1. 왜 로컬 캐시(Caffeine)를 도입했을까?
영화 예매 시스템에서 가장 많은 요청이 집중되는 API는 "상영 중인 영화 목록 조회" API였다. 특히 홈 화면에서 진입 시마다 호출되는 이 API는 페이징 없이 전체 영화를 반환하기 때문에, 쿼리량이 많고 응답 바이트 크기 또한 컸다. DB 조회 없이 빠르게 응답할 수 있는 구조가 필요했고, 가장 가까운 위치에서 캐시를 두는 전략으로 로컬 캐시(Caffeine)를 도입하게 되었다.
이 단계에서는 Redis 없이 단일 인스턴스 구조만 가정하고 캐시 전략을 실험했다. 단일 서버 환경에서는 Redis보다 네트워크 비용이 없는 로컬 메모리 캐시가 더 적합하기 때문이다.
2. Caffeine 적용 방식 및 설정
Caffeine은 JVM 기반의 고성능 로컬 캐시 라이브러리다. LRU(Least Recently Used) 기반의 사이즈 제한과 TTL(Time To Live)을 지원하며, 응답 성능을 극적으로 개선할 수 있다.
캐시 대상
- 상영 중인 영화 전체 목록 (
key = movies:all) - 검색 조건이 포함된 영화 목록 (
key = movies:search:{title}:{genre_hash})
캐시 설정 예시
@Configuration
class CacheConfig {
@Bean
fun movieListCache(): Cache<String, List<MovieDto>> =
Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build()
}적용 방식
- 캐시 키를 기반으로 Caffeine에서 먼저 조회
- MISS인 경우 DB에서 조회
- 결과를 캐시에 저장
val cacheKey = "movies:all"
val cached = cache.getIfPresent(cacheKey)
if (cached != null) return cached
val result = movieRepository.findAll()
cache.put(cacheKey, result)
