
1. 디스크 컨트롤러
디스크에 작업이 들어온다. 각 작업의 요청시간과 처리소요시간이 주어진다. 우리가 구해야할 것은 평균작업 시간이다. 한번에 하나의 작업만 수행가능하다. 따라서, 앞의 작업이 완료되기 전에 들어오면 앞의 작업이 완료될때까지 기다렸다가 완료되면 그제서야 비로소 작업이 시작된다.
예를 들어 아래와 같이 작업에 대한 요청시간과 소요시간이 주어졌다고 해보자.
let jobs = [
[0, 3],
[1, 9],
[2, 6],
];첫번째 작업을 a / 두번째 작업을 b / 세번째 작업을 c라고 했을때 a는 0ms에 task에 들어왔고 3ms가 걸린다. b는 1ms에 task에 들어왔고 9ms가 걸린다. c는 2ms에 task에 들어왔고 6ms가 걸린다.
가장 일반적인 처리는 들어온 순서대로 처리하는 방법이다. 그림으로 나타내면 아래와 같다.
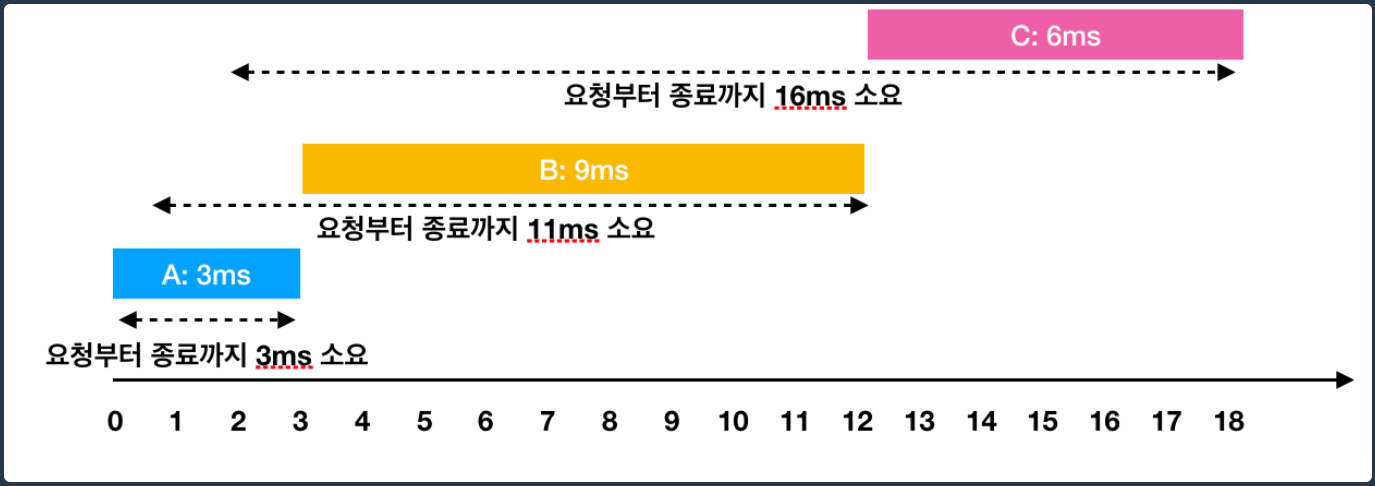
그럼 총 걸린 시간은 (3+11+16)/3 이므로 10ms이 답이다.
그러나 a다음에 c가 오면 어떨까? 그래서 처리순서가 a-> c -> b 로 바뀌면 총 걸린시간은 어떻게 될까?
