개요
CPU 성능지표
- Instruction Count
- CPI (Cycle Per Instruciton)
- Clock Cycle Time
가정
- 두 가지 버전의 cpu를 살펴본다
- A simplified version
- A pipelined version
- 9개 instruction을 구현한다.
- memory : lw, sw
- arithmetic/logical : add, sub, and, or, slt
- Control transfer : beq, j
- PC, Instruction Memory, Data Memory, Registers, ALUs가 있다.
- 일반적인 CPU의 5개 구성 : ALU, Control Unit, Memory, Input Unit, Output Unit.
요소 동작
- PC : instruction memory에 접근해 instruction을 fetch
- Register # : register에 읽기/쓰기
- instruciton class에 따라 달라지는 것
- ALU 계산 결과 (숫자, 메모리 주소, branch target 주소)
- Memory load인지 store인지
- PC에 넣을 값이 PC+4인지, 그 밖의 target address인지
Logic Design Basics
- bit encoding
- Low V : 0, High V : 1
- One wire per bit (여러 비트는 여러 와이어를 요구)
- Combinational Elements
- AND-gate
- Adder
- Mux (multiplexer)
- ALU (Arithmetic/Logic Unit)
- Sequential Elements : Register
- 회로에서 데이터를 저장. 언제 업데이트 될지 결정하기 위해 Clock signal 사용
< D flipflop >
+-----+
D --| |-- Q
write --| |
clock --|> |
+-----+
clock 입력부 표기가 > 이면 PGT (rising-edge)
>o 이면 NGT (falling-edge)
< Clock signal >
level 1 ____ ____ ____
| | | | | |
level 0____| |____| |____| |_______
↑ ↑
0에서 1로 바뀔 때 업데이트 1에서 0으로 바뀔 때 업데이트
= PGT (rising-edge) = NGT (falling-edge)- Datapath : 데이터와 주소를 처리하는 CPU내 요소 (레지스터, ALU, mux, 메모리 등)
CPU 살펴보기
교재에서 살펴본 CPU는 굵직한 다섯 개 요소를 갖고있다.
- PC와 Instruction Memory
- Registers 모듈
- ALU
- Data Memory
각 요소는 대략 아래의 흐름으로 동작한다.
- 일단 PC값에 해당하는 라인의 인스트럭션을 읽는다.
- 그 다음 인스트럭션을 적절하게 쪼개서 각 부분에 전달해주면
- ALU의 연산과 (숫자든 주소든)
- Data Memory의 load와 store
- Destination에 해당하는 Register값 갱신까지 이루어진다.
- beq나 j를 수행한다면 PC의 값도 PC+4가 아닌 다른 값이 들어가게 된다.
이 흐름이 동시에 일어나는지에 따라 두 가지로 분류한다.
- Single-cycle : 한 인스트럭션 끝나고, 그제서야 다음 인스트럭션 시작
- Pipelined : 인스트럭션 여러 개를 동시에 굴림
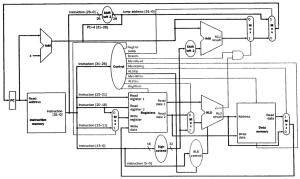
Single-cycle Datapath
- Control Signal
RegWrite가 1이어야 RegDst, MemtoReg가 의미가 있다.
