
<1주차 활동내용>
아나콘다로 주피터노트북 설치
파이썬 속성 정리
판다스 치트시트
파일 경로 설정방법
🐧주피터 노트북
🐍아나콘다
🤔파이썬 / r 등 데이터분석 관련 패키지 많음. 버전이 업데이트되며 꼬이는 문제를 가상 개발환경을 통해 귀찮은 일을 없애는것!
🐍주피터 노트북
1. 작업을 해줄 폴더를 새로 만들고
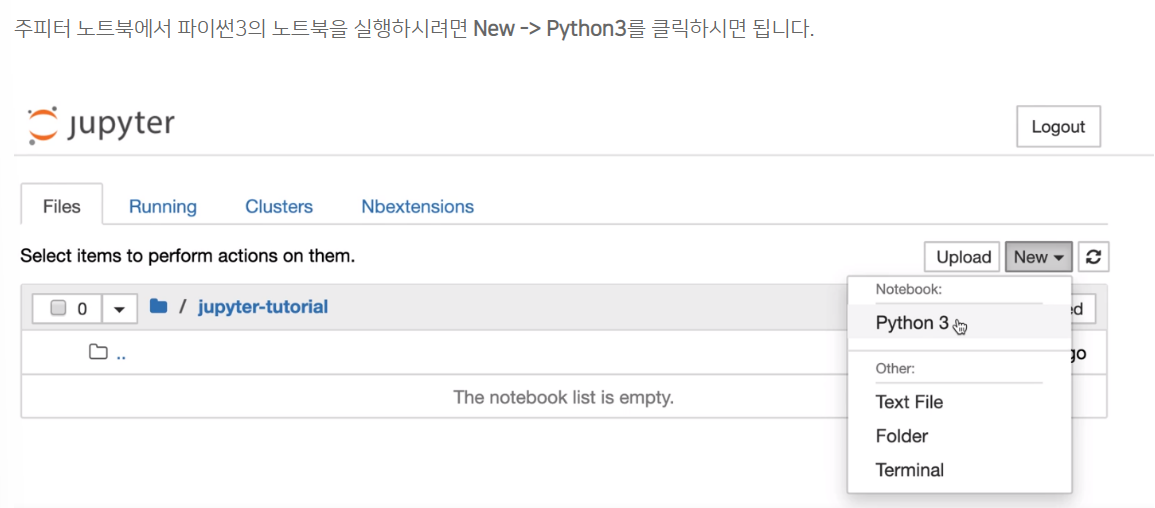
python3 선택해서 만들기. 제목도 변경 가능
2. 다양한 단축키 + 마크다운 + 메뉴탭
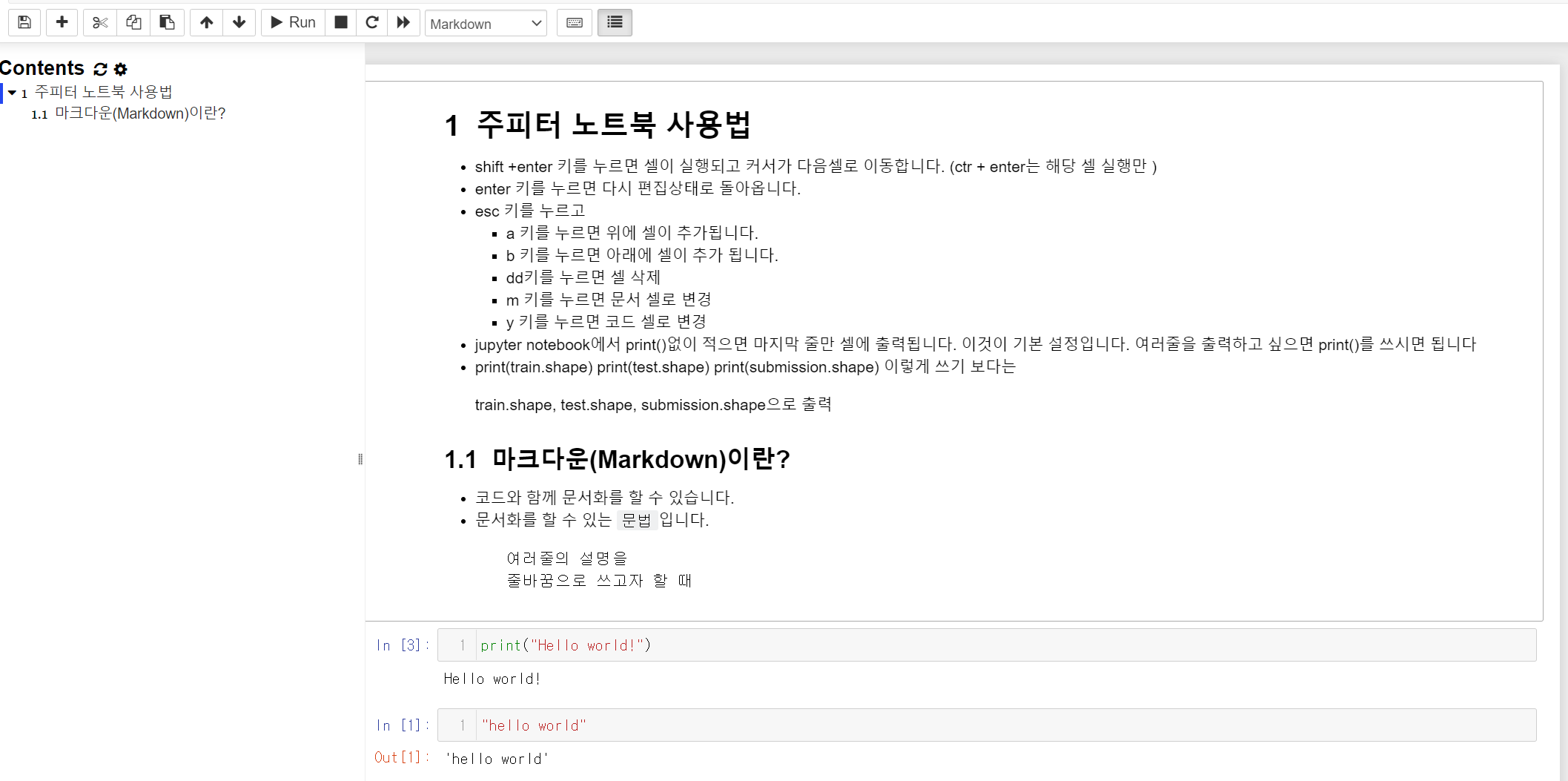
- 그 밖에 - h : 다양한 주피터 노트북의 단축키를 확인
- velog 처럼 마크다운 문법을 사용함. 코드랑 왔다갔다 자주 쓴다.
- 메뉴탭 :
View -> Toggle Line Numbers : 라인 넘버를 확인
Kernel -> Restart & Clear Output : 커널과 결과를 초기화
3. Nbextensions 설치
Nbextensions -> Table of Contents 의 기능을 활용하면 index 기능을 활용할 수 있습니다.
-> 여기서 오류 발생했었는데 설치는 잘됐으나
체크박스가 안뜨는 문제 발생. 터미널에 아래 코드 입력해서 해결 ! (윈도우 기준)pip install jupyter_contrib_nbextensions && jupyter contrib nbextension install --user🐧파이썬 속성정리
파이썬 기초는 학습한 상태이므로 일부만 기재하겠습니다.
🦭string
lower, upper 소문자로 , 대문자로!
# til 이라는 변수에 문자열을 담아봅니다.
til = "Today I Learned"
til
# 결과 : 'Today I Learned'
# 모두 소문자로 만들어 보세요.
til.lower()
# 결과 : 'today i learned'
# 모두 대문자로 만들어 보세요.
til.upper()
# 결과 : 'TODAY I LEARNED'🦭 lists 반복문
enumerate로 인덱스와 원소 가져오기!
lang = []
lang.append("python")
lang.append("java")
lang.append("c")
# 결과 : ['python', 'java', 'c']
# enumerate를 사용하면 인덱스 번호와 원소를 같이 가져올 수 있습니다.
for i, val in enumerate(lang):
print(i, val)
#결과 : 0 pyhon
# 1 java
# 2 c🦭 문자열
strip로 앞뒤 공백 제거!
address = " 경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층"
# 앞뒤 공백을 제거합니다.
# 데이터 전처리 시 주로 사용합니다.
address = address.strip()
address
# 결과 : '경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층'
address 변수에 다시 저장을 해줘야 반영이 된다.
split으로 문자열을 분리하여 리스트로!
