Python Scapy 조사
목차
1. Pyhon Scapy 조사
2. Pyhon Scapy 조사
3. 공부내용
1. Pyhon Scapy 조사
설명
scapy tool 을 이용하여 네트워크 트래픽 데이터 (pcap) 중
암호트래픽 TLS 의 페이이로드 정보의 Bytes 분포를 구하는 프로그램을 작성한다.
TLS 세션 별로 각 패킷에대한 bytes distribution 정보를( 0 ~ 255 ) 분포정보를 포함하는
CSV 파일로 출력되어야한다.
주어진 pcap에서 tls 세션(src-ip, src-port, dst-ip, dst-port )정보를 구한다.
해당 세션의 payload 데이터를 구한다.
payload 데이터의 바이트 분포 정보를 구한다.
csv 출력 형식
시간, src-ip, src-port, dst-ip, dst-port , 0,2,3,4,.. 255
2023-01-02 13:12:33.111, 1.1.1.1, 2311, 8.8.8.8, 443, 0,2,1,....0
코드
from scapy.all import *
import datetime
import pandas as pd
from scapy.layers.inet import TCP, UDP
from scapy.layers.tls.record import TLS
from collections import Counter
packets = rdpcap("C:\\Users\\future\Desktop\sampleData.pcap")
session_info = {}
for packet in packets:
# packet을 scapy로 처리할 때 특정한 통신을 정하지 않으면 오류가 나서 TCP로 고정하고 진행
if TCP in packet:
# 시간
timestamp = datetime.datetime.fromtimestamp(packet.time).strftime('%Y-%m-%d %H:%M:%S')
# src-ip
src_ip = packet.src
# src-port
src_port = packet.sport
# dst-ip
dst_ip = packet.dst
# dst-port
dst_port = packet.dport
# 배열형태로 넣기위한 Key값
session_id = f'{src_ip}:{src_port}-{dst_ip}:{dst_port}'
# TLS인 경우 다음과 같은 로직 진행
if packet.haslayer(TLS):
#데이터의 바이트 분포 정보
# 바이트 수를 count해서 특정 바이트 값의 특정한 의미를 유추
payload = bytes(packet[TLS])
counter = Counter(payload)
# 분산 값을 하나씩 출력
output = [str(counter[i]) for i in range(256)]
payload_value = (','.join(output))
session_info[session_id] = [timestamp, src_ip, src_port, dst_ip, dst_port, payload_value]
df = pd.DataFrame(session_info)
df.to_csv("save.csv", index=None, header=None)결과

문제점
- DataFrame 생성 시 session_info 딕셔너리를 전달하면서 열과 행이 바뀌게 됩니다.
따라서 예상했던 것과 다른 결과가 CSV에 출력되었습니다 - 각 Column에 열 이름이 제공되지 않아서 의미 파악이 어렵습니다.
2. Python Scapy 조사
설명
1) 구현한 소스코드의 문제점 분석
구현한 소스에서 문제점/개선점 찾기 2가지 이상
( 예 CSV 를 row정렬로 표기 등.. )
2) 구현한 소스를 이용하여 다음과 같은 프로그램을 만들어보세요
pacap 파일명을 argument로 받아서 패킷의 정보를 출력하는 프로그램
python pcap_analyzer.py {TARGET FILE}
옵션 -o , --out {OUTPUT FILENAME} CSV형태로 출력