| instruction | RegDst | ALUOp | ALUSrc | Branch | MemRead | MemWrite | RegWrite | MemtoReg |
|---|---|---|---|---|---|---|---|---|
| R-fotmat | 1 | 10 | 0 | 0 | 0 | 0 | 1 | 0 |
| lw | 0 | 00 | 1 | 0 | 1 | 0 | 1 | 1 |
| sw | X | 00 | 1 | 0 | 0 | 1 | 0 | X |
| beq | X | 01 | 0 | 1 | 0 | 0 | 0 | X |
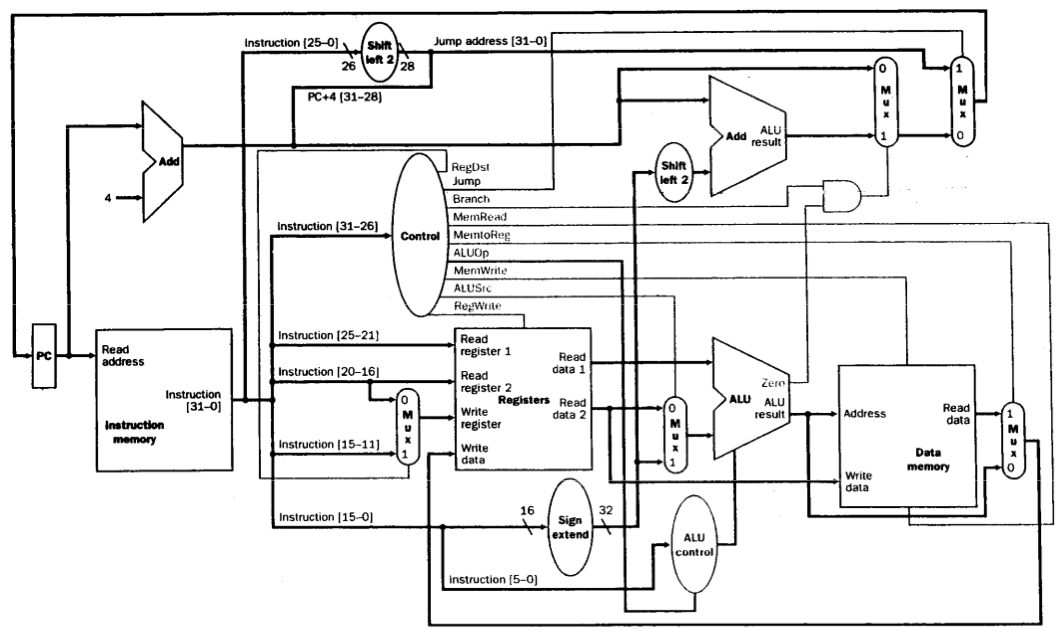
Pipelined Datapath
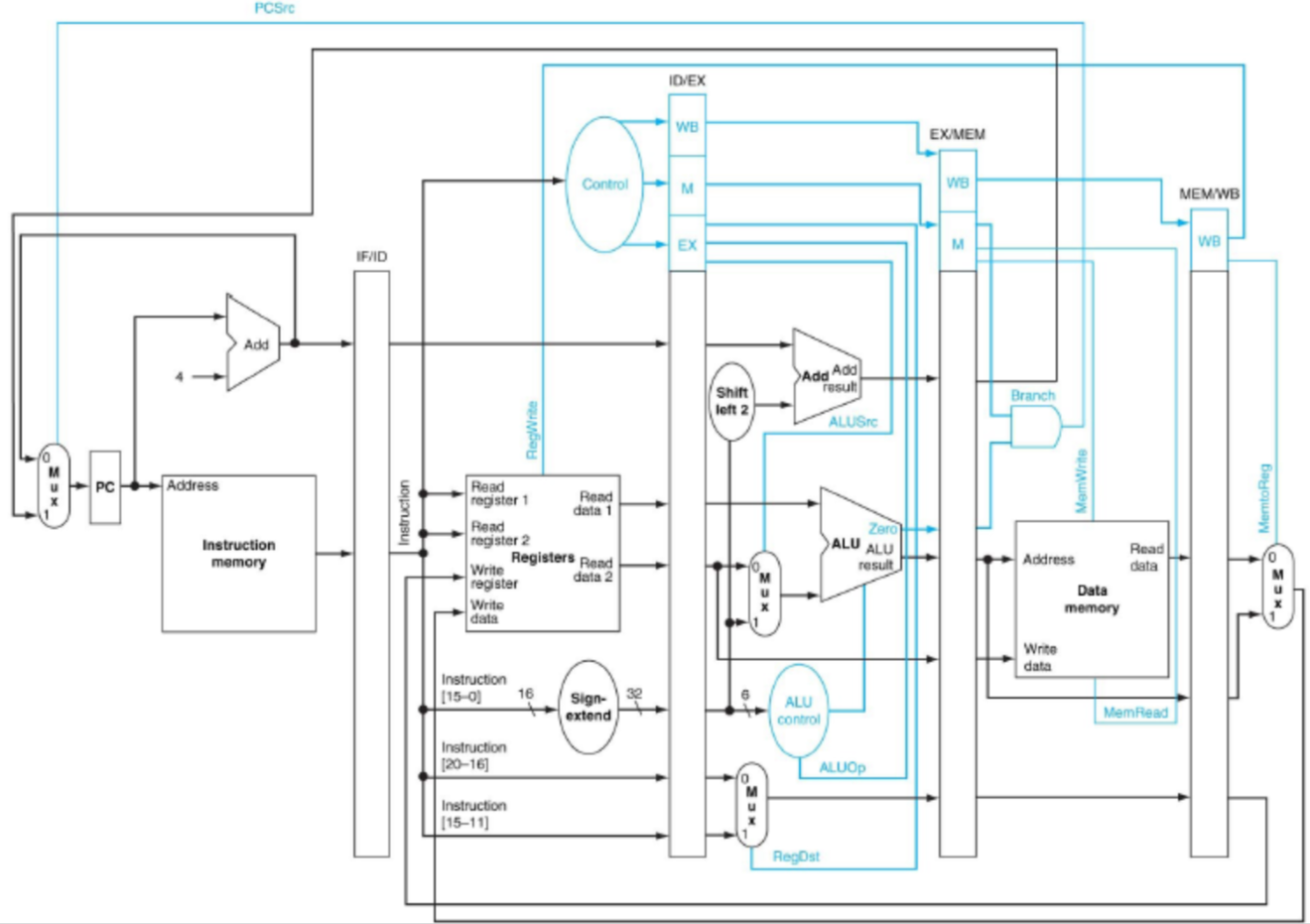
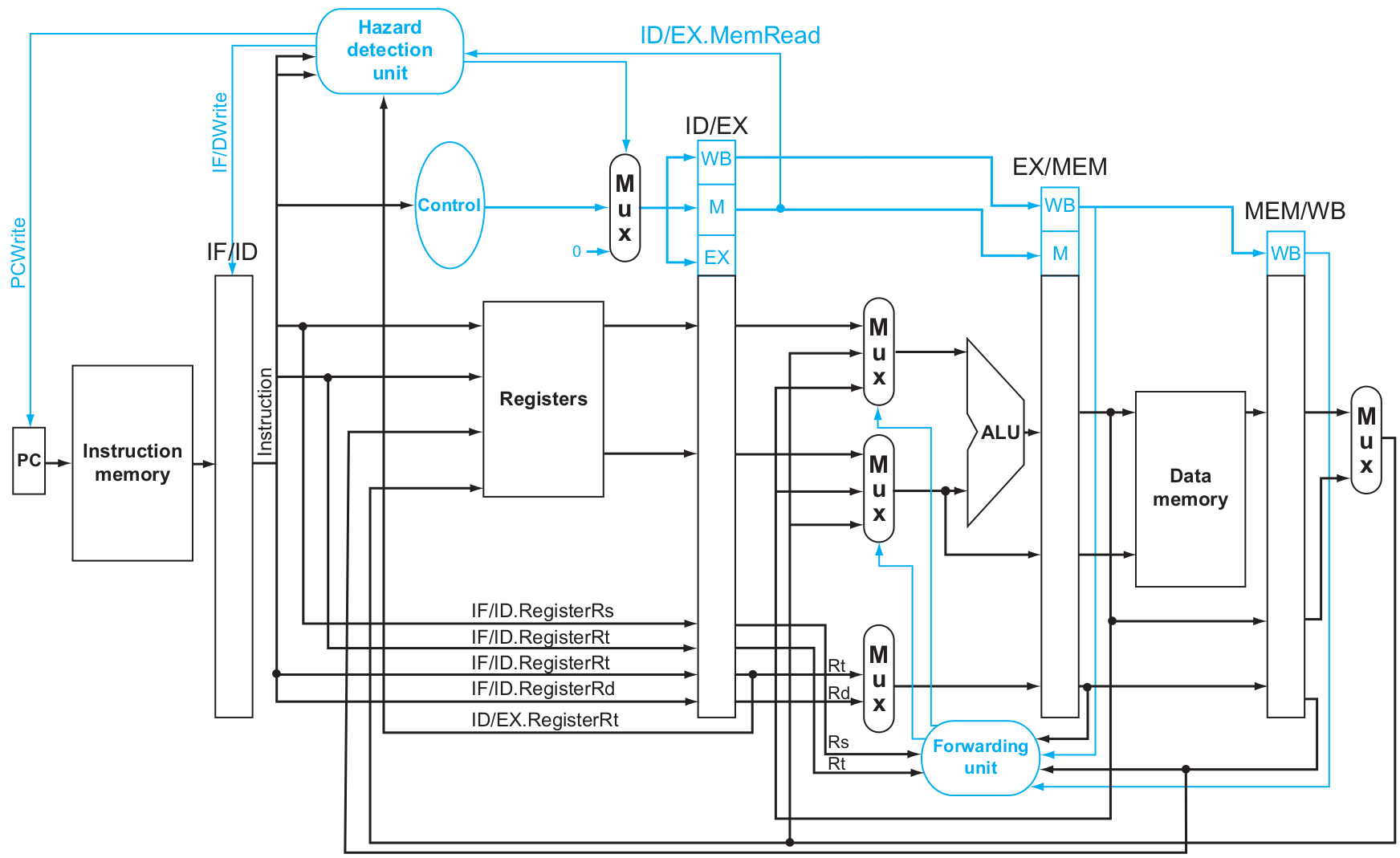
MIPS는 작고 규칙적인 ISA이기에 파이프라이닝 하기 좋다.
한 인스트럭션을 5개 스테이지로 쪼개어 수행한다.