# 공백으로 문자열 분리
address_list = address.split()
address_list
# 결과 : ['경기도', '성남시', '분당구', '불정로', '6', 'NAVER', '그린팩토리', '16층']
# split() 괄호안에 들어가는거의 기준으로 분리🔸문자열 분리했더니 리스트가 되었당!
슬라이싱, startswith,in을 통해 문자열에 있는지 확인
# 슬라이싱으로 문자 가져오기
address:[:2]
# 결과 : '경기'
# startswith를 사용하면 특정 문자가 포함되는지 + 시작되는지 여부 확인
address.startswith("경기")
# 결과 : True
# in을 사용하게 되면 특정 문자열을 포함하고 있는지 여부를 확인할 수 있습니다.
"경기" in address
# 결과 : True
🦭 리스트
join으로 리스트를 문자열로!
# " ".join(리스트)를 사용하면 리스트를 공백 문자열을 연결할 수 있습니다.
# 리스트로 분리된 문자열을 다시 연결합니다.
" ".join(address_list)
# 결과 : '경기도 성남시 분당구 불정로 6 NAVER 그린팩토리 16층'adress_list = " ".join(address_list)해야 반영이 된다.
in
# in을 사용하게 되면 리스트에 해당 데이터를 포함하고 있는지 여부를 확인할 수 있습니다.
# "경기"가 리스트에 포함되는지를 봅니다.
"경기" in address_list
# 결과 : False --> "경기도" 처럼 완전하게 적어야 True가 나옵니다.
🐧판다스
🐼pandas
🤔수식으로 계산할 수 있고 시각화도 할 수 있는 데이터 분석도구입니다.
🤔참고 자료
링크텍스트
-> 스크롤 하는데 10분이 걸리는 pandas 문서
링크텍스트
-> pandas cheat sheet. 컨닝페이퍼같은 요약본!
import pandas as pd🤔참고 강의 (무료 기준)
이 강의만으로는 판다스 실습이 부족하므로 참고 자료나 강의는 기회가 되면 따로 정리하겠습니다!
< 본 강의 내용 정리 >
DataFrame
df = pd.DataFrame(
{"a" : [4, 5, 6],
"b" : [7, 8, 9],
"c" : [10, 11, 12]},
index = [1, 2, 3])
df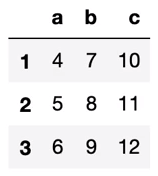
결과를 보시면 a, b, c 컬럼을 가진 DataFrame이 생성된 것을 보실 수 있습니다.
Series
df["a"]
df1 4
2 5
3 6
출력됩니다. 이러한 형태를 series 데이터라고 합니다.
- 1차원 구조이다.
- 벡터다.
- dataframe 으로 바꾸고 싶다면 대괄호 하나 더쓰기
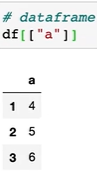
- 2차원 구조이다.
- 행렬이다.
