Process와 Thread가 무엇일까 🤓
Process
: 실행중인 프로그램
- 논리적인 연산장치
- 올라갈 때 code, data, stack, heap 공간 등을 잡기 때문에 무거움
- 물리적인 매체에 저장되어있는 프로그램이 메모리에 올라가서 프로세서에 의해 실행중인 것
Process의 상태 변화
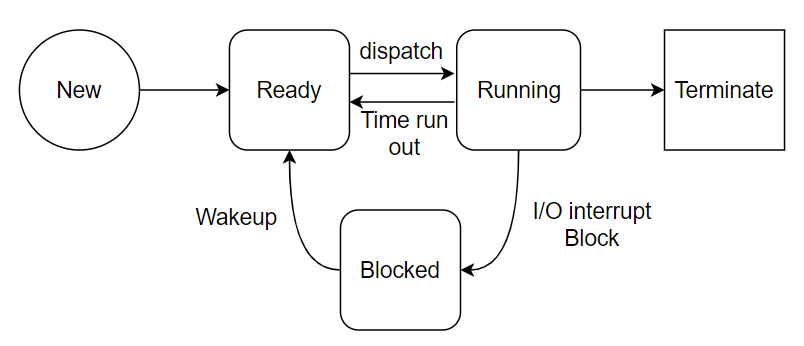
New: 프로세스가 메모리에 올라와 실행 준비를 완료한 상태 (스레드가 생성되고 start()가 호출되지 않은 상태)Ready: 프로세서에서 실행되기 위해 대기하는 상태 (start()가 호출된 상태)Running: Ready 상태에 있는 프로세스 중 하나가 CPU 스케줄러를 통해 선택이 되어 작업을 수행하는 상태Blocked: 특정 자원이나 이벤트를 기다리는 상태Terminate: 프로세스가 종료된 상태
Thread
: 한 프로세스 내에서 나뉘어진 하나 이상의 실행 단위
- 프로세스의 자원을 이용해서 실제로 작업을 수행하는 것
- 기존에 올라가있는 프로그램 내에서 별도로 생성이되어 코드와 static 메모리를 공유하기 때문에 resource 차원에서 프로세서보다 가볍다
* main스레드의 경우 Single Thread여서 순차적으로 실행됨
Thread의 상태 변화
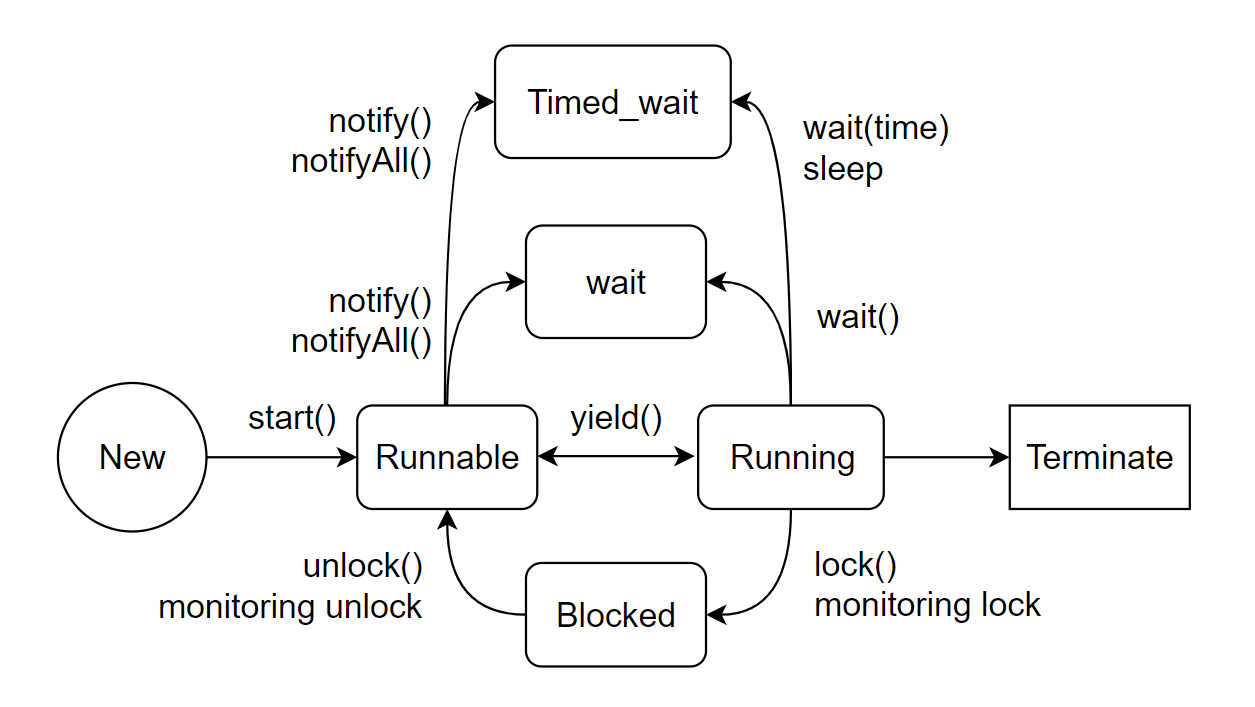
New: 스레드가 실행 준비를 완료한 상태Runnable: start()가 호출되어 실행될 수 있는 상태Waiting: 다른 스레드가 통지할 때까지 기다리는 상태Timed_Waiting:정해진 시간동안 기다리는 상태Blocked: 사용하고자 하는 객체의 잠금(Lock)이 풀릴 때까지 대기하는 상태Terminate: 실행이 종료된 상태
Thread 상태 변화 메소드
| 메소드 명 | 설명 | 상태 변화 |
|---|---|---|
sleep() | 실행 중인 스레드를 파라미터에 주어진 시간만큼 잠시 Timed_waiting 하게 만듦. | Running → (메소드 호출 후) Timed_waiting → Runnable |
join() | join() 메소드를 호출한 스레드가 종료될 때까지 기다리도록 스레드를 Wait 상태로 만듦. | Running → (메소드 호출 후) Waiting → Runnable |
interrupt() | 일시정지 상태인 스레드를 깨워서 실행가능한 상태(실행대기 상태)로 만듦. (단지 작업 취소를 요청만 하는 것이지 스레드를 강제로 종료시키지는 못함) | Waiting → (메소드 호출 후) Runnable |
yield() | 자신에게 주어진 실행시간을 동일하거나 높은 우선순위를 가진 스레드에게 양보함. | Running → (메소드 호출 후) Runnable |
