
AWS Summit Seoul 2024
일정: 2024.05.16(목) ~ 2024.05.17(금)
장소: 코엑스 컨벤션 센터
AWS Summit Seoul 2024는 10주년을 맞이해 2015년 첫 행사 이후 최대 규모로 개최된다는 소문에 사전 예약자만 2.9만명을 넘어섰다고 한다.
작성한 Agenda 외에도 참석하였지만 개인적으로 Insight를 얻을 수 있었던 항목에 대해서만 다루고자 한다.
AWS Summit Seoul | Day 1
Agenda. 삼성계정은 DR에 진심, 글로벌 리전 장애 조치 아키텍처 사례 - L300 (1F 그랜드볼룸 102+103+104호 - 신기술 트렌드) 
1. AWS에서의 복원력
- 다운타임 비즈니스 임팩트
- 복원력이랑 인프라나 서비스의 장애를 견디고 예상치 못한 상황에서도 신속하게 복구할 수 있는
- 고가용성
- 설계와 운여 메커니즘을 통한 일반적 장애에 대한 내성 확보
- 장애 발생시 서비스 장애를 방지
- 재해 복구
- 드물지만 큰 영향을 미치는 재해에 대해 특정 목표 내에서 운영 복구
- 장애 발생시 서비스 복구를 위한
- 복구시점 및 복구시간 목표 (RPO, RTO)
- 시간 목표
- 재해로 인한 장애 발생 시 정상 가동시간까지의 허용 시간
- 시점 목표
- 재해 발생시 허용되는 시간에 따른 데이터 최대 손실량
- 시간 목표
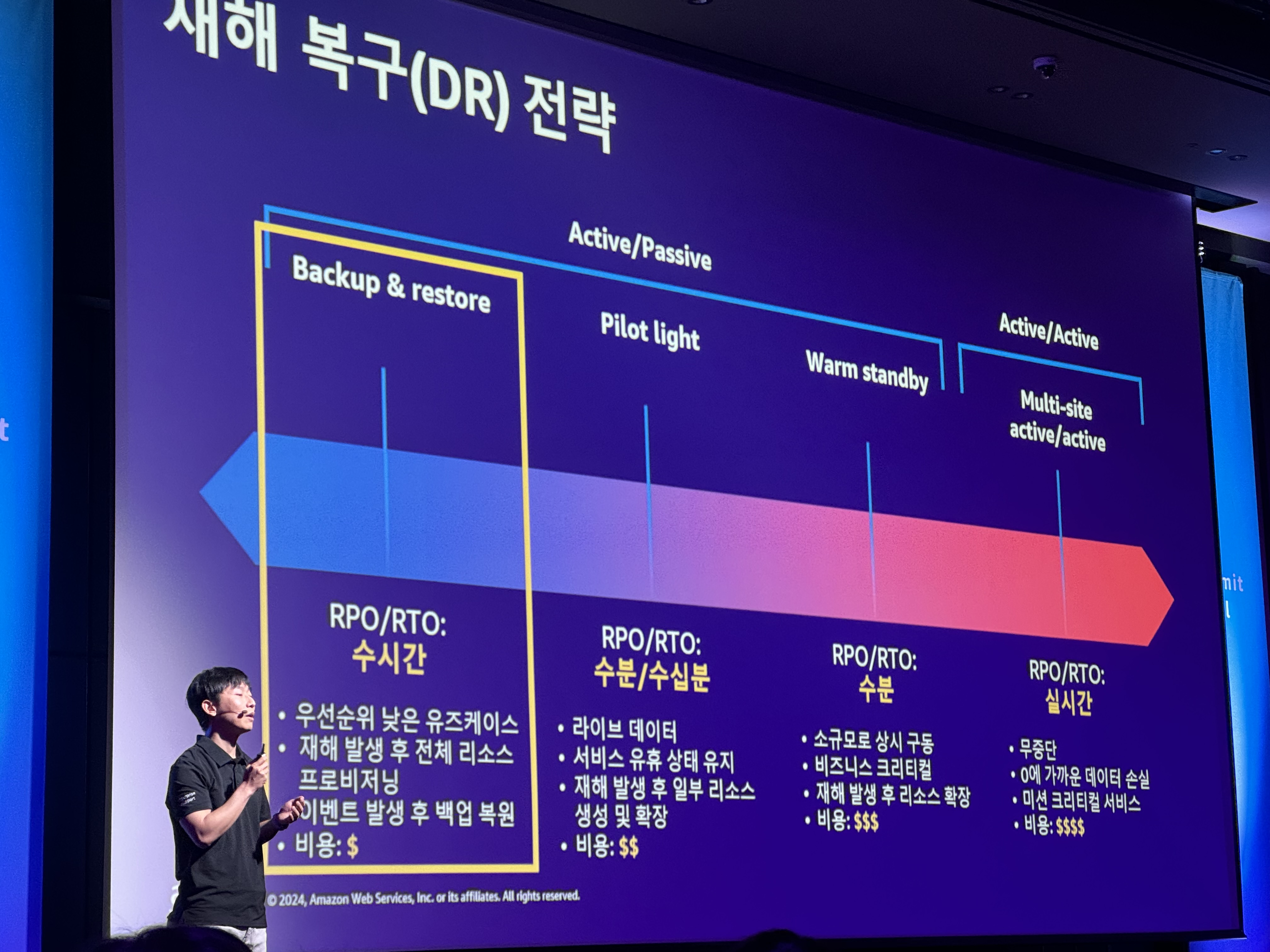
- 재해 복구(DR) 전략

- Active / Passive
- Backup&restore - 수시간
- 백업을 얼마나 주기적으로 실행하는지에 따라 발생
- 4시간마다 백업한다면 장애 발생시 백업이후의 4시간이 복구시간목표가 된다.
- 백업을 얼마나 주기적으로 실행하는지에 따라 발생
- Pilot light - 수분/수십분
- 전체규모의 서비스 환경을 프로비저닝
- Warm standby - 수분
- 복구 시점은 Pilot light과 동일
- 복구 시점은 수분내로 단축할 수 있음
- Backup&restore - 수시간
- Active/Active
- Multi-site active/active - 실시간
- 가장 복잡하고 비용이 많이 드는 기술선택이지만 zero에 가까운 데이터 손실
- 시스템 복잡도가 높아질 수 있음 - 동일하게 유지해야 하기 때문
- Multi-site active/active - 실시간
- 복잡도와 가용수준을 고려하여 적절한 목표를 수립해 사용
- Active / Passive
- 주요 정리

