
1. Overview
Apache Flink는 실시간 데이터 처리를 위한 스트림 엔진이다. Flink 프로그램은 Java 기반 DataStream API를 사용해 작성하며, 연산자(operator)들을 연결해 데이터 흐름을 구성한다. 이 글에서는 가장 기본적인 스트림 예제인 WordCount 프로그램을 작성하고, Gradle과 shadowJar를 사용해 실행 가능한 JAR을 생성하는 과정을 정리한다.
2. 프로젝트 초기 설정
프로젝트는 Gradle과 Java 17을 사용한다. Flink DataStream API를 사용하기 위해 필요한 의존성은 flink-streaming-java와 flink-clients이며, 이후 Flink 클러스터에서 실행 가능한 fat-jar를 만들기 위해 shadowJar 플러그인을 구성한다.
plugins {
id 'java'
id 'application'
id 'com.github.johnrengelman.shadow' version '8.1.1'
}
ext {
flinkVersion = '1.19.1'
}
dependencies {
implementation "org.apache.flink:flink-streaming-java:${flinkVersion}"
implementation "org.apache.flink:flink-clients:${flinkVersion}"
}
application {
mainClass = 'com.flinkhandson.WordCountJob'
}
shadowJar {
archiveClassifier.set('all')
mergeServiceFiles()
manifest { attributes('Main-Class': application.mainClass.get()) }
}이 설정은 Flink API 기반 코드를 작성하도록 하고, 이후 Flink 클러스터에 제출할 수 있도록 단일 실행 파일 형태로 패키징하는 것을 목표로 한다.
3. DataStream 프로그램 구조
Flink DataStream 프로그램은 다음 다섯 단계로 구성된다.
- 실행 환경 생성 (StreamExecutionEnvironment)
- Source 정의 (데이터 생성 또는 입력)
- Transformation 구성 (flatMap, keyBy, sum 등)
- Sink 정의 (print, 파일 저장 등)
- env.execute()로 전체 파이프라인 실행
main 메서드 내부에서 이 흐름대로 DAG(연산 그래프)를 구성하고 Flink 엔진에 제출한다.
4. WordCountJob 작성
아래 예제는 리스트 형태의 문자열을 입력 데이터로 사용한 WordCount 프로그램이다. 외부 의존성 없이도 실행할 수 있어 Flink의 기본 구조를 익히기에 적합하다.
package com.flinkhandson;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCountJob {
public static void main(String[] args) throws Exception {
// (0) 실행 파라미터 파싱(선택 사항)
final ParameterTool params = ParameterTool.fromArgs(args);
// (1) 실행 환경 생성
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// (2) Source 정의: in-memory 리스트 데이터
DataStream<String> text = env.fromElements(
"hello flink",
"hello world",
"apache flink is powerful",
"real time stream processing with flink"
);
// (3) Transformation 구성
DataStream<Tuple2<String, Integer>> counts =
text
// 입력 문장을 단어로 분리
.flatMap(new Tokenizer())
// 단어를 key로 그룹핑
.keyBy(value -> value.f0)
// 단어별 카운트(sum)
.sum(1);
// (4) Sink 정의: 결과 출력
counts.print().name("print");
// (5) 파이프라인 실행
env.execute("WordCount Example");
}
/**
* Tokenizer: 한 줄의 문장을 단어로 분리하는 FlatMap 함수
* 입력: "hello flink"
* 출력: ("hello", 1), ("flink", 1)
*/
public static class Tokenizer implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.toLowerCase().split("\\s+")) {
if (!word.isEmpty()) {
out.collect(new Tuple2<>(word, 1));
}
}
}
}
}- fromElements: 리스트 형태의 문자열을 Source로 사용한다.
- flatMap: 문장을 단어로 나누고 각 단어를
(word, 1)형태로 변환한다. - keyBy: 동일한 단어 단위로 데이터를 그룹핑한다.
- sum(1): 단어별 등장 횟수를 누적한다.
- print(): 최종 결과를 TaskManager의 표준 출력으로 출력한다.
5. shadowJar로 실행 JAR 빌드
아래 명령으로 실행 가능한 fat-jar를 생성할 수 있다.
./gradlew clean shadowJar생성된 JAR 파일은 다음 위치에 저장된다.
build/libs/<프로젝트명>-all.jar이 JAR은 로컬 실행은 물론, 이후 Flink 클러스터(docker-compose 기반 또는 실제 환경)에서 실행할 수 있다.
6. 로컬 환경에서 직접 실행하기
Flink는 로컬 JVM에서 자동으로 “MiniCluster”를 생성해 DataStream 프로그램을 실행할 수 있다. IntelliJ에서 main 메서드를 실행하면 다음과 같이 단어별 카운트가 출력된다.
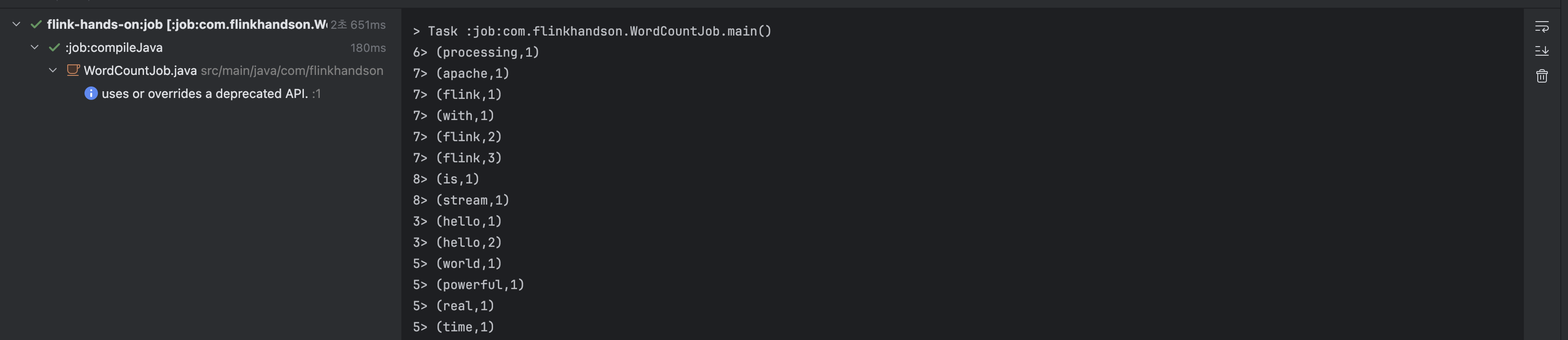
앞의 숫자는 subtask index이며 병렬도가 1보다 큰 경우 연산이 여러 서브태스크로 분배되어 처리되는 것을 확인할 수 있다.
참고자료
- Apache Flink 공식 문서: https://flink.apache.org/
