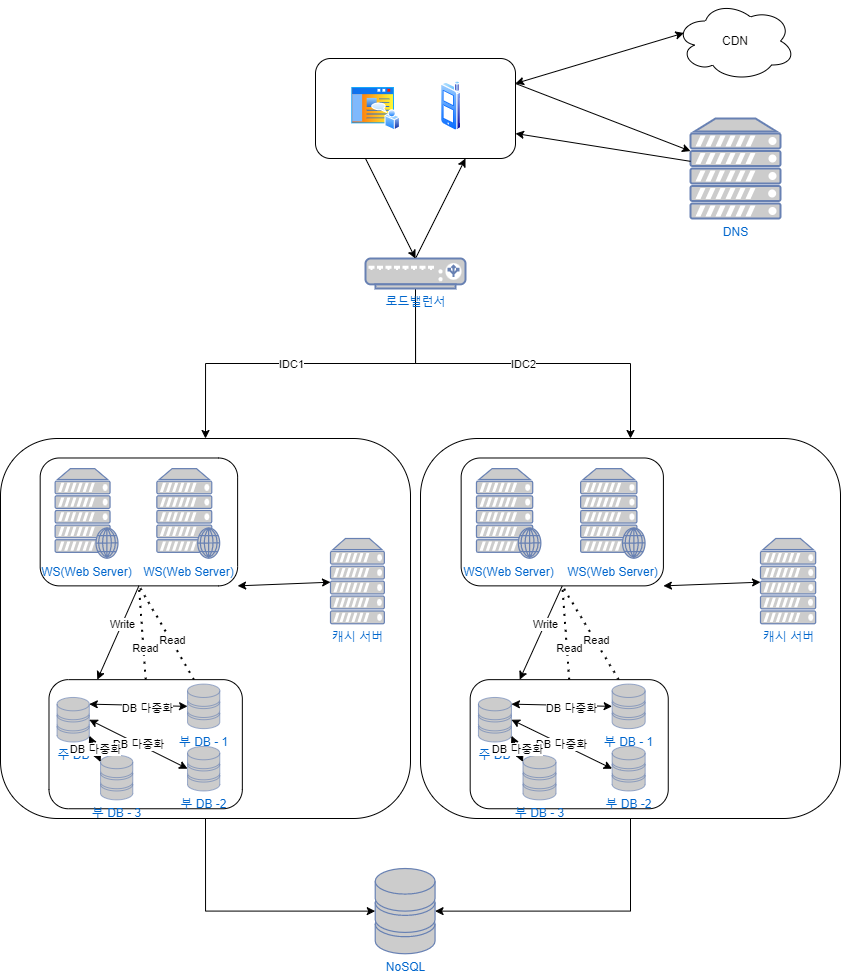
데이터 센터로의 확장
이제는 두 개의 데이터 센터를 이용하는 경우로 확장시켜 보자. 장애가 없는 상황에서 사용자는 원래의 데이터 센터로 안내되어 정상적으로 서비스를 사용하게 된다. 이때 사용하는 라우팅을 지리적 라우팅(geoDNS-routing 또는 geo-routing) 이라고 부른다. 지리적 라우팅에서의 geoDNS 는 사용자의 위치에 따라 도메인 이름을 어떤 IP주소로 변환할지 결정할 수 있도록 해 주는 DNS 서비스다. 이떄 여러개의 데이터센터(IDC) 로 라우팅하는 방법으로는 해싱등 여러가지 전략을 이용할 수 있다. 해싱에 대해서는 추후의 글을 통해서 자세히 알아보도록 하겠다.
다중 데이터센터 아키텍처의 기술적 난제
- 트래픽 우회
올바른 데이터센터로 트래픽을 보내는 효과적인 방법을 찾아야 한다. GeoDNS 는 사용자에게서 가장 가까운 데이터센터로 트래픽을 보낼 수 있도록 해준다.- GSLB (GLobal Server Load Balancing)
이름만 보면 얼핏 업그레이드된 로드 밸런싱이라고 생각도리 수 있지만, 사실 DNS 서비스의 발전된 형태이다.
DNS 는 도메인 주소와 IP를 매핑하여 해당 도메인주소로 요청이 들어왔을 때, 해당되는 IP주소를 반환해주는 서비스를 말한다. DNS를 이용해서 가용성 있는 서비스를 구축할 수 있게 된다. 하지만 DNS의 정책(라운드로빈 등등)의 한계로 인해 많은 도메인주소에 대하여 해당 IP주소를 빠른 시간에 응답하는데 한계가 있다는 것이다. 이러한 문제를 해결하기 위해 나온 것이 GSLB 이다.