* Object 클래스에 정의되어 있는 메소드
: synchronized 블럭 내에서만 사용 가능 (호출하는 스레드가 반드시 고유락을 갖고 있어야 함)
wait(): 실행 중이던 스레드는 해당 객체의 waiting pool에서 notify( )를 기다림.notify(): 해당 객체의 waiting pool에 있던 스레드 중 임의의 스레드만 Runnable하게 만듦.notifyAll(): waiting pool에 있는 모든 스레드를 Runnable하게 만듦.
실행 후 스레드 상태 변화
- 쓰레드를
New(생성)하고start()를 호출하면 바로 Running하는 것이 아니라 실행대기열에 저장되어 차례가 될 때까지 기다려야한다. - Runnable 상태였다가 자기 차례가 되면 Running 상태가 된다.
- 주어진 실행 시간이 다 되거나
yield()를 만나면 다시 Runnable상태가 되고 다음 차례의 스레드가 Running 상태가 된다. - 실행 중에
sleep(),wait(),join(),I/O block에 의해 Waiting 상태가 될 수 있다. - 일시정지 시간이 다 되거나
notify(),interrupt()가 호출되면 일시정지상태를 벗어나 다시 실행대기열에 저장되어 차례를 기다리게 된다. - 실행을 모두 마치거나
stop()이 호출되면 스레드는 소멸된다.
<Process와 Thread 비교 예시>
스터디룸을 빌리는 경우로 생각해봤을 때
프로세스의 경우 항상 사용해야되는 책상과 의자를 사용이 끝나면 모두 치우고, 새로운 예약이 들어올때마다 새로 setting 해야한다.(context switching) 하지만 스레드의 경우 책상과 의자를 (공유되는 자원) 프로세스처럼 매번 다시 setting 할 필요가 없다 (캐싱 적중률 ↑)
멀티 프로세스 (Multi-process) / 멀티 스레드 (Multi-thread)
: 멀티 프로세스는 두 개 이상 다수의 프로세서(CPU)가 두개 이상의 작업을 동시에 처리하는 것이고,
멀티 스레드는 하나의 프로세스에 여러 스레드로 자원을 공유하며 작업을 나누어 수행하는 것이다.
즉, 한 어플리케이션에 대한 작업을 동시에 하기 위한 2가지 처리방식이라고 할 수 있다.
멀티 프로세스는 독립적인 메모리를 가지고 있지만,멀티 스레드는 자원을 공유하여 스레드끼리 긴밀하게 연결되어 있기 때문에 하나의 스레드에 문제가 생기면 전체 프로세스에 영향을 준다.멀티 프로세스는 개별 메모리를 사용하기 때문에 context switching 비용이 큰 반면,
멀티 스레드는 공유된 자원을 사용하여 메모리가 효율적이고 context switching 비용 역시 적다.멀티 프로세스는 동기화 작업이 필요하지 않지만,멀티 스레드는 자원을 공유하기 때문에 동기화나 교착상태 등의 문제가 발생할 수 있어 공유자원 관리를 해줘야할 필요 있다.
