해당 포스팅은 Do it! 자료구조와 함께 배우는 알고리즘 입문: 파이썬 편을 보고 작성하였습니다.
1. 병합 정렬(Merge sort)
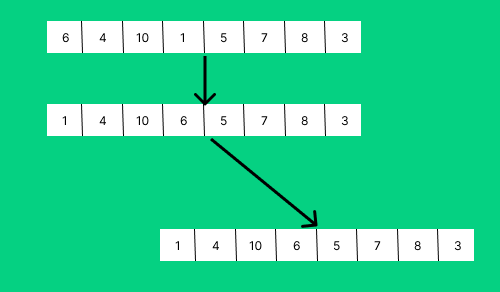
병합 정렬은 배열을 앞 뒤 두 부분으로 나누어 정렬한 후 병합하는 정렬이다.
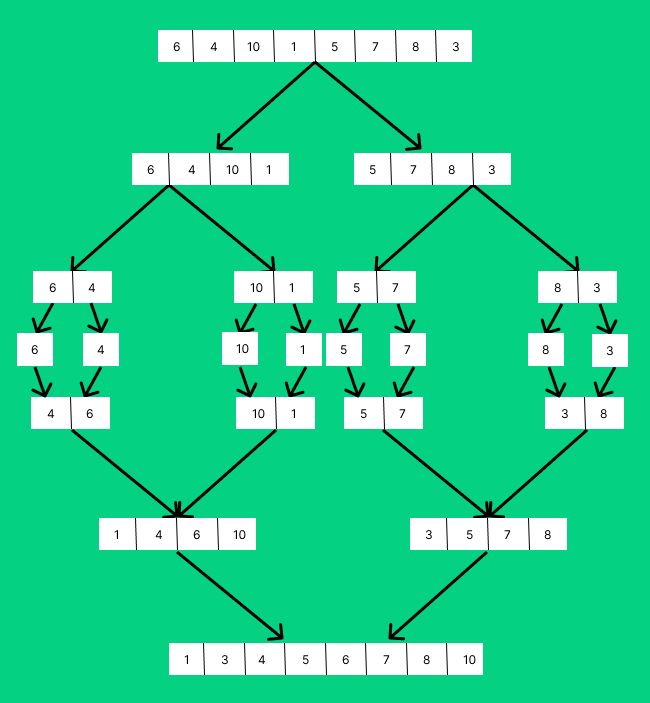
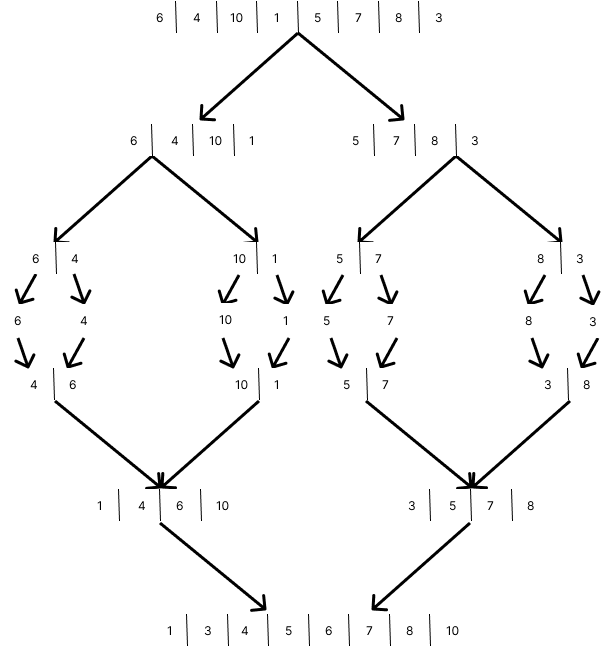
위는 크기 8의 병합 정렬되는 과정이다.
크기가 1이 될 때까지 쪼개지고 서로 정렬되면서 병합되는 것을 확인할 수 있다.