- 재무적 손실과 브랜드 이미지 피해
- 실패에 대비한 복원력 설계
- 고가용성과 재해 복구 전략을 적절히 활용
2. 삼성 계정 글로벌 리전 DR 구성 사례 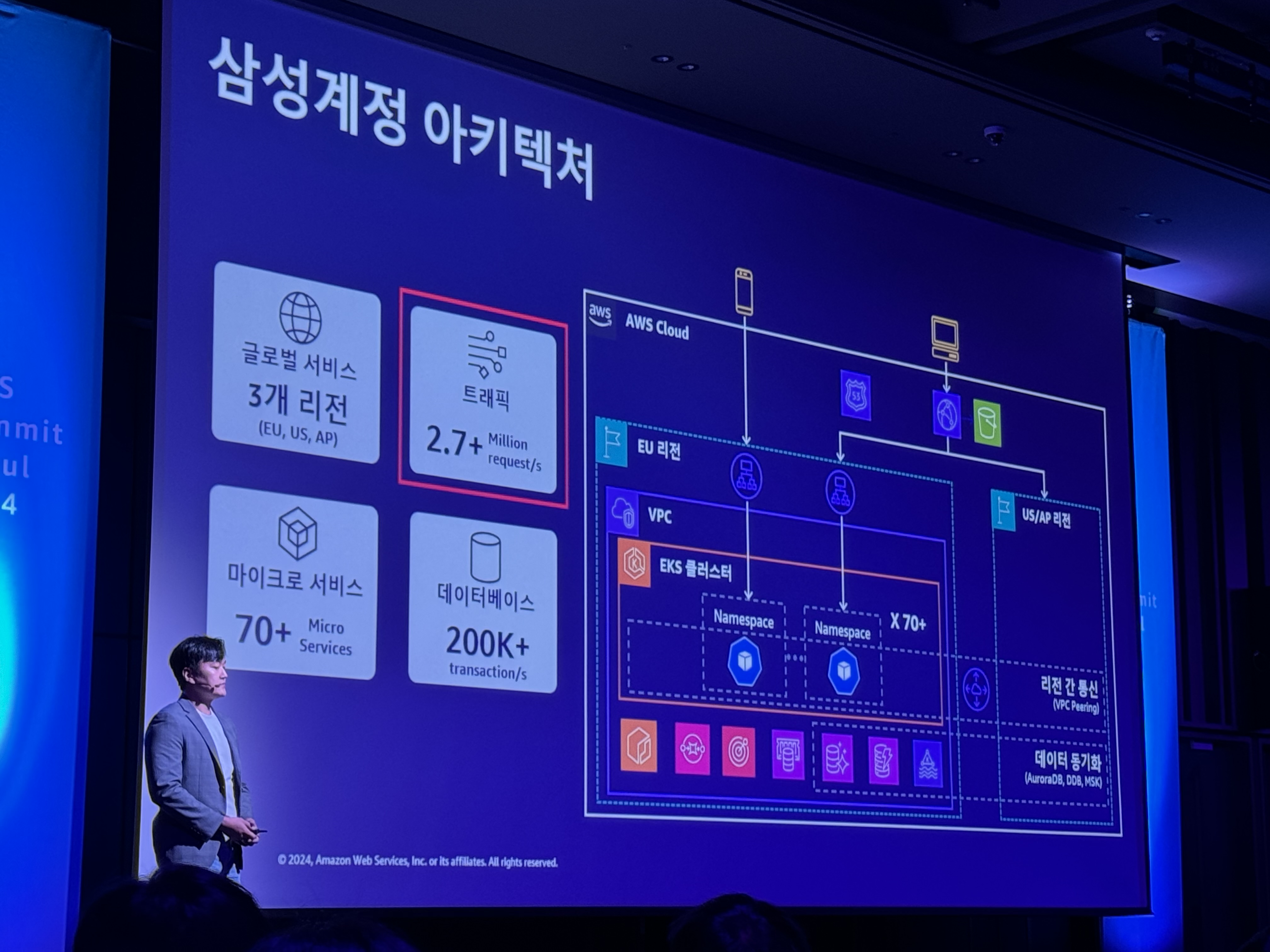
-
초당 270만 대용량 트래픽을 소화하고 있음
-
70개 이상의 MSA - 고가용성을 위해 - EKS 기반으로 운영
-
초당 20만 transaction 처리 auroraDB를 메인으로 사용 (dynamoDB, ElastiCache …)
-
cloudfront를 사용한 cdn을 기반으로 제공
-
높은 안정성과 가용성 필수
- 삼성의 모든 기기와 서비스를 연결하는 비즈니스 크리티컬 시스템으로 높은 수준의 RTO를 목표
-
글로벌 Active/Active 아키텍처
-
높은 수준의 DR을 위한 글로벌 Active/Active 아키텍처로 고도화
- Action #1. 장애 복구 안정성을 위한 신규 리전 구축
- Action #2. 리전 단위 서비스 형상 일치화
- Action #3. 리전 단위 데이터 동기화
- postgres msk 기반 동기화 아키텍처
- dynamodb aws 자체 솔루션인 global table을 가지고
-
트래픽 전환 제어
- 대용량 트래픽을 저비용으로 효율적 전환할 수 있는 방법?
- case #1. 글로벌 로드 밸런서 기반 트래픽 전환 제어
- 즉각적인 트래픽 전환이 가능
- 많은 비용과 많은 엔드포인트
- 글로벌 로드 밸런서가 너무 많다는 문제점 발생
- case #2. DNS 기반 장애 트래픽 전환 제어
- 리전단위 장애 발생 시 레코드 변경
- ex. 10.0.0.2 장애 발생 시 레코드를 변경하여 10.0.0.3으로 전환
- DNS 캐시로 인하여 레코트 변경에 시간이 추가로 소요될 수 있다
- 삼성은 이걸 선택함
- 리전단위 장애 발생 시 레코드 변경
- case #1. 글로벌 로드 밸런서 기반 트래픽 전환 제어
- 대용량 트래픽을 저비용으로 효율적 전환할 수 있는 방법?
-
제어 계층 의존성
- 리전 단위 장애 발생 시 Route53을 변경할 수 없다면?
- Route53 설정/변경 = 리전 장애 복구
- 큰 장애가 발생하는 경우 리전IP로 변경하지 못하면?
- 리전 단위 장애 발생 시 Route53을 변경할 수 없다면?
-
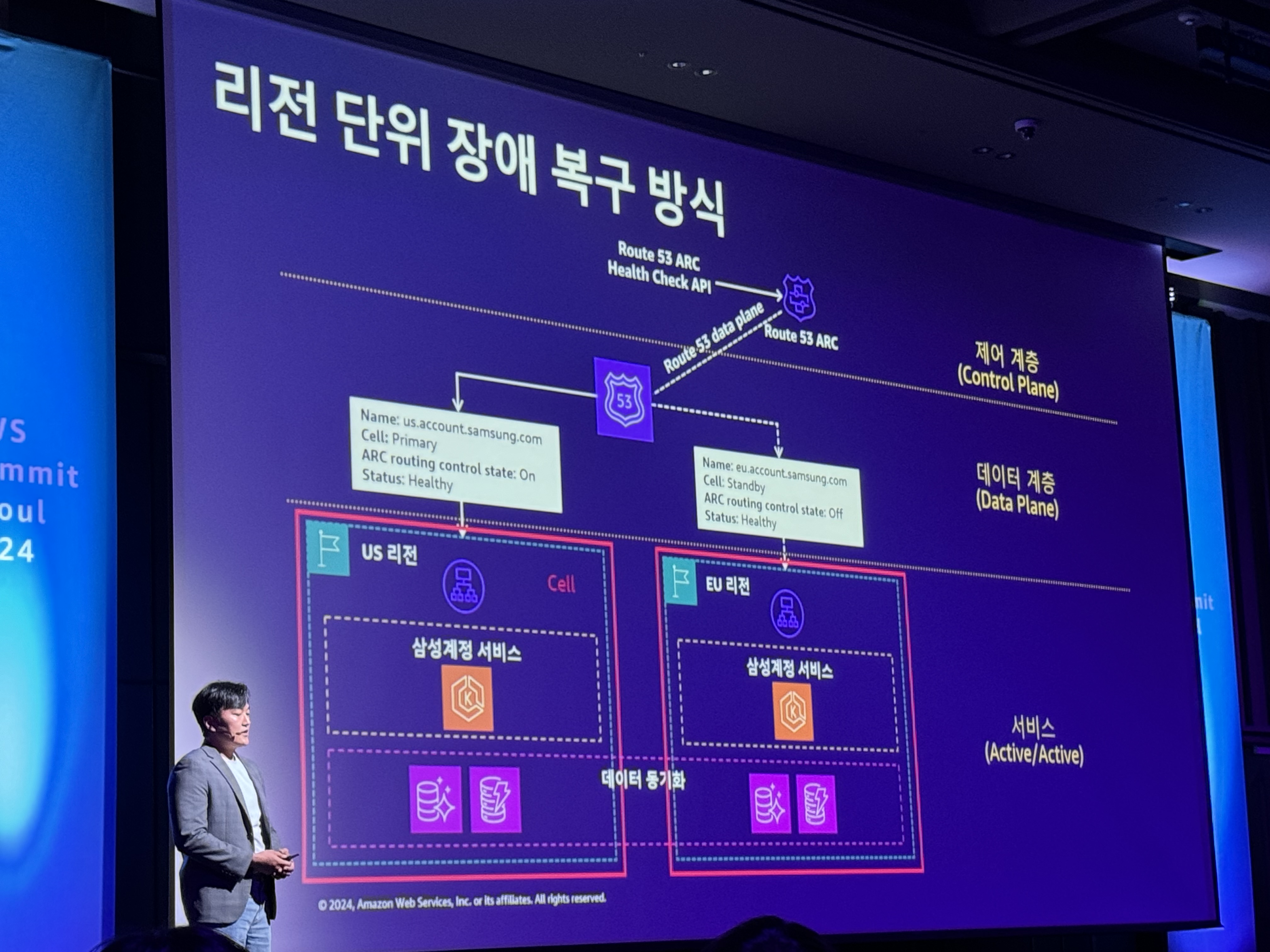
리전 단위 장애 복구 방식
- Route 53 ARC Health Check API
- control plane에서 장애가 발생하더라도 장애조치가 가능할 수 있게 해준다.
- 장애트래픽전환제어 요청
- 다른 리전으로 트래픽이 이전되도록
- 결과적으로 리전단위 장애대응 아키텍처를 확보
-
예측 가능 분산 아키텍처
-
트래픽 예측이 가능하며 변화가 적은 방식의 분산 아키텍처 필요
-
오버프로비저닝
- but 비용
-
case #1. 지연 시간 기반 라우팅
- route53에서 제어하기 때문에 예측하여 서비스 규모정책을 정의할 수 없다
-
case #2. 지리적 라우팅
-
전체 트래픽을 국가단위로 미리 예측하고 장애트래픽에 대비한 지리적 라우팅 아키텍처
-
256개 국가 record 설정
-
각 국가의 트래픽 예측 및 세밀하게 관리
-
운영관점에서 어려움
-
그룹핑 할 수 있는 방법?
-
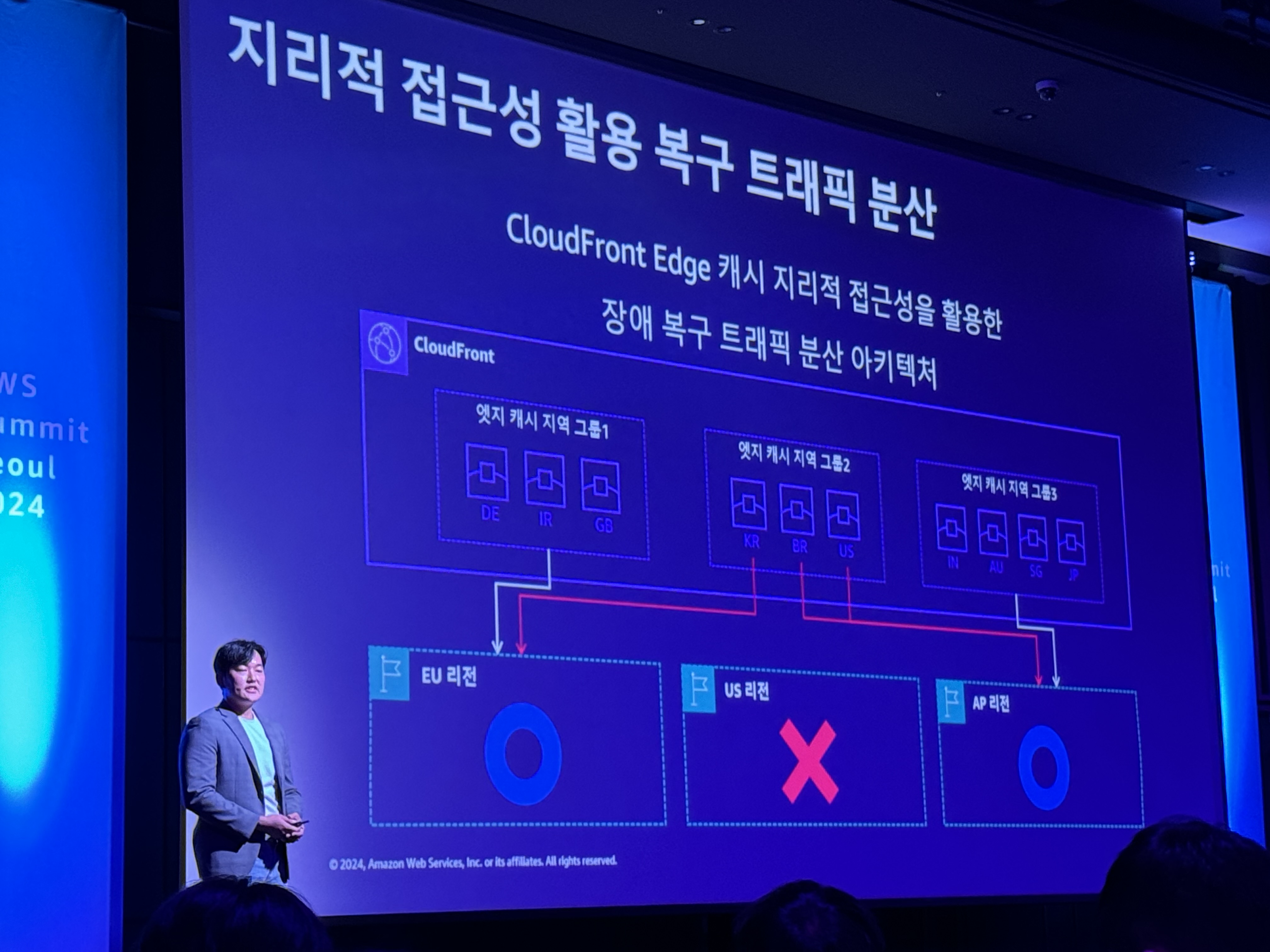
CloudFront Edge Location 캐시 지리적 접근성을 활용한 장애 복구 트래픽 분산 아키텍처
- 운영 복잡성을 획기적으로 줄임
-
장애 트래픽 분산 계획에 따라 타 리전으로 다른 트래픽을 분산시키는 것이 가능해짐
-
-
-
-
-
-
-
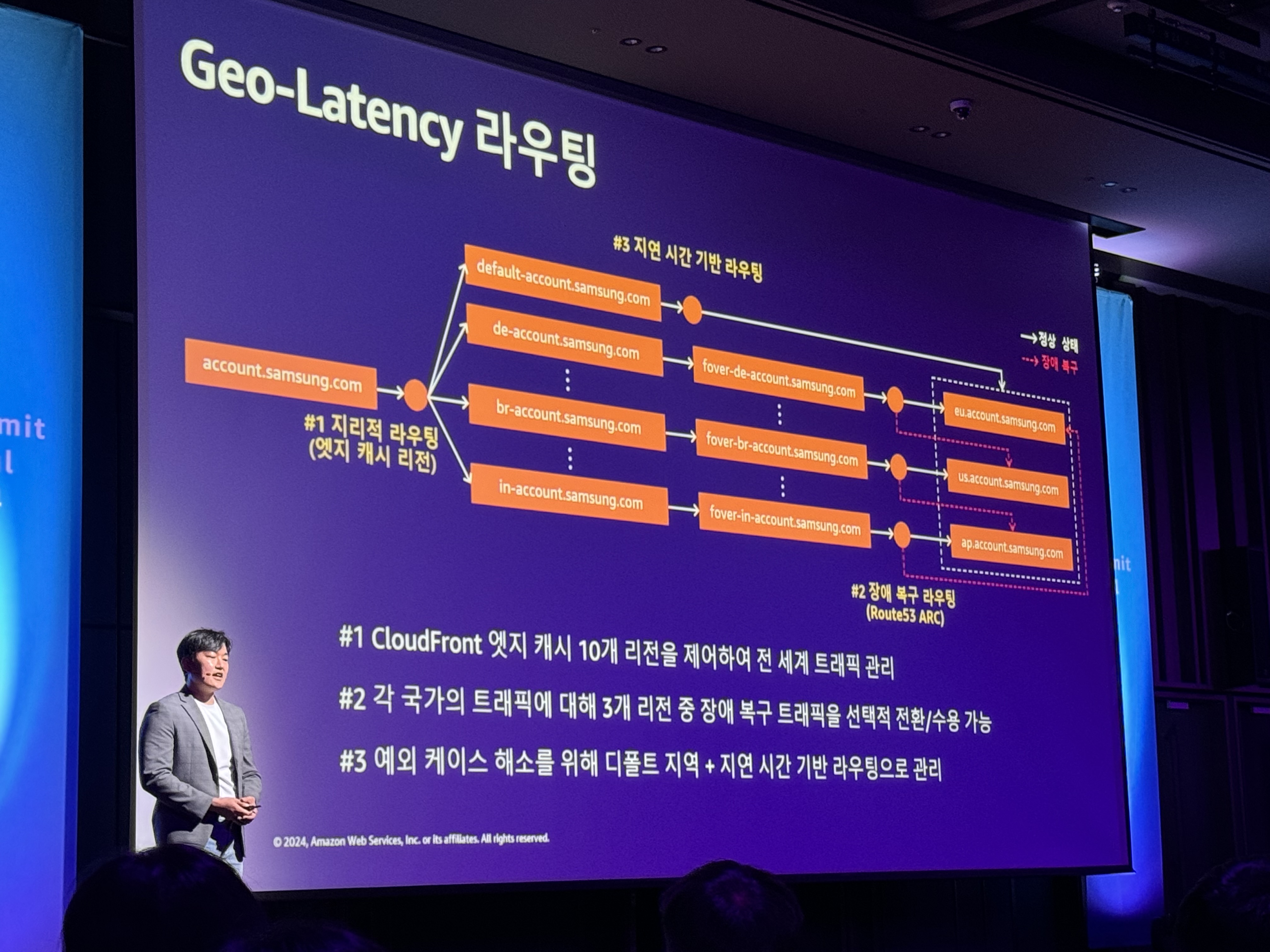
Geo-Latency 라우팅 - 최종적으로 완성