기존에는 한 인스트럭션 수행시간이 1 클럭 사이클이었다면, 분할된 뒤에는 가장 긴 스테이지의 수행시간이 1 클럭 사이클이 된다.
- IF : Instruction Fetch
- ID : Insturction Decode + Register Read
- EX : Execute
- MEM : Access Data Memory
- WB : Write to Register
따라서 파이프라이닝을 한다면 throughput이 증가한다.
그러나 정해진 Latency(한 인스트럭션 수행시간)는 줄일 방도가 없다.
각 스테이지 사이에는 버퍼역할을 하는 레지스터가 있다.
- ID와 EX스테이지 사이에 있는 버퍼는 ID/EX레지스터라고 한다.
- ID/EX.RegisterRs는 버퍼에 있는 rs레지스터 값을 의미한다.
- ID/EX.RegDst는 버퍼에 있는 RegDst시그널 값을 의미한다.
Hazard
파이프라이닝 데이터패스를 사용할 때 각 인스트럭션 사이의 싱크를 맞추기 위해 고려할 사항이 있다.
hazard는 source of problems이다.
Structural Hazards
자원을 여럿이서 차지하려고 할 때 발생
- 만약 메인메모리와 인스트럭션 메모리가 하나라면 IF와 MEM이 충돌한다. ALU또한 하나라면 PC계산과 EX스테이지 계산이 충돌한다.
- 그러나 MIPS에서는 따로 있다. 그래서 Structural hazard문제는 무시해도 된다.
Data Hazards
갱신되기 전 레지스터를 가져다 쓰려고 할 때 발생
- EX hazard : 한 스텝 전에서 포워딩하면 된다.
if( EX/MEM.RegWrite and EX/MEM.RegisterRd!=0 // 갱신하고 있냐?
and EX/MEM.RegisterRd = ID/EX.RegisterRs ) // rs가 바뀔거냐?
forwardA = 10 // 응~ rd를 rs로 포워딩해
if( EX/MEM.RegWrite and EX/MEM.RegisterRd!=0 // 갱신하고 있냐?
and EX/MEM.RegisterRd = ID/EX.RegisterRt ) // rt가 바뀔거냐?
forwardB = 10 // 응~ rd를 rt로 포워딩해- MEM hazard : 두 스텝 전에서 포워딩하면 된다.