쪼개고 합치는데 O(log n) 정렬 할 때마다 O(n)이 걸려 총 O(n log n)이 걸린다.
from typing import Sequence, MutableSequence
def mergesort(a : MutableSequence)->None:
def _mergesort(a:MutableSequence, left:int, right:int)->None:
if left >= right:
return
center = (left+right)//2
_mergesort(a,left,center)
_mergesort(a,center+1,right)
p = j = 0
i = k = left
while i <= center:
buff[p] = a[i]
p+=1
i+=1
while j < p and i<=right:
if buff[j]<=a[i]:
a[k]=buff[j]
j+=1
else:
a[k]=a[i]
i+=1
k+=1
while j < p:
a[k] = buff[j]
j+=1
k+=1
n = len(a)
buff = [None]*n
_mergesort(a,0,n-1)
del buff
if __name__ == "__main__":
arr =[6,4,10,1,5,7,8,3]
mergesort(arr)
print(arr)
위는 merge sort 코드이다. merge sort를 작성해보신 분들이라면 해당 코드가 자신이 아는 방식과 좀 다르다는 것을 빨리 캐치했을 것이다.
내가 이 코드를 보고 가장 궁금했던 것은 buffer의 역할이었다.

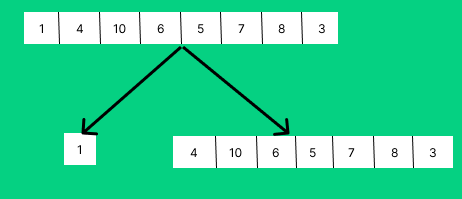
위 예시에서 가장 마지막으로 정렬되는 부분이다. buffer에 왜 5,7이 들어가있는지는 설명을 들으면 알게 될 것이다.
먼저 아래와 같이 변수들이 선언된다.
p = j = 0
i = k = left
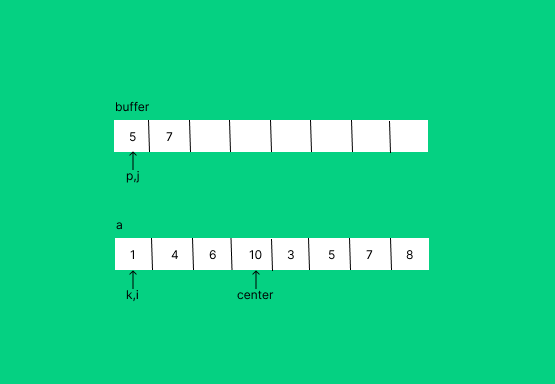
while i <= center:
buff[p] = a[i]
p+=1
i+=1i 값이 움직이면서 buffer에 값을 넣어주게 된다.
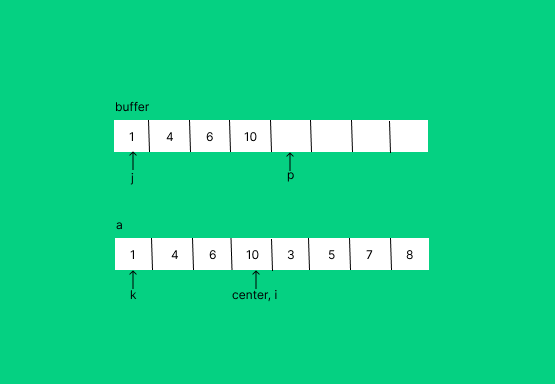
위 그림을 보았을 때 buffer에 left에서 온 값이 담겨있는 것을 알 수 있다.
여기서 딱 느낌이 온다.
buffer에 left값을 담고 buffer와 right의 값을 비교하면서 바로 a에 담으려는 목적이구나!
해당 방법으로 merge sort를 구현하면 buffer에서 다시 a로 옮기는 비용을 줄일 수 있을 것이다.
while j < p and i<=right:
if buff[j]<=a[i]:
a[k]=buff[j]
j+=1
else:
a[k]=a[i]
i+=1
k+=1
while j < p:
a[k] = buff[j]
j+=1
k+=1위 사진과 코드를 보면 이제 각 변수가 의미하는 것을 깨닫게 된다.
p : buffer의 끝을 의미하는 변수
j : buffer에서 a에 들어가지 않은 인덱스를 가리키는 변수
i : a의 right 부분의 시작점을 가리키는 변수
k : a에 정렬된 값이 들어갈 인덱스를 가리키는 변수추가적으로 왜 while j<p만 들어가고 while i<=right는 들어가지 않는지에 대해 의문이 들 수 있다. 그 이유는 buffer의 값이 다 들어가고 i<=right인 상태면 a가 모두 정렬된 상태이기 때문에 굳이 추가적인 연산을 할 필요가 없다. 잘 와닿지 않는다면 i가 a의 배열을 직접 가리키고 있는 것에 대해 곰곰히 생각해보면 될 것같다.
