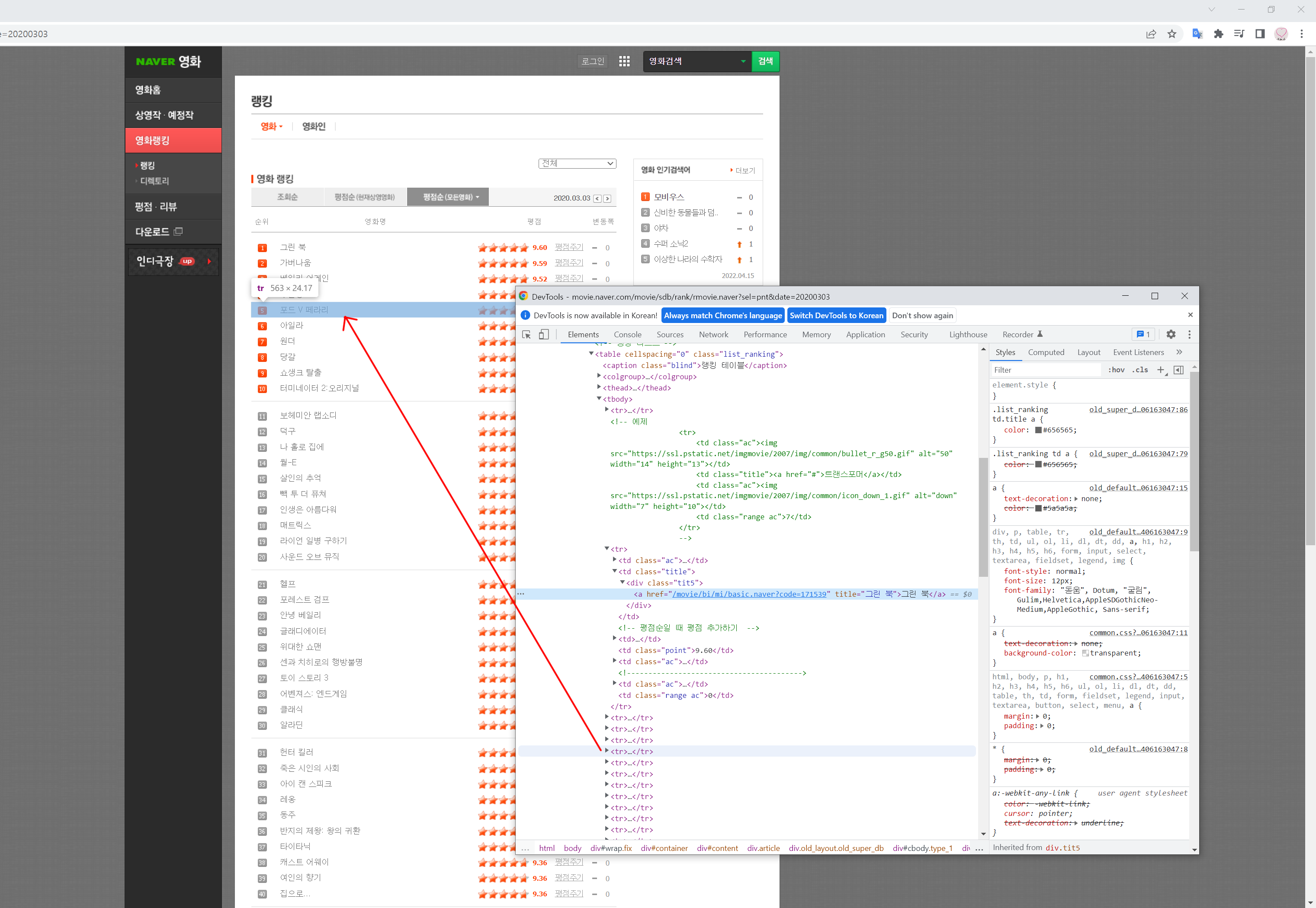
tr.select_one(): tr 내의 한 요소를 선택할 수 있음.
#ex)
tr.select_one('td.title > div > a') - hello.py
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#모든 tr을 가리킴
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
title = a_tag.text
print(title)Run 결과
C:\Users\rokimo\Desktop\sparta\pythonprac\venv\Scripts\python.exe C:/Users/rokimo/Desktop/sparta/pythonprac/hello.py
그린 북
가버나움
베일리 어게인
주전장
포드 V 페라리
아일라
원더
당갈
쇼생크 탈출
터미네이터 2:오리지널
보헤미안 랩소디
덕구
나 홀로 집에
월-E
살인의 추억
빽 투 더 퓨쳐
인생은 아름다워
매트릭스
라이언 일병 구하기
사운드 오브 뮤직
헬프
포레스트 검프
안녕 베일리
글래디에이터
위대한 쇼맨
센과 치히로의 행방불명
토이 스토리 3
어벤져스: 엔드게임
클래식
알라딘
헌터 킬러
죽은 시인의 사회
아이 캔 스피크
레옹
동주
반지의 제왕: 왕의 귀환
타이타닉
캐스트 어웨이
여인의 향기
집으로...
굿바이 마이 프랜드
서유기 2 - 선리기연
주토피아
두 교황
굿 윌 헌팅
클레멘타인
히든 피겨스
세 얼간이
쉰들러 리스트
울지마 톤즈
Process finished with exit code 0