학습 목표
- SQL의 복잡한 검색 기능에 대하여 이해한다.
- 관계 대수에 대해서 알아본다.
- SQL 질의를 처리하는 과정을 이해한다.
학습 내용
- SQL에서 복잡한 검색 질의
- 관계대수를 이용한 정보조작
SQL에서 복잡한 검색 질의
조인 질의
RDBMS에서 가장 중요
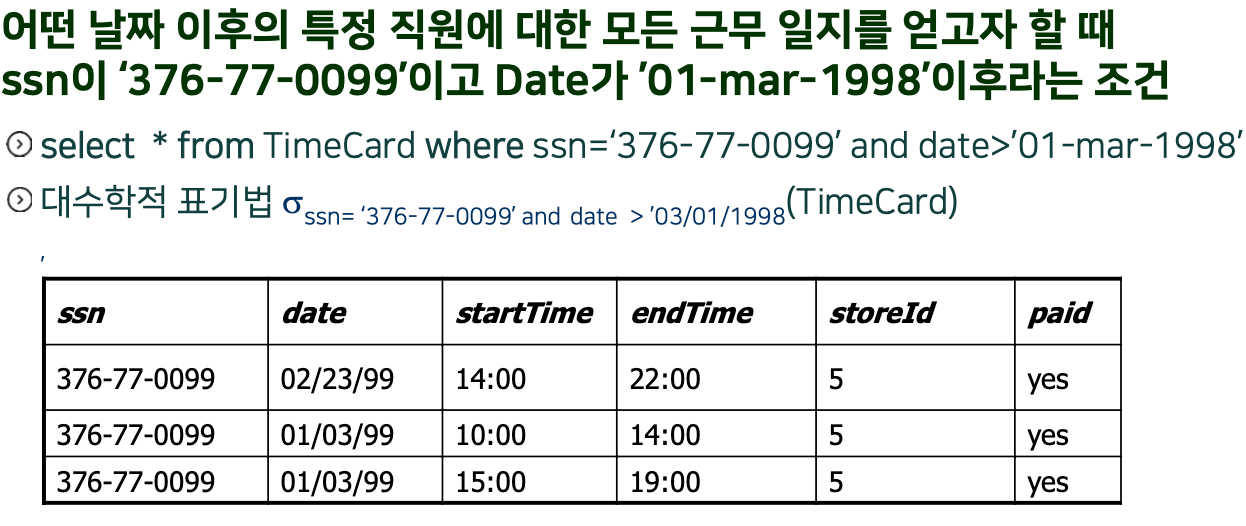
Q. 질의 : 모든 직원ㄷ르의 정보와 근무시간카드를 검색하여라
TIP
ㄴ 처리시간이 가장 많이 든다
ㄴ 밑 그림에서 2번째 방식을 추천