( 옵션 없는경우 화면에 결과를 출력 ) 출력 형식
TLS Sesessions
TIME DURATION SRC:Port DST:Port TLS Version TX Bytes RX Bytes
2023-02-03 10:32:23 10 secs 1.1.1.1:2332 2.2.2.2:443 1.0 123123 123123
2023-02-03 10:35:22 15 secs 201.23.13.11:2332 3.3.3.11:443 1.0 123123 123123
총 패킷수 : 100 총 TLS 패킷 수 : 30 총 TLS 세션 수 : 20 -----------------------------------------------------
코드
import argparse
from scapy.all import *
from scapy.layers.inet import TCP, UDP, IP
from scapy.layers.tls.record import TLS
import pandas as pd
def timestamp(packets):
timestamp_list = []
for packet in packets:
if IP in packet:
if TCP in packet:
timestamp = datetime.fromtimestamp(packet.time).strftime('%Y-%m-%d %H:%M:%S')
elif UDP in packet:
timestamp = datetime.fromtimestamp(packet.time).strftime('%Y-%m-%d %H:%M:%S')
timestamp_list.append(timestamp)
return timestamp_list
def duration(packets):
# timestamp 값을 이용해서 이전 패킷과의 시간 간격을 계산하고 이를 duration으로 사용
duration_list = []
duration_list.append(0)
for i in range(len(packets)-1):
delay = packets[i+1].time - packets[i].time
delay_value = f"{delay:.6f} secs"
duration_list.append(delay_value)
return duration_list
def src_port(packets):
src_port_value = []
for packet in packets:
if IP in packet:
src_ip = packet[IP].src
if TCP in packet:
src_port = packet[TCP].sport
elif UDP in packet:
src_port = packet[UDP].sport
else:
continue
src_info = f"{src_ip}:{src_port}"
src_port_value.append(src_info)
return src_port_value
def dst_port(packets):
dst_port_value = []
for packet in packets:
if IP in packet:
dst_ip = packet[IP].dst
if TCP in packet:
dst_port = packet[TCP].dport
elif UDP in packet:
dst_port = packet[UDP].dport
else:
continue
dst_info = f"{dst_ip}:{dst_port}"
dst_port_value.append(dst_info)
return dst_port_value
def tls_version(packets):
tls_versions = []
tls_version_value = None
for packet in packets:
if TLS in packet:
tls_record = packet[TLS]
version_value = tls_record.version
if version_value == 0x0304:
