Redshift COPY 명령으로 테이블에 레코드 적재하기
Redshift의 벌크 업데이트 명령인 COPY를 사용해서 테이블에 레코드를 적재하는 과정을 담은 글이다.
이 과정에서 AWS IAM Role을 사용해볼 수 있다.
- COPY명령을 사용해 raw_data 스키마 밑 3개의 테이블에 레코드를 적재해볼 예정
- 각 테이블을 CREATE TABLE 명령으로 raw_data 스키마 밑에 생성
- 이 때 각 테이블의 입력이 되는 CSV파일을 먼저 S3로 복사해야함
- 그래서 S3 버킷부터 미리 생성 (S3 Web Console)
- S3에서 해당 테이블로 복사를 하려면 Redshift가 S3 접근권한을 가져야함
- 먼저 Redshift가 S3를 접근할 수 있는 역할을 만들고 (IAM 웹콘솔)
- 이 역할을 Redshift 클러스터에 지정 (Redshift 웹콘솔)
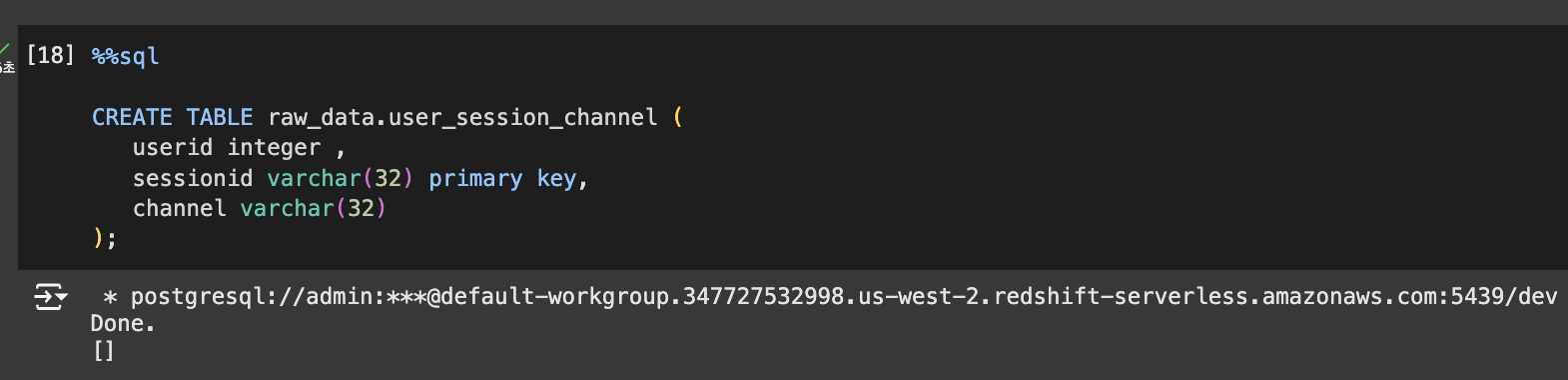
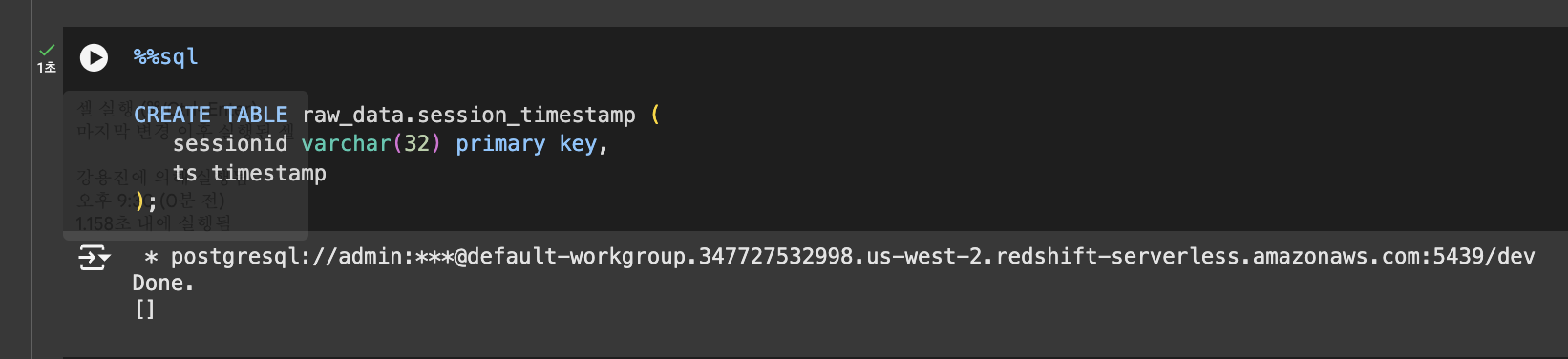