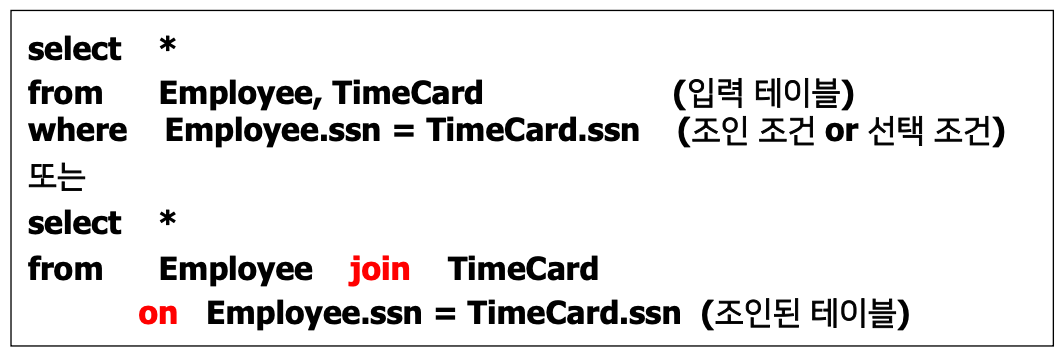
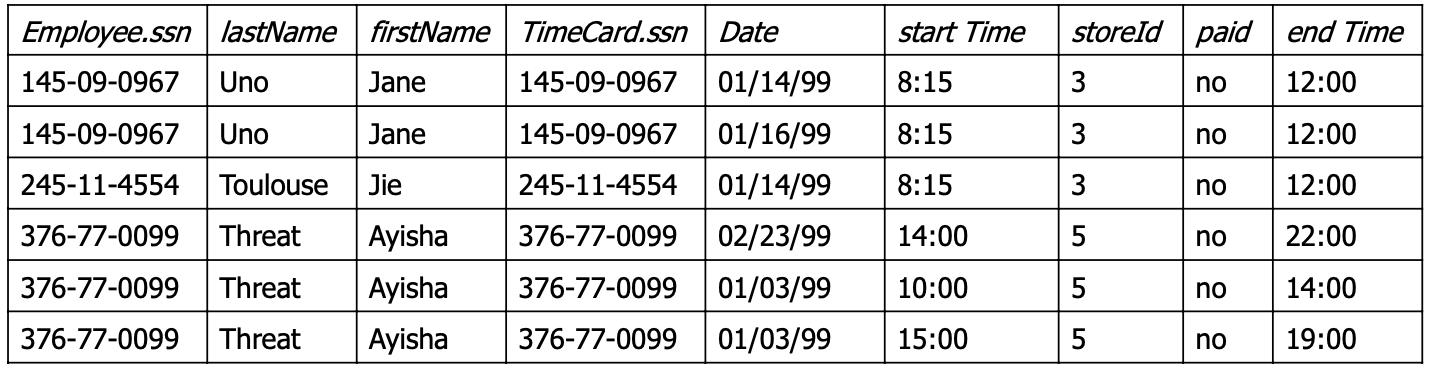
Employee.ssm == PK (기본기)
TimeCard.ssn == FK (외래키)
- 조인 연산을 위해 명시적인 연산자 → Join키워드
- 조인 조건은 Where 절 대신에 on절로 표시
Ans

SQL 질의에서 표현식 : 집단화 함수
- 집단 함수 : 여러 튜플의 정보를 요약하여 하나의 튜플로 요약하는데 사용
- count, avg, sum ,min ,max ..