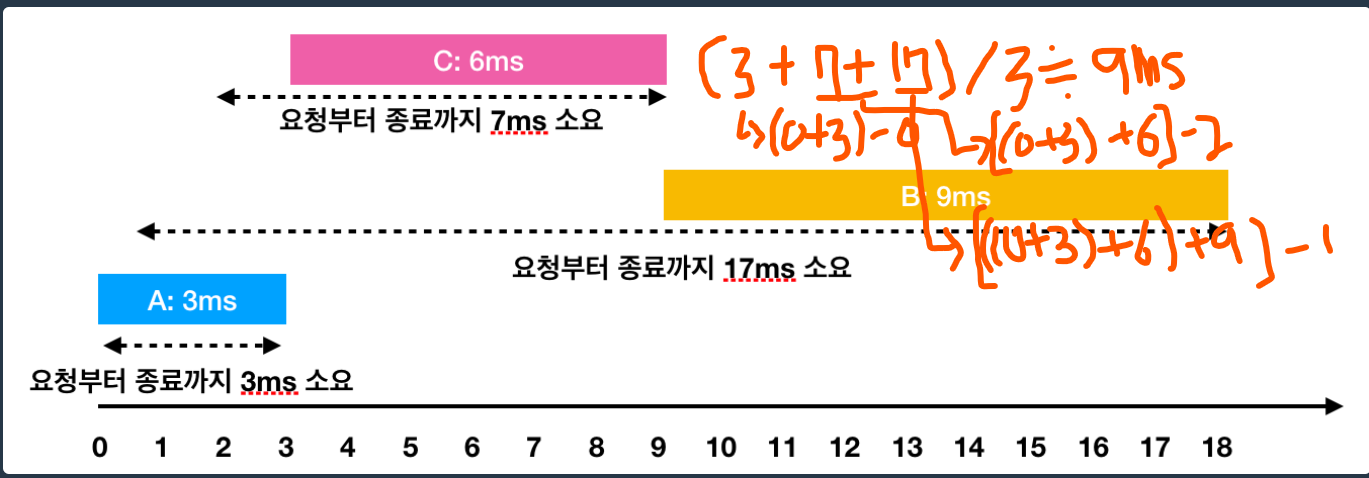
보다시피 9ms으로 위의 순서보다 1ms더 적게 걸린다. 그리고 계산 방법은 => (앞의 작업이 끝난 시점 + 소요시간) - 요청시점 이다. 그럼 무엇이 앞으로 와야할까? 바로 처리시간이 적은것이 앞으로 가면 된다. 그럼 한 번 본격적으로 풀어보자
2. 접근 방법
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
[0,3][4,5][5,6] 일때 3초뒤에는 아무작업도 하지 않는다는 얘기. 이때는 4초에 시작하는 것부터 먼저처리한다는 뜻.
일단 뭐부터 먼저 처리하는게 좋을지 생각해보자! 시각화시키고 비교를 해보았다. 서로 다른 처리방법에 대해서 우선순위 큐를 잘 활용해보자. 처리시간이 적은것부터 먼저 처리?
알아냄.. 먼저 처리해야하는 순서. => 걸리는시간-요청시간 이 적은것 부터 먼저 처리.
왜냐면 (걸리는시간-요청시간) = 최종 소요시간 이므로 최종 소요시간이 가작 적은 것 부터 처리하는것이 좋다.
계산 방법 = (이전 작업이 완료된 시점+현재 작업이 걸리는 시간) - 요청시간
- pseudo code
- sort를 하자 최종소요시간이 가장 짧은 것 부터
- 그리고 for문을 통해서 계산을 이어나가는 것이다.
function solution(jobs) {
let answer = 0;
jobs.sort((a, b) => {
return a[1] - a[0] - (b[1] - b[0]);
});
let prevEndPoint = jobs[0][0];
for (let i = 0; i < jobs.length; i++) {
answer += prevEndPoint + jobs[i][1] - jobs[i][0];
prevEndPoint = prevEndPoint + jobs[i][1];
}
return Math.floor(answer / jobs.length);
}테스트케이스는 맞았는데 최종에서 하나빼고 다 틀렸다 ㅋㅋㅋㅋ 그래도 시도는 굉장히 좋았다. 문제를 이해하고 나름 코드를 적어서 완성은 했다.
그럼 다른 사람의 코드를 보자. 일단 그 분의 설명을 적어보겠다.
- pesudo code
설명1. 먼저요청이 들어온 작업부터! 그래서 [0]에 따라서 정렬.
설명2. 작업을 처리하는 동안 들어오는 작업을 pq에 넣어 줌.
설명3. jobs안에 있는 작업들을 모두 한번씩 해나가야함 (j < jobs.length).
설명4. 처리시간이 가장 작은 작업이 맨 앞으로오게해서 처리하게 함. 이렇게 해야 최소시간을 만족함.