2. 힙 정렬(Heap sort)
힙 정렬(Heap sort)는 배열을 힙으로 만들고 힙에서 pop을 하며 정렬한다.
따라서 힙 정렬을 하기 위해서는 heapify가 필수이다.
1. Heapify
힙은 완전이진트리로 구현된다. 배열로 구현할 경우 부모와 자식은 다음과 같은 관계를 갖는다.
#부모가 a[i]인 경우
왼쪽 자식 : a[i*2+1]
오른쪽 자식 : a[i*2+2]
#자식이 a[i]인 경우
부모 : a[(i-1)//2]a=[6,4,10,1,5,7,8,3]을 이진트리로 나타내보자
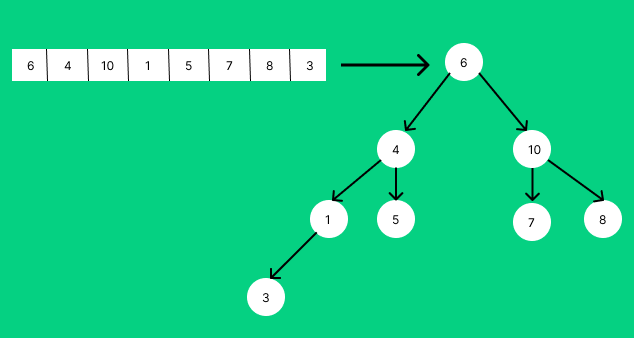