- select 절이나 having 절에 사용
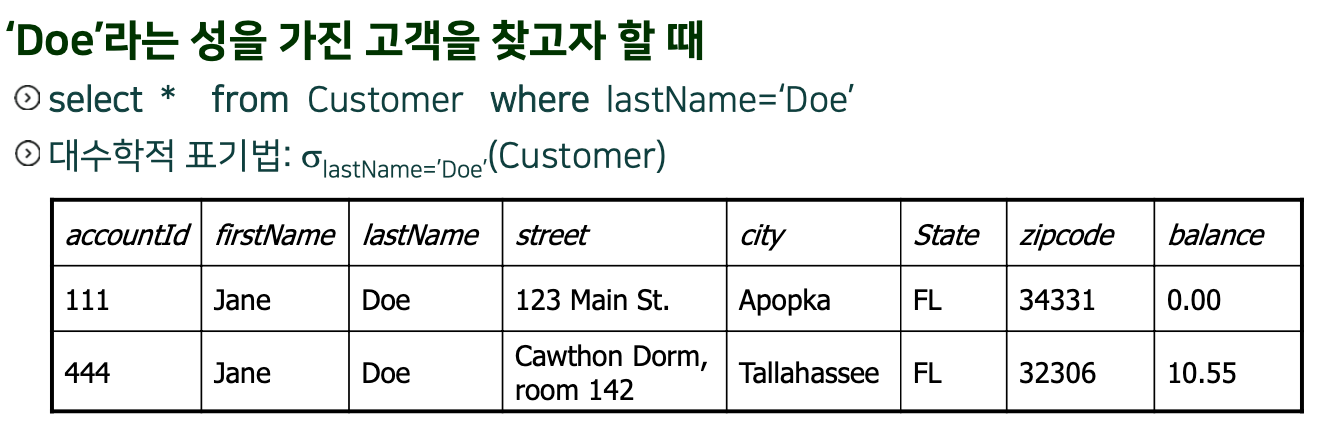
Q. 고객 번호 101인 고객의 현재 대여 횟수를 검색하여라.
select count(*)
from Rental
where accountId = 101Q. 고객의 성(lastName)의 개수를 검색하여라
select count (distinct lastName)
from CustomerQ. 직원들의 평균 근무 시간을 계산하여라
select avg((endTime-startTime * 24)) as avghoursWorked
from TimeCardGroupt By 절과 Having 절
Group By 절
- 같은 컬럼 값에 대하여 튜플들의 그룹을 구성
- 그룹핑 애트리뷰트를 명시하기 위한 절
- Select 절은 그룹핑 애트리뷰트와 튜플들의 각 그룹에 적용할 집단 함수들만 포함

Having 절
- 그룹에 적용되는 셀렉션 연산 ( Group By에 조건을 명시)
- Having 절의 조건을 만족하는 그룹만 질의 결과 테이블에 반영
- Having절에 나타날 수 있는 애트리뷰트들은 위의 Select 절에서 가능한 애트리뷰트들과 동일

from → where → group by → having → select
중첩 질의 (Nested Query)
중첩질의
- Where 절에 또 다른 select 문장이 있는 질의
- 비교 연산자 in을 사용 (어떤 원소가 주어진 집합에 있는지 검사)

정첩질의표현에서 괄호안 을 sub-query라고도 부름
단일 SQL 질의 표현에서 중첩 질의 표현으로 바꾸는 작업을 Tunning이라 부름
Tunning : 효율성있게 바꾸는 작업 (최적화)
ex ) Join → Nested Query
- Cost : 중첩 질의 표현 <<<<<< 단일 SQL 질의 표현
중첩 질의 : Exists 함수
- Exists 다음에 오는 select 문장의 실행 결과가 존재하는지 검사
- Exists 함수의 결과
- 참 : 한 튜플이라도 있는 경우, 거짓 : 한 튜플도 갖지 못할 경우

그 외 중첩 Select 문에 사용되는 연산자
- all , unique, contains, not
집합 연산자 : Union, Intersect , Except
Relation == a set of Tuples
집합 연산
- 합집합, 교집합, 차집합
- 호환성이 있는 , 즉 열의 수가 같고 열들의 순서대로 같은 타입을 가지는 경우 어떠한 두개의 테이블에 대해서 사용가능 (도메인이 같아야한다.)
- 중복된 튜플들이 결과에서 제거됨
관계대수를 이용한 정보 조작
관계 대수 (Relational Algebra)
Algebra란?