- #1 CloudFront 엣지 캐시 10개 리전을 제어하여 전 세계 트래픽 관리
- #2 각 국가의 트래픽에 대해 3개 리전 중 장애 복구 트래픽을 선택적 전환/수용 가능
- #3 예외 케이스 해소를 위해 디폴트 지역 + 지연 시간 기반 라우팅으로 관리
-
CloudFront Origin Group
- CloudFront Origin Group 활용 S3 장애 복구 대응
- primary, secondary region s3
- CloudFront Origin Group 활용 S3 장애 복구 대응
-
D-Day: 운영 환경 모의 장애 훈련

- 글로벌 장애 복구 아키텍처 검증 및 장애 훈련 실시
- 부하검증 - 개발 검증 절차에 맞춰
- Step1: 아키텍처 기능 검증
- 누락된 URL 설정들을 조기에 확인하고 조치할 수 있었음
- Step2: 장애복구 부하 검증
- 리전간 호출 급증 등 아키텍처 개선에 필요한 항목을 확인할 수 있었음
- Step3: 모의 장애 훈련
- 수분 내 장애트래픽 전환에 성공
-
복원력 강화를 위한 여정

- MTTR 단축을 이뤄냄
- end-to-end monitoring system을 구축하고 있음
- 이를 통해 MTTD를 단축하여 복원시간을 줄이고자 함
-
Agenda. GS리테일 Amazon EKS의 모든 것: 무중단 운영부터 배포 자동화까지 - L300 (4F 401호 - 유통 및 소비재 상품)

1. EKS운영에 어려운 점이 무엇일까요?
- 고객이 Amazon EKS로 혁신하는 방법
- Web, Backend, Analytics, AI/ML, Legacy apps
- 클러스터 관리
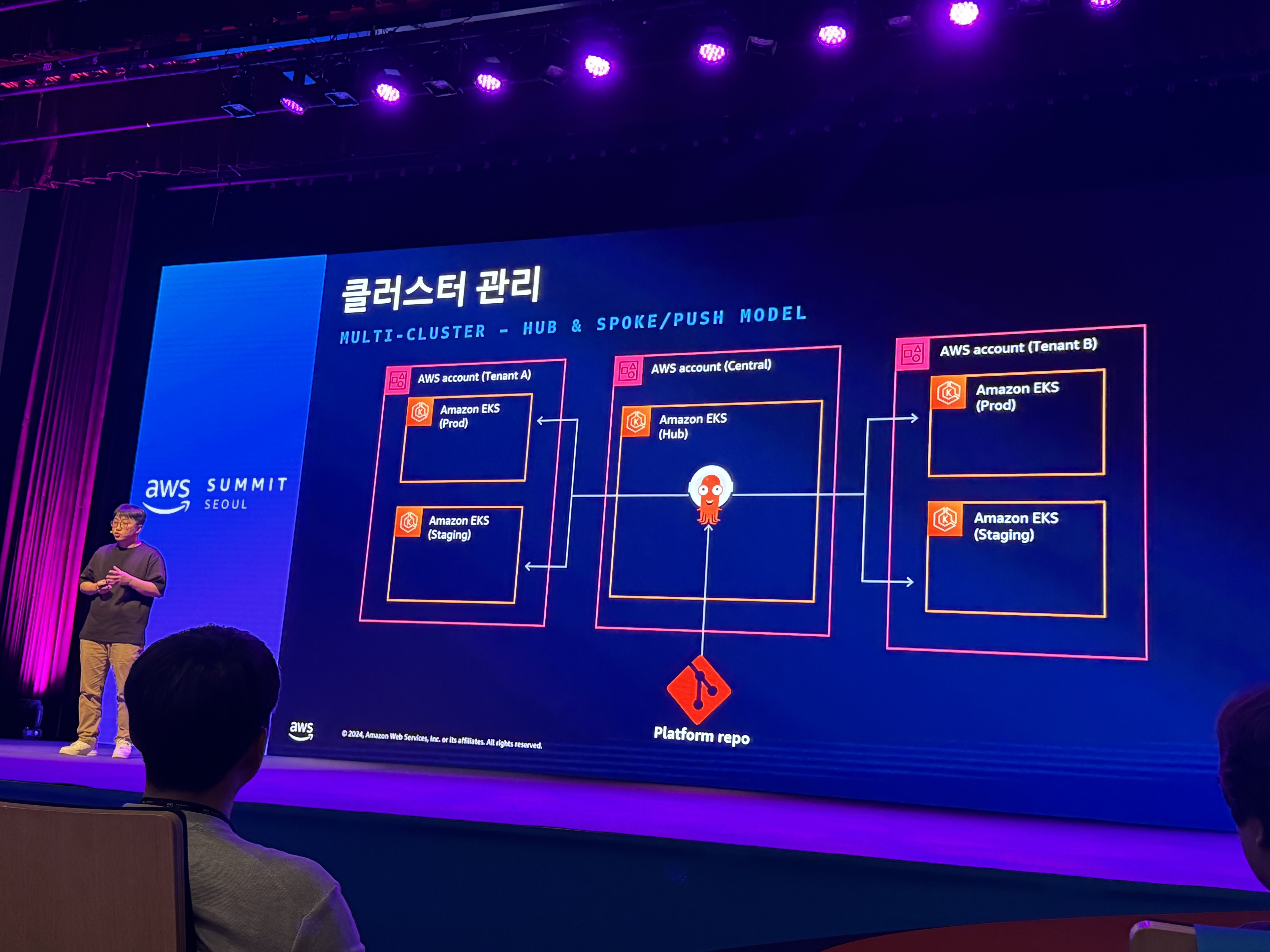
- 클러스터 전반에 보안 표준 및 모범 사례를 적용하여 배포 자동화
- Add-on 관리
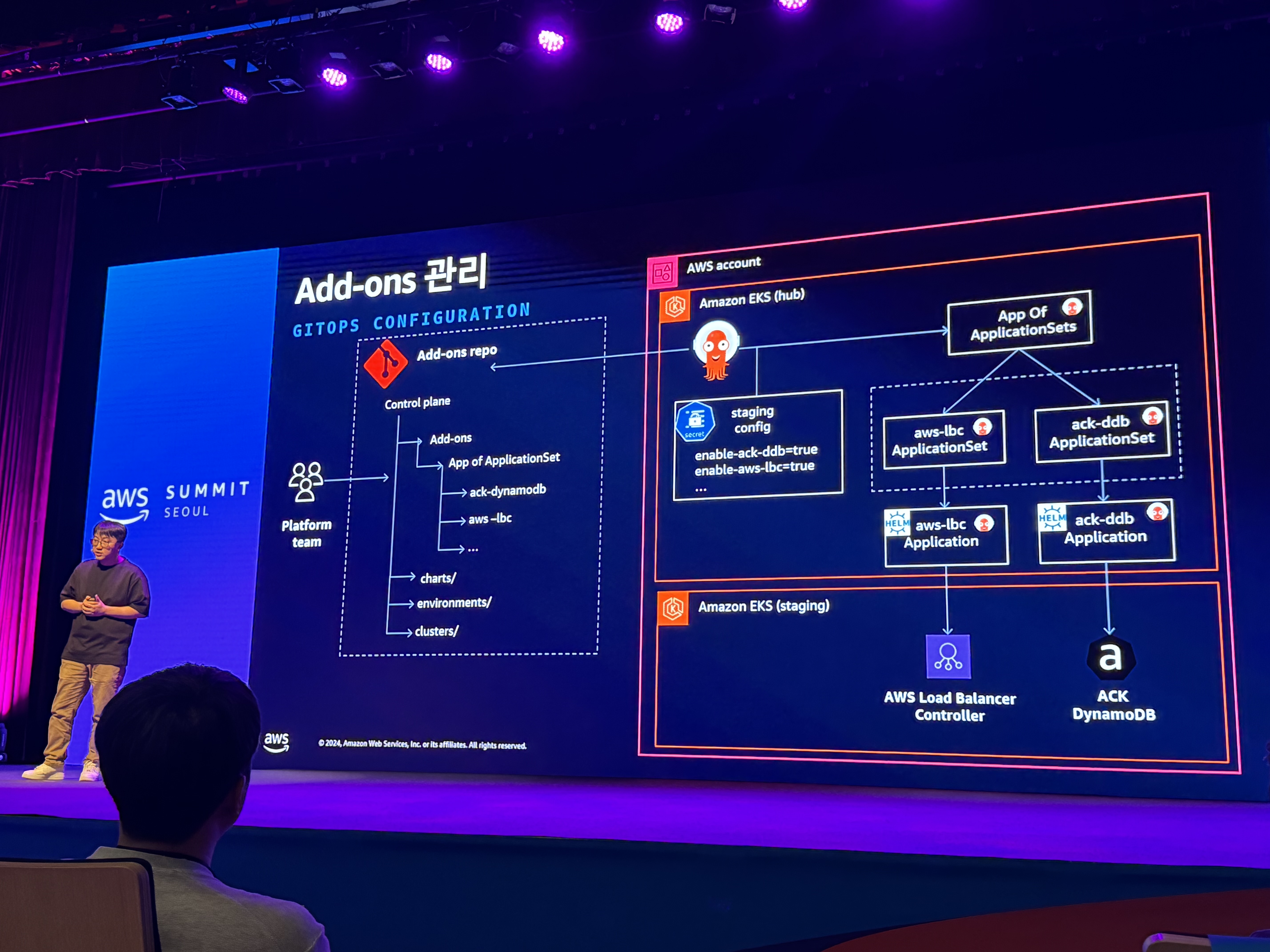
- Add-on 및 해당 dependencies 설치
- 팀 관리
- 여러 팀 간 R&R 경계 정의
- Configuration 관리
- 수십 수천개의 설정 파일
- 고객이 사용하는 도구
- CI, CD, IaC
- GitOps
- 원하는 상태를 선언적으로 표현
- → 비즈니스 위험 감소
- 원하는 상태를 불변/버전 관리 방식으로 저장
- → 변화이력 추적
- 에이전트가 원하는 상태를 자동배포
- → 보안 강화
- 에이전트는 원하는 상태를 지속적 관찰/동기화
- → 일관성 유지
- 원하는 상태를 선언적으로 표현
- 문제 해결 방법
- 클러스터 관리
- EKS blueprints
- Multi Cluster
- Add-ons 관리
- control plane
- 팀 관리
- team - repo - proj
- 클러스터 관리
2. GS리테일 클라우드 여정에서 인프라 Challenge 
- 비지니스 테넨트 분리에 따른 클러스터 증가
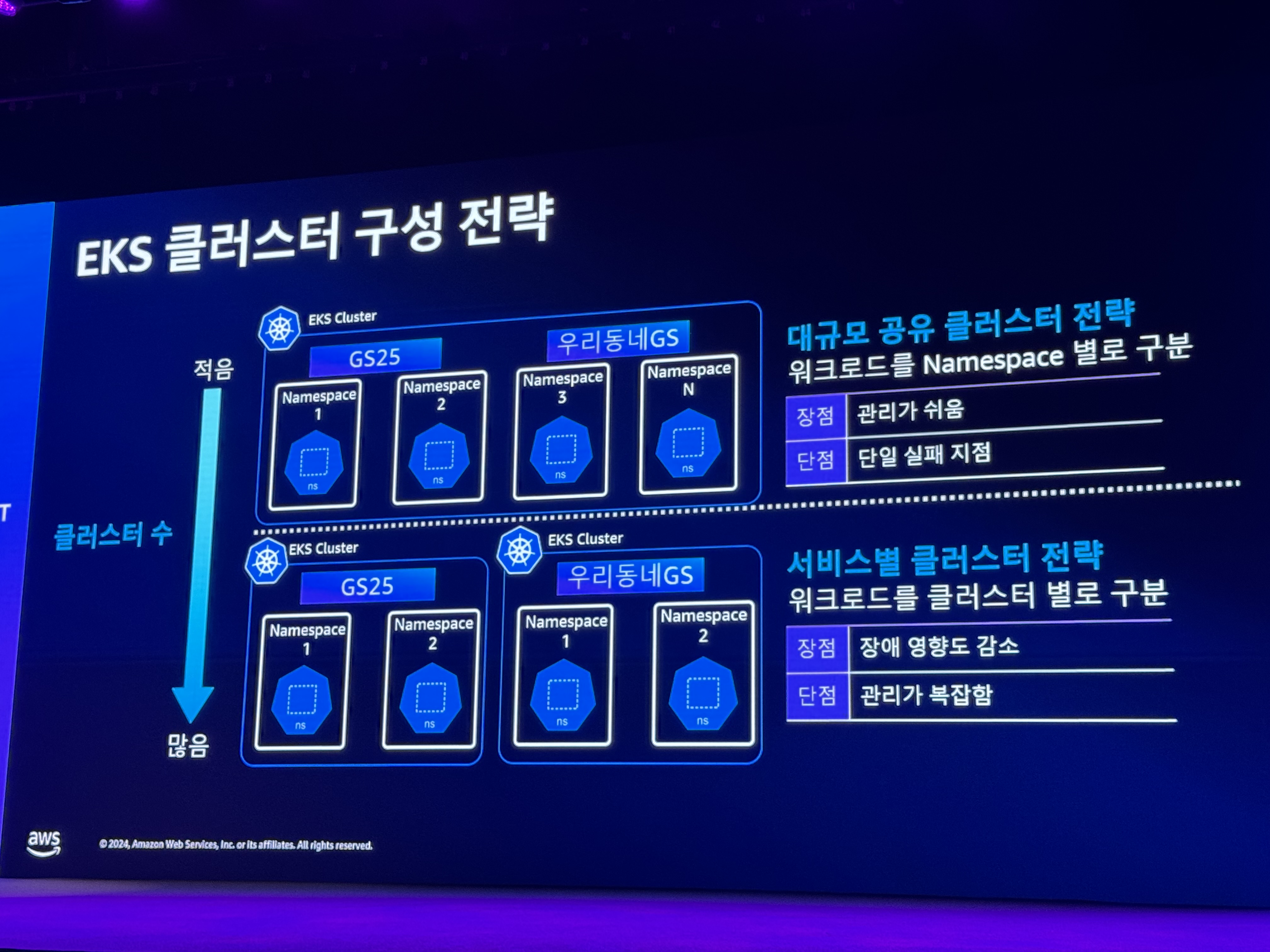
- 인프라 Challenge