tls_version_value = "TLS 1.3"
elif version_value == 0x0303:
tls_version_value = "TLS 1.2"
elif version_value == 0x0302:
tls_version_value = "TLS 1.1"
elif version_value == 0x0301:
tls_version_value = "TLS 1.0"
elif version_value == 0x0300:
tls_version_value = "SSL 3.0"
else:
tls_version_value = None
tls_versions.append(tls_version_value)
return tls_versions
def tx_byte(packets):
tx_bytes = []
for packet in packets:
if IP in packet:
tx_byte = len(packet)
tx_bytes.append(tx_byte)
return tx_bytes
def rx_byte(packets):
rx_bytes = []
for packet in packets:
if IP in packet:
rx_byte = len(packet)
rx_bytes.append(rx_byte)
return rx_bytes
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("pcap_file")
parser.add_argument('--o', '--out', default="out.csv")
args = parser.parse_args()
packets = rdpcap(args.pcap_file)
timestamp_value = timestamp(packets)
duration_value = duration(packets)
src_port_value = src_port(packets)
dst_port_value = dst_port(packets)
tls_version_value = tls_version(packets)
tx_byte_value = tx_byte(packets)
rx_byte_value = rx_byte(packets)
data = {
"TIME": timestamp_value,
"DURATION": duration_value,
"SRC:Port": src_port_value,
"DST:Port": dst_port_value,
"TLS Version": tls_version_value,
"TX Bytes": tx_byte_value,
"RX Bytes": rx_byte_value
}
df = pd.DataFrame(data)
print(df)
df.to_csv(args.o, index=None)
결과
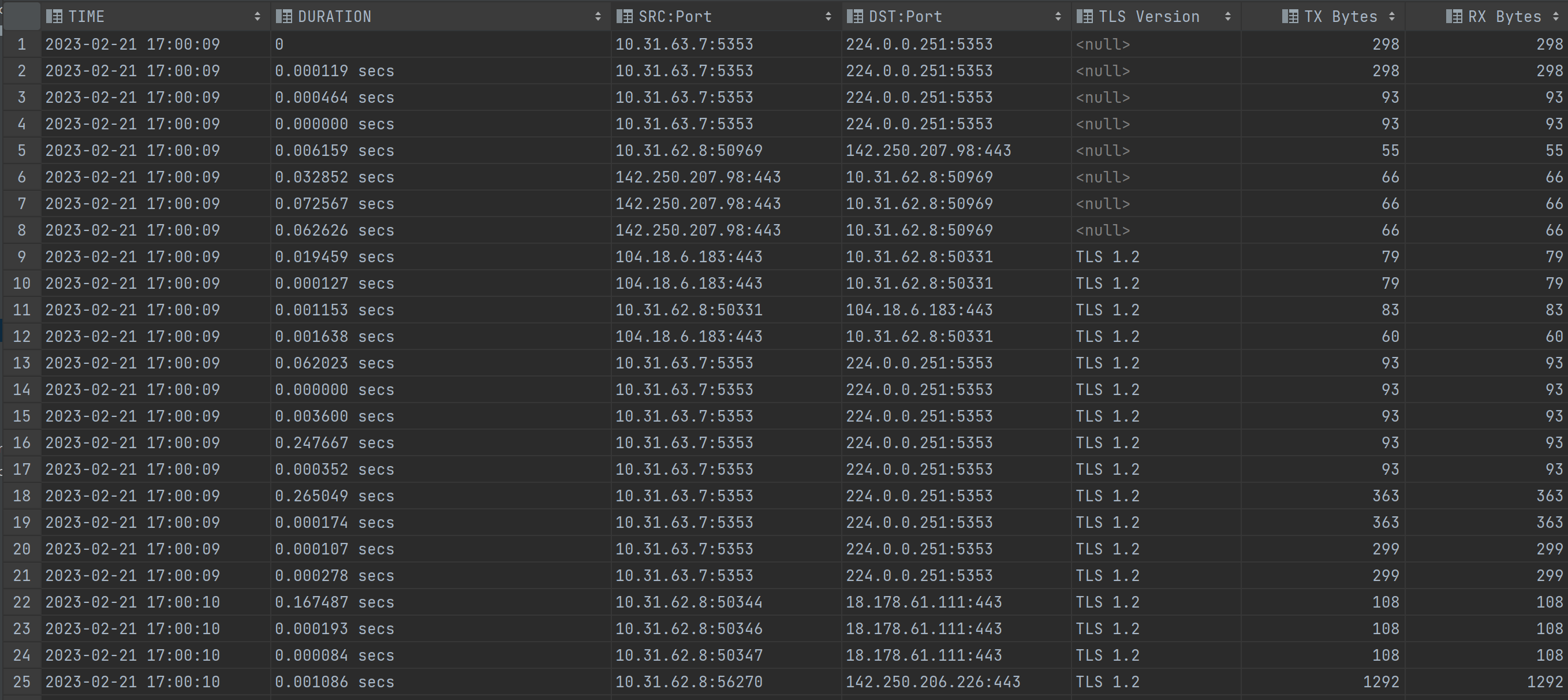
개선사항
- 딕셔너리를 전달하면서 열과 행이 바뀌게 되는 현상을 막기 위해서 메서드로 필수요소들을 추출했습니다.
- 열 이름이 제공되지 않아서 의미 파악이 어려웠던 문제를 해결하기 위해서 열 이름을 주입하였습니다.
3. 공부내용
패킷 이해하기
패킷을 이해하기 위해서 4개의 레이어 모델로 전체 구조를 자르고 각각의 레이어가 통신하는 방법에 대해서 알아보자.
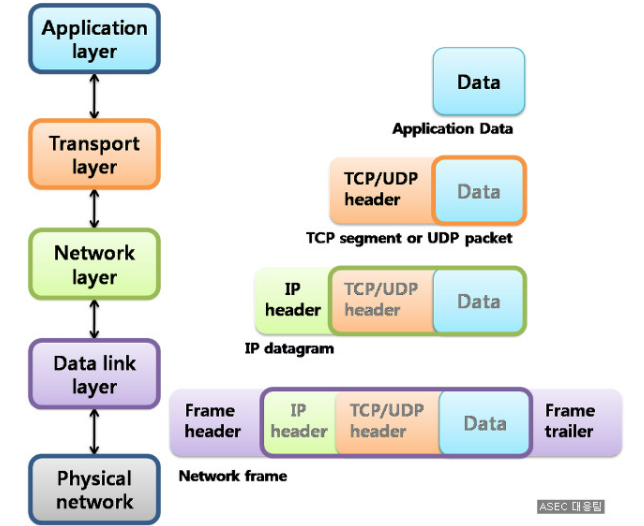
네트워크의 전체적인 흐름을 알기 위해서 이용자가 웹 사이트에 접근했을때 상황으로 확인해보자.
이용자는 웹 브라이저를 통해서 도메인 주소를 입력해서 통신을 요청한다. 이 때 Applcation 계층에서 DSN서버에게 도메인 주소의 IP주소를 받아온다. 그 후 https는 TCP 프로토콜을 사용하여 이용자의 컴퓨터와 운영 서버는 커넥션을 확립한다.
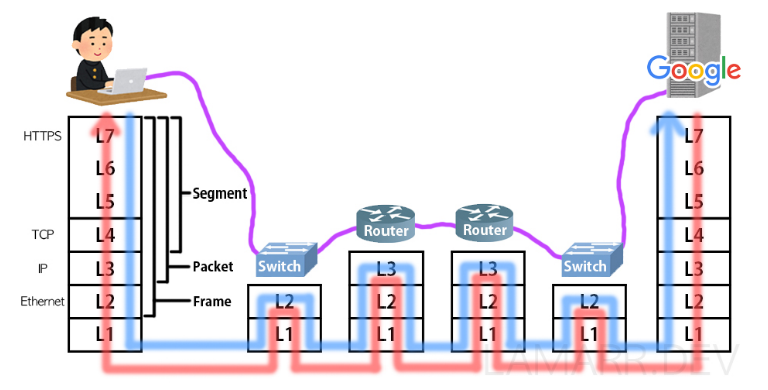
커넥션이 확립되면 유저는 운영서버에 웹 페이지를 요청하는 데이터를 보내고 요청하고자 하는 데이터에 헤더가 붙으며 캡슐화가 진행된다. 이때 헤더에는 HTTPS가 붙게된다.