ex) Integer Algebra
3 + 4 = 7
Integer Operator Integer , Return Integer
- 관계 조작을 위한 연산들의 집합
- 폐쇄 성질 (Closure Property)
- 피연산자와 결과는 릴레이션
- 중첩된 수식의 표현이 가능
관계 대수 연산자
- 셀렉션 (Selection) : 특정한 조건을 만족하는 튜플들을 선택 (Where절과 유사) : σ
- 프로젝션 (Projection) : 특정 애트리뷰트의 선택 : π
- 집합 연산 (Set) : 튜플의 결합과 비교를 통해 유사한 2개의 튜플 집합을 조작
- 합집합 : ∪ , 교집합 : ∩, 차집합 : ㅡ
- 조인(Join), 프로덕트(Product) : 두 릴레이션의 튜플들을 하나로 묶음
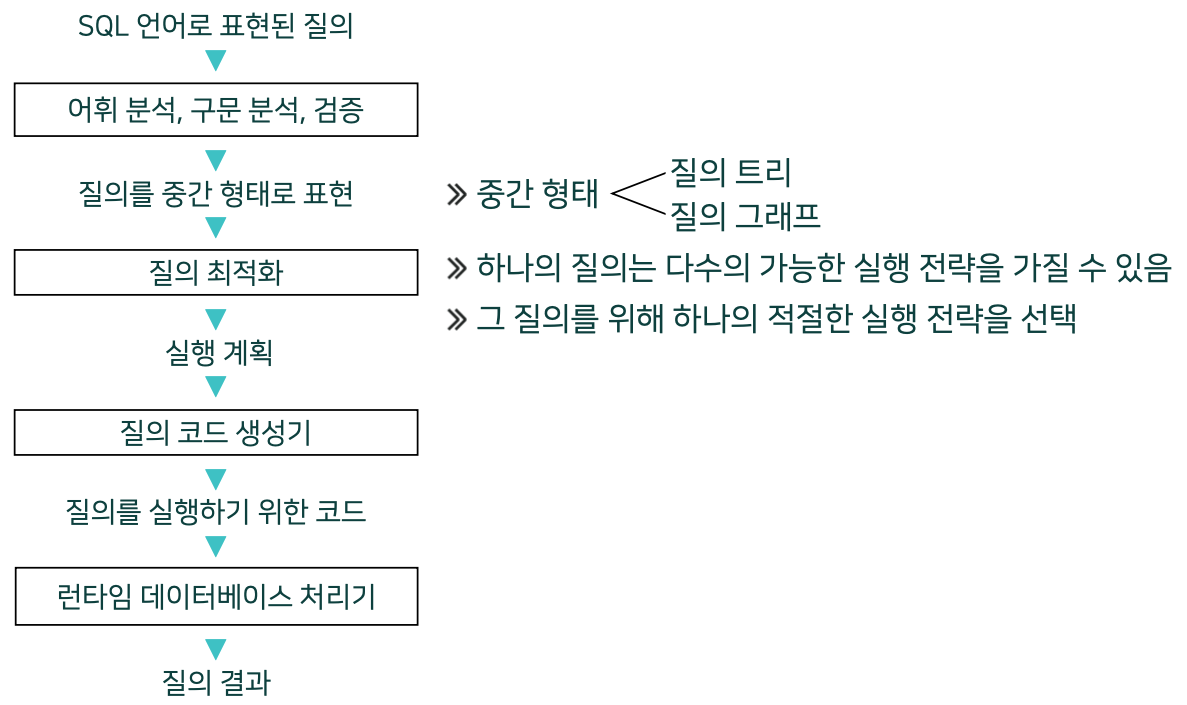
SQL 질의를 처리하는 전형적인 과정

질의 최적화 (Query Optimization)
질의 최적화란?
- 질의를 실행하기 위해 적절한 실행 전략을 선택하는 과정
- 질의 최적화가 필요한 이유
- RDBMS의 SQL은 고수준의 질의어이므로, 질의의 결과를 얻기 위한 절차(HOW)를 상세하게 명시하기 보다는 질의의 원하는 결과가 무엇인지(WHAT)인가를 명시하기 때문
- what은 사용자가 how는 컴퓨터가