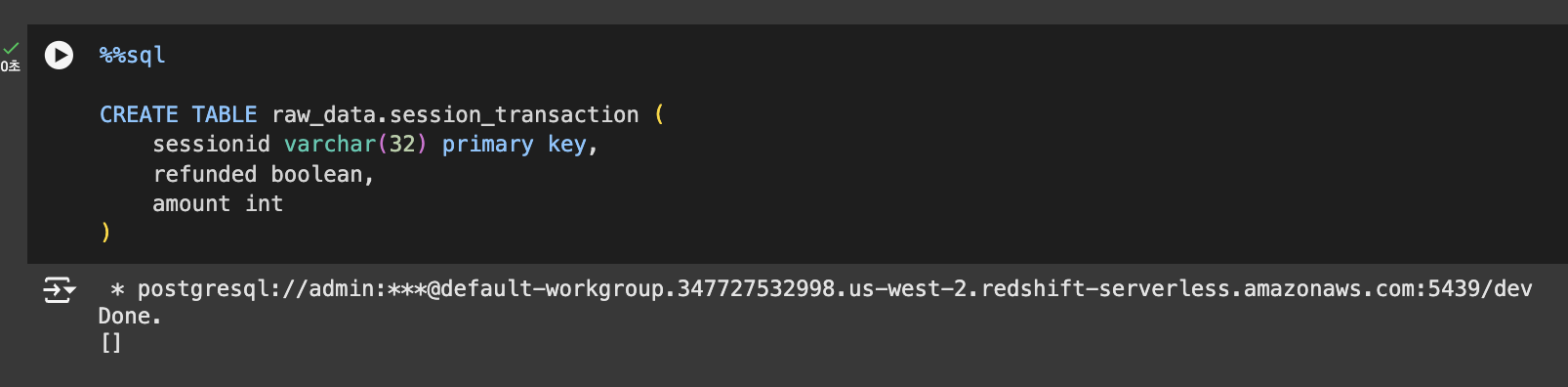
- raw_data 테스트 테이블 만들기 - 테이블 생성
- raw_data 테스트 테이블 만들기 - S3 버킷 생성과 파일 업로드
- AWS 콘솔에서 S3 Bucket 하나 만들고 거기로 업로드하기
- Redshift에 S3 접근권한 설정
- Redshift가 앞서 만든 S3 버킷을 접근할 수 있어야함
- AWS IAM (Identity and Access Management)을 이용해 이에 해당하는 역할(Role)을 만들고 이를 Redshift에 부여해야함
테이블 생성
S3 버킷 생성과 파일 업로드
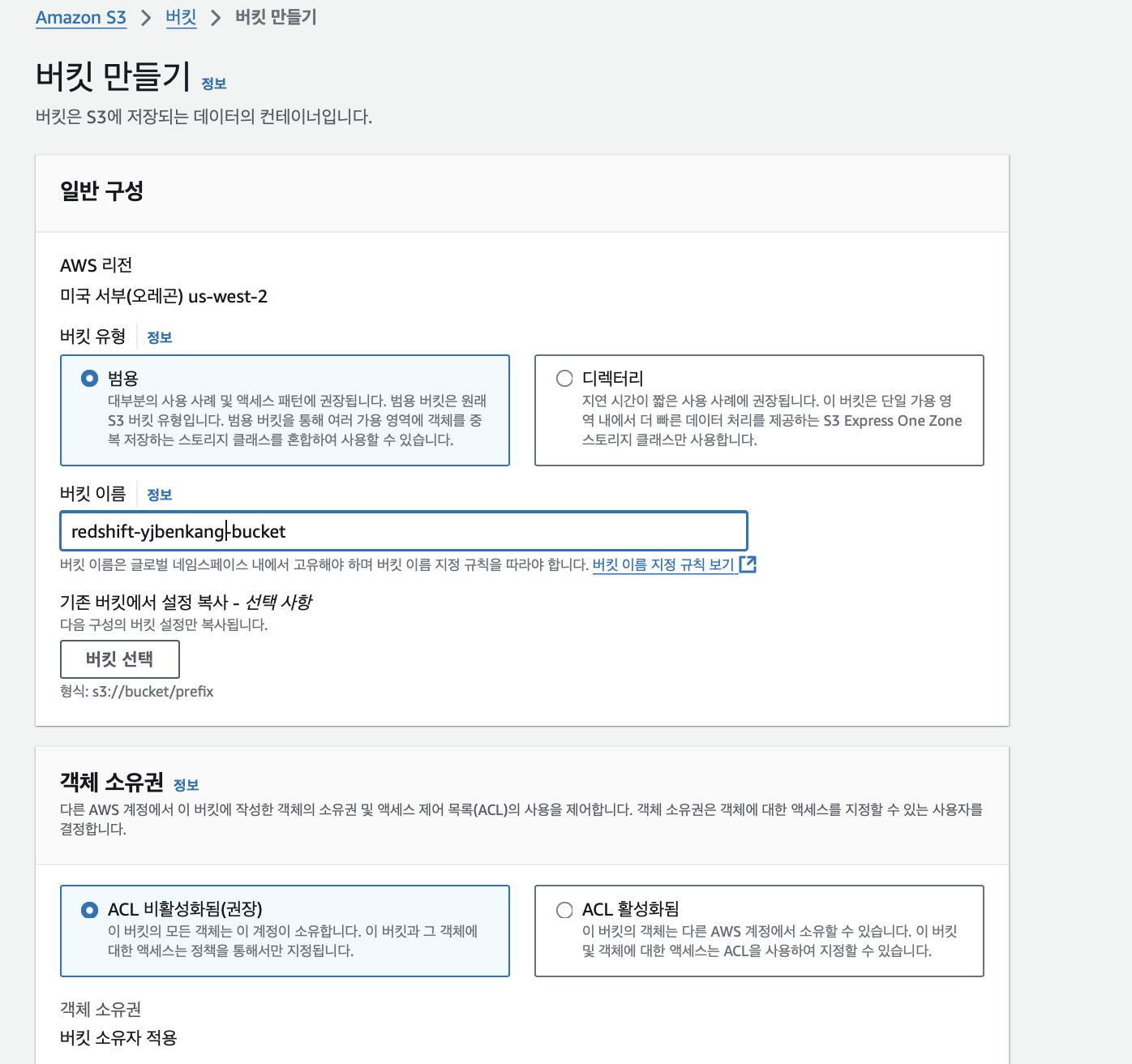
지역으로 redshift의 지역과 동일한 오레곤 선택 후 S3로 이동 후 버킷 생성 클릭한다. 버킷 만들기에서 버킷 이름을 쓰고 다른 세팅은 그대로 두고 버킷을 생성한다.
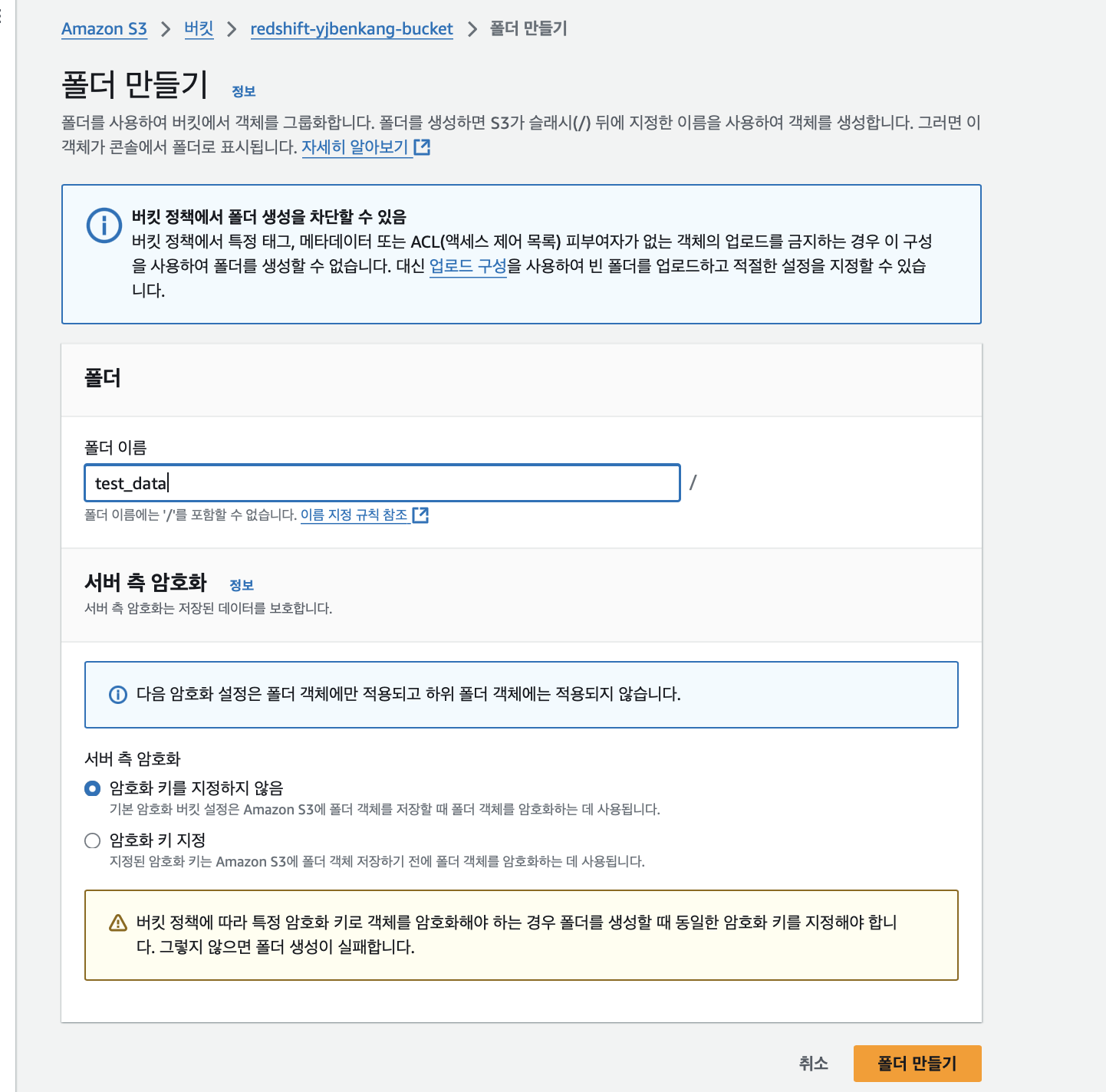
csv파일들이 들어갈 test_data 폴더를 만들어준다.