Subset
일부 값만 불러오기
-
row 기준
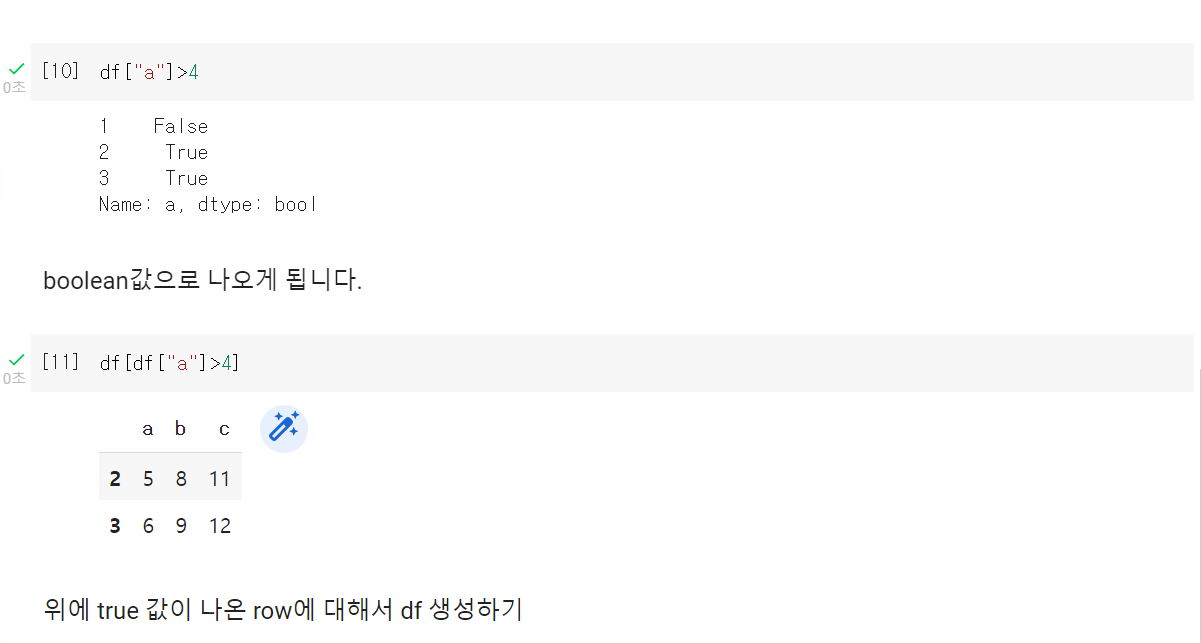
-
cloumn 기준

df['a','b'] 이렇게 불러오면 오류나용
Summarize Data
Categorical한 값의 빈도수를 구하는 방법입니다.
value_counts

Reshaping
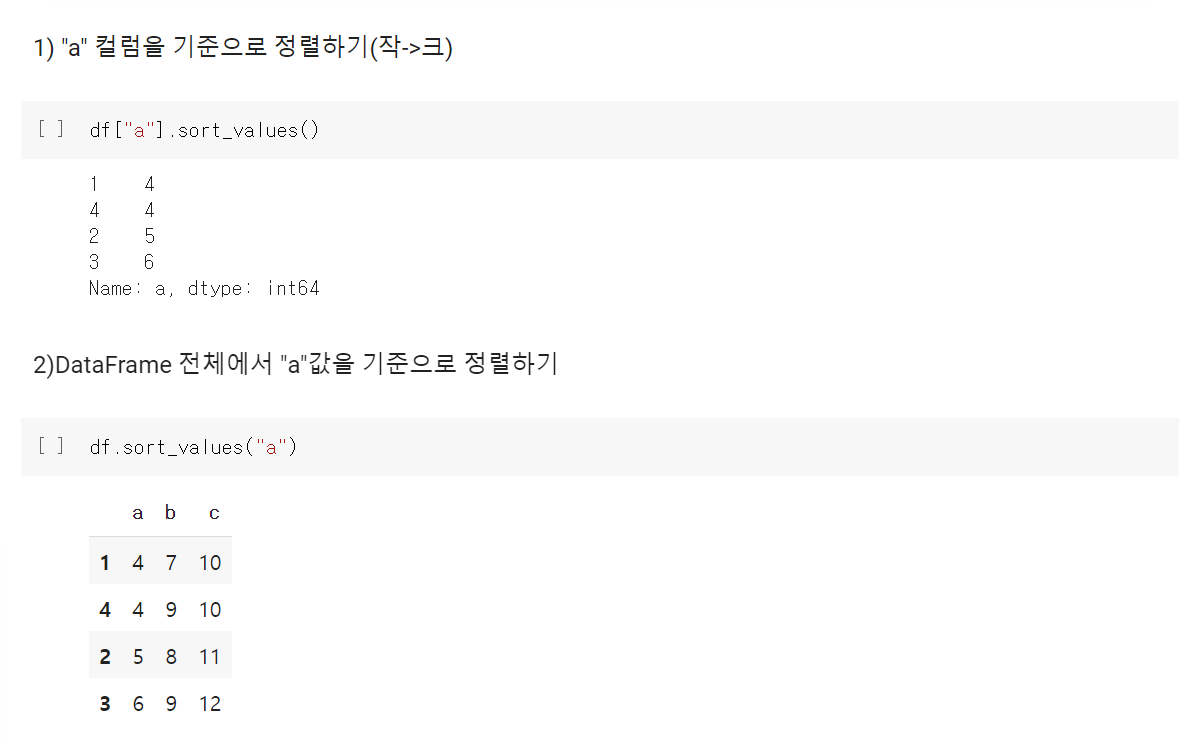
sort_values , drop
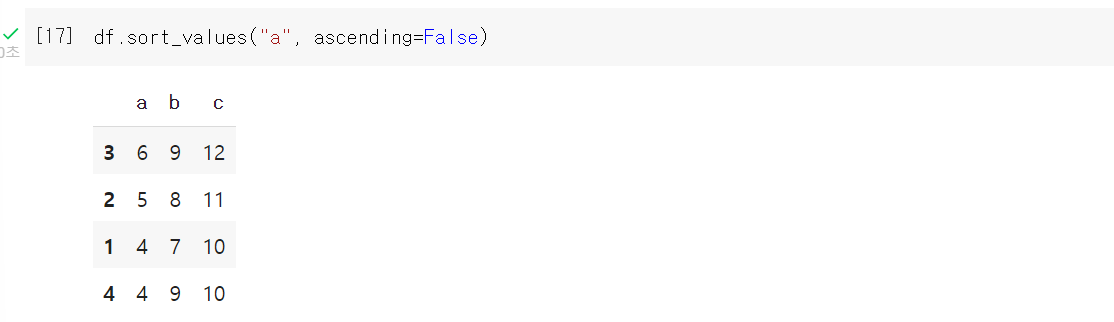
sort_values
- 역순으로 정렬 ascending = False
drop

Group Data