- Non - Procedured Language
- how를 채워주는건 query optimization이다
- RDBMS의 SQL은 고수준의 질의어이므로, 질의의 결과를 얻기 위한 절차(HOW)를 상세하게 명시하기 보다는 질의의 원하는 결과가 무엇인지(WHAT)인가를 명시하기 때문
- DBMS는 Selection, Join 또는 이런 연산자들의 조합으로 구성된 관계 대수 연산을 구현한 여러 개의 일반적인 데이터베이스 접근 알고리즘들을 가지고 있음
- 질의 최적화 모듈은 DBMS의 접근 알고리즘에 의해 구현될 수 있으며, 특정 질의와 특정 물리적 데이터베이스 설계에 적용되는 실행 전략들을 고려
what
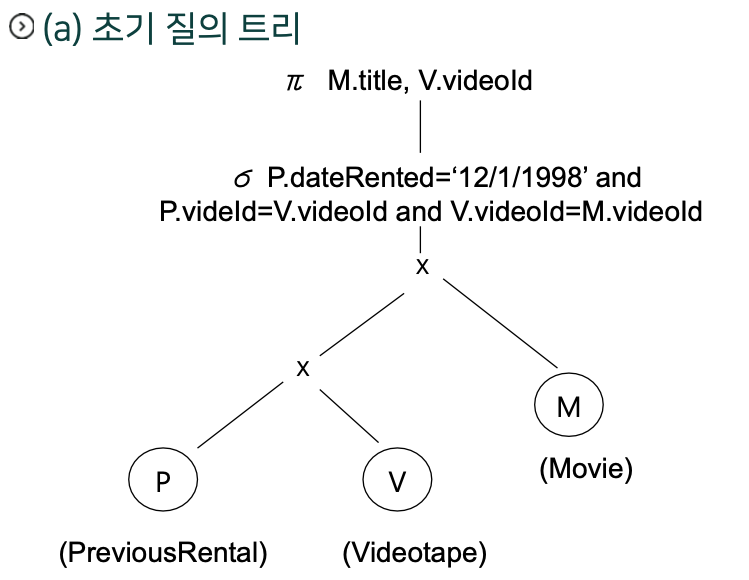
how
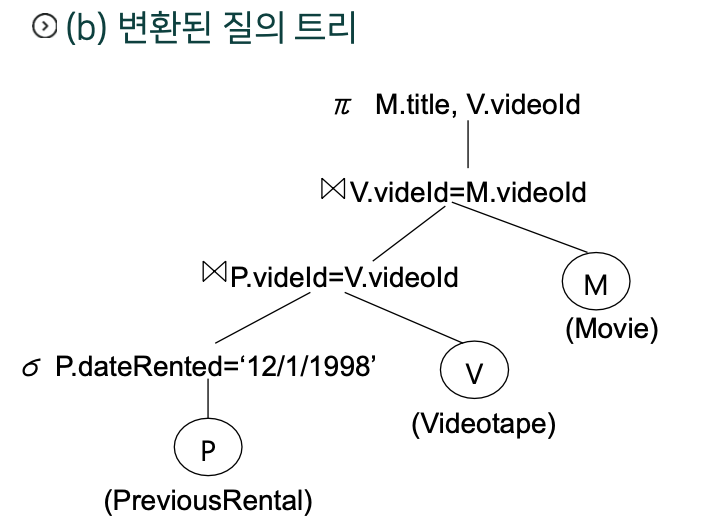
- 파싱트리
질의 최적화를 위한 작업 (Query Optimization)
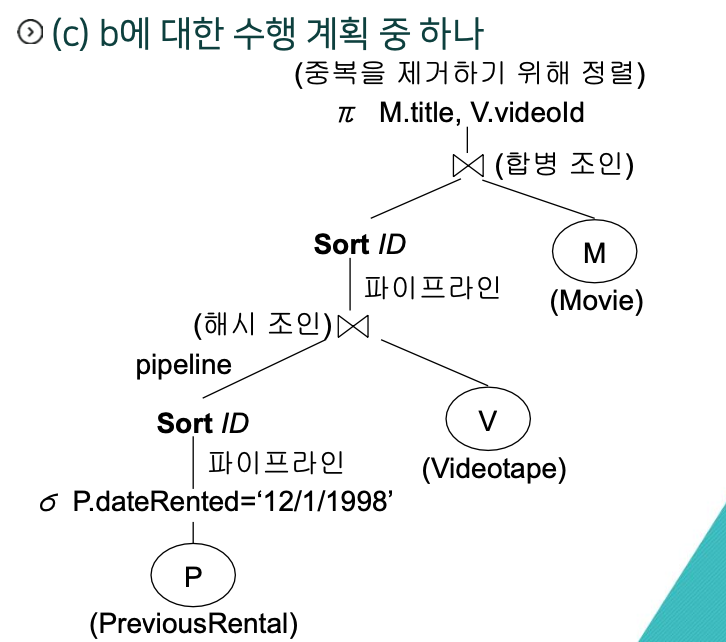

셀렉션 연산자
셀렉션 : σ
- 릴레이션으로부터 특정한 기준을 만족하는 모든 튜플들을 선택

프로젝션 연산자
프로젝션
위에서 부터 짤라와라
- 한 릴레이션으로부터 임의의 애트리뷰트를 선택
- 선택된 애트리뷰트만을 가지는 릴레이션을 생성
- 프로젝션의 결과는 집합이므로, 모든 중복은 제거된다.
