
데이터베이스를 선정할 때의 고려대상
여러분은 데이터베이스를 선정할 때에 어떤 기준을 가지고 선정하시나요?
아래 3가지는 데이터베이스를 선정할 때에 항상 고민하게 되는 요소들 입니다.
1️⃣ 확장성
확장성은 데이터베이스를 고르는 데 아주 중요한 요소다. 데이터베이스마다 확장 방법이 다르다. 예를 들어 관계형 데이터베이스는 수평적 확장에 어려움을 겪을 수 있지만 NoSQL 데이터베이스는 수평적 확장에 뛰어나다. 데이터베이스를 선택할 때는 예상 성장률과 확장을 얼마나 잘 처리할 수 있는지를 고려해야 한다.
데이터베이스 확장을 잘하려면 단순히 서버를 더 추가하는 게 아니라 시스템의 설계와 아키엑쳐(schema 등등 포함)을 잘 이해해야 한다.
2️⃣ 성능
쿼리 효율성과 write 및 read 성능 간의 균형을 고려해야 한다. 읽기(read) 작업에 최적화된 데이터베이스도 있고 쓰기(write) 성능을 우선시하는 데이터베이스도 있다. NoSQL은 전반적으로 심플한 데이터 모델과 schema 덕분에 쓰기에 최적화되어 있고, 관계형 데이터베이스는 join과 aggregation 등 좀 더 복잡한 쿼리에 최적화되어 있다. 시계열 데이터베이스는 타임시리즈 데이터에 적합하다.
3️⃣ Consistency
데이터베이스의 정보가 정확하고 일관성 있어야 한다. 일관성을 달성하기 위해 데이터베이스는 종종 ACID 속성과 CAP Theorem에 의존한다. 데이터베이스에 따라 이러한 측면의 우선순위가 달라지므로 시스템을 설계할 때 요구사항을 정확하게 파악하고 그에 알맞는 데이터베이스를 선택해야 한다.
출처 - 데이터베이스를 고를 때 고려해야 하는 요소 | 킴코더님
일단 위 3가지 요소를 모두 100% 완벽하게 만족시킬 수 있는 데이터베이스는 사실 없습니다. (있으면 너무 좋겠지만..)
다만 목적에 더 적합한 데이터베이스를 찾고, 3가지에 있어서 더 만족스러운 결과를 만들 수 있게끔 변화시킬 수 있는 것이 개발자가 할 수 있는 최선의 방법이라고 생각합니다.
이전 포스팅에서 PlanetScale과 Prisma에 대한 글을 작성하였는데, 이러한 노력들도 데이터베이스에 대한 만족도를 높일 수 있는 방법중 하나입니다.
이전 포스트 -> PlanetScale을 프리즈마로 효율성 높여보기
위 글에서처럼 PlanetScale은 관계형 데이터베이스 임에도 수평적 확장을 쉽게 할 수 있게 만들어주는 데이터베이스입니다.
하지만, PlanetScale은 Consistency에서 개발자의 꼼꼼함을 요구하고, Prisma사용으로 편리함은 늘어났지만, Prisma는 SQL의 성능 부분에서 아쉬운 부분이 많은 ORM이며, 데이터베이스 함수나 복잡한 SQL문을 만들어내기에 Prisma의 쿼리빌더는 너무 빈약한 느낌이 있습니다.
그렇다면 이부분을 어떻게 해결해 볼 수 있을까요?
