앞서 수행한 코드들
- hello.py (영화정보 웹스크래핑)
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
print(rank,title,star)- dbprac.py (insert / find / update / delete)
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
# insert / find / update / delete
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
same_ages = list(db.users.find({'age':21},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})- 웹스크래핑 결과 저장하기
앞서 했던 영화정보 웹스크래핑 hello.py의 정보를 dbsparta에 저장
- hello.py에 mongodb 사용을 위해서 다음을 임포트한다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta- dbprac.py: 변수에 딕셔너리를 정의하고 저장한다.
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)- hello.py
import requests
from bs4 import BeautifulSoup
#mongodb 사용을 위해서 다음을 임포트한다.
from pymongo import MongoClient
client = MongoClient('localhost', 27017)
db = client.dbsparta
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.nhn?sel=pnt&date=20200303',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a_tag = tr.select_one('td.title > div > a')
if a_tag is not None:
rank = tr.select_one('td:nth-child(1) > img')['alt']
title = a_tag.text
star = tr.select_one('td.point').text
doc = {
'rank':rank,
'title':title,
'star':star
}
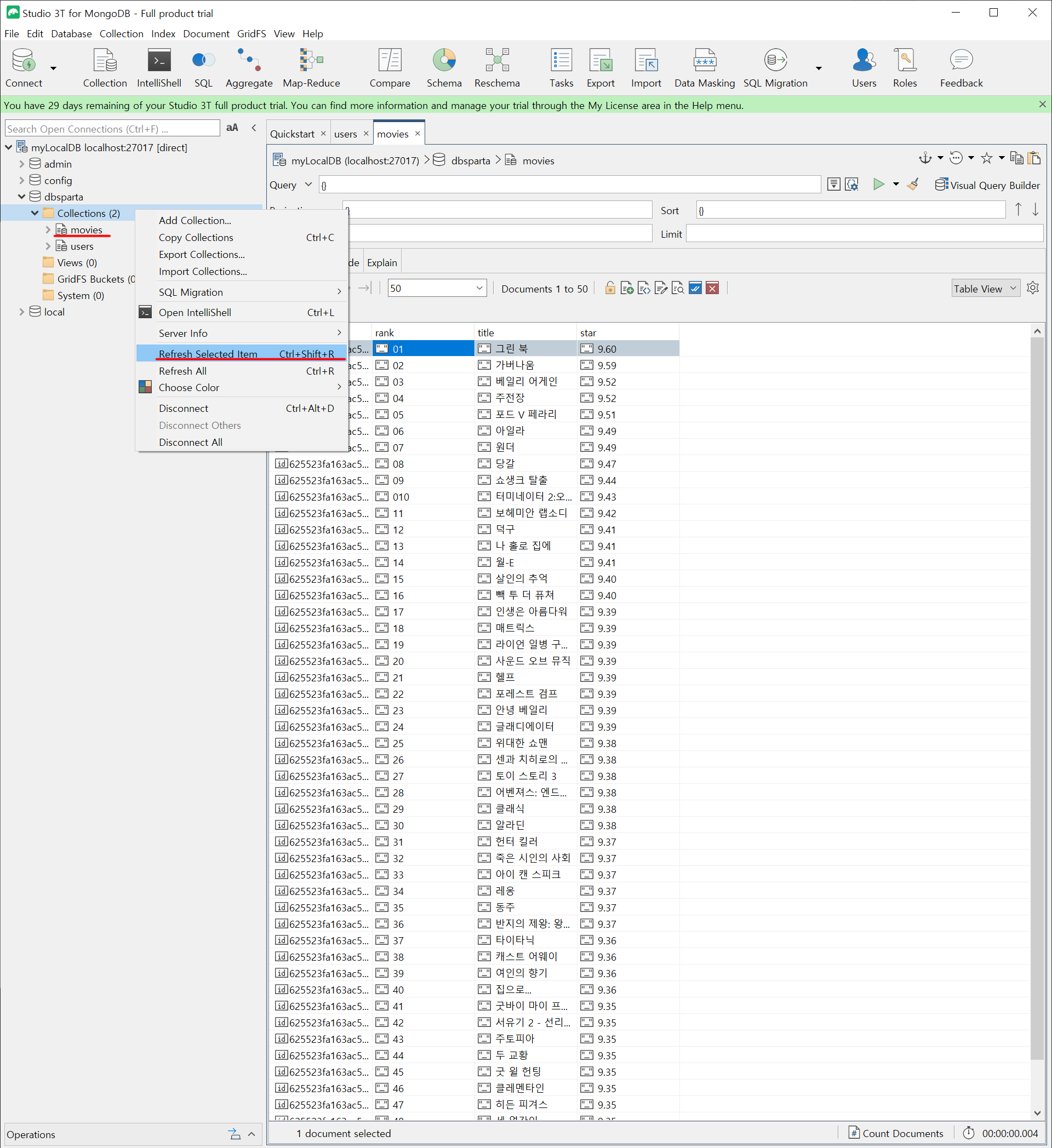
db.movies.insert_one(doc)Collections를 Refresh 하면 movies 콜렉션이 생성되고 오른쪽 테이블에 데이터가 출력된다.