- (주의) EX hazard와 MEM hazard가 동시에 나타나면 EX hazard를 고른다.
if( MEM/WB.RegWrite AND MEM/WB.RegisterRd!=0 // 갱신하고 있냐?
and not ( EX/MEM.RegWrite and EX/MEM.RegisterRd!=0 // EX hazard 있는거 아니지?
and EX/MEM.RegisterRd = ID/EX.RegisterRs )
and MEM/WB.RegisterRd = ID/EX.RegisterRs ) // rs가 바뀔거냐?
forwardA = 01
if( MEM/WB.RegWrite AND MEM/WB.RegisterRd!=0 // 갱신하고 있냐?
and not ( EX/MEM.RegWrite and EX/MEM.RegisterRd!=0 // EX hazard 있는거 아니지?
and EX/MEM.RegisterRd = ID/EX.RegisterRt )
and MEM/WB.RegisterRd = ID/EX.RegisterRt ) // rt가 바뀔거냐?
forwardB = 01- load-use case : 어쩔 수 없다. 미래에서 포워딩 땡겨올 수는 없으니 1 cycle stall줘야 한다.
- 한 줄기 희망 : 컴파일러가 인스트럭션 순서를 잘 바꾼다면 stall없이 갈 수도 있다.
- 절망편 : 1 cycle insert stall (이 말은 즉, Hazard detection unit이 시그널을 보내서 PC가 업데이트되지 않도록 하고 + IF/ID Register를 flush하고 + ID/EX의 시그널 파트로는 0을 보낸다는 것)
if( ID/EX.MemRead and
( ID/EX.RegisterRt = IF/ID.RegisterRs
or ID/EX.RegisterRt = IF/ID.RegisterRt ) )
insert bubble(nop)Control Hazards(Branch Hazards)
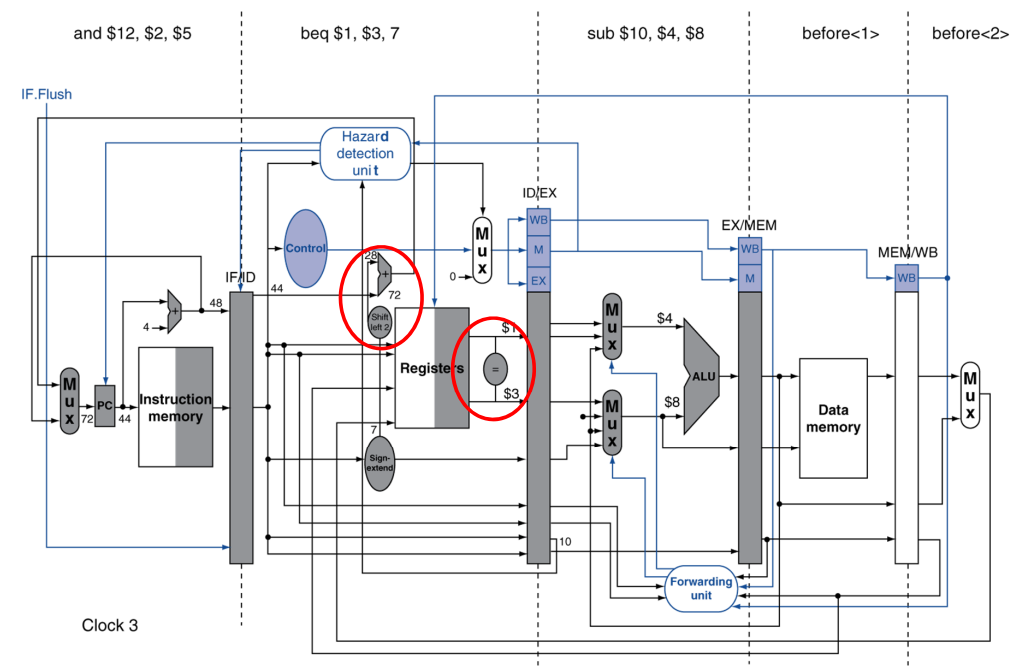
beq를 사용할 때 점프를 하긴 하는건지, 한다면 어디로 하는지는 MEM스테이지에서나 알 수 있다. (beq한 번 하려고 stall 3개를 먹여야 한다)
- 위 사진처럼 수정되기 전 상태에서는 Prediction이 유일한 해결법이다. * 운 좋으면 stall 없이 다음 instruction을 수행 가능
Control hazard는 근본적으로 해결할 수는 없지만 어느정도 완화할 수 있다.