이진 트리를 heapify할 때는 한가지만 기억하면 된다.
힙이 아닌 최소 단위부터 힙으로 만들자
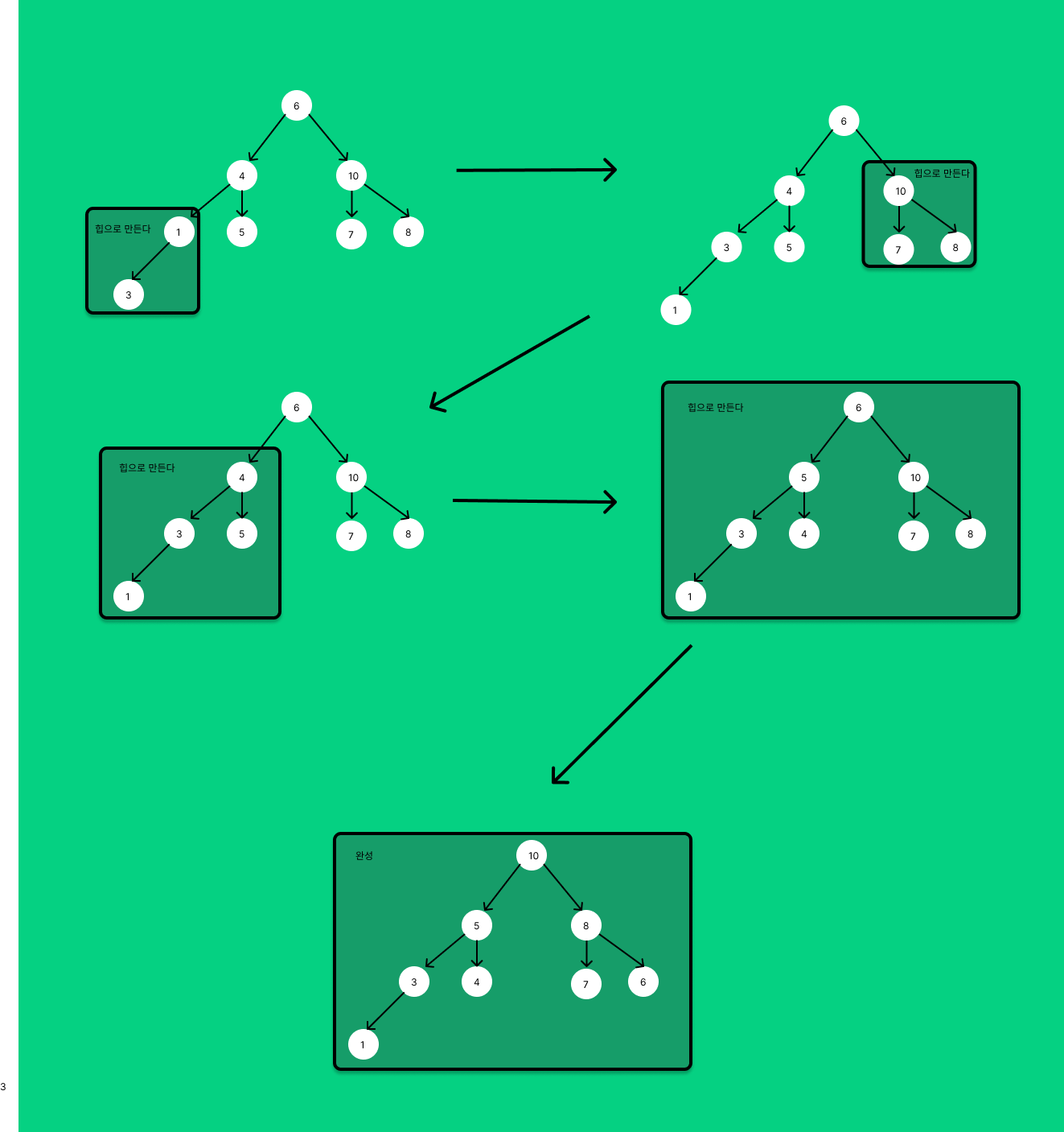
그렇다면 Heapfiy는 어떻게 진행 될까?
직관적으로 눈치챈 분들도 있겠지만 부모 노드 기준으로 좌,우가 이미 힙이기 때문에 좌,우를 비교해가며
자신보다 크기가 큰 자식이 없을 때까지 둘 중 큰 자식과 위치를 바꾸면된다.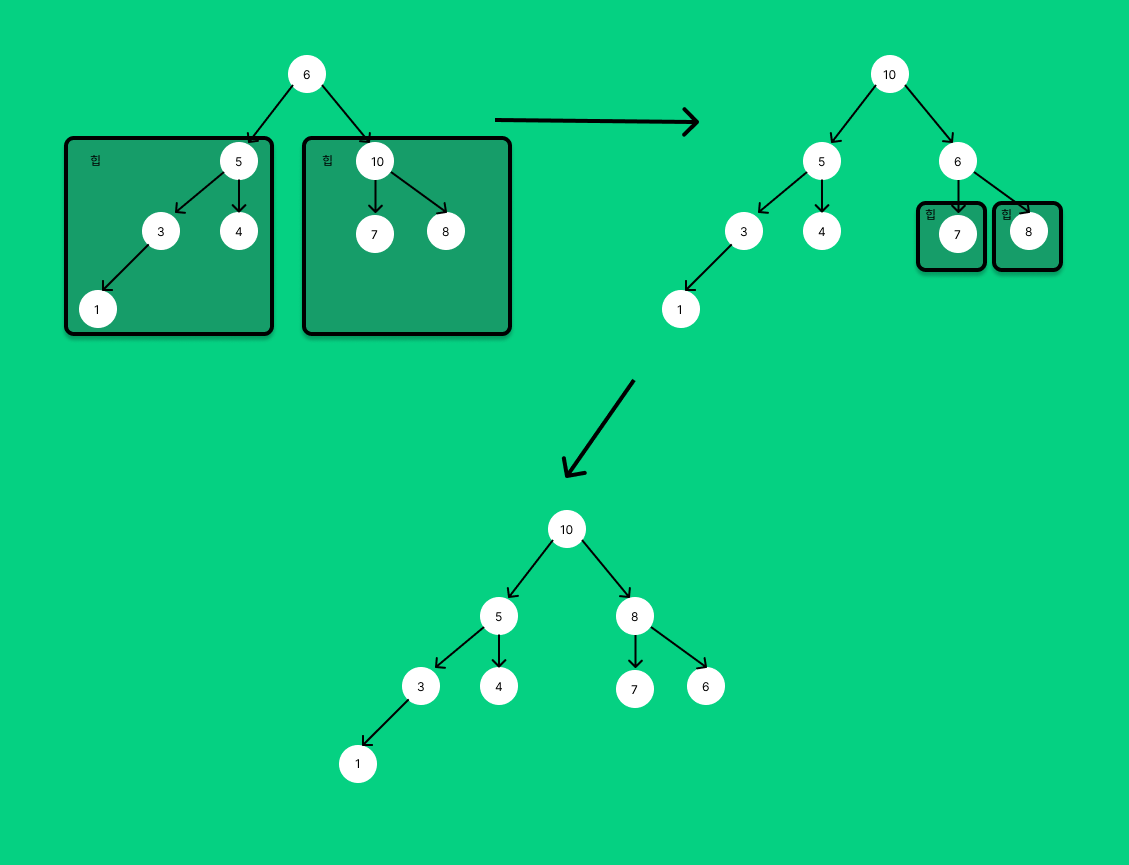
이진트리가 Heap구조가 된 것을 볼 수 있다.