Transport Layer에서 TCP 헤더가 붙으면서 TCP 프로토콜은 신뢰할 수 있고 정확한 데이터 송신을 위해서 사용되고 출발지 포트번호와 목적지 포트번호가 기록된다. 여기까지의 데이터를 세그먼트라고 한다.
Network Layer에서는 IP 프로토콜의 헤더가 붙으면서 출발지 IP주소와 목저지 IP 주소가 기록된다 이렇게 구성된 데이터를 패킷이라고 한다.
Data Link Layer에서는 Ethernet 헤더가 붙는다. 헤더에는 목저지로 가기위해 거쳐야할 IP주소를 가지고 있는 장비 즉 라우터의 MAC 주소가 기록되고 이 데이터를 프레임이라고 한다.
Physical network에서는 랜카드라는 장비를 거쳐 데이터는 전기신호로 변환된다. 그리고 케이블로 물리적으로 연결 되어 있는 스위치라는 장비로 향한다.
스위치에 도착한 데이터는 L1,L2 순으로 역캡슐화가 이루어지고 스위치는 이더넷헤더에서 목적지의 MAC 주소를 알아내고 MAC 주소 테이블을 참고하여 어느 포트로 내보내야 할지를 조사하고 다시 데이터를 캡슐화해서 전기 신호로 다음 목적지인 라우터로 전송한다.
라우터는 전기신호로 도착한 데이터를 우선 L2 헤더까지 역캡슐화하고 목적지 MAC 주소와 자신의 MAC 주소가 같으면 L3의 헤더까지 역캡슐화를 수행하고 자신의 라우팅 테이블과 목적지 IP주소를 비교한다. 자신의 라우팅 테이블에서 목적지 IP까지의 경로를 알 수 있으며 라우팅을 진행한다. 이 때 만약 출발지 IP가 사설 IP일 경우 L3 IP헤더에서 출발지 IP주소를 라우터의 공인 IP 주소로 설정한다.
다음으로 이더넷 헤더에서 라우팅으로 출발지 MAC 주소와 목적지 MAC 주소를 알아낸 다음 목적지 MAC 주소를 수정하고 데이터를 다시 캡슐화해서 다음 경로로 보낸다. 이때 여러 라우터를 거치며 목적지까지 역캡슐화와 캡슐화의 과정을 반복한다.
마지막 라우터는 라우팅 테이블을 통해 목적지 IP주소까지의 경로를 알 수 있다. L3 헤더에서 출발지 IP 주소를 자신의 라우터 내부 IP주소로 변경하고, 이더넷헤더에서는 스위치에 전달되도록 MAC 주소를 수정한다. L2헤더에서는 스위치에 전달되도록 MAC 주소를 수정한다. 다시 캡슐화를 하고 전기신호를 연결되어있는 스위치로 전달한다.
마지막으로 목적지에 도착하여 서버측의 데이터 처리를 한다. 스위치는 역캡슐화와 캡슐화를 진행하고 데이터를 운영서버에 전기신호로 전달한다. 운영서버는 이용자가 보낸 웹페이지를 요청하는 데이터 전체를 역캡슐화한다.
역캡슐화 과정은 먼저 L2에서 이더넷 프레임의 목적지 MAC 주소와 자신의 주소를 비교한다. 주소가 같으면 L2헤더와 트레일러를 분리하고 Network Layer에 전달한다.
Network Layer에서는 목적지 IP주소와 웹 서버 IP주소가 같은지 확인하고 같으면 IP 헤더를 분리하고 Transport Layer에 전달한다.
Transport Layer에서는 목적지 포트 번호를 확인하여 어떤 어플리케이션으로 전달할지 정한다. 만약 데이터에 오류가 있다면 송신측에게 데이터를 재전송 요청한다. 오류가 없다면 TCP 헤더를 분리하고 Session Layer에 전달한다. 그리고 문제가 없으면 6, 7 Layer에 전달하고 데이터를 처리하여 이용자에게 보여준다.
문답🤔
많은 양의 데이터의 패킷분석을 하려면??
1. 많은 양의 데이터를 분석할 경우, 시스템의 자원 사용량이 증가하여 성능 문제가 발생 할 수 있다. 따라서, 시스템 자원 사용량을 모니터링하고 필요한 경우 스케일 업, 스케일 아웃을 고려할 수 있다.