- 관련 모듈을 ID스테이지로 땡겨오고 Comparator를 붙인다. ---> 예측 틀려도 1 stall로 해결 가능
- 브랜치를 예측한다.
- Static Prediction : 브랜치 국룰을 미리 정의하고 이대로 예측한다.
- Dynamic Prediction : 버퍼를 두고 결과를 저장한다. 1비트 Predictor는 한 번 예측실패하면 바꾼다. 2비트 Predictor는 두 번 예측 실패하면 바꾼다.
Branch가 data hazard를 만날 수도 있다.
- beq 2스텝 전, 3스텝 전의 data hazard : 그냥 포워딩하면 해결
- beq 1스텝 전 R-format, 2스텝 전 lw : 1 stall 넣어야된다.
- beq 직전 lw : 2 stall 넣어야 된다.
Exception
exception은 CPU에 의해 발생하는 예기치 못한 일이다. (Interrupt는 I/O controller에 의해 발생한다.)
handling
exception은 CP0(System Control Coprocessor)에 의해 관리됨
- 문제가 발생한 PC를 EPC(Exception Program Counter)에 저장
- Cause register에 문제원인 저장 (0 : undefined opcode, 1 : overflow)
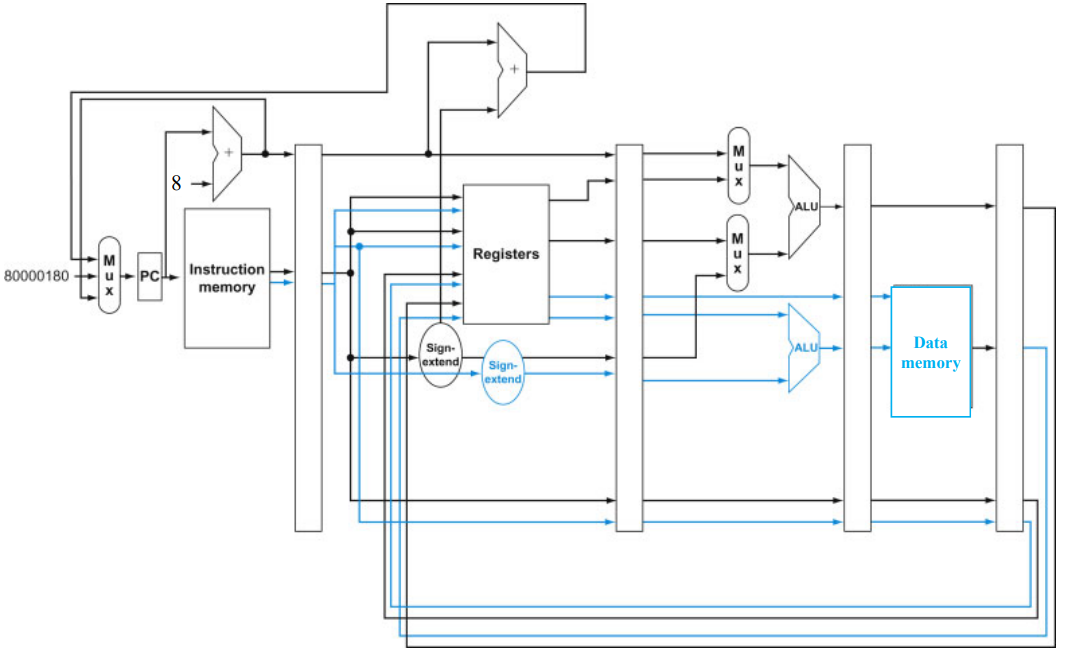
- handler로 jump (8000, 00180)
위 절차의 대안으로 Vetored Interrupts를 사용할 수 있다.
(다시 말해 인터럽트로 해결하거나 직접 핸들러로 점프하면 된다)
만약 다시 시작 가능하면 (restartable) corretive action을 취하고 EPC로 돌아간다
계속 하기 어려운 상황이면 프로그램(프로세스)를 멈추고 에러를 리포트한다.
handling in a Pipeline
파이프라인의 핸들링도 크게 다르지 않다.