- 멀티 클러스터 관리의 어려움
- CI/CD 파이프라인 관리의 어려움
- 쿠버네티스 진입장벽
- 대규모 매니패스트 관리의 어려움
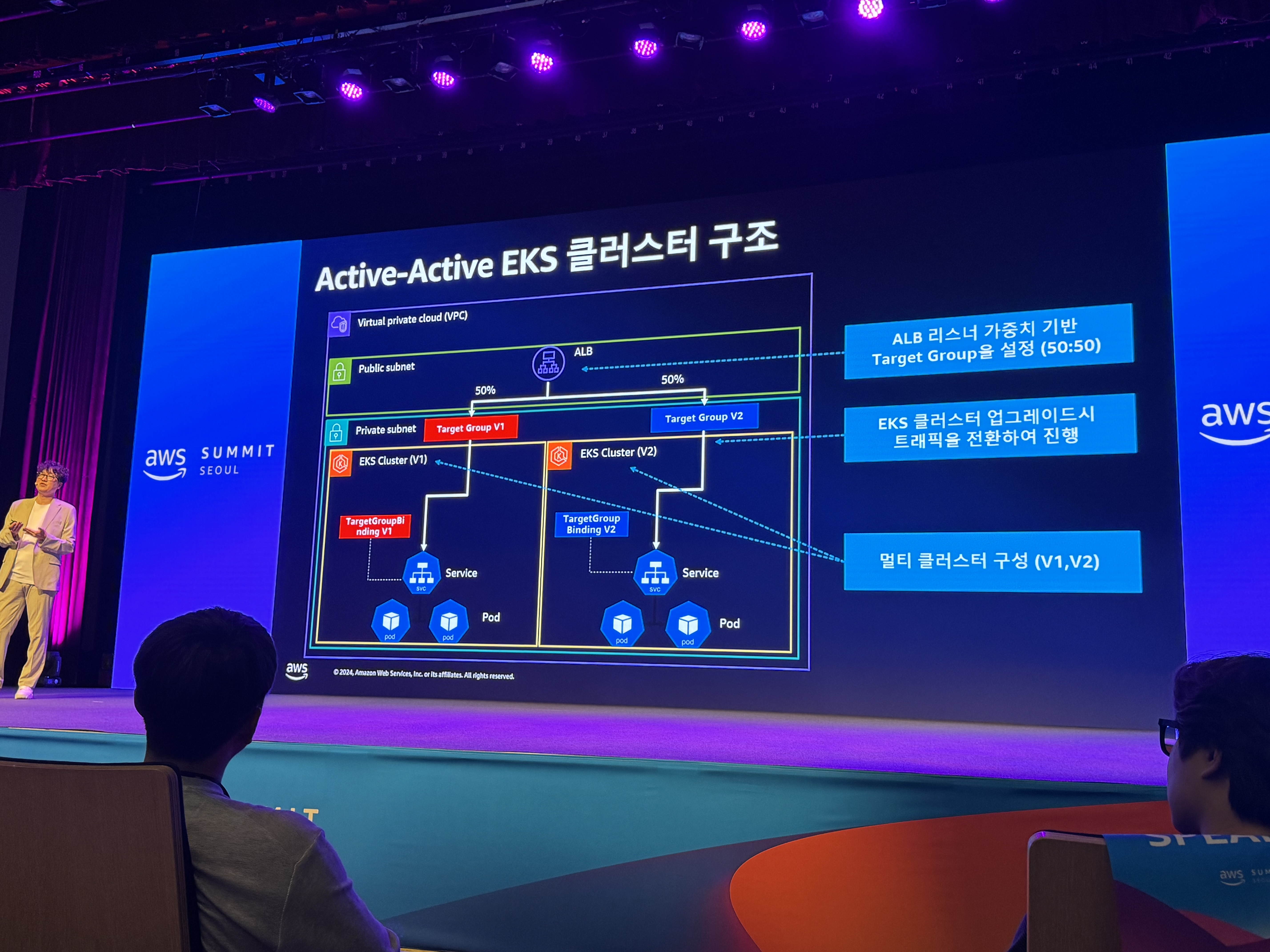
- Active-Active 클러스터 구조의 무중단 서비스 운영
- EKS 업그레이드 이슈
- 3개월 주기, 최대 14개월 지원
- 업그레이드 방식
- single
- 롤백 불가능
- multi
- blue-green
- WAF, cloudfront origin 재 등록 작업 필요
- ALB가 변경됨에 따라 Ingress 재배포
- 업그레이드 시 로드밸런서
- 로드밸런서를 사용자가 관리하는 방식으로 변경
- blue-green
- Active-Active EKS
- ALB 가중치 변경
- weight 설정 50:50으로 운영하고 잇음
- EKS 아키텍처
- Stateful 서비스는 최대한 AWS Managed SVC 활용
- Stateful App은 별도 클러스터로 분리
- active-active 구조 장점
- 0 hour
- 기술적 부채 감소
- 쿠버네티스 버전, Add-on, SW를 최신버전으로 유지
- single
- EKS 업그레이드 이슈
- 배포 템플릿화를 통한 개발 생산성 향상

- 과거 CI, CD가 합쳐져 있는 구조
- 개발자가 쿠버네티스 기본 수준을 이해해야 함
- CI/CD 이슈
- 책임 소재가 모호 - 빌드 배포:개발자, 배포된 인프라 운영: 인프라
- CI/CD 구조가 팀마다 다름
- 어떻게 해결할까?
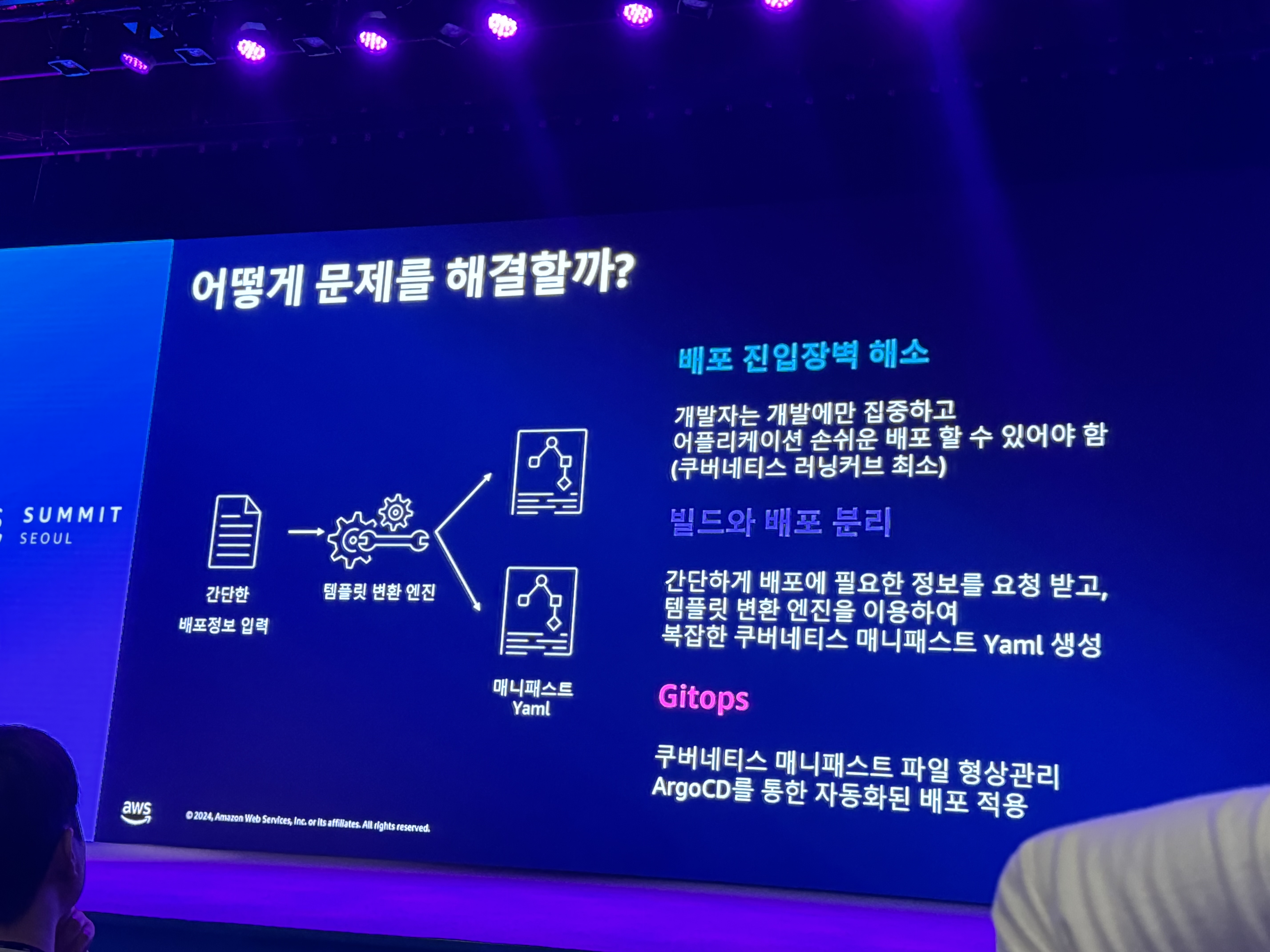
- 배포 진입장벽 해소
- 러닝커브 최소화
- 빌드와 배포 분리
- 템플릿 변환 엔진
- GitOps
- 자동화된 배포 적용
- 배포 진입장벽 해소
- 커스텀 배포 API