return result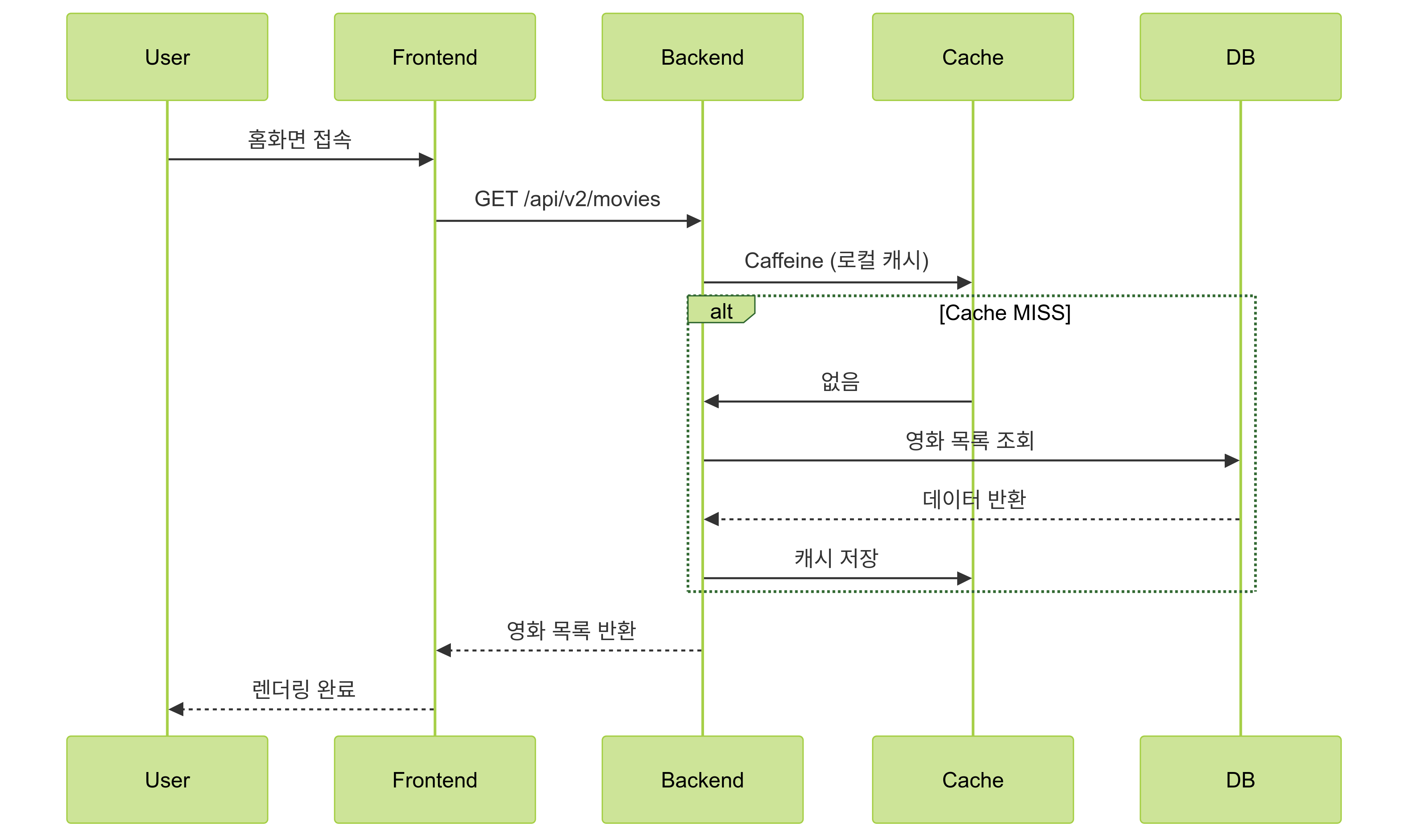
3. 테스트 기반 성능 확인
단일 인스턴스 기준에서 캐시 적용 전후의 성능을 K6로 테스트해보았다. 테스트는 다음과 같은 조건으로 구성했다:
- VUs: 50명
- Duration: 30초
- 시나리오:
/api/v1/movies,/api/v2/movies호출 반복
테스트 결과 요약
| 구분 | 캐시 미적용 (v1) | Caffeine 적용 (v2) | 개선률 |
|---|---|---|---|
| 평균 응답시간 | 214.35ms | 73.83ms | 65.56% ↓ |
| 서버 응답 대기시간 | 193.16ms | 58.78ms | 69.57% ↓ |
| 전체 반복 시간 | 2.21s | 2.07s | 6.33% ↓ |
캐시를 적용한 v2 API는 DB 없이 메모리에서 즉시 응답했기 때문에 응답시간이 평균 65% 이상 줄어드는 성능 개선 효과를 확인할 수 있었다.
4. 운영 시 고려사항 및 한계
단일 서버 기준에서 Caffeine은 매우 효과적이지만, 다음과 같은 한계를 가진다:
- 서버 재시작 시 캐시 초기화
- 멀티 인스턴스 환경에서는 캐시 일관성 불가
- TTL에 의존한 데이터 동기화
따라서 단일 인스턴스에서는 간단하게 적용할 수 있지만, 서비스가 수평 확장되거나 캐시 동기화가 필요한 상황에서는 Redis와의 병행 구조가 필요하다. 실제로 이후에는 "조회 5회 이상"인 데이터만 Redis에 동기화하는 방식으로 캐시 계층 구조를 설계했다.
5. 마무리: 단일 인스턴스 기준의 최적 캐시 전략
Caffeine은 빠른 응답 속도, 낮은 복잡도, 높은 적중률이라는 장점을 가진다. Redis를 사용하기 전에, 단일 서버 환경에서 가장 손쉽게 적용할 수 있는 캐시 전략으로서 큰 효과를 발휘한다.
다만 실제 운영 환경에서는 인스턴스 간 일관성과 캐시 적중률, TTL 설계 등 다양한 요소를 함께 고려해야 하며, 이 부분은 다음 글에서 다룰 Caffeine + Redis + DB 기반의 3단 캐시 구조로 이어진다.