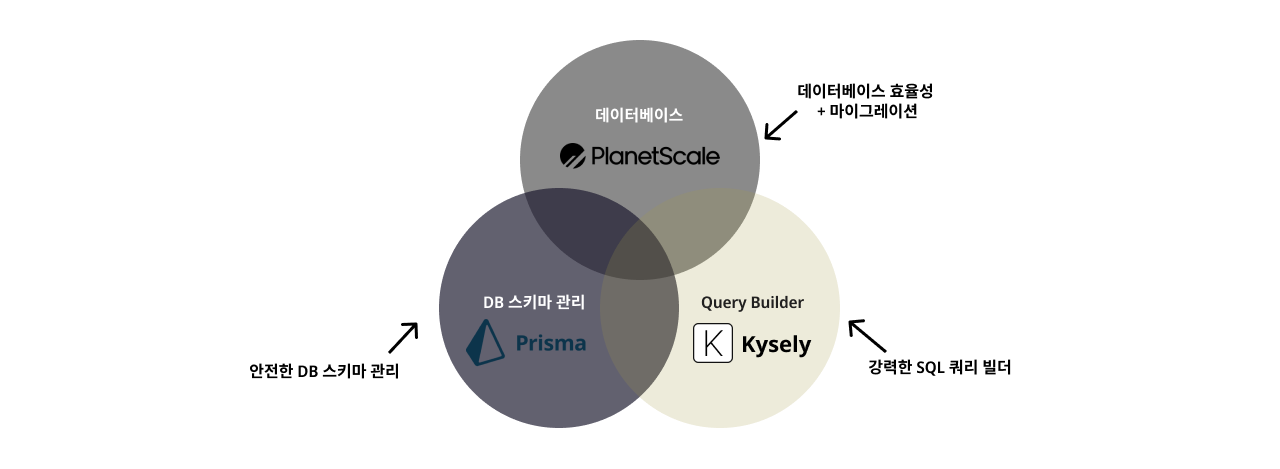
이번에 시도해본 방법은 PlanetScale과 Prisma, 그리고 QueryBuilder를 함께 사용해 각각의 장점이 나타나는 부분의 기능을 이용하여, 단점을 상쇄시키는 방법입니다.
PlanetScale, Prisma, 다른 ORM(QueryBuilder)들의 장단점
먼저 PlanetScale, Prisma, ORM 3축으로 장점들을 연결해 사용하게 될 것이기 때문에 각각의 장단점에 대하여 알아보겠습니다.
PlanetScale
- + 데이터베이스를 유지보수하기 위한 노력을 최소화 할 수 있다.
- + 마이그레이션과 스키마 관리를 PlanetScale에서 쉽게 진행할 수 있다.
- + 수평적 확장에 용이한 데이터베이스 설계를 가지고 있고, 개발자는 이에 대해 신경쓰지 않아도 내부적으로 자동화 되어있다.
- - Vitess 데이터베이스를 이용하기 때문에, 실질적으로 외래키를 가지고 있지 않고, 제약조건도 만들어지지 않는다.
Prisma
- + prisma.schema 라는 자체 문법을 이용해 다른 ORM에 비해 간단하고 쉽게 스키마를 작성할 수 있다.
- + prisma-cli를 이용해 Database와의 싱크를 맞추기 때문에 안전한 마이그레이션이 가능하다.
- - 복잡한 SQL문을 만들어내기에 부족하고, 데이터베이스 함수와 같은 기능을 사용하기 위해서는 rawQuery를 만들어야 한다.
기존의 ORM (Sequelize, TypeORM 등)
- + 강력한 쿼리빌더를 통해 비교적 폭넓은 SQL문을 생성할 수 있다.
- - 마이그레이션시에 안정성을 확보하기가 까다롭다.
- - 데이터베이스 태이블과 싱크를 맞추기 위한 객체모델을 직접 코드로 구현해야 한다.
위 3개의 목록들 중에 단점들을 없애고 서로 원활하게 연결되어 작동되게 만들기 위해 기존의 ORM대신에 저는 Kysely라는 QueryBuilder를 통해 SQL을 만들어 데이터를 조작하는 방법을 선택하였습니다.
Kysely?
Kysely는 Knex에서 영감을 얻어 만들어진 쿼리빌더입니다.
Node.js환경을 위해 개발되었지만, Deno 및 브라우저에서도 작동됩니다.
그렇다면 TypeORM, Sequelize와 같은 기존의 ORM이 아닌, 왜 Kysely라는 다소 생소할 수 있는 라이브러리를 사용할까요?
다음과 같이 2가지로 설명할 수 있습니다.
- Kysely는 PlanetScale serverless driver 를 지원하는 몇 안되는 QueryBuilder중 하나입니다.
- Kysely는 Prisma의
prisma.schema를 읽고 Kysely의 ObjectType으로 자동으로 변환할 수 있습니다.
또한 충격적이게도 Kysely는 ORM이 아닙니다. relations | kysely Docs
Kysely는 ORM이 아니며 관계의 개념이 없는 오직 SQL을 만들기 위해 존재하는 쿼리 빌더라고 문서에서 설명합니다.