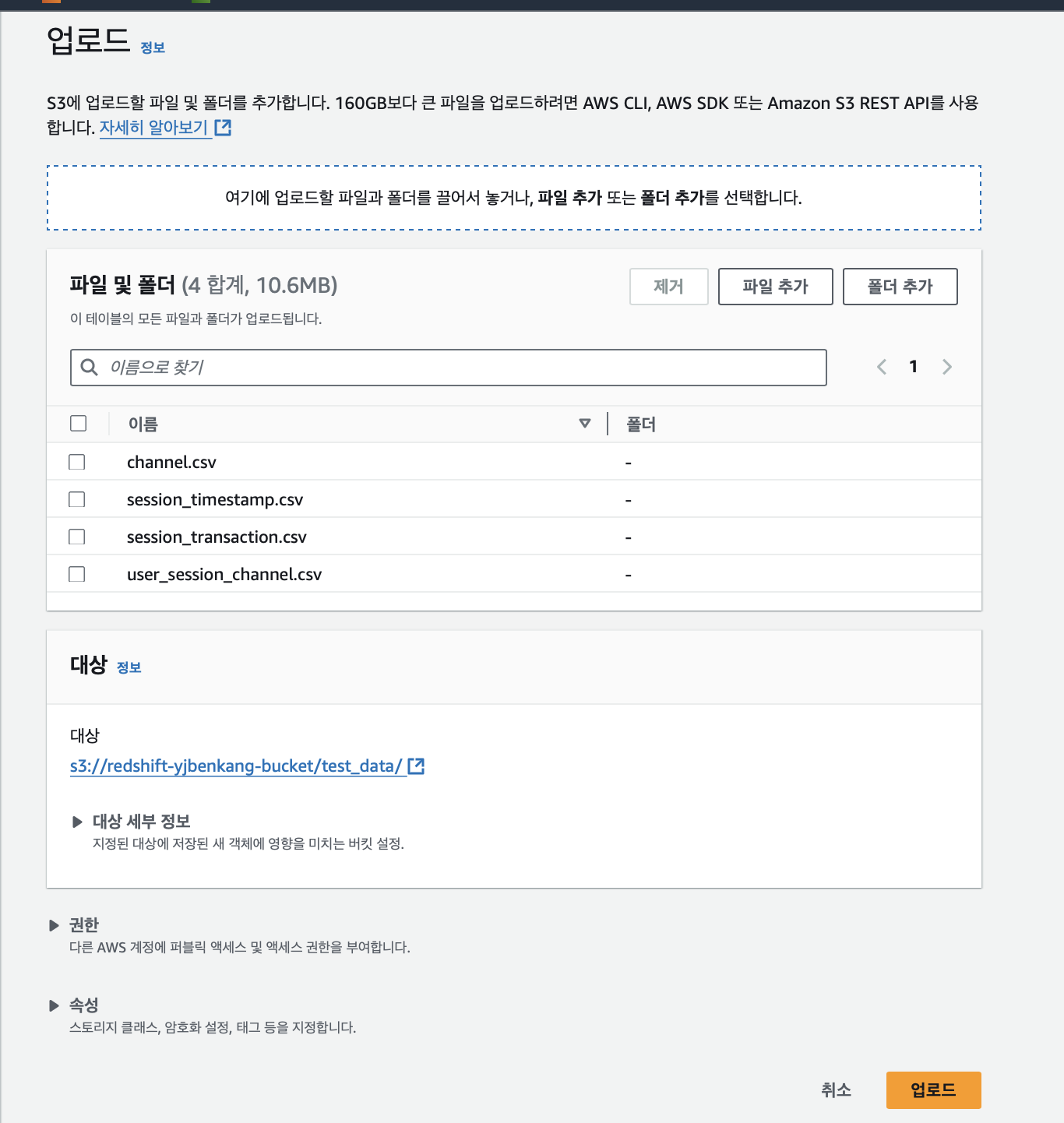
준비한 csv파일들을 업로드해준다.