평균값 구하기 groupby,pivot_table
Groupby

pivot_table

plotting 시각화
꺾은선
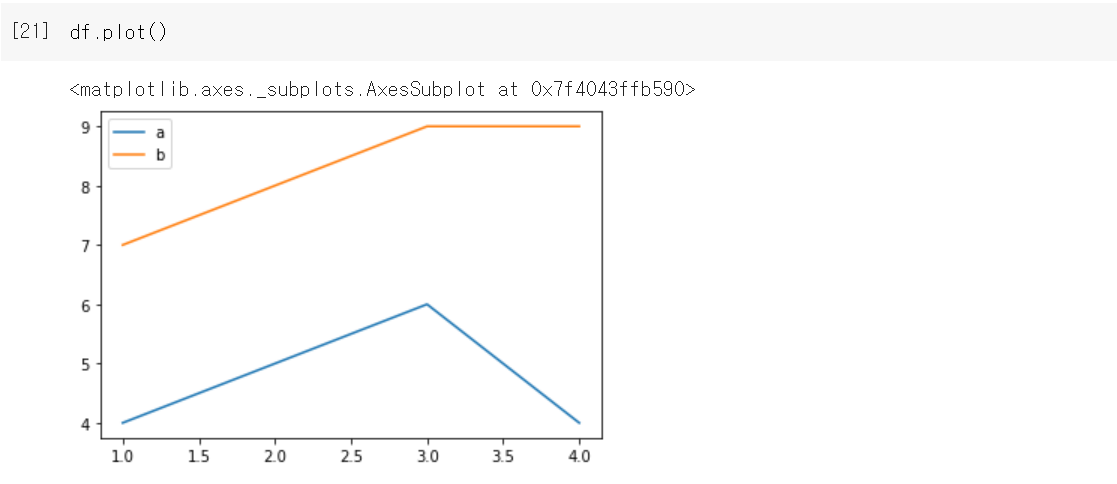
막대
밀도함수
2. 위의 참고 자료 정리
🐧 파일 경로 설정 방법
절대경로와 상대경로
절대경로
http 로 시작하는 위에 링크나 C:\user .... 최상위 디렉토리 포함
상대경로
= 현재 위치한 곳을 기준으로 하는 경로
./ = 현재 위치
../ = 현재 위치의 상위폴더
../../ = 두 단계 위의 상위폴더
csv 파일 경로 설정 방법
1) 'file-path-setting'의 이름을 가진 주피터 노트북 파일을 만들어 줍니다.