2. pop
힙을 만들었다면 최댓값을 빼내어 배열의 가장 뒤로 보내면서 정렬을 하면된다.즉, 힙이 없어질 때까지 pop을 하면 된다는 뜻이다.
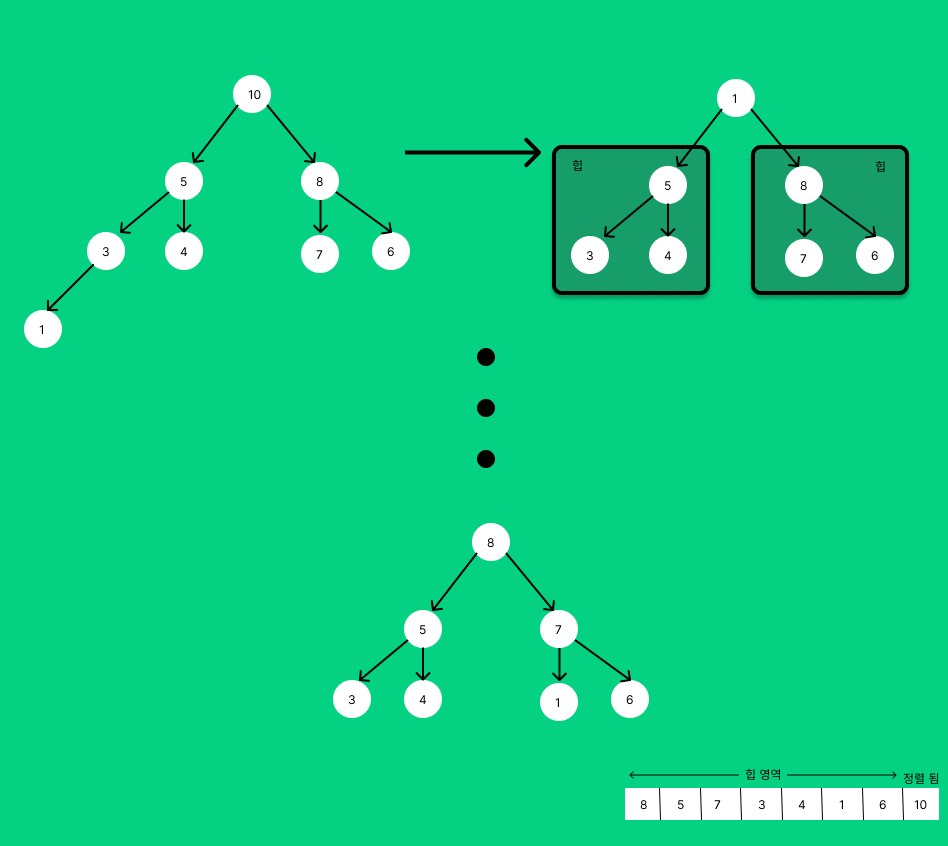
힙에서 pop을 하고 뒤로 보낸뒤 가장 마지막 요소를 루트로 이동시킨다.
그러면 방금 했던 좌,우가 힙 형태를 나타내는 구조가 만들어지고 Heapify를 진행하면된다.
Heapify가 완료되었을 때 배열을 보면 뒤에는 정렬된 영역, 앞에는 힙 영역인 것을 확인할 수 있다.