사실 관계의 개념이 없음에도, JSON을 이용해 기존의 ORM과 같은 결과값을 만들어 낼 수 있으며, kysely는 성능도 기존 ORM들에 비해 뛰어난 편입니다.
또한, PlanetScale도 외래키 제약조건이 없기때문에 오히려 PlanetScale을 만난 kysely는 더 나은 조합이 될 수 있습니다.
관계의 개념이 없다는 것에 너무 겁먹을 필요는 없다는 뜻입니다 :)
Kysely + PlanetScale + Prisma 함께 사용하기
아직 서로의 역할에 대하여 이해가 안되겠지만, 각각 방법에 대하여 살펴본뒤 마지막에 정리를 해보겠습니다.
전체적으로 보면 PlanetScale 데이터베이스를 Prisma를 이용해 Schema를 관리하며,
Prisma를 통해 작성된 prisma.schema를 바탕으로 Kysely type을 자동으로 생성해 SQL문을 만드는 작업입니다.
prisma.schema를 kysely type으로 만들기
Sequelize나 TypeORM을 이용할때 가장 귀찮고, 신경쓰기 힘든 부분은 바로 태이블을 객체로 작성하는 것입니다.
prisma는 다른 ORM들에 비해 비교적 간단하게 자체 언어를 통해 태이블을 schema로 작성할 수 있는데,
prisma를 이용해 스키마가 작성되어 있다면, prisma-kysely를 통해 간단하게 kysely에서 바로 사용할 수 있습니다.
먼저 prisma-kysely를 설치해 줍니다.
yarn add prisma-kysely기존에 prismaClient를 이용하는 방법이라면 아래와 같이 prisma.schema파일에 client privider를 작성한뒤 npx prisma generate를 통해 프리즈마 클라이언트 객체를 생성하게 됩니다.
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
relationMode = "prisma"
}하지만, prisma.schema를 바탕으로 kysely타입을 만들기 위해서는 아래와 같이 kysely generator를 추가해 주어야 합니다.
// generator를 두개사용해 prisma-client와 kysely모두 사용할 수도 있습니다.
generator client {
provider = "prisma-client-js"
}
//prisma-kysely
generator kysely {
provider = "prisma-kysely"
// 타입이 생성될 디렉토리
output = "../src/db"
// 타입이 생성될 파일명
fileName = "types.ts"
// Optionally generate runtime enums to a separate file
enumFileName = "enums.ts"
}
datasource db {
provider = "mysql"
url = env("DATABASE_URL")
relationMode = "prisma"
}
model User {
// 사용자 정보
id Int @id @default(autoincrement())
phone String? @db.VarChar(32)
createdAt DateTime @default(now())
updatedAt DateTime @default(now()) @updatedAt
@@map("USERS")
}두개의 generator를 사용할 수 있기 때문에, 기존에 prisma를 사용중인 유저라면 점진적으로 마이그레이션을 진행할 수도 있습니다.
prisma.schema수정이 끝났다면, npx prisma generate를 통해 아래와 같은 kysely type을 생성할 수 있습니다.
// src/db/types.ts
import type { ColumnType, GeneratedAlways } from "kysely";
export type Generated<T> = T extends ColumnType<infer S, infer I, infer U>
? ColumnType<S, I | undefined, U>
: ColumnType<T, T | undefined, T>;
export type Timestamp = ColumnType<Date, Date | string, Date | string>;
export type User = {
id: Generated<number>;
phone: string | null;
createdAt: Generated<Timestamp>;
updatedAt: Generated<Timestamp>;
};
// DB타입을 추후 커넥터에 타입으로 제공해 주어야 합니다.
export type DB = {
USERS: User;
};
이제 kysely에서 사용할 태이블을 작성하는 단계가 모두 끝났습니다.
Kysely + PlanetScale 연결하기
kysely를 통해 데이터베이스에 쿼리를 보내기 위해서는 데이터베이스와의 연결이 먼저 선행되어야 합니다.
PlanetScale은 MySQL드라이버로도 연결을 할 수 있지만, 운영중인 서버에서 임의의 아웃바운드 TCP 연결을 허용하지 않을 수 있기 때문에, PlanetScale 드라이버를 통해 연결해 주는 것이 좋습니다.
