
1. Overview
Flink는 “스트림 중심 분산 처리 엔진”이다. 단일 머신이 아니라 여러 노드가 협력해 실시간으로 데이터를 처리한다. 그래서 단순히 코드를 실행하는 게 아니라, 클러스터 전체의 CPU와 메모리를 어떻게 나눠 쓰고 조율할지가 중요하다.
Flink는 Hadoop YARN이나 Kubernetes 같은 리소스 매니저와 통합해 동작할 수도 있고, 자체 클러스터(standalone)로도 구동된다.
2. Anatomy of a Flink Cluster
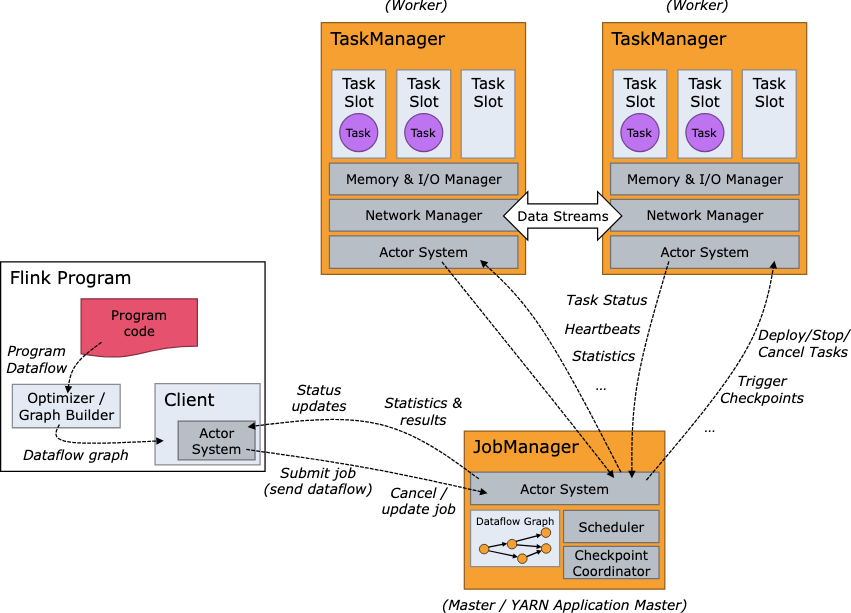
출처: Apache Flink 공식 문서 – Architecture (Apache License 2.0)
Flink의 런타임은 JobManager와 TaskManager라는 두 축으로 구성된다. 먼저 Client가 사용자가 작성한 Flink 프로그램을 JobManager로 전송한다. 이때 두 가지 실행 모드가 있다.
- Attached Mode: 클라이언트가 Job의 상태를 계속 모니터링함
- Detached Mode: Job을 맡기고 연결을 끊음
JobManager는 받은 Job을 여러 작업 단위(Task)로 쪼개고, 이를 TaskManager들에게 분배한다. TaskManager는 실제로 데이터를 처리하는 워커 노드다. 이렇게 클라이언트 → JobManager → TaskManager로 이어지는 구조가 Flink 실행의 기본이다.
3. JobManager - 조정자
JobManager는 클러스터의 두뇌 역할을 한다. 한마디로 “어떤 Task를 언제, 어디서, 어떻게 실행할지 결정하고, 실패하면 다시 복구하는 컨트롤러”다. 내부적으로는 세 가지 주요 컴포넌트로 나뉜다.
- ResourceManager: 클러스터의 자원을 관리한다. TaskManager의 슬롯을 배분하고 해제한다.
- Dispatcher: REST API를 통해 Job을 받으면 새로운 JobMaster를 띄운다. 동시에 Flink Web UI를 구동해 실행 현황을 보여준다.
- JobMaster: 단일 JobGraph의 실행을 담당한다. JobMaster는 태스크 간 의존 관계를 관리하고, 체크포인트를 조정해 장애가 나도 상태를 복구할 수 있도록 한다.
고가용성(HA) 환경에서는 JobManager가 여러 개 존재할 수 있는데, 한 대가 리더로, 나머지는 대기 상태로 있다가 장애 시 즉시 승계한다.
4. TaskManager - 작업자
TaskManager는 실제 연산을 수행하는 주체이다. JobManager가 분배한 Task를 받아 실행하고, 처리 결과를 다른 TaskManager로 스트림 형태로 전달한다. 각 TaskManager는 하나 이상의 Task Slot을 가진다. 슬롯은 "병렬 작업을 위한 리소스 단위"다. 예를 들어 슬롯이 3개라면 이 TaskManager는 동시에 3개의 Task를 수행할 수 있다. 슬롯이 많을수록 병렬성이 높아지지만, JVM 하나 안에서 CPU와 네트워크를 공유하기 때문에 너무 많은 슬롯은 오히려 자원 경쟁을 일으킬 수 있다.
5. Tasks and Operator Chains
Flink는 여러 Operator(map, filter, window 등)를 Task 단위로 묶어 실행한다. 이걸 Operator Chaining이라고 부른다. 예를 들어 map → filter → sink 세 단계가 하나의 Task로 묶이면, 스레드 간 버퍼링이 사라지고 지연이 줄어든다. 이 덕분에 Flink는 높은 처리량과 낮은 지연을 동시에 달성할 수 있다. 즉, Flink는 “데이터를 즉시 전달하는 파이프라인”을 내부적으로 최적화해 구성한다.
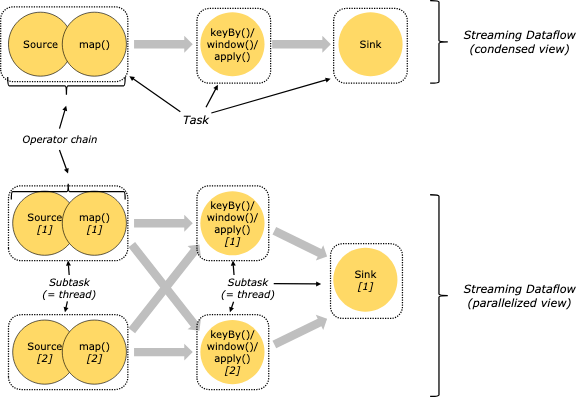
출처: Apache Flink 공식 문서 – Architecture (Apache License 2.0)
6. Task Slot과 리소스
TaskManager는 JVM 프로세스 하나로 실행된다. 내부에는 여러 개의 슬롯이 있고, 각 슬롯은 일정량의 메모리를 할당받는다. 예를 들어 3슬롯 TaskManager라면 메모리를 1/3씩 나누어 쓴다. 단, CPU는 슬롯 간 격리되지 않아 하나의 JVM 안에서 공유된다. 슬롯이 하나면 완전 독립 프로세스로 실행되고, 슬롯이 여러 개면 여러 Task가 하나의 JVM을 공유하며 TCP 연결, 하트비트, 데이터셋을 함께 사용한다.
또한 Flink는 기본적으로 Slot Sharing을 지원한다. 같은 Job에 속한 여러 Task가 하나의 슬롯을 공유할 수 있다. 이 구조 덕분에 리소스 효율이 좋아지고, 가벼운 연산(map, source 등)과 무거운 연산(window 등)이 공존해도 균형 있게 분산된다.