2) 데이터를 다운받아줍니다.
https://www.data.go.kr/dataset/15003493/fileData.do
3) 다운받은 파일을 주피터 노트북에서 작업하고 있는 폴더로 가져오기
-
- 공공데이터 파일을 다운받는다. 이때 C드라이브 download 폴더에 저장된다.
-
- 맥은 %mv이고 윈도우 환경은 !move, 슬레쉬(/)가 안될때는 원화표시()로 해주어야 한다.
-
-
!move "C:\Downloads\도로교통공단1.csv" .
* 윈도우 환경이고, 상기와 같이 적으면, C드라이브에 file-path폴더로 이동된다. * C드라이브가 아닌 다른곳(목적지)로 이동하고 싶으면 원하는 경로를 따옴표 묶어 추가하여 적는다 예) !move "C:\Downloads\도로교통공단.csv" "F:\python" .(마침표) * 즉 윈도우 환경일때 !move "파일다운로드 받은 경로" "보내고싶은 목적지 경로" .(마침표) 한다. (큰따옴표 필수)제일 끝에 한 칸을 띄우고 . 을 적어야됩니다!
주피터 노트북 파일이 있는 폴더 경로를 확인하려면 주피터 노트북 상에서 %pwd를 실행하시면 됩니다.
이것도 저것도 힘들다면 다운받은 파일을 File-path 폴더에 드래그앤드롭으로 한폴더에 수동으로 넣으면 됩니다!
-
4) **판다스로 csv파일 불러오기**
pd.read_csv("폴더/ 파일 명 ", encoding="cp949")encoding="cp949" 는 한글파일 인코딩을 위해서 해줌
5) 데이터 파일의 경우 따로 폴더를 만들어서 관리하는 것을 추천드립니다.
- 'data' 폴더를 생성 한 후 'csv'파일을 옮겨줍니다.
ex)상대경로

data 라는 폴더에 이 파일을 넣어줬기 때문에 폴더의 경로를 써줘야지 , 파일만 써주면 못찾는다!!
glob
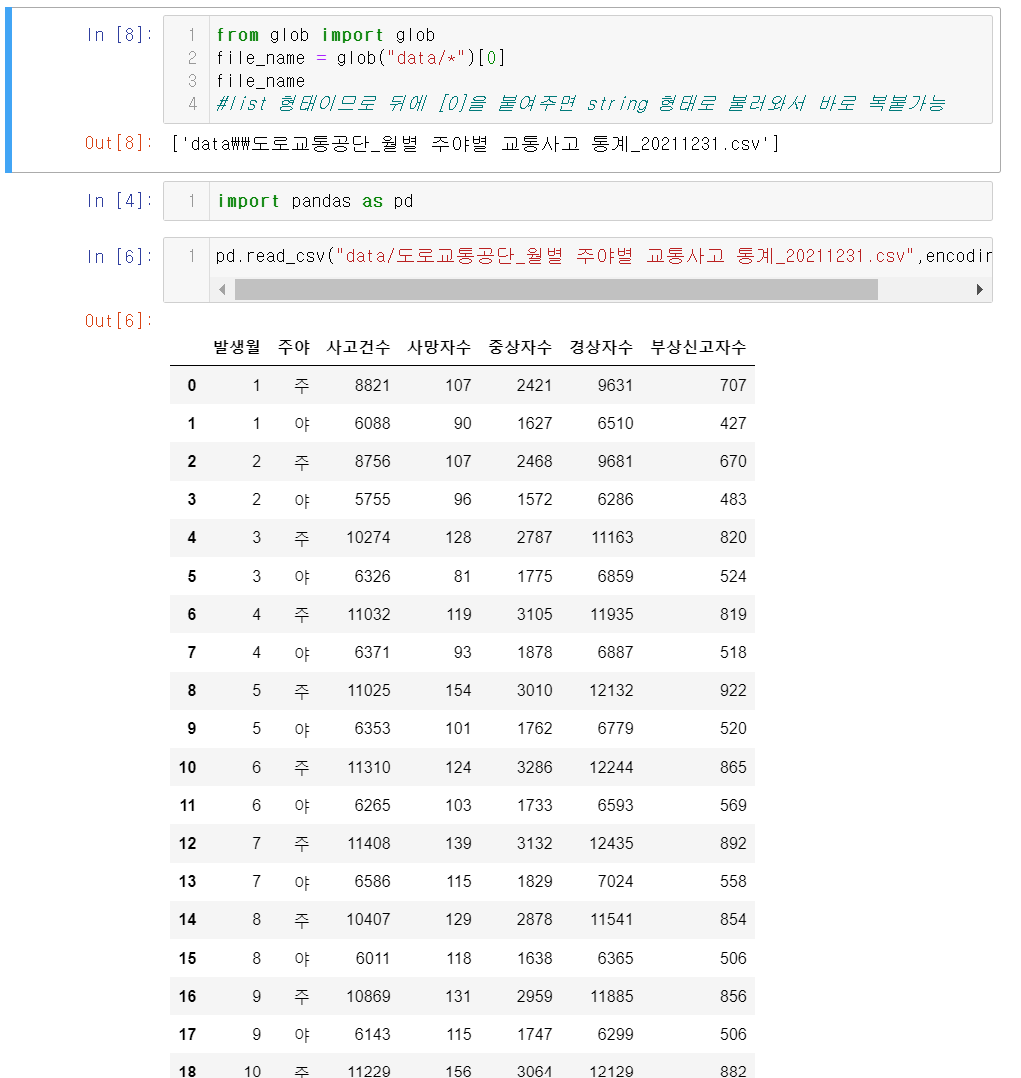
🤔파일명 불러올때 오타날것같아요!