- 변경 후 빌드/배포 프로세스
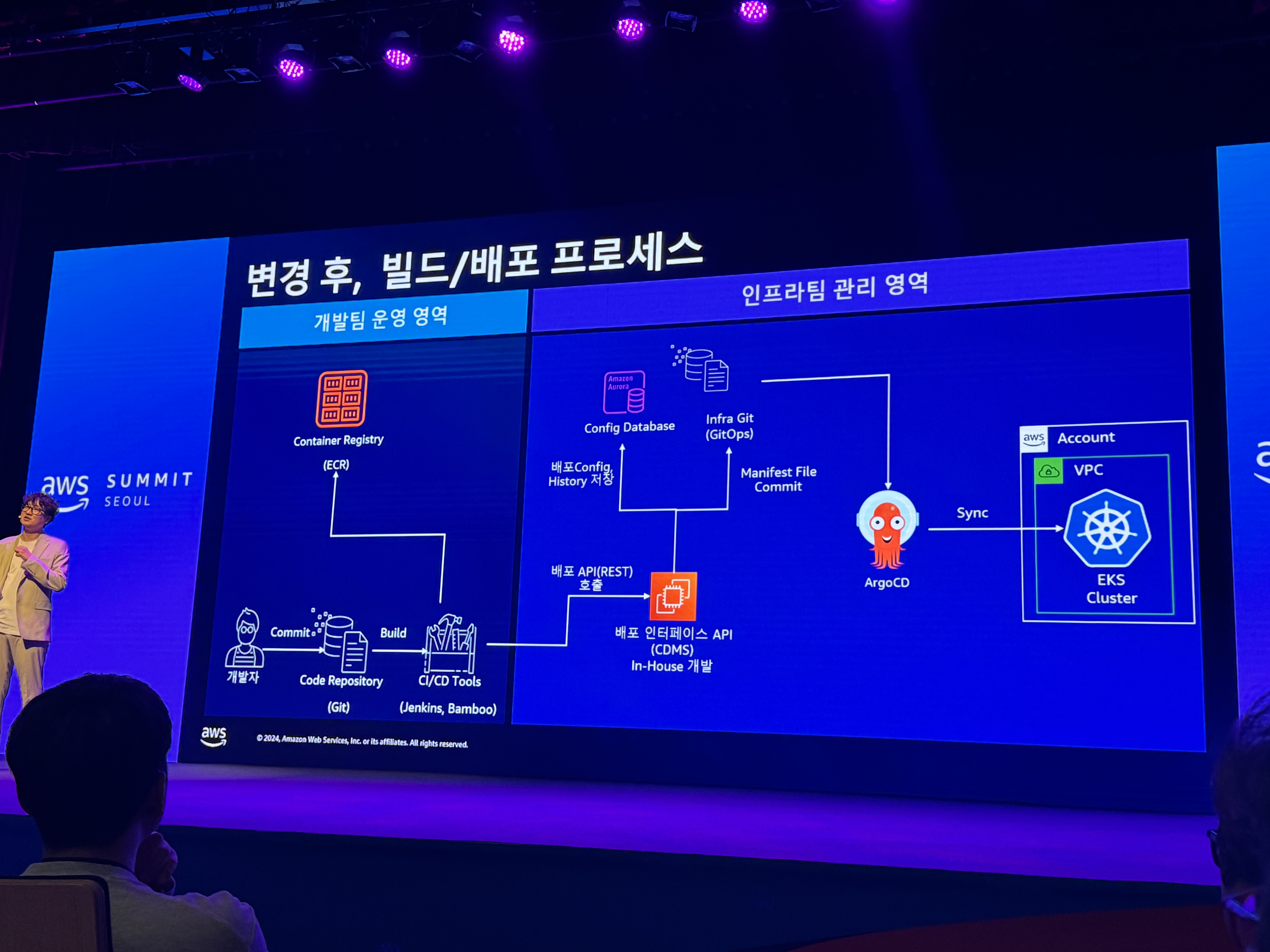
- 무엇이 좋아졌나요?

- R&R 정리
- 복잡성 해소
- 진입장벽 해소
- → 어플리케이션 개발에만 집중
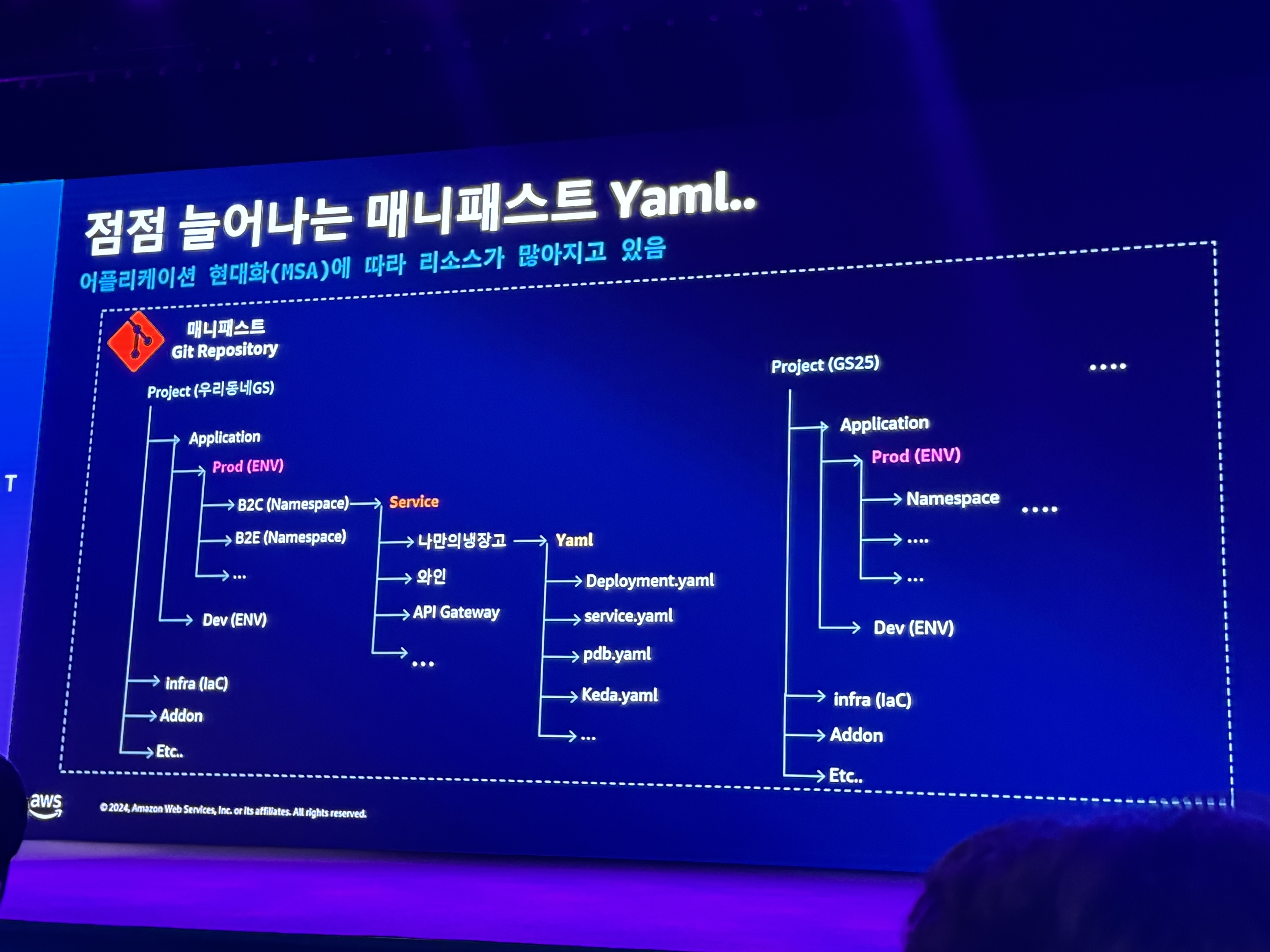
- 대규모 쿠버네티스 리소스 파일 쉽게 관리하기 - 템플릿 변환 엔진 개발
- 점점 늘어나는 매니패스트
- 템플릿 관리도구
- helm vs kustomize
- helm - 운영환경에서의 가시성 부족
- kustomize - 비공통 부문에서는 수작업 필요, 파편화 → 복잡해짐, 휴먼 리소스 부족 및 낭비가 심함
- 템플릿 변환 엔진 개발
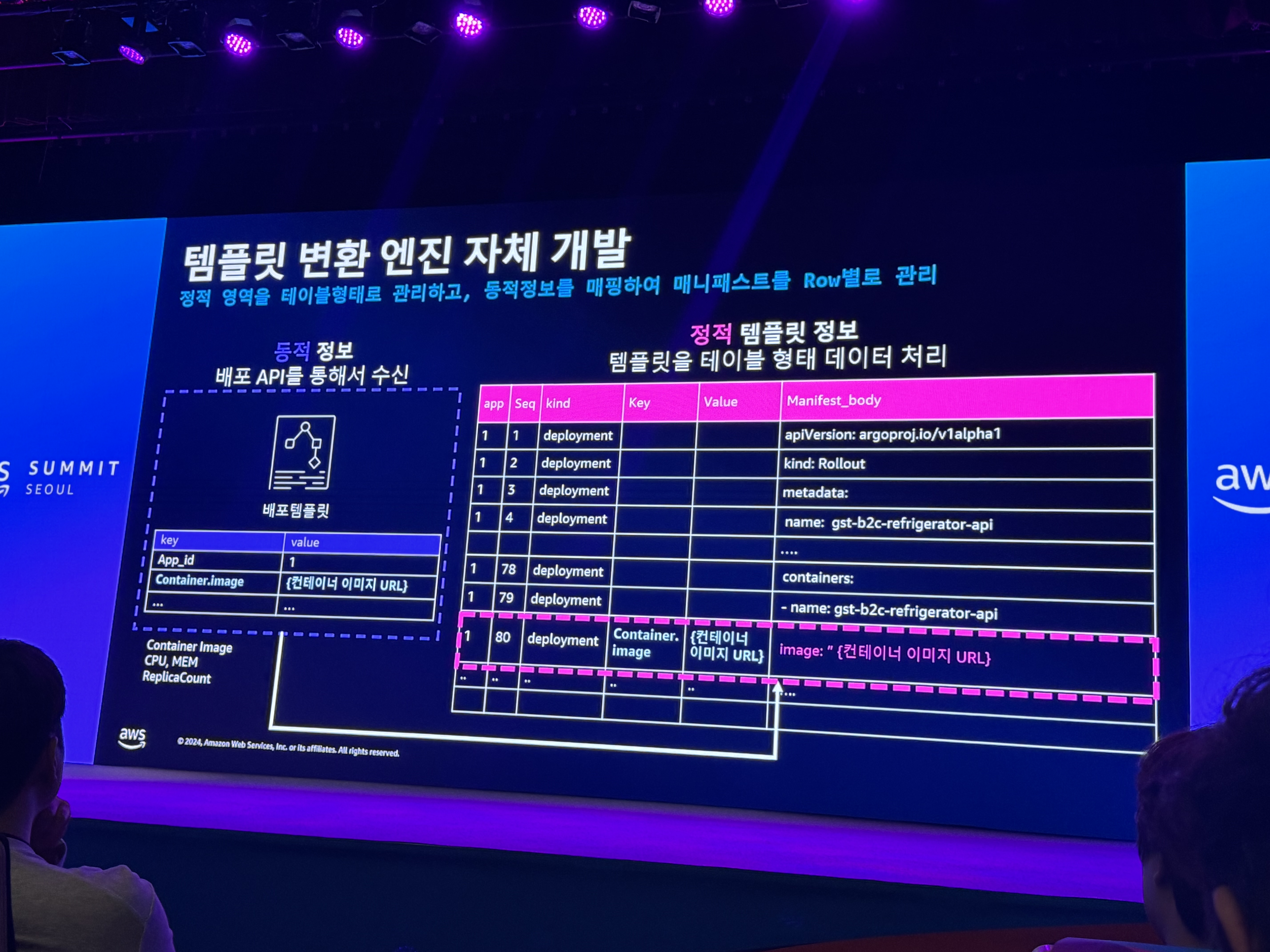
- 대규모 변경 사례