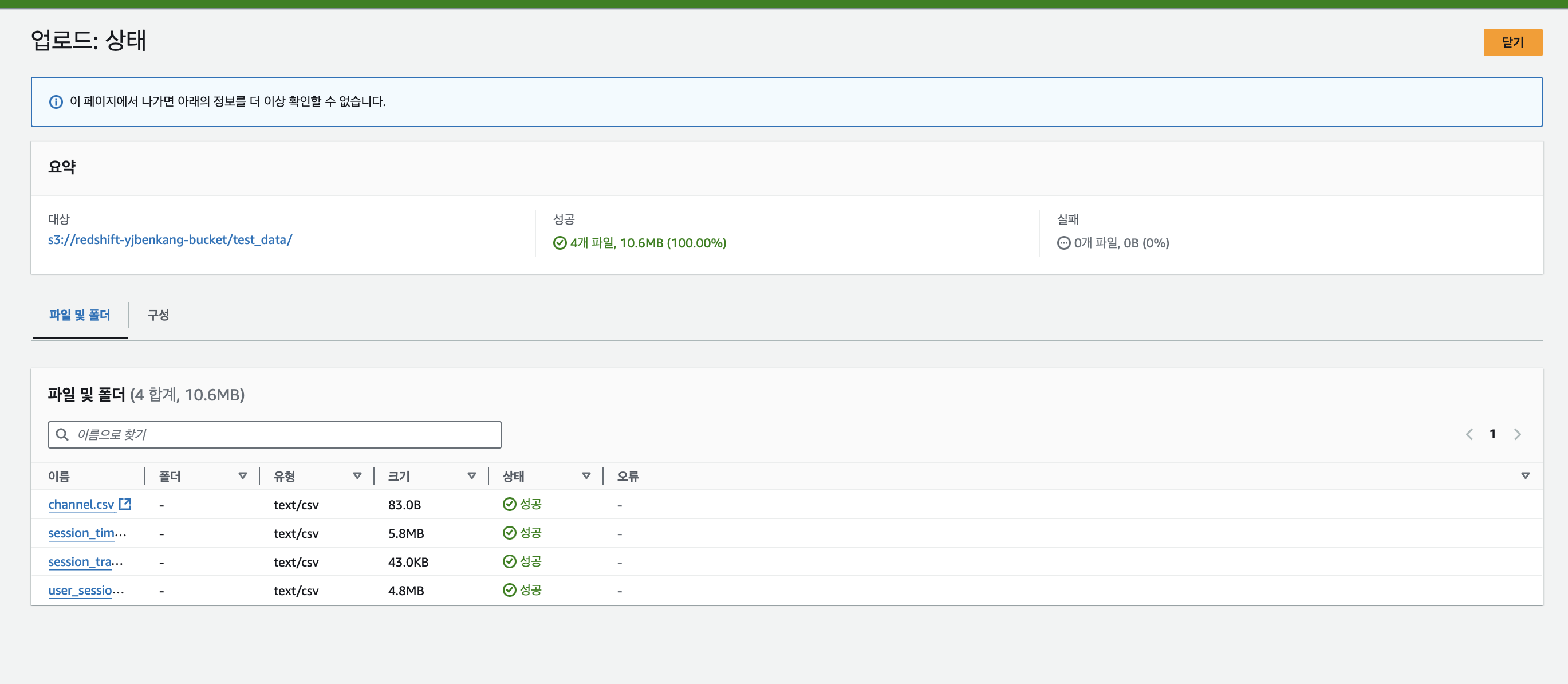
업로드 확인완료
Redshift의 S3 접근 권한용 IAM Role 만들기
AWS IAM 콘솔로 접속 후 역할 클릭 후 역할 생성 클릭
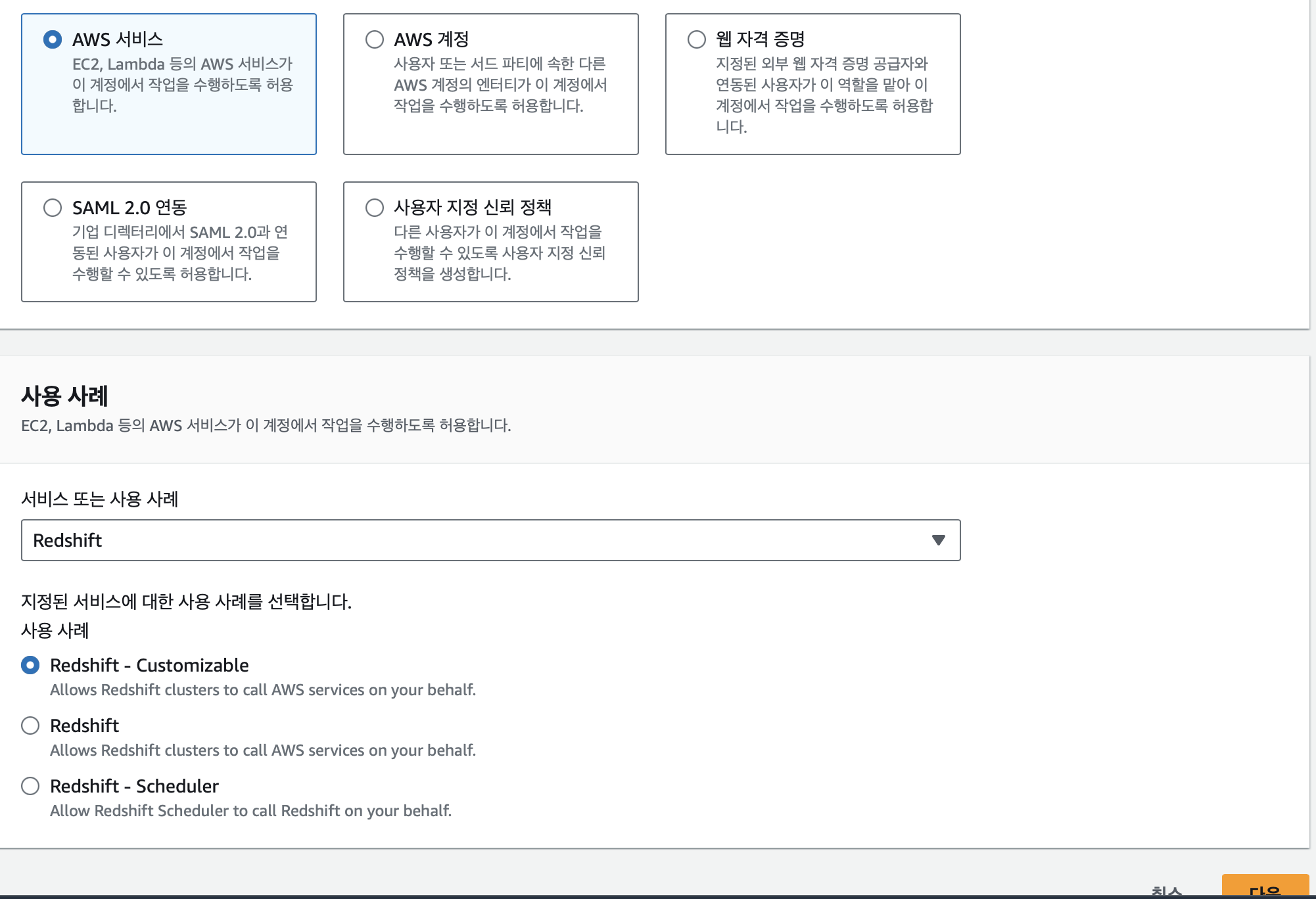
우리는 Redshift의 S3 접근을 위한 역할을 만들어주는 것이기 때문에 AWS 서비스 선택, 서비스 또는 사용 사례에서 Redshift 선택, Redshift- Customizable 선택