CPU의 코어는 한 번에 단 하나의 작업만 수행할 수 있는데,
동시에 실행이 되는 것처럼 보이기 위해서 실행 단위는 시분할로 cpu를 점유하여 context switching을 함
* Context Switching이란?
: CPU에서 여러 프로세스를 돌아가면서 작업을 처리하는 과정Thread를 생성해보자! 😊
1. Thread 클래스 상속
public class 클래스이름 extends ThreadThread 스레드이름 = new Thread();- 객체를 생성하여 바로 실행이 가능하여 편리하다.
- 자바에서는 두 개이상의 클래스를 상속할 수 없으므로 다른 클래스를 상속해야 하는 경우에는 사용이 어렵다.
2. Runnable 인터페이스 구현
public class 클래스이름 implements RunnableThread 스레드이름 = new Thread(new 클래스이름());- 다른 클래스를 상속해야 하는 클래스 구현 시에 사용이 유리하다.
- 재사용성이 높고 코드의 일관성을 유지할 수 있다.
- 객체 생성 후 바로 실행이 불가능하여 번거롭다.
동기화 (synchronized)
: 한 스레드가 진행 중인 작업을 다른 스레드가 간섭하지 못하도록 막는 것
멀티스레드 프로세스의 경우 여러 스레드가 같은 프로세스 내의 자원을 공유하여 작업하기 때문에 서로의 작업에 영향을 주게 된다.
그럼 이러한 문제는 어떻게 해결할 수 있을까?
공유 데이터를 사용하는 코드 영역을 임계 영역 (critical section)으로 지정해놓고, 공유 데이터(객체)가 가지고 있는 lock을 획득한 단 하나의 스레드만 이 영역 내의 코드를 수행할 수 있게 한다. 이렇게 되면 해당 스레드가 임계 영역내의 모든 코드를 수행하고 벗어나서 lock을 반납해야만 다른 스레드가 반납된 lock을 획득하여 임계 영역의 코드를 수행할 수 있게 된다.
동기화 구현하는 방식
- 메소드 전체를 임계 영역으로 지정
public syncronized void 메소드명() {
//
}- 스레드는 synchronized메소드가 호출된 시점부터 해당 메소가 포함된 객체의
lock을 얻어 작업을 수행하다가 메소드가 종료되면lock을 반납
- 특정한 영역을 임계 영역으로 지정
syncronized (객체의 참조변수) { /*
// 여기가 synchronized 블럭
} */- 참조변수는
lock을 걸고자하는 객체를 참조하는 것이어야 함 synchronized 블럭으로 들어가면서부터 스레드는 지정된 객체의lock을 얻게 되고, 블럭을 벗어나면lock을 반납
동기화로 인해 생길 수 있는 문제점
한 스레드가 lock을 보유한 채로 메소드를 실행 가능할 때까지 기다리게 된다면, 다른 스레드들은 해당 객체의 lock을 기다리느라 다른 작업들까지 원활하게 진행되지 못할 것이다.
그럼 이러한 문제는 어떻게 해결할 수 있을까?
동기화된 임계영역의 코드를 수행하다가 작업을 더 이상 진행할 상황이 아니면, 일단 wait()을 호출하여 스레드가 lock을 반납하고 기다리게 한다. 그러면 다른 스레드가 lock을 얻어 해당 객체에 대한 작업을 수행할 수 있게 된다. 나중에 작업을 진행할 수 있는 상황이 되면 notify()를 호출해서 작업을 중단했던 스레드가 다시 lock을 얻어 작업을 진행할 수 있게 한다.
여기서 생기는 궁금증 🧐
왜 쓰레드를 실행시킬 때 run()이 아닌 start()를 호출할까?
run() 은 단순히 클래스에 선언된 메소드를 호출하는 것이지만,
start()는 call stack을 생성한 다음 run()을 호출해 생성된 call stack에 run()을 올려 스레드가 독립된 공간에서 작업을 수행한다.
왜 sleep 메소드가 생각처럼 작동이 안될까?
main메소드에서 스레드 두개를 생성한 후 try-catch문에서 thread1에 대해 sleep()을 호출했는데 멈추지 않고 가장 먼저 종료가 되었다. 이유가 무엇일까?
public static void main(String args[]) {
Thread thread1 = new Thread();
Thread thread2 = new Thread();
thread1.start();
thread2.start();
try {
thread1.sleep(2000);
} catch(InterruptedException e) {}
}sleep( )은 항상 현재 실행 중인 스레드에 대해 작동하기 때문에 'thread1.sleep(2000)'과 같이 호출하였어도 실제로는 main메소드가 실행하는 main스레드가 영향을 받기 때문이다. 그래서 sleep()은 'Thread.sleep( )'과 같이 호출해야 한다.