즉, GSLB는 서버의 상태를 모니터링(life check)를 통해서 지리적으로 가장 가까운 DNS 서버로 전환시켜주는 기능도 한다. 뿐만 아니라 일반적인 DNS 서버는 Round Robin 의 방식을 사용하고 있다면 GSLB는 사용자의 지리적위치를 고려하여 사용자에게 더욱 빠른 응답을 보장한다.
- GSLB (GLobal Server Load Balancing)
- 데이터 동기화
여러 데이터 센터가 각자의 데이터베이스를 사용하고 있다면, 동기화문제가 발생한다. 이는 장애발생시, 다른 데이터센터로의 우회할때 데이터의 불일치가 발생하게 된다는 것에 문제가 있다. 이런 상황을 막는 방법은 여러 데이터센터의 DB를 다중화하는 것이다. Netflix의 다중화 전략 - 테스트와 배포
여러 데이터센터로의 테스트와 배포는 중요하게 작용한다. 각자의 다른 데이터센터로의 연속적인 배포/테스트가 이루어지지 않는다면 이또한 데이터 동기화 문제를 일으킨다. 이는 자동화된 배포도구를 활용하여 해결할 수 있다.
시스템을 더 큰 규모로 확장하기 위해서는 더욱 시스템의 요소(Component)들을 분리하여 독립적으로 확장할 수 있도록 해야한다. 이때, MQ(Message Queue)가 핵심적인 해결책 중 하나로 사용되고 있다.
Message Queue (MQ)
MQ?
메시지 큐는 메시지의 무손실(큐에서 메시지를 consumer가 꺼내기 전까지 안전히 보관되는 특성)을 보장하는, 비동기 통신을 지원하는 컴포넌트 이다.
메시지 큐의 기본아키텍처는 메시지를 생산하는 생산자(Producer) 와 생산된 메시지를 소비하는 (Consumer)로 나뉜다. 메시지를 작성하는 Producer 는 메시지큐에 메시지를 발행(Publish) 한다. 큐에는 각 소비자들(서버)이 연결되어 메시지를 받아 맞는 동작을 수행한다.
pros & cons
메시지 큐를 활용하면 서비스와 서비스 또는 서버간의 결합이 느슨해져서 규모확장성이 보장되어야 하는 안정적인 애플리케이션을 구성하기 좋다. 생산자(Producer)는 소비자(Consumer)가 다운되어 있어도 메시지를 발행할 수 있고, 반대로 소비자는 생산자가 다운되어 있어도 메시지를 수신할 수 있다.
하지만 큐가 가득 차서 더는 큐에 메시지를 저장할 수 없는 상황에는 미시지를 다른 곳에 보존하거나 버리게 되는데 여기서 데이터의 손실이 발생할 수 있다.
오픈소스 메시지 큐
- RabbitMQ
- Kafka
로그, 메트릭 그리고 자동화
서비스의 규모에 따라서 로그/메트릭/자동화는 선택적으로 채택될 수 있다. 하지만 서비스 규모가 큰 서비스에서는 필수적으로 채택해야한다.
- 로그
에러사항에 대한 로그를 수집하는 활동이다. 시스템의 오류와 문제들을 보다 쉽게 찾아낼 수 있도록 하는 전략과 도구도 중요하게 작용할 것 이다. 에러로그는 서버단위로 모니터링 해서 따로 수집할 수도 있지만, 도구를 사용하여 이를 통합관리한다면 더 편리하고 빠르게 에러로그를 관리할 수 있다.
대표적인 에러로그 관리 툴로는 Graylog, Fluented, Flume 등이 있다. - 메트릭
CPU, 메모리, 디스크I/O 에 관한 메트릭정보를 잘 수집 및 분석한다면 유용한 정보를 얻을 수 있다. - 자동화
시스템이 크고 복잡해 지면 생산성을 높이기 위해 자동화 도구를 반드시 사용하게 된다. 이런 자동화 도구들을 사용해서 개발을 한다면 빌드/배포/테스트 등의 절차를 자동화할 수 있게되어 개발 생산성을 크게 향상시킬 수 있다.
