[도서] 친절한 SQL 튜닝
1.[친절한 SQL 튜닝] 1장 SQL 처리 과정과 I/O
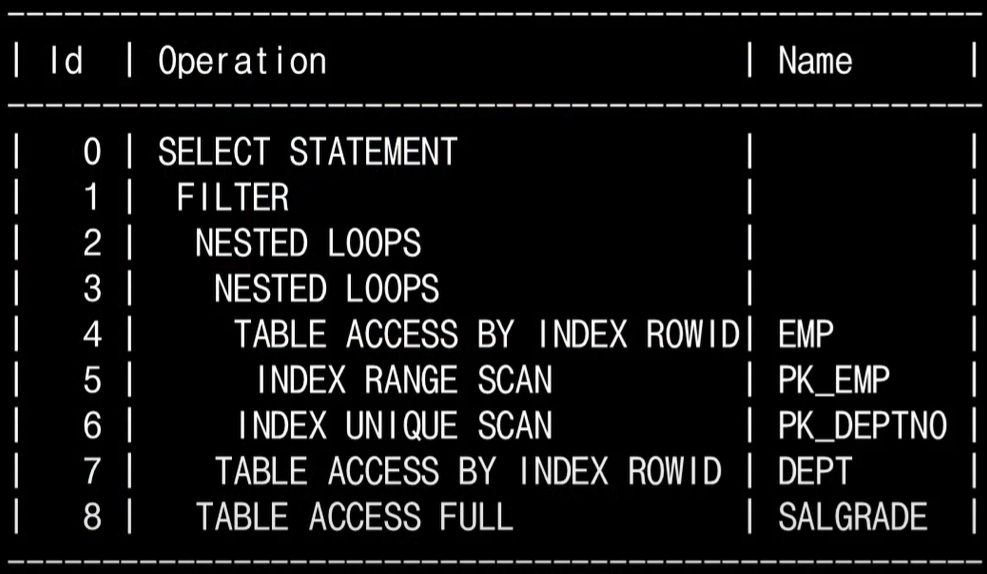
SQL(Structured Query Language)구조적 질의 언어구조적(structued)이고 집합적(set-based)이고 선언적(declarative) 인 질의 언어결과 집합은 구조적, 집합적이지만 만드는 과정은 절차적(procedural)이어야 한다.옵티마이
2.[친절한 SQL 튜닝] 2.1~2.2장 인덱스 기본
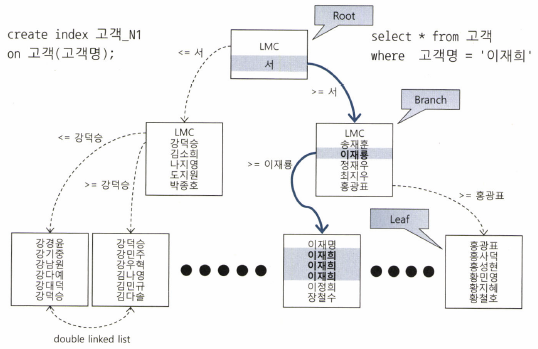
인덱스 : 온라인 트랜잭션 처리(Online Transaction Processing) 시스템에서는 소량 데이터를 주로 검색하므로 인덱스 튜닝이 중요하다.인덱스 스캔 효율과 튜닝인덱스 스캔 과정에서 발생하는 비효율을 줄이는 것예) 어떤 컬럼을 인덱스로 활용해야 스캔량이
3.[친절한 SQL 튜닝] 2.3~3.2장 인덱스 기본, 튜닝
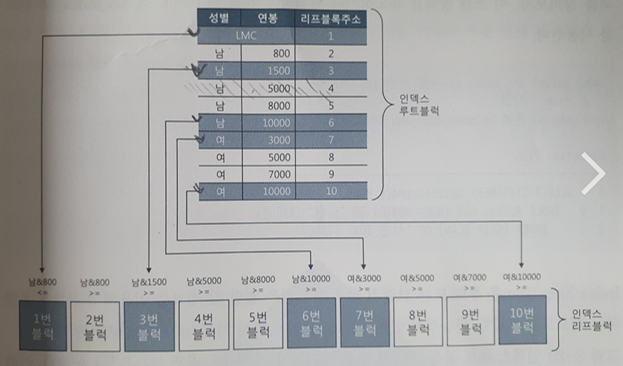
Index Range Scan 은 B\*Tree 인덱스의 가장 일반적인 현택의 방식수직적 탐색 + 수평적 탐색(필요한 범위만)선두 칼럼을 가공하지 않은 상태로 조건정레 사용해야 한다 -> 조건 만족시 무조건 Range Scan 가능수직적 탐색 없이 인덱스 리프 블록을
4.[친절한 SQL 튜닝] 3.3장 인덱스 스캔 효율화
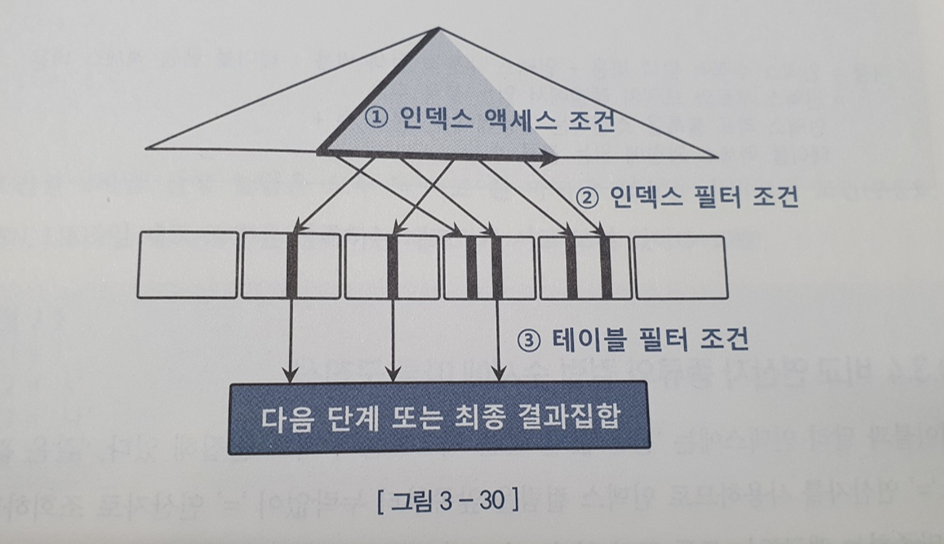
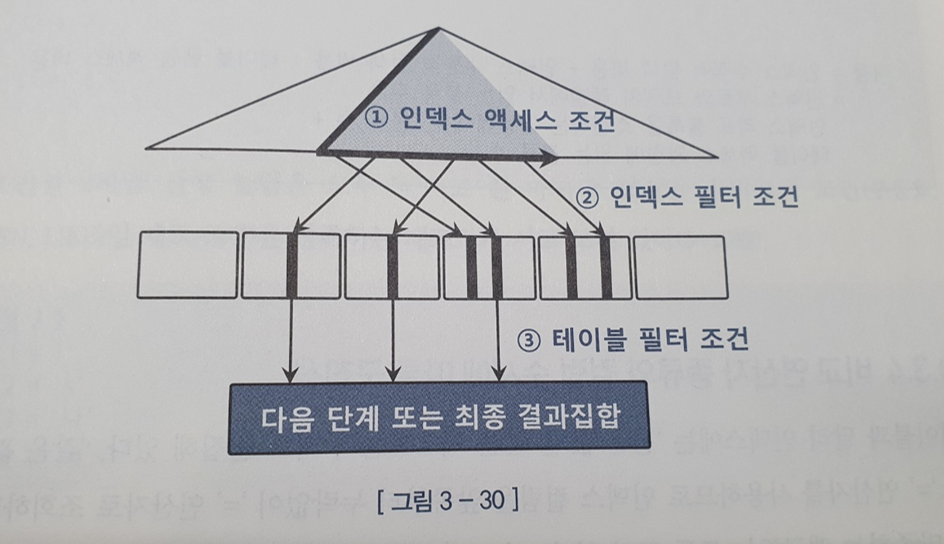
3.3 인덱스 스캔 효율화 3.3.1 인덱스 탐색 책 참고(p173 ~ p183) 3.3.2 인덱스 스캔 효율성 인덱스 스캔 효율이 좋은지 않은지는 SQL 트레이스로 확인가능하다 3.3.3 액세스 조건과 필터 조건 1.인덱스 액세스 조건 인덱스 스캔 범위를 결정하는 조