-> glob 적극적 사용 권장
file_ name 이라는 변수를 설정하면 파일명을 바로 불러올 수 있다.
pd.read_csv(file_name, encoding="cp949")참고로 cp949는 한글인코딩해주는건데 , 신기했던 점이 내가 직접 한글을 치면 실행이 안되는데 불러온 한글을 ctrl c+V 해주면 될때가 있다는점...
삽질하는것은 이럴때 억울한것같습니다.
여러 파일을 한번에 로드하는 방법
🤔소상공인시장진흥공단같이 크기가 상당히 큰 파일일 경우 ,압축을 풀면 text 파일 , csv파일 등등 너무 많은 종류의 파일이 있습니다. 이럴때 일수록 잘 정리해서 가져와야겠죠?
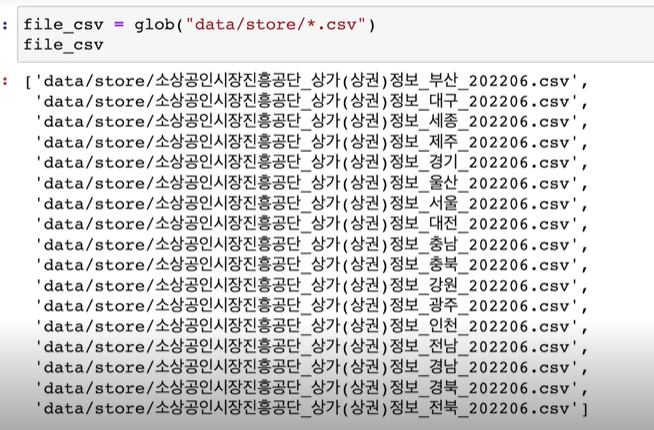
*뒤에 .csv로 csv 파일들만 불러와봤다.(그 밖에 한글 , 기호 등 여러 구분문자로도 불러올수 있습니다.)
그 다음, file 이름들만 불러와보자.
🤔요런 반복문이 있었나? 파이썬에서 배웠다!
for item in iterable:
... 반복할 구문...
iterable한 객체이기만하면 반복할 수 있다.
iterable은 사전적의미와 똑같이 반복가능한 객체를 말합니다.
ex) list , dictionary,string, tuple....
https://wikidocs.net/16045 참고 !
아무튼 , file_list 를 만들어서 각각의 file 을 불러오고 싶다면
file_list = []
for file_csv_name in file_csv:
temp = pd.read_csv(file_csv_name)
file_list.append(temp)file_list 에는 이제 file 들이 리스트 형태로 담기게 되었다!
여러개의 dataframe 이 있음
file_list[0]
file_list[-1] 등등을 통해 각각의 dataframe 확인가능,
concat 등등도 강의에서 휙휙 지나가지만 뒤에서 배울 예정이므로 일단 보류!