먼저 아래 3가지를 모두 설치해 주어야 합니다.
kysely-planetscale플래닛스케일용 kysely-dialectkysely키슬리@planetscale/database플래닛스케일 서버리스 드라이버
yarn add kysely-planetscale kysely @planetscale/database설치가 모두 끝났다면, 데이터베이스 커넥터를 작성할 차례입니다.
prisma를 사용할때 DATABASE_URL을 이용하기 때문에 이를 변환하는 함수를 이용해 host,username,password를 만들어 커넥터로 전달해 줍니다.
// src/libs/db.ts
import {Kysely} from 'kysely'
import {PlanetScaleDialect} from 'kysely-planetscale'
//DATABASE_URL을 이용하기 위한 함수
const genSecret = () => {
if (process.env.DATABASE_URL) {
const url = process.env.DATABASE_URL.split('/')[2];
const username = url.split(':')[0];
const password = url.split(':')[1].split('@')[0];
return { username, password };
}
};
export const db = new Kysely<DB>({ // DB는 prisma-kysely를 통해 만들어진 타입입니다.
dialect: new PlanetScaleDialect({
host: 'aws.connect.psdb.cloud',
username: genSecret()?.username || '',
password: genSecret()?.password || '',
}),
});
host,username,password를 통해 연결하는 방식이 아닌,database_url을 통해 바로 연결하는 방식도 있지만, nodejs의 버전이 18보다 높을경우 fetch관련 오류가 발생할 수 있습니다.
위와 같이 db connector를 만들고 나면 아래와 같이 kysely를 통해 query를 만들 수 있습니다.
~~~
await db
.selectFrom('USERS')
.innerJoin('REQUESTS', 'REQUESTS.userId', 'USERS.id')
.selectAll()
.excute()
~~~kysely는 데이터베이스 함수, 서브쿼리등 정말 다양한 SQL문을 만들어 낼 수 있기때문에, 꼭 아래 문서를 읽어보는것을 추천드립니다.
kysely introduction | kysely Docs
마치며
처음에 설명한 것처럼 모든 요구사항을 충족시키는 완벽한 데이터베이스는 없습니다.
완벽하다고 생각된 데이터베이스 또한 개발을 진행하다보면 부족한 부분을 많이 찾게 되는게 보통인데, 좋은 개발자는 이러한 부족한 부분에 대해 타협보다는 더 나은 방법을 찾는 개발자라고 생각합니다.
사실 조금만 불편함을 감수하면, 많은 사람들이 이용하는 MySQL + TypeORM과 같이 전통적인 방법으로 문제에 접근하는것이 좋은 방법일 수 있습니다.
하지만 PlanetScale + Prisma + Kysely 3가지를 이용해 개발을 진행하면, 아래와 같이 위에서 나열한 단점들을 완화 시켜주는 모습을 가지고 있을 것이라고 생각됩니다.
- PlanetScale의 단점 | Vitess 데이터베이스를 이용하기 때문에, 실질적으로 외래키를 가지고 있지 않고, 제약조건도 만들어지지 않는다.
- Prisma를 통해 완화
- Prisma의 단점 | 복잡한 SQL문을 만들어내기에 부족하고, 데이터베이스 함수와 같은 기능을 사용하기 위해서는 rawQuery를 만들어야 한다.
- Kysely QueryBuilder를 통해 극복
- 기존 ORM의 단점 | 마이그레이션시에 안정성을 확보하기가 까다롭다.
- Prisma + PlanetScale을 통한 마이그레이션을 진행하기 때문에 안전하고 쉽게 마이그레이션, 혹을 롤백 할 수 있다.
- 기존 ORM의 단점 | 데이터베이스 태이블과 싱크를 맞추기 위한 객체모델을 직접 코드로 구현해야 한다.
- Prisma의 prisma.schema를 그대로 이용해 객체모델을 생성하기 때문에 쉽고 빠르게 객체모델 구현이 가능하다.
사실 3가지 모두 조금은 생소하거나 메인스트림급이 아닐 수 있지만, 모두 각자의 방향성을 잘 지켜가며 발전하고 있으며, 생태계를 구축해 나가고 있는 단계이기 때문에
한번쯤 사용해 보아도 좋을것 같다는 생각이 들었습니다.

PlanetScale, Prisma, Kysely가 모이니 삼위일체급 퍼포먼스를 낼 수 있네요