5.[친절한 SQL 튜닝] 3.4~4.1장 인덱스 설계, NL 조인
3.4 인덱스 설계 3.4.1 인덱스 설계가 어려운 이유 인덱스가 많으면 문제가 발생한다 DML 성능 저하(->TPS 저하) 데이터베이스 사이즈 증가(-> 디스크 공간 낭비) 데이터베이스 관리 및 운영 비용 증가 데이터 입력시 모든 인덱스에 데이터를 입력해야
6.[친절한 SQL 튜닝] 4.2 소트 머지 조인
4.2 소트 머지 조인 4.2.1 SGA vs PGA SGA(System Global Area) : 공유 메모리 영역으로 SGA 에 캐시된 데이터는 여러 프로세스가 공유할 수 있다. 하지만 동시 액세스가 되지 않아 Lock 메커니즘인 래치(Latch)가 존재한다. PGA(Process/Program/Private Global Area) : 각 오라클 서버 ...
7.[친절한 SQL 튜닝] 4.3 해시 조인

4.3 해시 조인 NL 조인은 인덱스를 이용한 조인으로 인덱스 구성에 따른 성능차이가 심하고, 랜덤I/O 로 인해 대량 데이터 처리에 불리하고, 버퍼캐시 히트율에 따라 성능이 들쭉날쭉하다. 소트 머지 조인과 해시 조인은 조인 과정에 인덱스를 사용하지 않아 대량 데이터
8.[친절한 SQL 튜닝] 5.1~5.2 소트 튜닝
소트는 PGA 에 할당한 Sort Area 에서 이루어진다.메모리 공간인 Sort Area 가 다 차면, 디스크 Temp 테이블스페이스를 활용한다.메모리 소트(In-Memory Sort) : 전체 데이터의 정렬 작업을 메모리 내에서 완료 (=Internal Sort)디
9.[친절한 SQL 튜닝] 6.3 파티션을 활용한 DML 튜닝
6.3 파티션을 활용한 DML 튜닝 파티션을 활용하면 대량 추가/변경/삭제 작업을 빠르게 처리할 수 있다. 6.3.1 테이블 파티션 파티셔닝(Partitioning) : 테이블 또는 인덱스 데이터를 특정 컬럼(파티션 키) 값에 따라 별도 세그먼트에 나눠서 저장 파티션