- 문제가 발생했다
- 하고있던거 멈춘다. (add과 같이 레지스터를 갱신하는 인스트럭션이라면, 갱신 하지 않는다)
- 이전에 들어왔던 인스트럭션은 그대로 진행한다.
- 문제가 발생한 인스트럭션과, 그 이후에 들어온 인스트럭션 모두 flush
- EPC, Cause 레지스터 기록
- 핸들러로 컨트롤 전송
라는 내용은 다시 시작가능한 경우에 대한 것이고, 만약 절차 진행 중 종료해야 할 상황이면 종료한다.
Multiple Issue
ILP : Instruction Level Parallelism
---> 파이프라이닝으로 달성 가능한 것이었다.
ILP의 정도를 더 높이기 위해서는 아래 두 방법이 있다.
- 파이프라이닝을 더 깊게 해서 클럭사이클 줄이기
- 멀티플 이슈 : 파이프라인 복사해서 의존성없는 인스트럭션 동시에 넣고 돌리기 (IF가 한 번에 두 개 돌아간다. ID도 두 개 돌아간다. EX도, MEM도, WB도)
멀티플 이슈를 평가하면 아래와 같다.
- 동작을 하긴 하지만 기대보다는 효율이 낮다.
(Dual issue이면 이상적으로 2배를 처리해야 하는데 그보다는 낮다) - 그리고 의존성 문제 제거 어렵다.
- 메모리의 지연과 한정된 대역폭 때문에 파이프라인을 가득 채우기는 현실적으로 어렵다.
speculation
branch prediction과 유사한데 load에 쓸 수 있는 방법으로 생각하면 쉽다.
load speculation
- avoid load and cache miss delay
- 효율적인 주소 예측, 로드될 값 예측, 저장되기 전에 로드, 저장된 값을 로드 유닛으로 우회
- don't commit load until speculation cleared
Static Multiple Issue
컴파일러가 동시에 넣을 인스트럭션 집합을 정해둔다.
Dual(2-way multiple) issue라면 두 개씩 짝지어둔다. 이걸 packet이라고 한다.
- slot 1은 R-format과 branch, j가 들어간다고 가정한다.
- slot 2는 lw, sw가 들어간다고 가정한다.
만약 한 slot에 채울 마땅한 인스트럭션이 없으면 nop로 채운다.
** nop는 32비트가 전부 0이다.
멀티플 이슈를 하면 처리할 수 있는 양이 많아질 수도 있지만, stall이 발생하면 그 비용이 단일 이슈보다 커진다. 때문에 좀 더 정교한 스케쥴링이 필요하다.
- 인스트럭션 실행 순서 바꾸기(필요하면 lw, sw의 오프셋까지 바꾼다.)
- loop unrolling :
- loop control overhead 감소
- register renaming 사용
- loop-carried anti-dependencies 회피
- procedure unrolling
Dynamic Multiple Issue
동시에 넣을 인스트럭션 집합을 미리 정해두지 않고 런타임에 결정한다.
superscalar processors
끝
Fallacies
- 파이프라이닝은 어렵다
- 아이디어는 쉬운데 구체적으로 파고 들어가면 너무어렵다
- 파이프라이닝은 기술에 의존적이다.
- 많은 트랜지스터는 발전된 기술을 현실화한다.
- 파이프라인에 관련된 ISA 설계는 기술동향과 연관있다.
Pitfalls
- 간단한 ISA 디자인이 파이프라이닝을 어렵게 만드는 요인이 되지는 않는다
- 복잡한 인스트럭션 셋 --> 파이프라이닝 오버헤드
- 복잡한 주소지정 모드 --> 레지스터 갱신 사이트이펙트
- 지연 분기 --> advanced pipelines have long delay slots
기타
ISA와 Datapath/control은 서로 영향을 주고받는다.
복잡성은 power wall을 유발한다. (긴 파이프라인의 강력한 하나 쓰는 것보다, 작은 코어 여러개 쓰는게 낫다.)