설명5. 혹시 우선순위가 다 비고나서 작업이 남아있으면 현재 jobs의 첫번째 배열에 있는 작업을 실행. 예를 들어서, [0,3]을 처리하고 나서 그 뒤에 남은 작업들이 [4,6][6,8] 이라면 [4,6]부터 실행하라는 뜻!
const solution1 = (jobs) => {
let answer = 0,
j = 0,
time = 0;
// 설명1. 먼저요청이 들어온 작업부터! 그래서 [0]에 따라서 정렬
jobs.sort((a, b) => {
return a[0] - b[0];
});
const priorityQueue = [];
// 설명2. 작업을 처리하는 동안 들어오는 작업을 pq에 넣어 줌
// 설명3. jobs안에 있는 작업들을 모두 한번씩 해나가야함 (j < jobs.length)
// 아직 작업이 다 완료되지 않았거나 || pq에 작업이 남아있다면 계속 돌려라!
// 그럼 계속 pq안에 작업을 push해야한다.
while (j < jobs.length || priorityQueue.length !== 0) {
// jobs.length > j 이면 아직 현재 완료한 작업의 갯수가 전체 작업의 수보다 작다는 말. 즉 아직 처리해야할 작업이 남아있다는 뜻이다.
// time >= jobs[j][0] => 그 작업을 완료했을때의 시점 , 즉 [0,3] 이 이전 작업이라면 현재 시간은 3이겠지.
// 다음 작업 [1,9]의 요청시간이 3보다 작을 경우 pq에 넣으라는 뜻 만약 3보다 크면, 예를들어 [4,6] 이면 저 밑에 else 에 걸리게 되어있음
if (jobs.length > j && time >= jobs[j][0]) {
// push 했으니깐 j가 하나 늘어난거다
priorityQueue.push(jobs[j++]);
// 설명4. 처리시간이 가장 작은 작업이 맨 앞으로오게해서 처리하게 함. 이렇게 해야 최소시간을 만족함
priorityQueue.sort((a, b) => {
// a[1] 이 작은게 앞으로 온다는 말이지
return a[1] - b[1];
});
continue;
}
if (priorityQueue.length !== 0) {
// 이건 시간 축을 그려보면 더 잘 알수 있음
// time은 각 작업이 끝나는 시점이다.
// 그리고 answer은 작업이 끝나는 시점에서 요청한 시간을 빼고 그전의 작업이 걸린 시점과 더하면 된다.
// 각 작업의 요청시간과 걸린시간을 그림을 그리고 그 그림을 보면서 코드를 보면 된다.
time += priorityQueue[0][1];
answer += time - priorityQueue[0][0];
// 작업완료되었으면 pq에서 제외
priorityQueue.shift();
} else {
// 설명5. 우선순위가 다 비고나서 작업이 남아있으면
// 현재 jobs의 첫번째 배열에 있는 작업을 실행. 예를 들어서, [0,3]을 처리하고 나서
// 그 뒤에 남은 작업들이 [4,6] [6,8] 이라면 [4,6]부터 실행하라는 뜻!
time = jobs[j][0];
}
}
return parseInt(answer / jobs.length);
};우와.... 이거 이해 할 줄 몰랐는데 이해해버렸다... 그이유는 뭐지??
일단 설명을 차근차근 보고 이해해서 그 설명이 해당되는 부분에다가 그 설명을 주석으로 달았다. 그리고 그 설명에 해당하는 코드를 유심히 살펴보고 디버깅도 보고, 그림도 같이 보면서 거기에 해당하는 구체적 예시를 대입해서 이해하려고 했다.
3. 배운점
- '구체적인 예시'와 '시각화'를 통해 이해도를 높이고, 그 이면에 깔린 '코드작성자의 의도'를 파악하려고 한다. 그럼 어느순간 퍼즐이 맞춰지면서 전체 내용과 목표를 이해하게 되는 것 같다! 장하다 장해. 잘하고 있다!!
내가 무언가를 해내거나 이해했을때 그렇게 할 수 있게된 원인이 분명히 있다. 그걸 분석하고 정리해서 밝혀내고 저장하자!!