- SQL Query 기반
- 대규모 매니패스트 관리를 위한 아키텍처
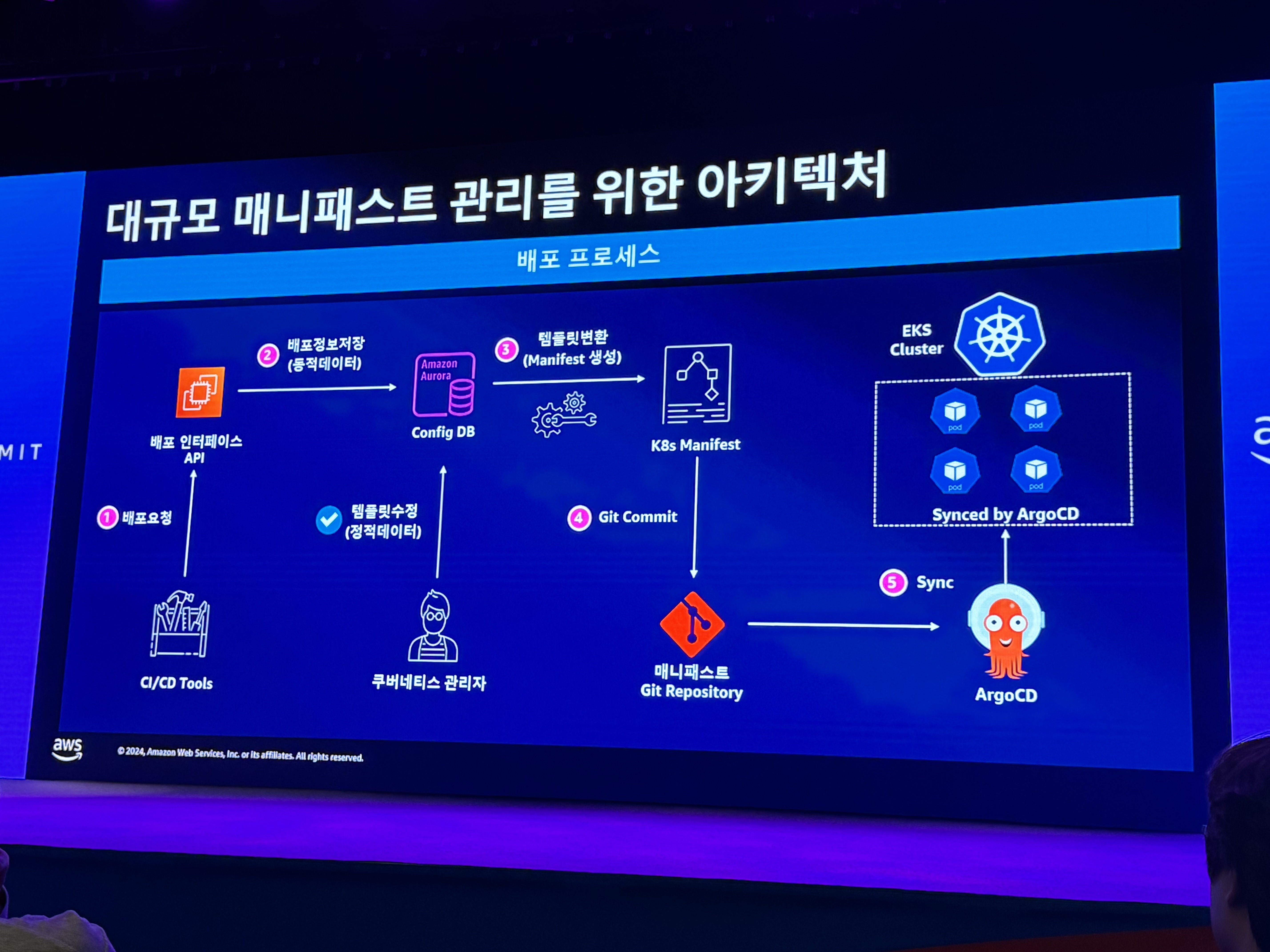
- 적은 수의 인력으로 효과적으로 운영하기 위해 이러한 방식을 선택함
- 점점 늘어나는 매니패스트
- 과거 CI, CD가 합쳐져 있는 구조
마무리

- EKS 무중단 업그레이드
- 배포 진입장벽 감소
- 대규모 매니패스트 통합 관리

최신화 계속하는 이유
- 전체적인 유지비용 감소
- 기술력의 발전을 가져온다 생각함
AWS Summit Seoul | Day 2
Agenda. Karpenter로 쿠버네티스 클러스터 최적화: 비용 절감과 효율성 향상 - L300 (2F 아셈볼룸 202-203호 - 데브옵스)

비용 절감 운영 효율성 관점
1. Karpenter 소개
- 스케일링의 필요성
- Karpenter 동작 방식
- 파드 오토 스케일링 → 보류 →
클러스터 오토 스케일러 → 오토 스케일링 그룹 - 파드 오토 스케일링 → 보류 → EC2 플릿
- NodePool, EC2NodeClass
- 파드 오토 스케일링 → 보류 →
- Karpenter 제공 기능
- 데이터 플레인 구성 및 확장
- Karpenter는 쿠버네티스 생태계의 일부 (오픈소스) - CNCF 기증
- 컴퓨팅 유연성
- 워크로드 스케줄링
- 표준 쿠버네티스 스케줄링 메커니즘
- 파드의 스케줄링 제약 조건은 노트풀에 정의된 요구사항을
- NodePool 구성 전략
- 단일 구성
- 단일 노드풀을 여러 팀과 워크로드에서 사용
- 복수 구성
- 다양한 목적에 맞게 컴퓨팅 환경 분리
- 가중치 구성
- 노드풀 가중치 구성을 통해 우선 순위 지정
- 단일 구성
- Karpenter를 활용한 비용 최적화
- consolidationPolicy
- 워커 노드의 활용도 향상 → 비용 절감
- 통합 기능 활성화
- 더 나은 워커 노드 선택 → 비용 절감
- 카펜터를 활용한 운영 효율화
- 데이터 플레인 관리 간소화
- 카펜터를 사용한 스팟 중단 대처
- 스팟 중단 알림
2. Karpenter 심층 분석
- 스케줄링
- 배치
- 확장 윈도우 알고리즘 [1, 10]초
- 유휴 대기시간: 1초
- 최대 10초
- 확장 윈도우 알고리즘 [1, 10]초
- 빈 패킹
- 스케줄링과 빈패킹 시뮬레이션 결합
- 노드풀과 파드 요구사항의 교집합 정의
- 호스트 포트 볼륨 토폴로지 볼륨 사용량 고려
- 데몬셋 스케줄링 고려
- 더 적은 수의 보다 큰 인스턴스 타입 선호
- 사용률 최적화가 아닌 비용 최적화
- 인스턴스 유형 디스커버리 → 비용 순으로 인스턴스 정렬 → 요구사항 교집합 → 재사용 스케일업 또는 생성
- 의사 결정
- ec2 생성 (EC2 Fleet API를 사용해서) - 가용 영역 + 용량 타입 + 가격
- 다양한 인스턴스 유형 정의를 통한 유연성 확보
- 온드맨드 할당 전략 - lowest-price
- 스팟 할당 전략 - price-capacity-optimized
- Karpenter Drift
- Karpenter 커스텀 리소스 값이 운영중인 머신과 일치하지 않는 상황
- 머신 노드 인스턴스의 변경 혹은 노드풀 노드클래스의 변경에 의해 발생
- karpenter-global-settings 컨피그맵에서 설정 (v.0.33.0 이상 자동 활성화)
- EC2NodeClass로 노드 환경 선택
- Drift 기능을 활용한 패치 및 업그레이드
- AMI를 사용하는 경우 amiFamily AL2
- 최신 ami 정보를 확인하여 가져옴
- karpenter는 parameter store에 저장해둠
- cluster version 업그레이드에도 적용
- 제로 터치로 항상 최신 EKS AMI 사용
- 노드 중단(disruption) 심층 분석
- 파드 버짓(PDB)을 활용한 고가용성 유지
- 종류: Expiration, Drift, Consolidation, Interruption
- 자발적 vs 비자발적 중단
- 중단의 영향: DNS, 캐싱
- 표준화 된 중단 워크플로우
- 후보 노드 식별 → 대체 노드 생성 → 후보 노드 드레이닝 → 후보 노드 종료
- 종류
- Drift
- 스펙 해시: 테인트, 라벨
- 주기적 폴링: Requirement 필드 및 ami
- Expiration
- 특정 기간 이후 노드 삭제
- Interruption
- 스팟 용량
- 헬스 이벤트
- Consolidation
- 비용 최적화
- 노드 → 0, 노드 → 1
- 주어진 제약 조건에 따른 비용 최적화
- 스케줄러, 빈패킹, 런처 로직 활용
- 후보 노드 선정 기준?
- 노드 중단 가능 여부
- 파드 중단 최소화
- 오래된 노드 선호
- 규모에 따른 컴퓨팅 비용 증가
- Drift
3. 위대한 상상 Karpenter 도입기
- aws 아키텍처
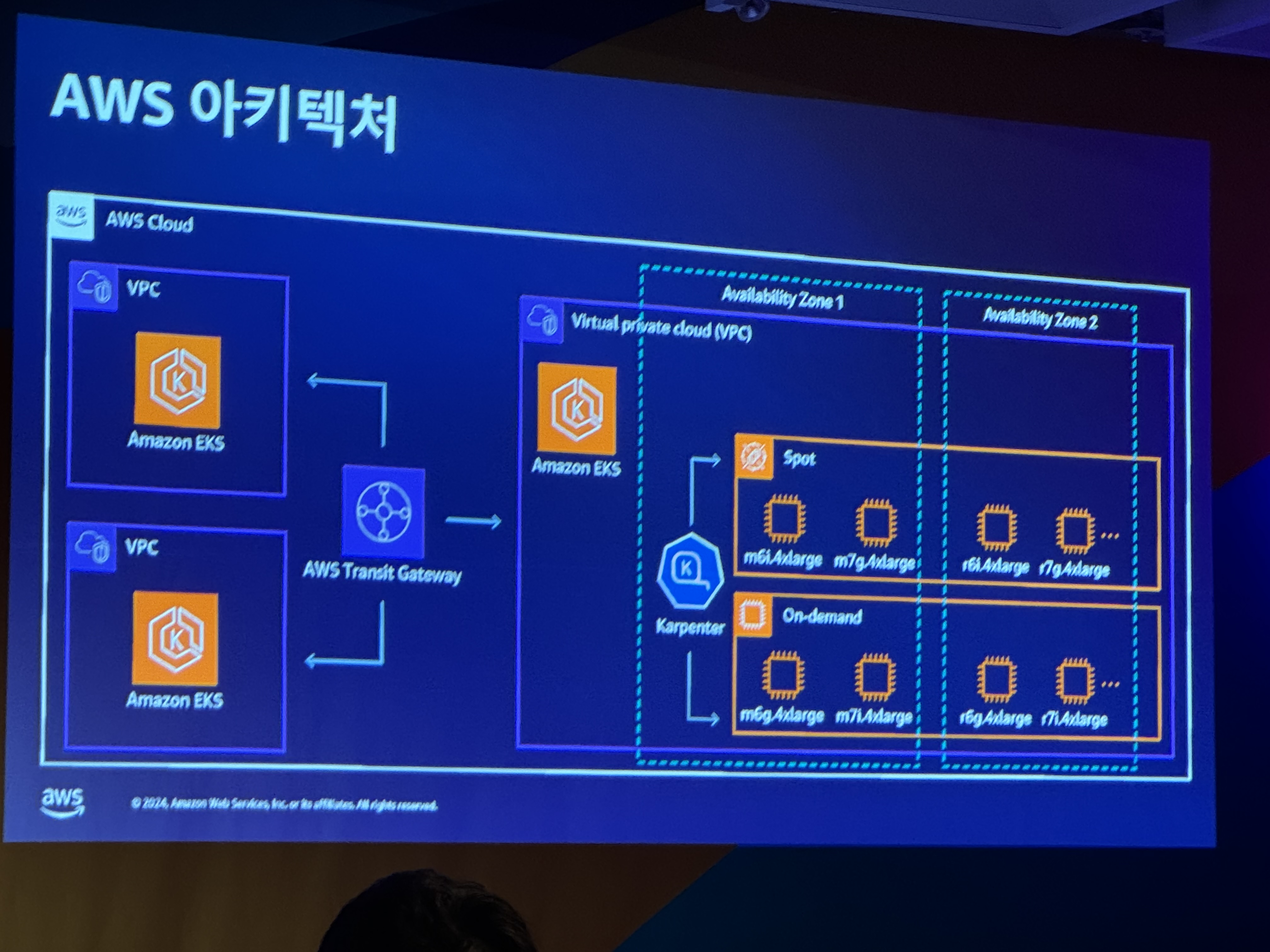
- nodepool 구성
- kubelet
- name
- System
- On-demand
- Spot
- Airflow
- Admin
- EC2NodeClass 구성
- 리소스 태깅 - 비용 추적
- 블록 디바이스 매핑
- 사용자 데이터 정의 - kubelet 추가 설정 - 빠르게 이미지를 땡기기 위해서
- 서브넷 지정
- 파드 스케줄링 고려사항
- 워크로드의 특성
- 네트워크 성능
- 그레이스풀 셧다운 시간
- 파드 버짓pdb
- spot의 경우 pod가 빨리 빠질 수 있도록 고려 - 30% 등
- 초기 CPU 사용량
- 워크로드의 특성
- 노드 오버 프로비저닝 전략
- 파드 우선 순위 (priorityClass)
- 가용 영역 분산 (topologySpreadConstraints)
- 파드 안티 어피니티 (podAntiAffinity)
- KEDA를 활용한 파드 스케일링 (CPU 코어 수) - 피크시간에 더 많은 노드가 배치될 수 있도록 함
- Karpenter 도입 효과
- 70% 비용 절감
- 75~93% 스팟 인스턴스 사용율
- 1.5x 노드 프로비저닝 속도
- 80% CPU 할당율
Agenda. 하시코프, 클라우드 시크릿의 보안 생명주기를 한 곳에서 한 번에 관리하기 - L200 (1F 그랜드볼룸 101호 - 고급 아키텍처)