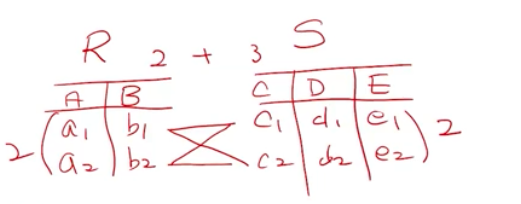
Relation == a set of Tuples이므로 set(중복 없음)
그래서 distinct가 있어야 대수학적 표기법과 정확한 의미임.집합 연산자
집합(set) 연산자
- 두 릴레이션이 같은 형태를 지니고 있을 때 적용
집합 연산의 피연산자들은 차수(degree)가 같고, 대응 애트리뷰트 별로 타입(domain)이 동일해야함
합집합 (Union)
교집합(Intersect)
- 두 입력 릴레이션 상에 공통으로 존재하는 튜플들의 집합을 생성
- 대수학적 표기법 : π000 n π000
차집합(Difference)
- 첫 릴레이션에는 존재하나 다음 릴레이션에는 존재하지 않는 튜플들의 집합
- 대수학적 표기법 : π000 - π000
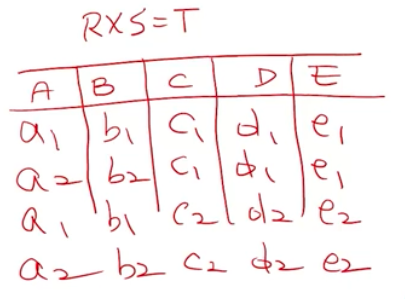
카티션 프로덕트(Cartisian Product)
- 두 릴레이션을 가지고 새로운 릴레이션을 생성
- 모든 조합을 구한다.
- ex ) A x B
- 애트리뷰트의 이름은 새로운 스키마의 생성으로 변경

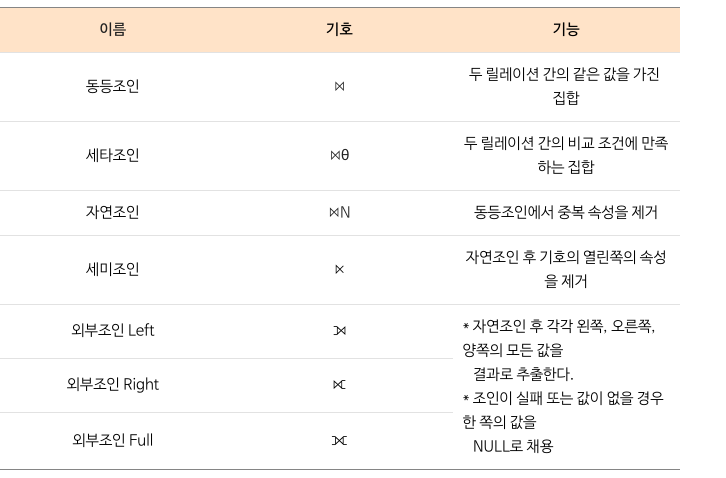
조인(Join)연산