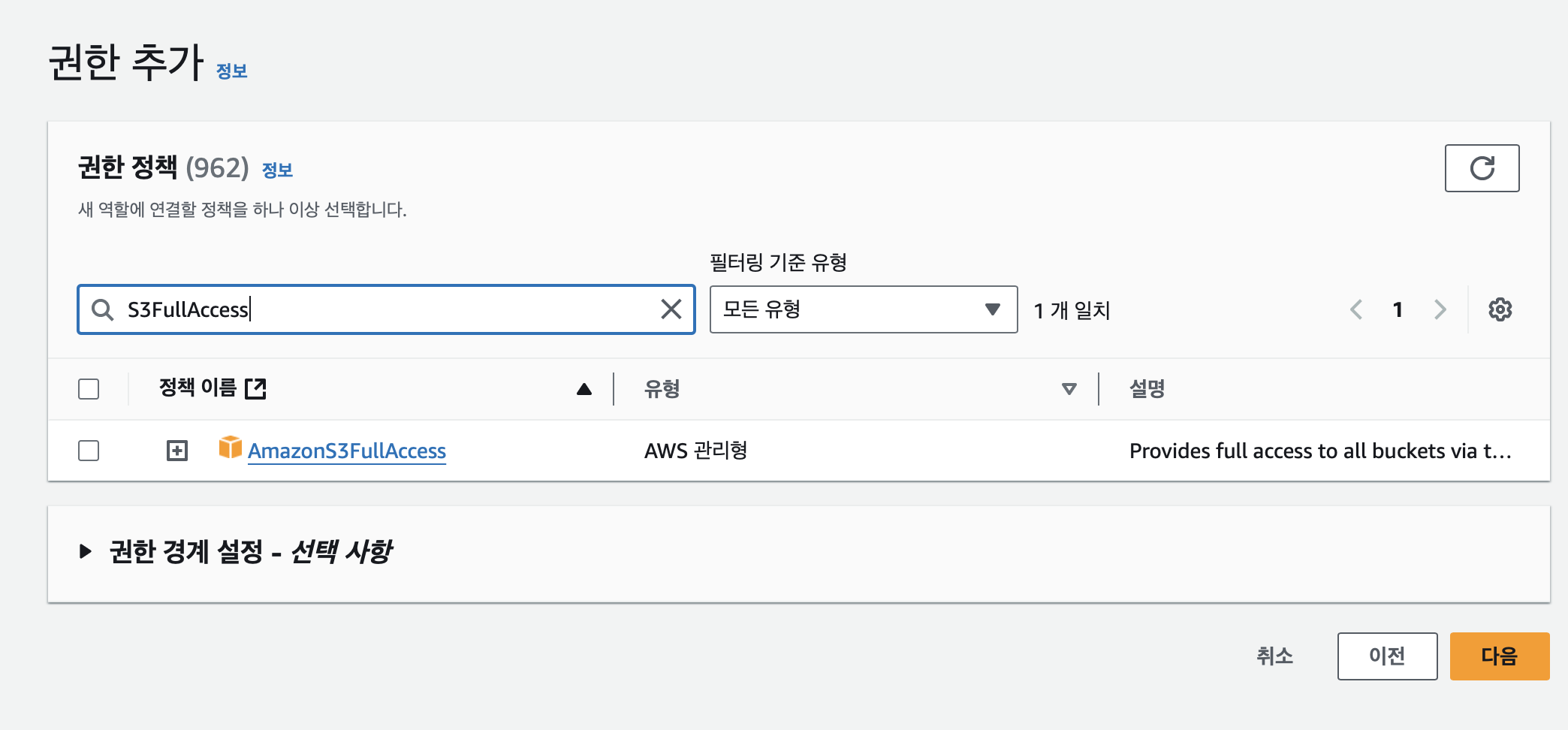
권한 추가에서 S3FullAccess검색하여 AmazonS3FullAccess 정책 선택 후 다음 클릭
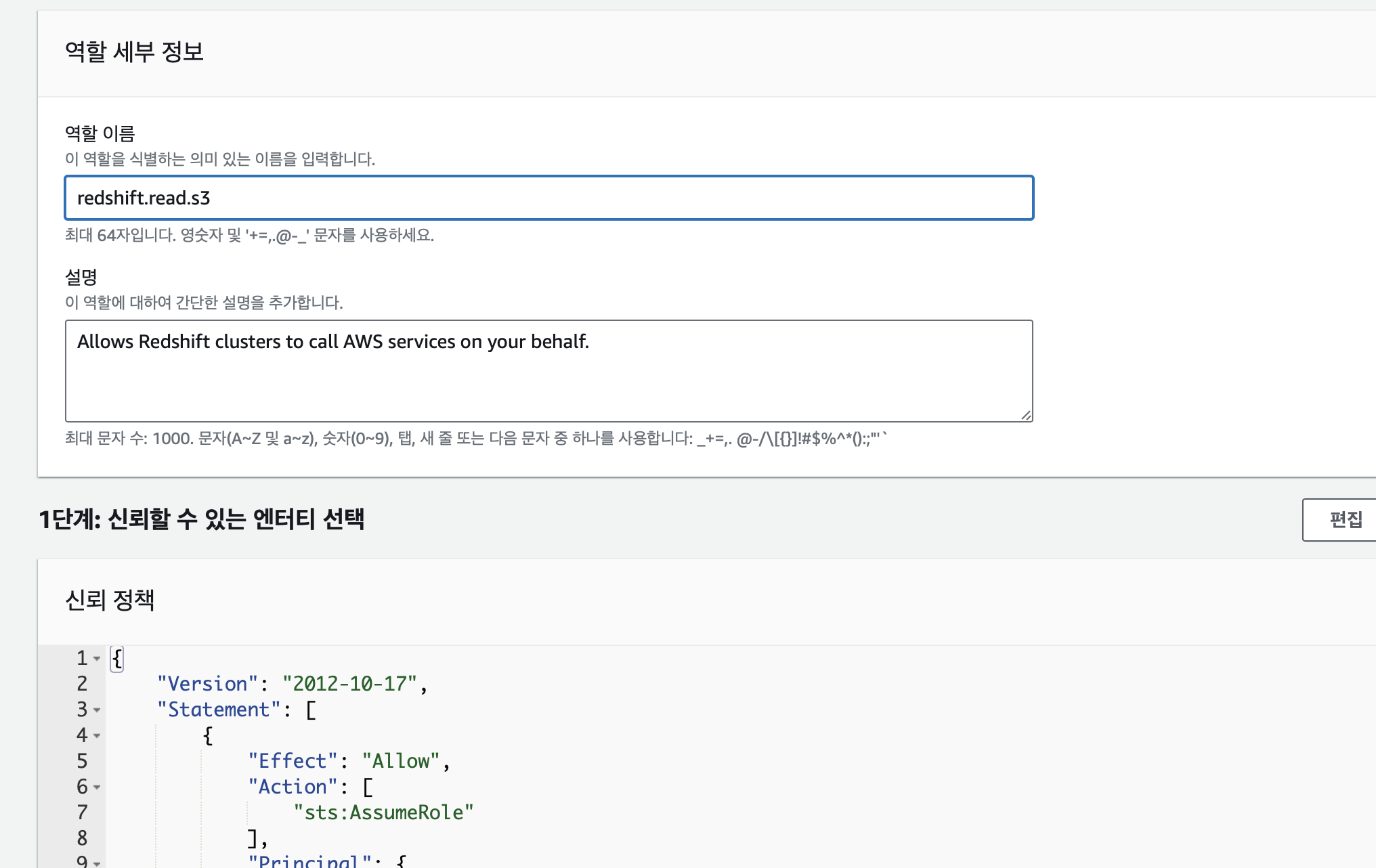
역할 이름 작성 후 역할 생성 클릭. 생성된 역할 클릭하여 보면 arn을 확인할 수 있다. 이 arn으로 redshift에서 s3접근 시 권한을 부여받을 수 있다.