1. 하시코프 클라우드 플랫폼 
- AI 시대에 맞는 프로세스 확립
- 애플리케이션, 인프라스트럭처, 보안의 생명 주기 관리
- 인프라스트럭처, 보안 - HashiCorp
- 애플리케이션, 인프라스트럭처, 보안의 생명 주기 관리
- 클라우드 환경에서의 자동화 보안강화 표준화 솔루션을 제공하고 있음
- 클라우드 성공을 위한 전략
- stage1. 도입 / 채택
- stage2. 표준화
- stage3. 확장
- 보안 생명주기 관리, 시크릿 변경 자동화

- 도입 채택 단계
- 표준화 단계 (운영 및 보안)
- 시크릿이란?
- 보호된 리소스 또는 민감한 정보의 잠금을 해제하는 키로 작동하는 중요 정보
2. 하시코프 볼트, 보안 생명 주기 관리 
- 클라우드 시크릿, 키 관리의 고려 요소
- 누가: 인증 (자격 증명)
- 무엇에: 대상 지정
- 얼마동안: 접근 허용 시간 지정 (TTL)
- 라이프 사이클: 시크릿, 키 생성 / 갱신 / 폐기 자동화
- 하시코프 볼트: 시크릿에 대한 접근을 관리하고 민감한 데이터를 보호하기 위한 보안 자동화 표준
- 자동화 및 최적화
- 가시성 및 정책
- 신회성 및 확장성
- 통합 및 API
- 거버넌스/컴플라이언스 위험 관리
- 하시코프 볼트 주요 사례
- 클라우드 접근키 관리
- 시스템 접근키 관리
- 데이터베이스 크리덴셜 관리
- 애플리케이션 시크릿 중앙 관리 (KeyValue Store)
- 클라우드/시스템 접근 관리 방안
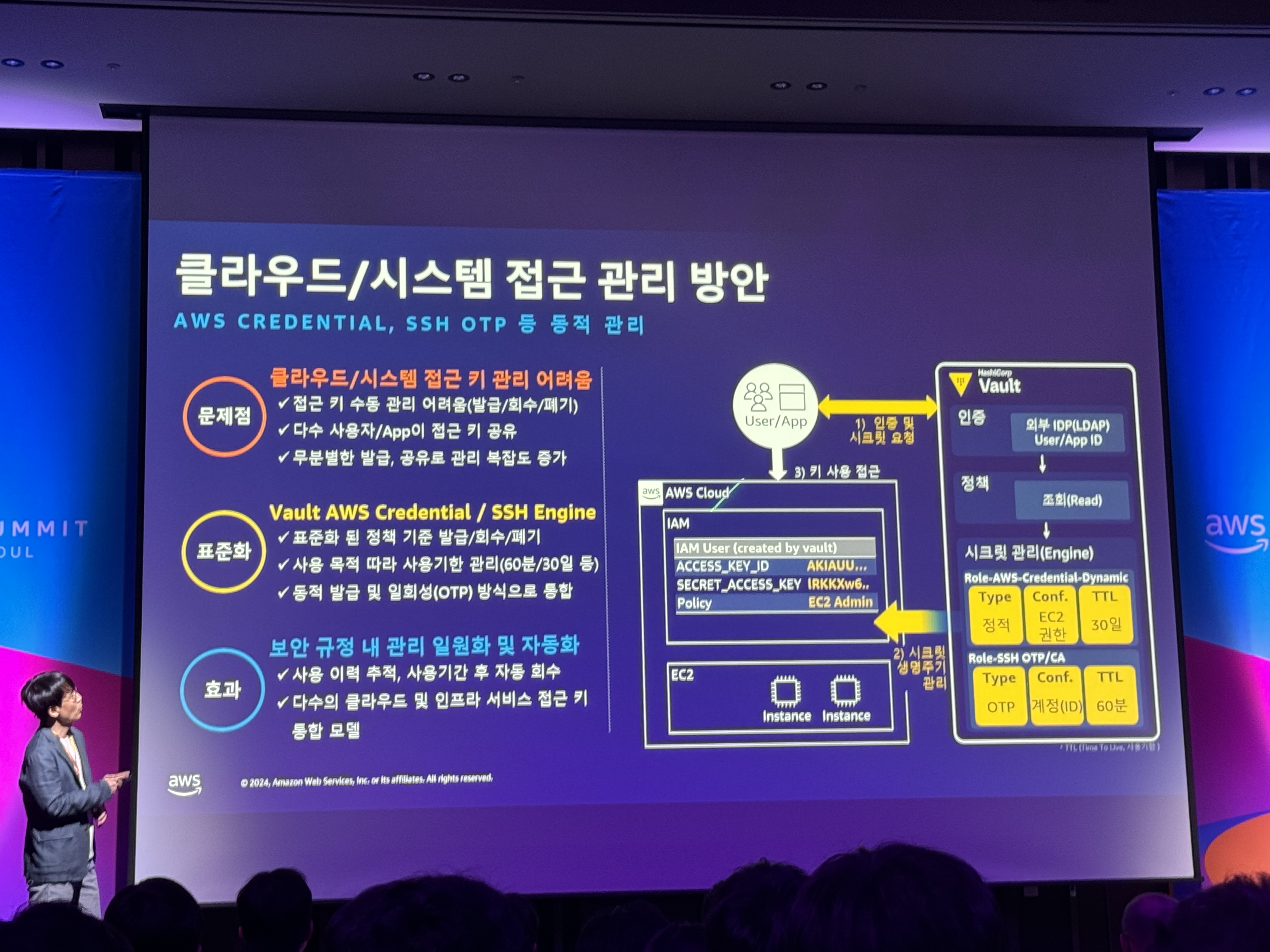
- 문제점: 클라우드/시스템 접근 키 관리 어려움
- 표준화: Vault AWS Credential / SSH Engine
- 효과: 보안 규정 내 관리 일원화 및 자동화
- 데이터베이스 계정 관리 방안
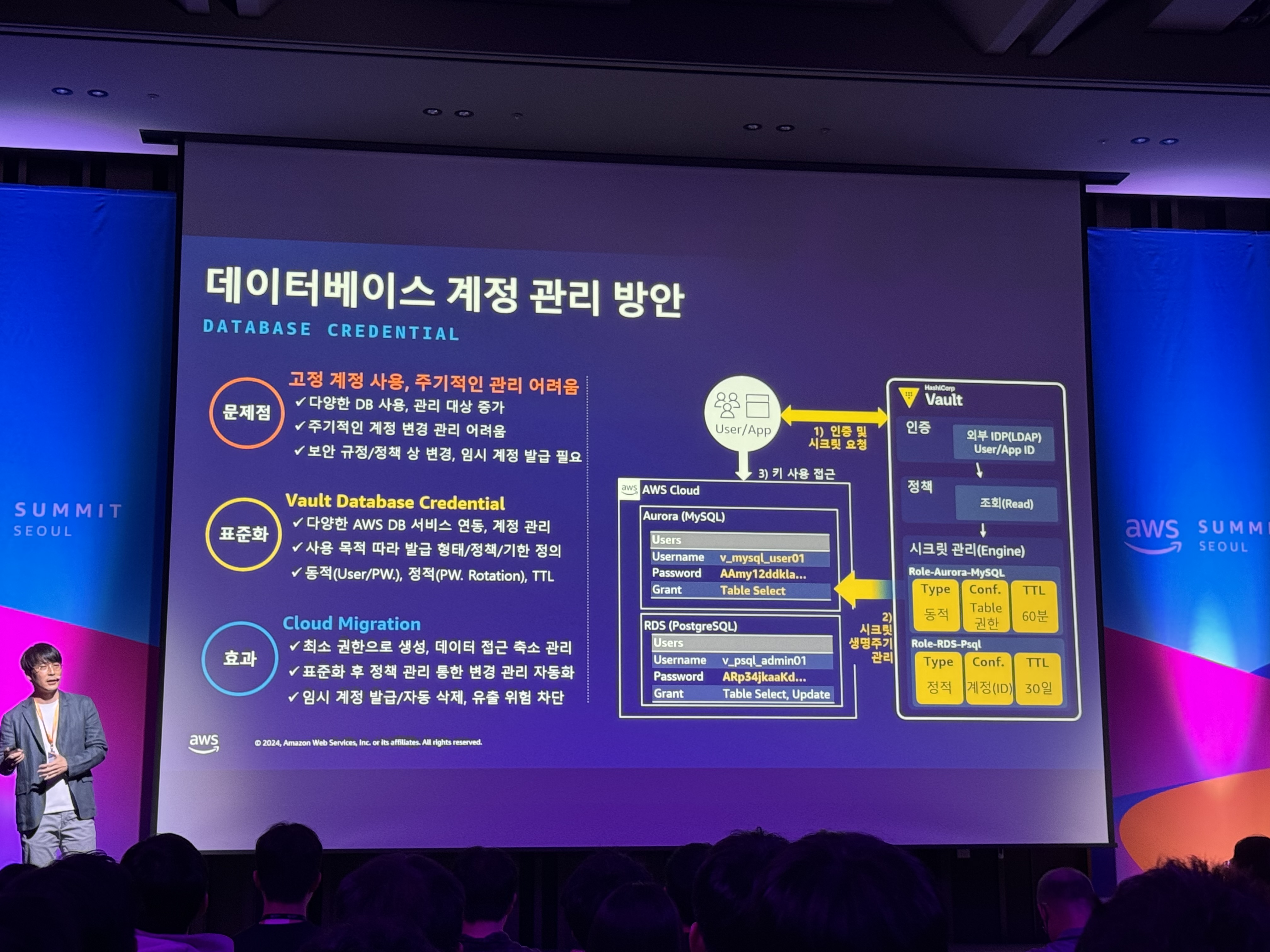
- 문제점: 고정 계정 사용, 주기적인 관리 어려움
- 표준화: Vault Database Credential
- 효과: Cloud Migration
- AWS Lambda 관리 방안