3. code
def heapsort(a: MutableSequence) -> None:
def heapify(a: MutableSequence, parent: int, last_idx: int):
root = a[parent]
# last_idx는 왼쪽 자식을 갖지 않는 첫번째 노드
while parent < (last_idx + 1) // 2:
left, right = parent * 2 + 1, parent * 2 + 2
child = right if right <= last_idx and a[right] > a[left] else left
if root >= a[child]: # 루트노드의 값이 가장 크다면 멈춘다
break
a[parent], parent = a[child], child #현재 부모와 자식의 값을 바꾼다
a[parent] = root
n = len(a)
for i in range((n - 1) // 2, -1, -1):
heapify(a, i, n - 1) #가장 마지막 부모 노드부터 heapify 진행
for i in range(n - 1, 0, -1):
a[0], a[i] = a[i], a[0] #루트노드를 정렬구역으로 옮김
heapify(a, 0, i - 1)나는 배열로 힙 정렬을 구현해 본적이 없어서 해당 코드를 이해하는데 시간이 오래 걸렸다.
먼저 첫 번째 for문을 해석해보자.
for i in range((n - 1) // 2, -1, -1):
heapify(a, i, n - 1)여기서 (n-1)//2가 의미하는 것은 가장 마지막 부모 노드이다. 따라서 해당 코드는 가장 마지막 부모 노드부터 순차적으로 힙으로 만들겠다는 것이다.
while parent < (last_idx + 1) // 2:
left, right = parent * 2 + 1, parent * 2 + 2
child = right if right <= last_idx and a[right] > a[left] else left
if tmp >= a[child]:
break
a[parent] = a[child]
parent = child
# parent = child
a[parent] = tmp
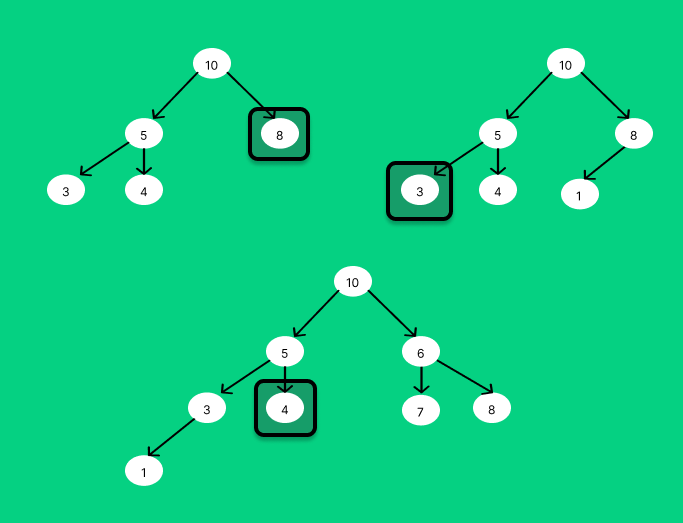
heapify함수에 안의 while문을 해석하는 것이 너무 어려웠다. 일단 (last_idx+1)//2를 해석할 수 있겠는가?
그래프를 그려보면서 확인해본 결과 가장 처음 발견되는 리프노드라는 것을 알 수 있었다.
아래 child를 정하는 코드도 굉장히 깔끔하게 짠 거 같다.
child = right if right <= last_idx and a[right] > a[left] else left이미 상위의 while의 조건에서 parent노드가 자식을 갖고 있다는 것을 보장하기 때문에 right<=last_idx로 parent노드가 왼쪽 자식만을 가지고 있는 노드인지 판별할 수 있다. 또, 정렬된 구역을 침범하거나 List out of range 에러가 뜨는 것을 방지 할 수 있다.