Redshift에 IAM Role 부여
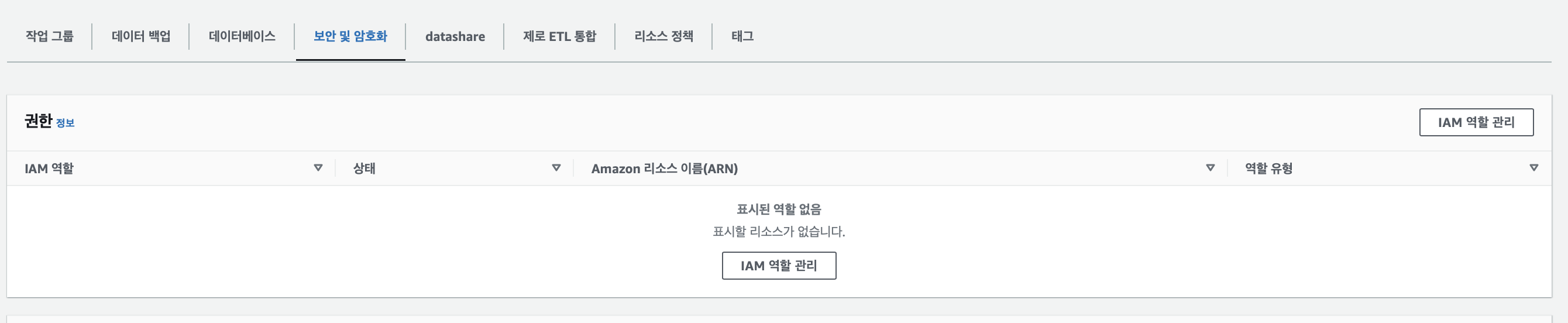
Redshift 네임스페이스 페이지에 접속하여 보안 및 암호화에서 IAM 역할 관리 클릭
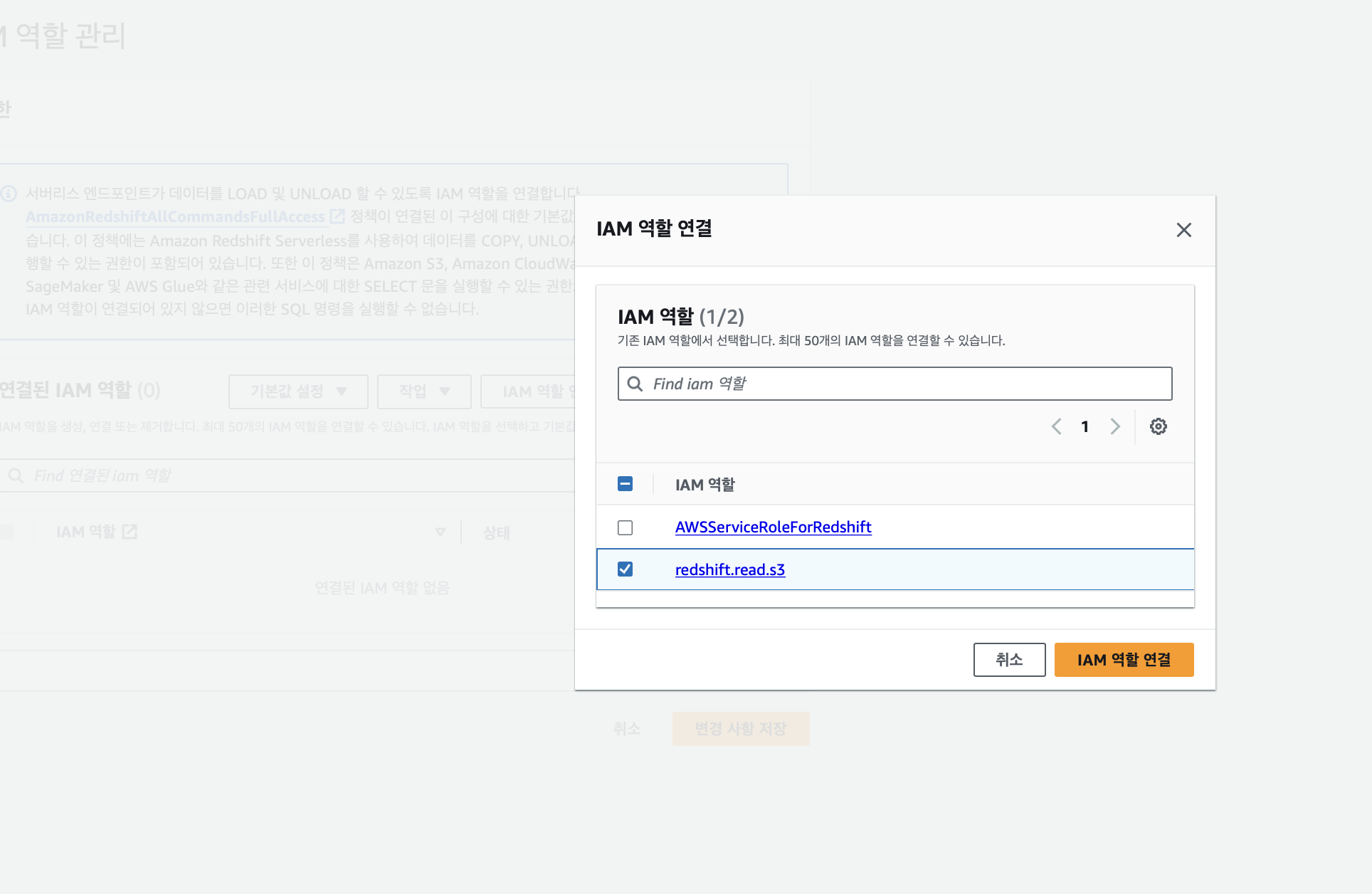
만들어 놓은 redshift.read.s3 IAM 역할 선택 후 연결, 변경 사항 저장 클릭
이렇게 하면 redshift가 s3에 접근할 수 있는 권한 부여가 완료된다.