2. 패킷분석은 네트워크를 주고받는데 사용된다. 악의적인 패킷에 대한 대비책을 마련해야 한다.
3. 데이터의 정합성 문제가 발생할 수 있다. 패킷의 순서 문제, 중복문제들이 발생할 수 있는데 이를 해결하기 위해서 데이터 정합성 검사를 하는것을 고려해야 한다
악의적인 패킷에 대비하는 방법은??
1. 방화벽을 사용해서 데이터의 흐름을 모니터링하고 차단할 수 있다.
2. VPN을 통해 안전한 테트워크 연결을 제공한다.
3. 패킷을 검사하여 악의적인 패킷을 차단하는 방법이 있다. 패킷 검사는 패킷의 프로토콜, 포트, 페이로드 등을 분석하여 악성 패킷을 식별하고 차단하는 역할을 한다.
4. 취약점을 분석하여 네트워크를 강화한다.
SSL과 TLS의 차이점은??
SSL과 TLS은 모두 암호화 프로토콜로 웹 사이트와 브라우저 간에 데이터 전송 시 보안을 제공하는 역할을 한다. 그러나 SSL는 넷스케이프에서 개발이 되었고 TLS는 IETF에서 개발되었다. SSL은 1.0, 2.0, 3.0 버전이 있고 TLS는 1.0, 1.1, 1.2, 1.3이 있다. 그리고 SSL은 3.0 이후에 TLS로 대체되었다
TLS는 SSL의 보안 취약점을 보완하기 위해 개발되었고 SSL은 HTTPS 프로토콜에서만 사용될 수 있지만, TLS는 FTPS, SMTPS 등 다양한 프로토콜에서 사용될 수 있어서 호환성면에서 뛰어나다 또한 TLS는 SSL보다 더 나은 성능을 제공하고 속도 보안성 모두 TLS가 뛰어난 모습을 보여준다.
네트워크 통신과정에서 데이터 단위를 바꾸는 이유는??
applcation계층에서 데이터를 넘겨줄때 stream 데이터를 넘겨주는데 이용자가 요청하는 데이터의 길이가 길면 넘겨줄 수 없습니다. 그래서 데이터를 잘라서 전달하게 되고 그 데이터를 segment라고 합니다. 이 때 데이터를 자르는 최대 크기를 MSS (Maximum Segment Size)라고 하며 기준은 MTU (Maximum Transfer Unit)를 기준으로 최대 패킷의 유닛 크기인 1500bytes가 됩니다.
언제 목적지 주소까지의 경로계산을 하는지??
네트워크에서 목적지 주소까지의 경로 계산은 패킷이 전송되기 전에 수행된다. 일반적으로, 라우터는 라우팅 프로토콜(예: OSPF, BGP 등)을 사용하여 네트워크의 경로 정보를 수집하고, 라우팅 테이블을 구성한다.
패킷이 라우터에 도착하면, 라우터는 패킷의 목적지 주소를 확인하고, 라우팅 테이블을 참조하여 패킷이 전달되어야 할 다음 라우터나 대상 컴퓨터를 결정한다. 그 후, 라우터는 패킷을 캡슐화하여 다음 라우터나 대상 컴퓨터로 전송한다.
따라서, 목적지 주소까지의 경로 계산은 패킷이 전송되기 전에 수행되며, 이는 라우팅 테이블이 패킷이 전송될 때까지 유지되는 이유이다. 라우터는 패킷을 처리할 때마다, 목적지 주소를 확인하여 라우팅 테이블을 참조하므로, 라우팅 테이블의 업데이트가 필요한 경우에는 이를 수행하여 새로운 경로 정보를 반영한다.
와이어샤크
와이어샤크를 통해 패킷을 분석할때 볼 수 있는 화면이다. 위에서 부터 Frame protocol, MAC procotol, IP procotol, TCP procotol, TLS 까지 확인할 수 있다.

Scapy를 활용한 pcap 파일 분석
Scapy는 Python으로 개발된 네트워크 패킷 분석 및 조작 도구이다. Scapy는 TCP/IP 프로토콜을 비롯한 다양한 프로토콜을 지원하며, 네트워크 패킷의 생성, 수정, 전송, 수신, 저장, 검증 등 다양한 작업을 수행할 수 있다. Scapy에서는 패킷을 캡처하고 디코딩하는 기능을 사용할 수 있는데 'rdpcap'을 사용해서 pcap파일에서 패킷을 로드해서 Scapy 패킷 객체로 변화하는 함수이다.