두 릴레이션으로부터 관계된 객체를 모음
정확히 같은 이름을 가지는 애트리뷰트에 대해 조인 됨
- 자연조인(Natural Join)
- 결과 테이블에서 중복되는 애트리뷰트는 하나만 보임
- 동등 조인(Equi-Join)
- 조인 조건이 동등 연산인 경우
관계 연산자의 조합
- 관계 연산자는 조합되어 관계 대수 표현식(Relational Algebra Expression)을 만들 수 있음
부하적인 관계 연산자
집단화 (Aggregation) 연산
- 피연산자가 릴레이션이 아인 튜플의 집합
- 산술연살이나 비교 연산을 어떠한 집합의 원소들에 대해 적용하는데 사용
- SQL에서 Aggregation Function으로 지원
- 객체들을 집합으로 그룹화 할 수 있으며 집단화 연산자들을 이 집합들에 적용
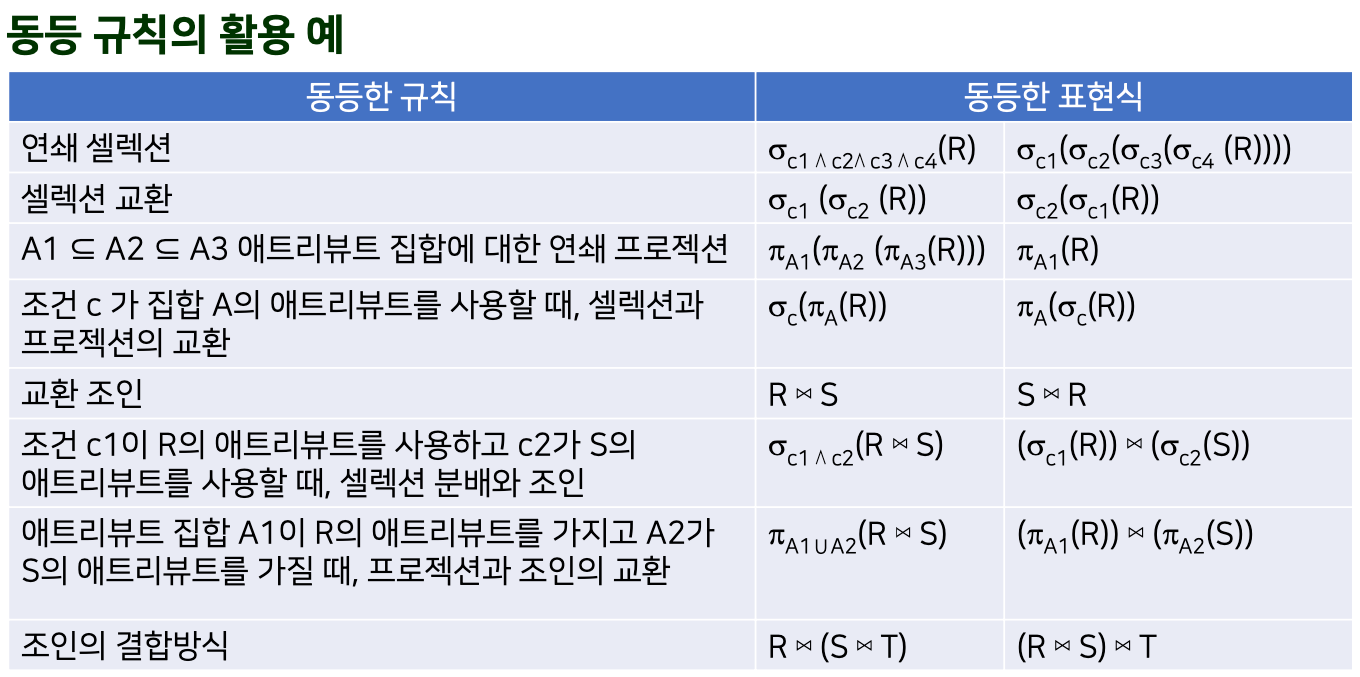
관계표현식의 대수적 조작
관계표현식
- 표현식에 대한 다양한 동치(Equivalence Rule)을 활용 가능
- 교환, 분배, 결합 법칙이 존재
- 하나의 고나계 대수 표현식에 대해 여러 표현 방법을 생성 가능
- 데이터베이스 최적화의 효율성은 관계 대수의 능력과 관계
동등 규칙의 활용 예