Intro
그동안 정처기 실기 준비 그리고 백신 부작용으로 인해서 포스팅을 꾸준히 하지 못했다. 이번에 object detection 대회, 정처기 공부, 몸조리 여러가지가 겹치면서 정말 바쁜 3주를 보낸 것 같다. 이번 object detection을 통해 느낀점을 간략하게 적어보려고 한다. 또 앞으로는 꾸준히 포스팅을 할 예정이다. (내일 백신2차 맞으러 가서 혹시 또 모르겠다 ..)
대회 개요
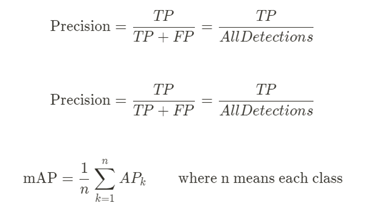
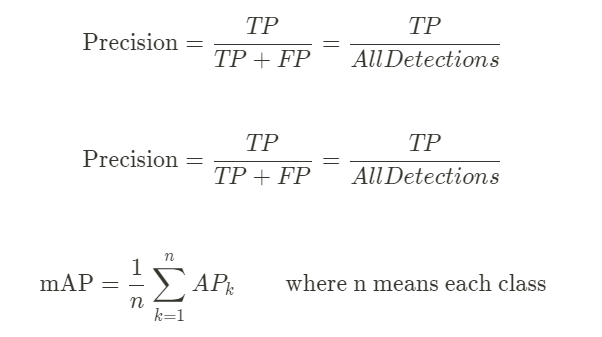
이번 대회는 대량 생산, 대량 소비의 사회에서 대두되고 있는 환경문제를 해결하기 위한 쓰레기 object detection 대회였다. 쓰레기를 10개의 클래스로 나눠 사진에 있는 쓰레기 객체를 탐지하고 그 쓰레기의 클래스를 분류하는 것이 대회의 핵심 목표였다. Input으로는 쓰레기 객체가 담긴 이미지와 bbox 정보가 사요되었고 output으로는 bbox 좌표와 confidence score 값이 출력되는 구조였다. 평가 방법은 object detection competition에서 흔히 사용하는 mAP 스코어를 사용하였다.
대회 과정
팀원은 5명으로 각자의 역할을 따로 나눠서 진행하지는 않았다. Github repository에서 공동의 baseline 코드를 작성하고 그 baseline을 기반으로 코드를 덧붙이는 식으로 진행하였다. 기존의 baseline에는 2개의 framework, mmdetection 그리고 detectron이 기본적으로 존재하였다. 가장 초반에는 boostcamp에서 제공해주는 3개의 sample code를 실행하여 어떤 framework가 가장 성능이 좋고 base framework로 선정하면 좋을지 판단하는 시간을 가졌다. 3개의 sample code는 각각 vanilla pytorch code, mmdetection, detectron으로 구성되어 있었고 가장 범용적이고 내장되어 있는 모델도 다양한 mmdetection을 최종적으로 선정하였다.
Object detection은 우선 dataset의 구조를 파악하는 것이 가장 중요하였다. 기본적인 classification 작업과는 다르게 dataset format이 여러가지 존재하였고 자신의 dataset을 format에 맞게 구성할 필요가 있었다. 사전에 주어진 dataset의 format은 COCO format이었고 해당 format에 맞춰 모델을 학습시켜야 했다. Object detection은 classification뿐만아니라 bbox localization의 작업도 필요하기 때문에 JSON 파일 안에 bbox와 label이 모두 포함되어 있었다.
모델 학습은 팀원 각자 다른 모델을 선정해서 수행하기로 하였다. Object detection은 모델의 학습시간이 길어서 빠른 학습과 추론이 힘들기 때문에 다양한 모델을 시도해보기 위해서는 각자 다른 모델을 선정할 필요가 있었다. 가장 처음으로 mmdetection에 내장되어 있는 faster-rcnn을 시도해 보았다. 모델의 성능을 높이기 위해서 mmdetection 공식 github을 많이 참고 하였고, 훈련 gpu 개수와 learning rate가 중요한 상관관계에 있다는 점을 파악할 수 있었다.