3. 퀵 정렬(Quick sort)
퀵 정렬은 행렬에서 pivot을 기준으로 왼쪽을 pivot 이하인 값, 오른쪽을 pivot 이상인 값으로 나누며 정렬이 진행된다.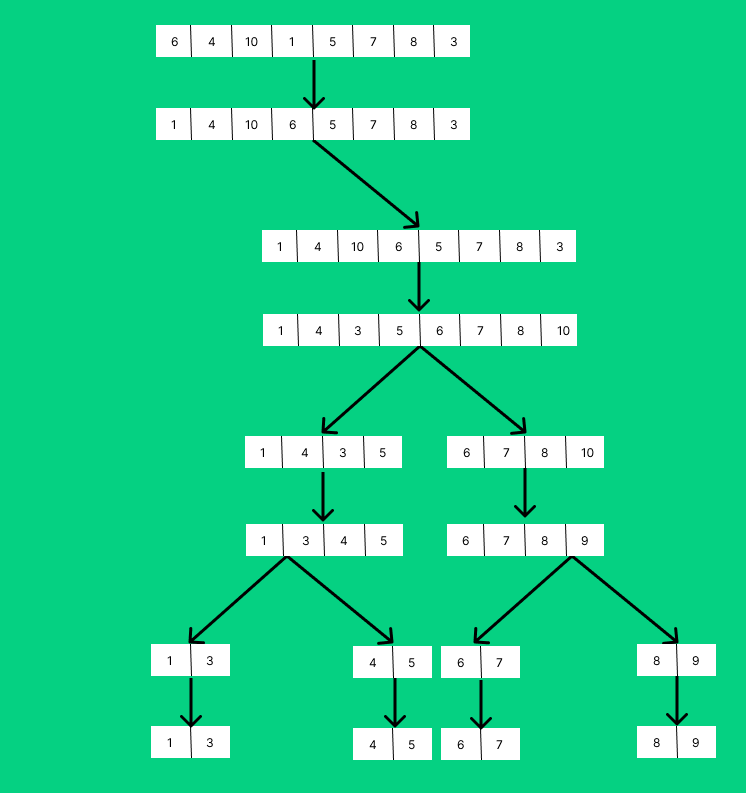
병합 정렬과 비교하였을 때 굳이 합칠 필요도, buffer를 생성할 필요도 없다.
주의해야 할 점은 항상 결과가 pivot 이상, 이하로 나뉘어지면서 분할 되는 것이 아니라 배열에 존재하는 특정 값으로 이상, 이하로 분할 될 수 있다는 것이다.
1.code
def quicksort(a: MutableSequence, left : int, right: int):
pl, pr = left, right
pivot = a[(left+right)//2]
while pl<=pr:
while a[pl] < pivot: pl+=1
while a[pr] > pivot : pr-=1
if pl <=pr:
a[pl],a[pr] = a[pr], a[pl]
pl+=1
pr-=1
if left < pr: quicksort(a,left,pr)
if pl < right: quicksort(a,pl,right)퀵 정렬의 코드이다. pivot을 가운데로 잡고 있다.
[1,4,10,6,5,7,8,3]을 가지고 예를 들어보겠다.
while a[pl] < pivot: pl+=1
while a[pr] > pivot : pr-=1pivot은 6으로 잡고 pl은 pivot보다 크거나 같은 값을 pr은 pivot보다 작거나 같은 값을 탐색한다.

따라서 pl은 10에서 pr은 3에서 멈추게 된다.
if pl <=pr:
a[pl],a[pr] = a[pr], a[pl]
pl+=1
pr-=1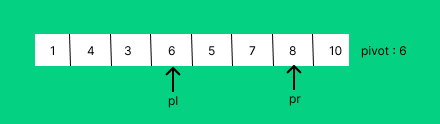
만약 pl<=pr일 경우 원소들을 서로 교환하고 한칸식 이동하게 된다.
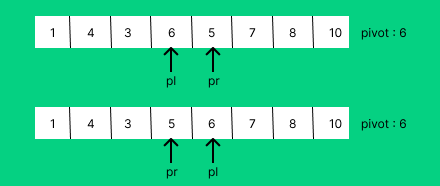
반복하게 되면 left부터 pr은 pivot 이하의 값이 pl부터 right는 pivot이상의 값으로 분리되게 되고 영역을 나누어 다시 퀵 정렬을 실행하게 된다.
2. 시간복잡도
퀵 정렬의 시간복잡도는 일반적으로 O(n log n)이 나온다. 하지만 최악을 경우 시간복잡도는 O(n^2)이 된다. 어떤 경우 일까?
위 예제에서 [6,4,10,1,5,7,8,3]이 [1,4,10,6,5,7,8,3]으로 바뀌고 이것을 다시 정렬하는, 한쪽으로 치우친 형태를 확인할 수 있다. 마치 최솟값을 앞으로 보내는 선택 정렬과 같다.
퀵 정렬에서 매번 pivot을 배열의 최댓값이나 최솟값으로 설정하는 경우 시간복잡도는 선택정렬과 같은 O(n^2)이 된다. 재귀를 사용하기 때문에 함수를 호출하는 비용까지 생각한다면 선택 정렬보다 훨씬 더 느린 정렬이 된다.
어떻게 하면 이를 해결 할 수 있을까?