- 문제점: 코드 내 민감한 정보 하드코딩
- 표준화: Vault Lambda Extension / KV Store
- 효과: 함수 코드의 자동화 환경 보안 강화
- Kubernetes Secrets 관리 방안
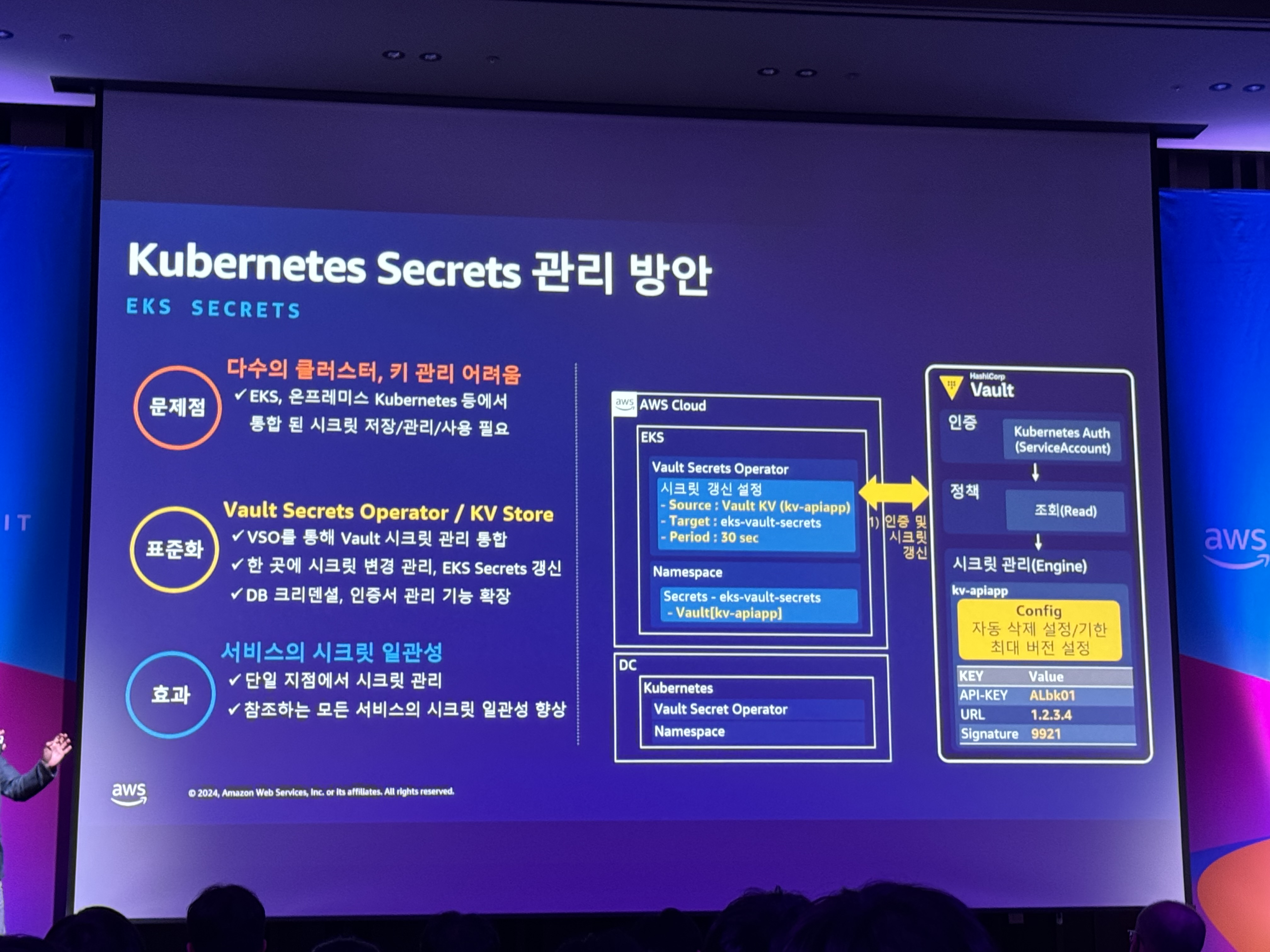
- 문제점: 다수의 클러스터, 키 관리 어려움
- 표준화: Vault Secrets Operator / KV Store
- 효과: 서비스의 시크릿 일관성
- Jenkins, Argo, Gitlab 등 Pipeline 관리 방안
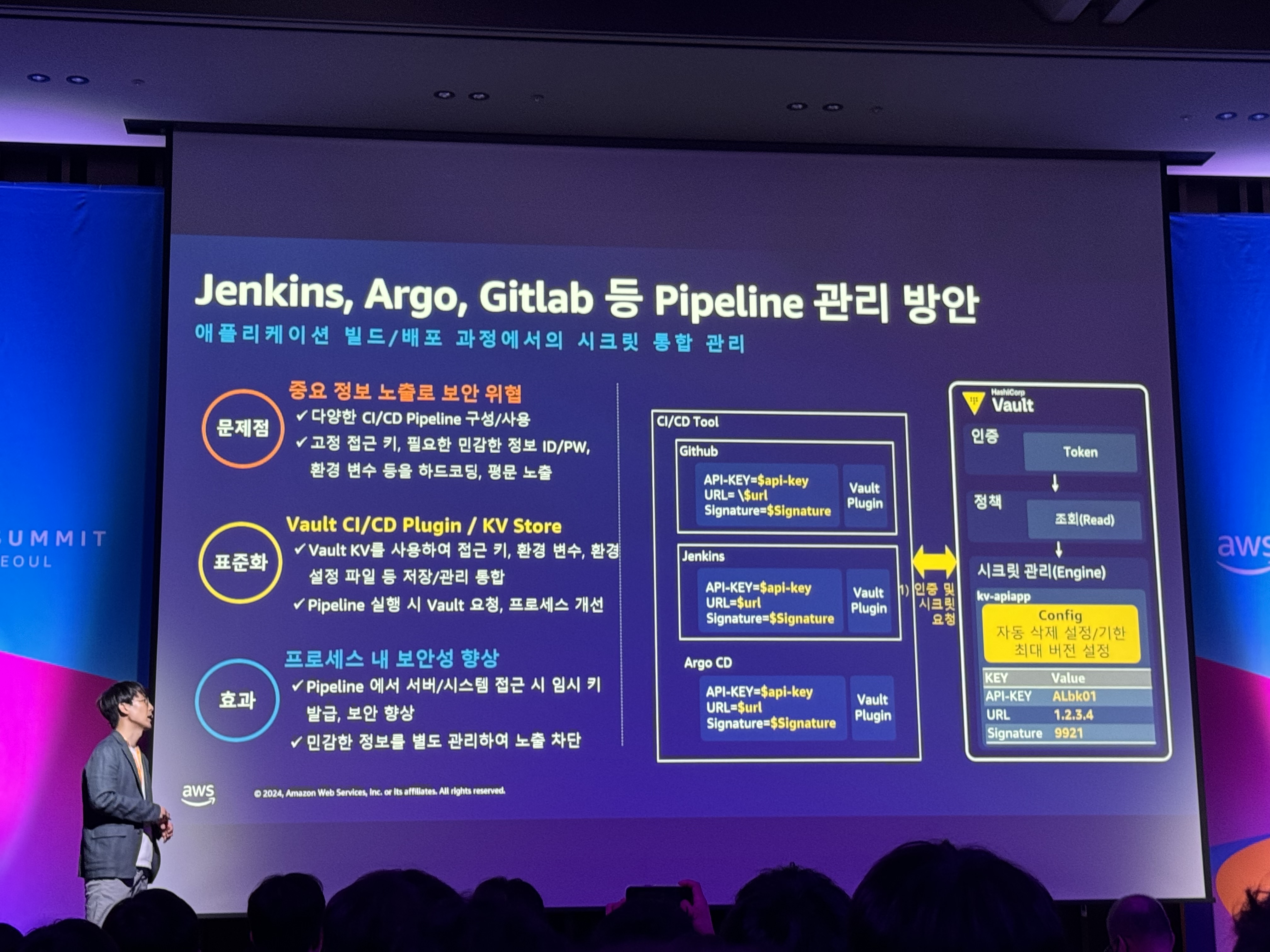
- 문제점: 중요 정보 노출로 보안 위협
- 표준화: Vault CI/CD Plugin / KV Store
- 효과: 프로세스 내 보안성 향상
3. 시크릿 관리 표준화 및 통합
-
클라우드 시크릿 보안 생명주기 관리, 성숙도 모델


-
시크릿 분류에 따른 표준화 과정

- 노출 위험을 줄이기 위한 3가지 과제
- 확산 요소 제거
- 노출 위험 우선순위에 따른 정책 적용
- 사전 예방.
- 노출 위험을 줄이기 위한 3가지 과제
-
사전 예방을 위한 시크릿 노출 검색
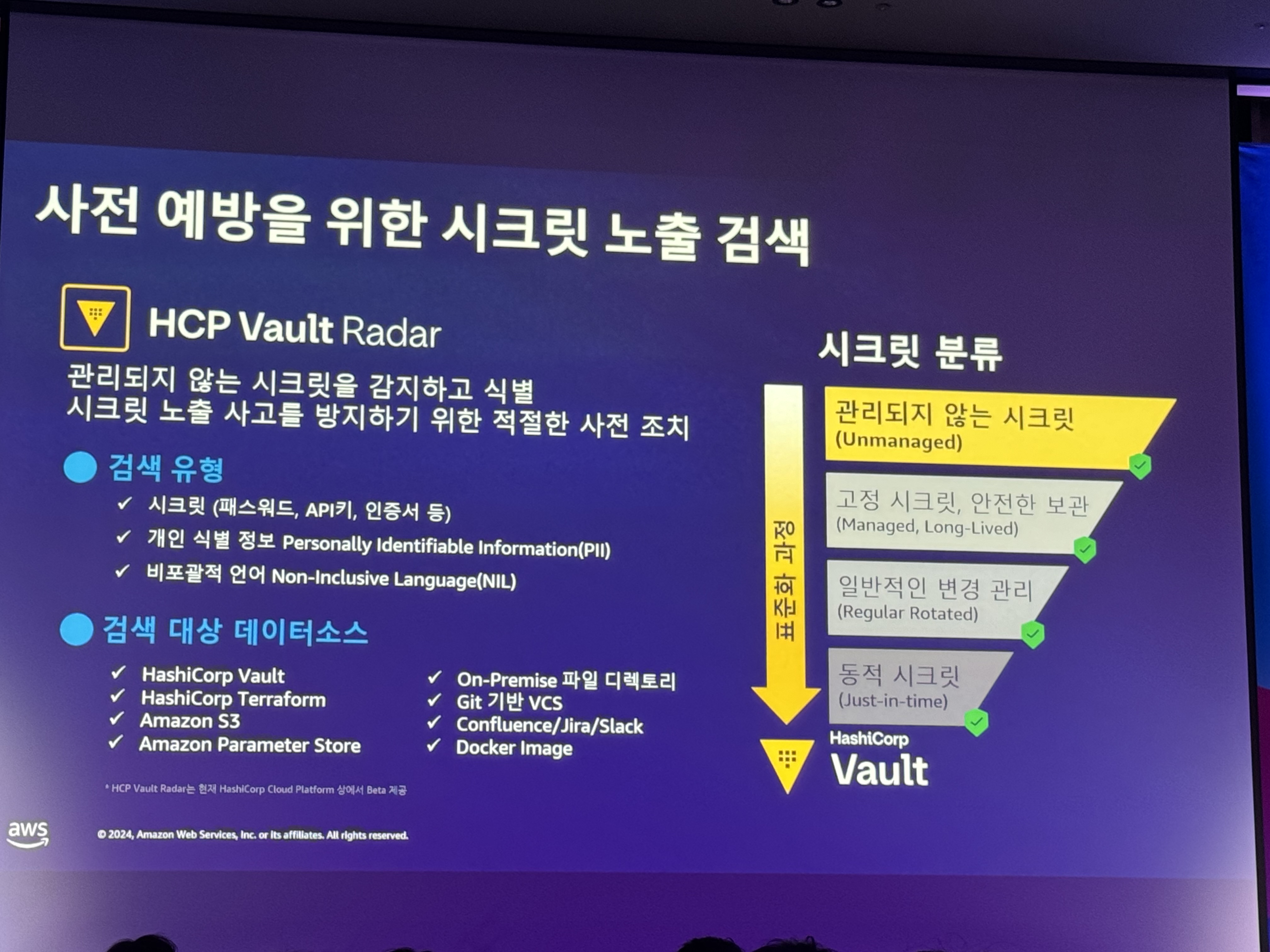
- HCP Vault Radar
- 관리되지 않는 시크릿을 감지하고 식별
- 시크릿 노출 사고를 방지하기 위한 적절한 사전 조치
- 검색 유형
1. 시크릿
2. 개인 식별 정보
3. 비포괄적 언어 - 검색 대상 데이터소스
1. vault, terraform, s3, parameter store, on-premise 파일 디렉토리 - 프로세스

1. 데이터 소스 등록 및 탐색
2. 노출 위험도 분석, 조회
3. 노출 시크릿 확인/조치
- 시크릿 관리 강화, 표준화 시작 시점



- APP 현대화 단계가 가장 중요 - 큰 어려움 없이 도입을 할 수 있다. - 궁극적인 목표 → 전사적인 시크릿 관리 표준화

- 표준화를 해야지만 자동화를 할 수 있다
- 1.모든 클라우드 모든 시크릿의 통합관리
- 2.서비스 단위의 시크릿 관리
- 3.단일팀의 시크릿 관리 (전사 통합 및 표준화) - 시크릿 운영팀
- 하나의 팀에서 만들고 관리하고 확산시키는 것이 목표
- 다양한 활용 분야
- cloud credential
- ssh key
- db credential
- PKI
- k8s secrets 등
- HCP Vault Radar
Review


Day 1.
- 장애 조치 아키텍처 사례를 보며 어떠한 관점에서 테크니컬하게 접근해야 하는지 방향성을 제시받은 것 같다.
측정에 대한 기준을 명확히 설명해주어 복원력 강화를 위한 여정에 발을 디딘 것 같다. 이러한 문화를 빠르게 적용할 수 있다면 더욱 안정적인 서비스를 위한 환경을 갖출 수 있게될 것 같다. - CI/CD를 개선하기 위한 대규모 개편이 쉽지 않다고 생각하는데, 이러한 도전에 박수를 쳐주고 싶다. 커스텀 배포 API 배포 자동화 시스템 구현은 헤비하다고 느껴지기도 했지만 사내시스템을 보유하고 있다는 것은 좋은 의미로 보았다.
Day 2.
- Karpenter의 심층 분석시간에 Karpenter의 스케줄링, 배치, 빈패킹 과정에 대해 설명하는 부분이 생각보다 유익했다. 추가적으로 EC2NodeClass의 사용자 데이터 정의 (kubelet 설정 등)을 통해 Image를 더욱 빠르게 준비할 수 있도록 하는 설정이 인상깊었고 PDB의 퍼센티지 운영에 대한 고민을 다시 하게 된 계기가 되었다.
- Vault의 주요 사례를 예로 들면서 문제점, 표준화, 효과를 설명해주는 것이 좋았다. 궁극적으로 시크릿 관 리를 강화하고 표준화를 시작해야 하는 시점을 점검하여 단계를 체크할 수 있는 부분에 대한 설명이 가장 인상깊었다.