Mmdetction에 내장되어 있는 모델들은 기본적으로 gpu 8대에 각각 batch size 2개씩(총 batch size 16) 올라가 수행되었기 때문에 현재 우리의 환경을 고려해서 그만큼 learning rate를 조정해 줄 필요가 있었다. 우리의 환경은 gpu가 1대였기 때문에 batch size를 조절하는 만큼 learning rate의 크기를 조정해야 했다. 이 설정을 맞춰주니 성능이 크게 향상하는 것을 알 수 있었다.
Fatser-rcnn은 비교적 오래된 모델이기 때문에 더 성능을 높이기 위해서는 다른 모델을 이용해야 했고 비교적 가장 최근 발표된 모델인 swin을 채택하였다. Swin은 모델의 backbone에 transformer를 붙인 모델로 FLOPS가 많은 만큼 성능도 뛰어났다. Swin에도 여러가지 버전이 있는데 swin-t, swin-s, swin-b, swin-l 순으로 연산량이 많아지고 성능 역시 높아졌다.
단일모델의 성능을 높이는 것도 중요하지만 대회에서는 결국 마지막에 결국 앙상블을 시도하기 때문에 여러가지 모델을 학습하는 것도 매우 중요했다. 따라서 기존에 학습하던 2 stage model이 아닌 1 stage model을 시도해 볼 필요가 있었다. 많은 모델들 중 아직 공식적으로 논문이 공개되지는 않았지만 code는 공개된 YOLOv5를 선정하였다. YOLOv5는 1 stage 모델은 성능이 높지는 않았지만 빠르게 학습할 수 있다는 장점이 있었다. 하지만 대회인만큼 속도보다는 성능에 치중하여 YOLOv5중에서도 가장 느리고 성능이 좋은 YOLOv5x모델을 선정해서 학습하였다. YOLOv5는 새로운 framework이기 때문에 dataset format을 그에 맞게 바꿔줄 필요가 있었다. COCO format은 json을 사용하는데 반해 YOLO format은 yaml을 사용하였다.
대회 막바지에 이르러 수도라벨링과 앙상블을 시도하였다. 앙상블은 눈에 띄게 성능이 좋아지는 것이 보였지만 수도라벨링을 통해서는 그렇게 큰 성능 개선이 부각되지는 않았다. 또한 우리는 수도라벨링된 data를 학습시켜 다시 앙상블하는 과정을 거쳤지만 과적합 때문인지 그렇게 큰 성능개선을 확인하기는 힘들었다. 마지막 순위는 7위로 마무리 했고 초중반에 높은 성적을 유지했던 우리였기 때문에 아쉬움이 많이 남는 대회였다.
대회 회고
대회를 진행하면서 근본적인 모델에 대해 의문이 드는 점이 많았지만 많은 모델을 학습해보기 위해 제대로 숙지하고 학습을 하지 못했다는 점이 가장 아쉬운 것 같다. 프레임워크가 정말 잘 구성되어 있어서 모델에 대한 깊은 이해가 없이도 학습하는 것이 쉽고 간단하였다. 앙상블을 진행하는 과정에서도 앙상블의 깊은 이해가 부족했다고 느꼈다. 마지막에 성능을 짜내기 위해서 앙상블을 여러 번 시도했는데 과적합때문인지 성능은 오르지 않고 제자리에 멈춰 있었다.
또한 다양한 resolution으로 학습하지 않은 것도 아쉬움이 많이 남는다. 우리는 원래 이미지 크기인 1024x1024에 맞춰서 계속 학습을 하였는데 resolution을 키워서 더 큰 이미지에 학습을 시킨 팀이 좋은 성적을 거두었다. 이는 성능을 올릴 때 기본적으로 가장 많이 사용하는 방법인데 이를 시도해보고자 생각은 했지만 시간이 부족해 실천하지 못한점에서 아쉬움이 더 많이 남는 것 같다.
이번 대회에서 github을 정말 많이 읽은 것 같다. Framework를 파악하는데 있어서 정말 많은 도움이 되었다. 하지만 대회는 성능을 높이는 것이 궁극적인 목표이고 이를 위해서 kaggle을 많이 활용할 필요가 있다고 느꼈다. Gtihub을 통해 library를 이해하는 것은 큰 도움이 되지만 성능의 개선을 위한 방법은 자세히 나와있지 않다. framework들이 대회를 위해 만들어진 것이 아니기 때문에 대회에서는 kaggle을 읽는 습관이 매우 중요하다는 것을 다시 한번 느꼈다.