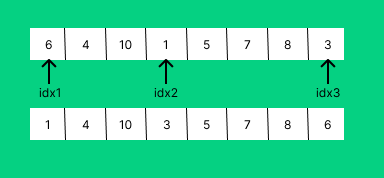
먼저 첫 번째 인덱스 값과 마지막 인덱스 값, 그리고 가운데 인데스 값을 선택하여 크기 순으로 정렬하고 각각의 자리에 다시 배치한다. pivot값은 idx2값인 3이 된다.
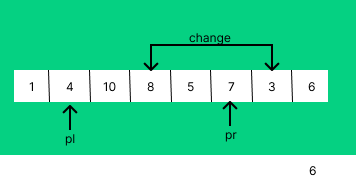
pl을 두번째 인덱스 부터, pr을 마지막에서 3번째 인덱스로 지정하고 기존의 처럼 pivot값과 비교하면서 정렬한다.
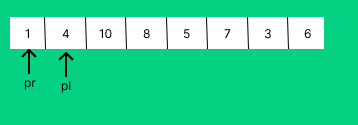
이 경우는 최악이라 하나와 나머지로 나누어졌다. 이 방법을 사용하면 그룹이 한쪽으로 치우치는 것을 피라 수 있고, 스캔할 원소를 3개 줄일 수 있다는 장점이 있다.
# 3개의 원소 정렬
def sort3(a:MutableSequence, idx1:int, idx2: int, idx3:int):
if a[idx2] < a[idx1]: a[idx2], a[idx1] = a[idx1], a[idx2]
if a[idx3] < a[idx2]: a[idx3], a[idx2] = a[idx2], a[idx3]
if a[idx2] < a[idx1]: a[idx2], a[idx1] = a[idx1], a[idx2]
return idx2
def quicksort(a: MutableSequence, left : int, right: int):
pl, pr = left, right
m = sort3(a,pl,(pl+pr)//2,pr)
pivot = a[m] #pivot은 가운데 값
a[m], a[pr-1] = a[pr-1],a[m]
pl+=1
pr-=2
while pl<=pr:
while a[pl] < pivot: pl+=1
while a[pr] > pivot : pr-=1
if pl <=pr:
a[pl],a[pr] = a[pr], a[pl]
pl+=1
pr-=1
print(a[left:right+1])
if left < pr: quicksort(a,left,pr)
if pl < right: quicksort(a,pl,right)
3. 병합 정렬 vs 퀵 정렬
병합 정렬과 퀵 정렬 모두 시간복잡도가 O(n log n)으로 같다.
하지만 일반적인 경우에 퀵 정렬이 병합 정렬에 비해 빠르다.
그 이유는 Locality 관점에서 설명할 수 있다.
Locality란 CPU가 짧은 시간 동안 일정 구간의 메모리 영역을 반복적으로 엑세스하는 경향
CPU가 연산을 할 데이터를 가져올 경우 RAM에서 가져올 때보다 캐치(cache)에서 가져오는 것이 훨씬 빠르다.
캐치의 용량은 RAM에 비해 매우 작기 때문에 시간적 지역성과 공간적 지역성을 고려하여 데이터가 올라간다. 즉, 어느정도 다음에 CPU가 사용할 데이터를 예측하여 캐치에 올린다고 생각하면 될 것 같다.
위 자료들은 정렬이 일어나는 과정을 보여준 것이다. 형광색 선들이 어떤 데이터를 참조하고 있는지를 보여주고 있다. 그 선들의 간격과 이동 거리가 병합 정렬보다 퀵 정렬이 훨씬 짧다는 것을 알 수 있고 이것은 Locality 관퀵 정렬이 병합 정렬보다 유리하다는 것을 알 수 있다.
참고한 링크 : Locality의 관점에서 Quick sort가 Merge sort보다 빠른 이유, [OS] 캐시 메모리(Cache Memory)란? 캐시의 지역성(Locality)이란?
4. 포스팅을 마치며
처음으로 맘에 드는 포스팅을 만들어 본 거 같다. 하루 반 정도를 포스팅하는데 썼는데 블로그에 있는 좋은 글들이 얼마나 많은 노력으로 쓰여졌는지 알게 되었다.
현재 나는 크래프톤 정글 2기 과정 중에 있으며 현재 7일차이다. 아직 여유있는 초반이라 좋은 글이 나온거 같은데 자신은 없지만 앞으로도 이정도의 포스팅을 계속 하기위해 노력할 것이다.