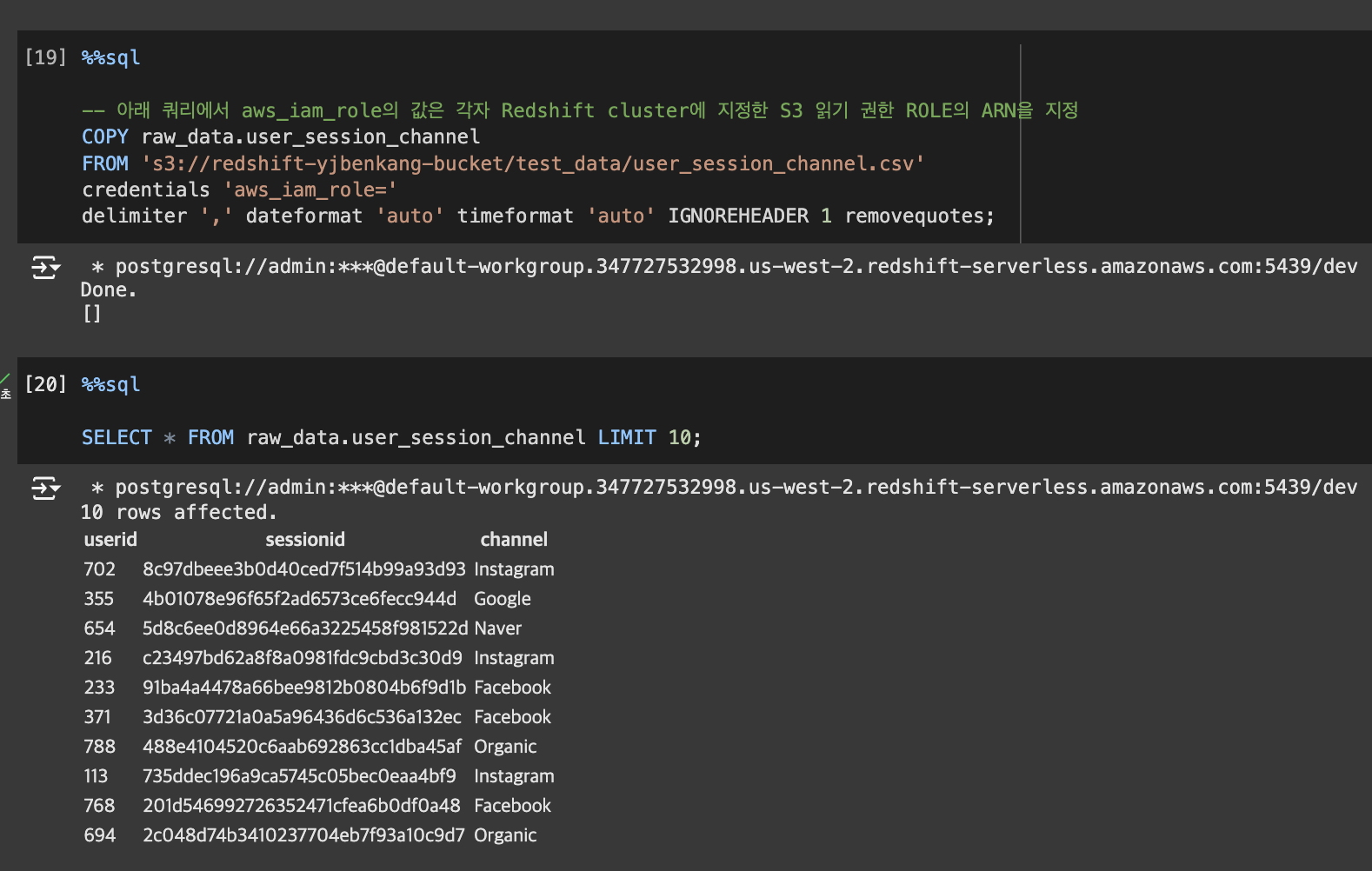
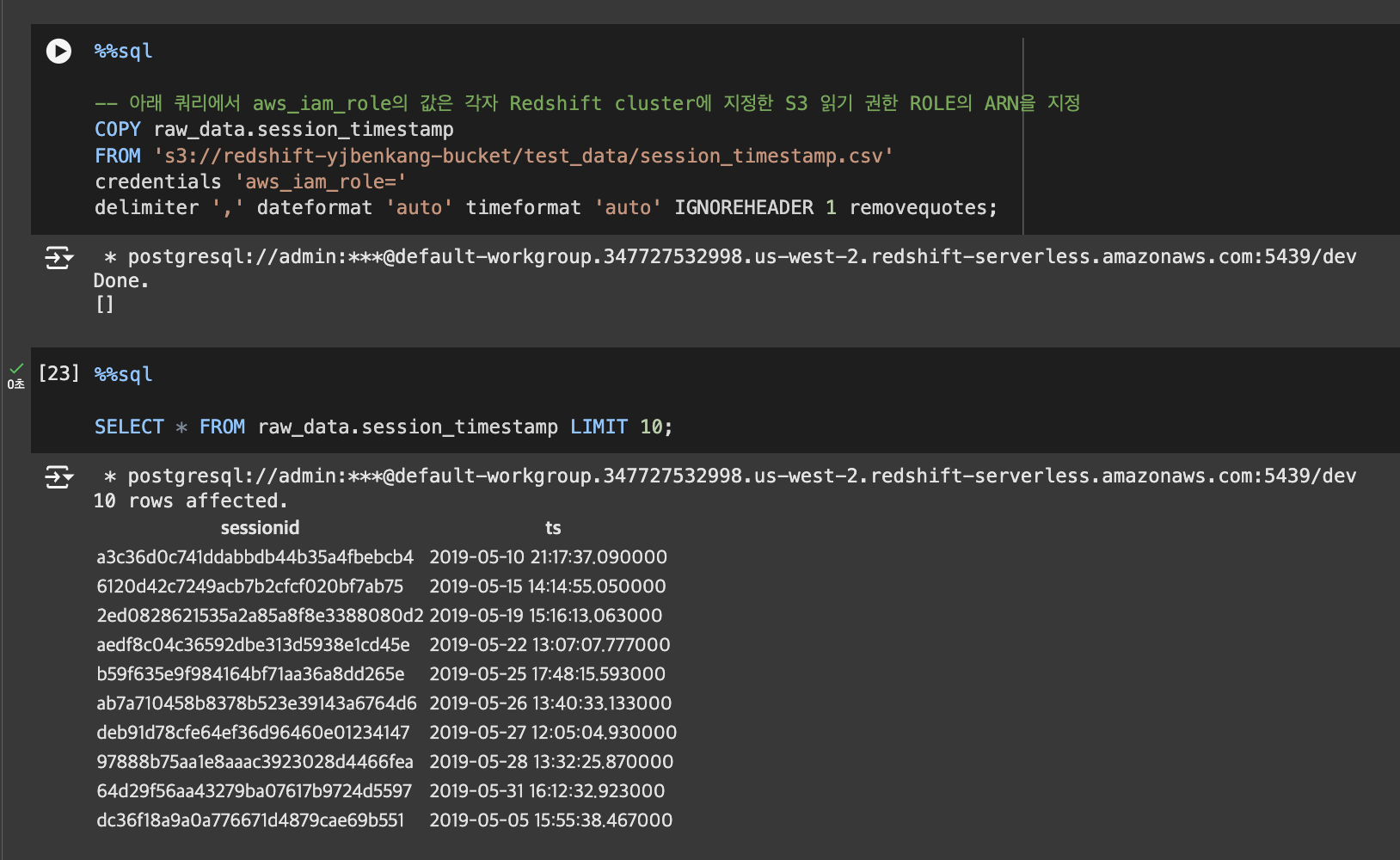
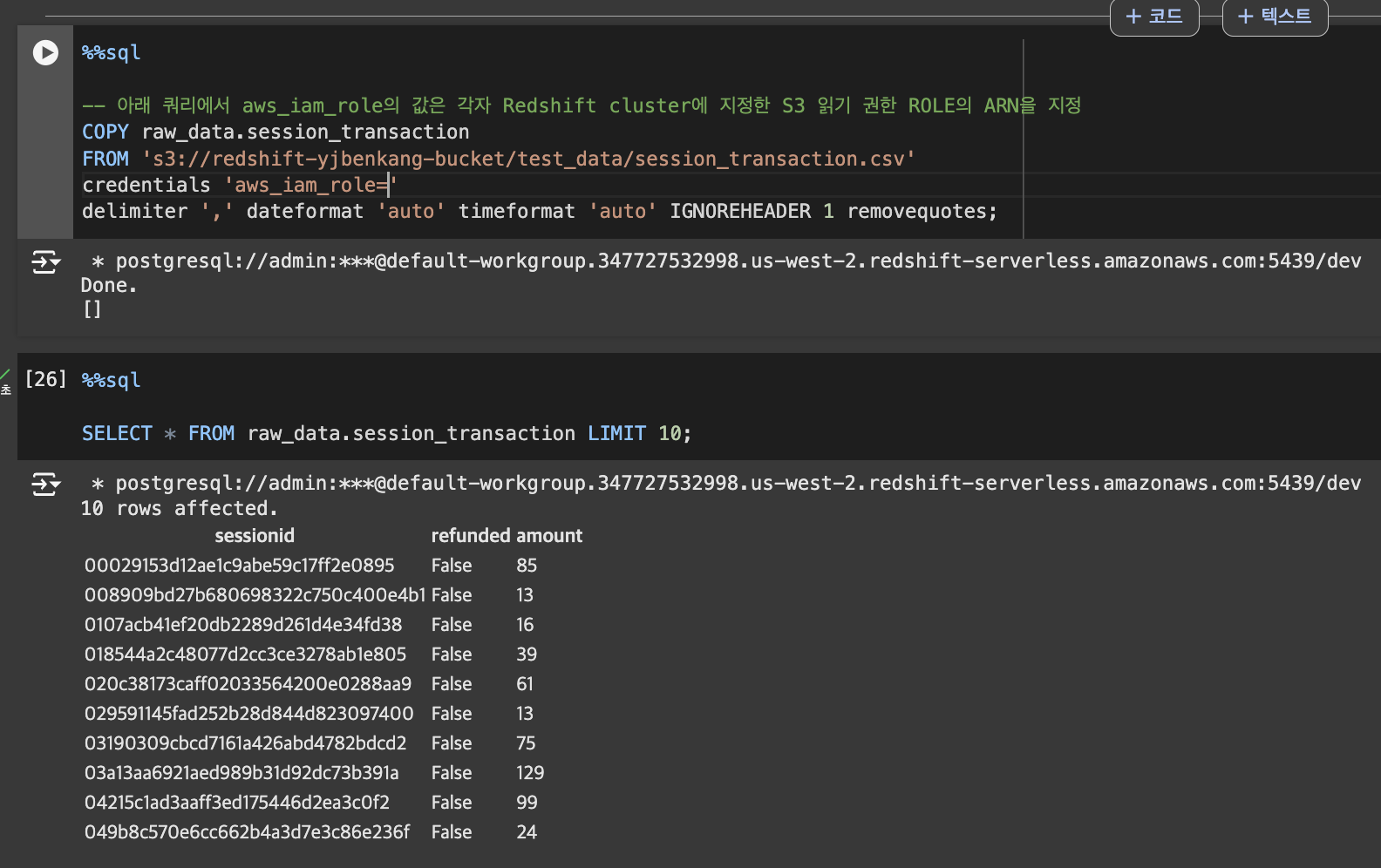
COPY 명령을 사용해 앞서 CSV 파일들을 테이블로 복사
- 앞서 생성한 테이블로 앞서 S3로 로딩한 파일을 벌크 업데이트 수행
- 이를 위해 COPY SQL 커맨드를 사용
- CSV 파일이기에 delimiter로는 콤마(,)를 지정한다.
- CSV 파일에서 문자열이 따옴표로 둘러싸인 경우 제거하기 위해 removequotes 지정
- CSV 파일의 첫번째 라인(헤더)을 무시하기 위해 "IGNOREHEADER 1"을 지정
- credentials에 앞서 Redshift에 지정한 Role을 사용. 이 때 해당 Role의 ARN을 읽어와야함. 명령어를 사용하는 사람 또한 권한이 있음을 나타내줌.
COPY 명령을 사용해 앞서 CSV 파일들을 테이블로 복사 시 에러 대처법
- 만일 COPY 명령 실행 중에 에러가 나면 stl_load_errors 테이블의 내용을 보고 확인한다.
SELECT * FROM stl_load_errors ORDER BY starttime DESC;analytics 테스트 테이블 만들기
- analytics 스키마에 새로운 테이블 만들기
- raw_data에 있는 테이블을 조인해서 새로 만들기 (ELT)
- 간단하게는 CTAS로 가능

keep growing