Redshift Spectrum으로 S3 외부 테이블 핸들링
S3에 굉장히 큰 데이터가 있는데 이를 Redshift로 로딩하기가 버겁다면 이를 외부 테이블로 설정해서 Redshift에서 조작할 수 있다.
- 비용
- 퀄리티가 좋지 않아 정제가 필요한 경우
Fact 테이블(S3)과 Dimension 테이블(Redshift)
- Fact 테이블 : 분석의 초점이 되는 양적 정보를 포함하는 중앙 테이블
- 일반적으로 매출 수익, 판매량 또는 이익과 같은 사실 또는 측정 항목을 포함하며 비즈니스 결정에 사용
- Fact 테이블은 일반적으로 외래키를 통해 여러 Dimension 테이블과 연결됨
- 보통 Fact 테이블의 크기가 훨씬 더 큼
- Dimension 테이블 : Fact 테이블에 대한 상세 정보를 제공하는 테이블
- 고객, 제품과 같은 테이블로 Fact 테이블에 대한 상세 정보 제공
- Fact 테이블의 데이터에 맥락을 제공하여 사용자가 다양한 방식으로 테이터를 조각내고 분석 가능하게 해줌
- Dimension 테이블은 일반적으로 primary key를 가지며, fact 테이블의 foreign key에서 참조
- 보통 Dimension 테이블의 크기는 훨씬 더 작음
ex)
- Fact 테이블:
- user_session_channel
- Dimension 테이블 : 사용자나 채널에 대한 정보로 상대적으로 크기가 작음
user_session_channel 테이블에 사용된 사용자나 채널에 대한 정보- user(성별, 사는 곳, 수입정도...)
- channel
- Fact 테이블:
- Order 테이블, 사용자들의 상품 주문에 대한 정보가 들어간 테이블
- Dimension 테이블:
- Product 테이블, Order 테이블에 사용된 상품에 대한 정보
- User 테이블, Order 테이블에서 상품 주문을 한 사용자에 대한 정보
이걸 합쳐 더 의미있는 분석이 가능하다.
Redshift Spectrum Use Case
-
S3에 대용량 Fact 테이블이 파일(들)로 존재
-
Redshift에 소규모 Dimension 테이블이 존재
-
Fact 테이블을 Redshift로 적재하지 않고 위의 두 테이블을 조인하고 싶다면?
-
이 때 사용할 수 있는 것이 Redshift Spectrum
- 이는 별도로 설정하거나 launch하는 것이 아닌 Redshift의 확장 기능으로 사용하고 그만큼 비용 부담
외부 테이블(External Table)이란?
- 데이터베이스 엔진이 외부에 저장된 데이터를 마치 내부 테이블처럼 읽기전용으로 사용하는 방법
- 외부 테이블은 외부(보통 S3와 같은 클라우드 스토리지)에 저장된 대량의 데이터를 데이터베이스 내부로 복사하고 쓰는 것이 아니라 임시 목적으로 사용하는 방식
- SQL 명령어로 데이터베이스에 외부 테이블 생성 가능(CREATE EXTERNAL TABLE)
- 이 경우 데이터를 새로 만들거나 하는 것이 아니라 참조만 하게 됨
- 외부 테이블은 CSV, JSON, XML과 같은 파일 형식 뿐만 아니라 관계형 디비와 같은 ODBC 또는 JDBC 드라이버를 통해 액세스하는 원격 데이터베이스와 같은 다양한 데이터 소스에 대해 사용 가능
- 외부 테이블을 사용하여 데이터 처리 후 결과를 데이터베이스에 적재 가능
- 외부 테이블은 보안 및 굉장히 클 경우 성능 문제에 대해 신중한 고려가 필요, 테스트를 해보는게 좋음.
- 이는 Hive 등에서 처음 시작한 개념으로 이제는 대부분의 빅데이터 시스템에서 사용됨
Redshift Spectrum 사용 방식
- S3에 있는 파일들을 마치 테이블처러 SQL로 처리 가능
- S3 파일들을 외부 테이블들(external table)로 처리하면서 Redshift 테이블과 조인 가능
- S3 외부 테이블들은 보통 Fact 테이블들이 되고 Redshift 테이블들은 Dimension 테이블
- 이를 사용하려면 Redshift 클러스터가 필요
- S3와 Redshift 클러스터는 같은 region에 있어야함
- S3 Fact 데이터를 외부 테이블(External Table)로 정의해야함
Redshift Spectrum 실습을 위한 외부 테이블 용 스키마 설정
- 먼저 앞서 만든 redshift.read.s3 ROLE에 AWSGlueConsoleFullAccess 권한 지정이 필요
- 다음으로 아래 SQL을 실행하여 외부 테이블용 스키마 생성
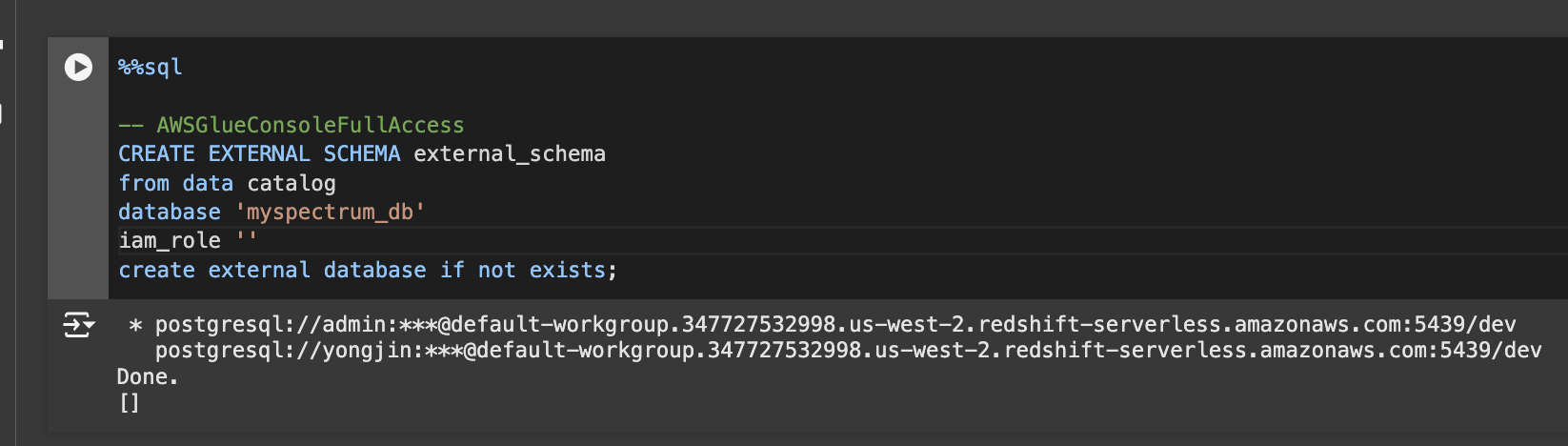
CREATE EXTERNAL SCHEMA external_schema
from data catalog
database 'myspectrum_db'
iam_role 'arn:aws:iam::1234123412341234:role/redshift.read.s3'
create external database if not exists;AWS Glue란 무엇인가?
- AWS ETL 서비스로 ,Airflow 비슷하지만 실제 동작은 AWS기능과 tight하게 커플되어있으므로 AWS 바깥으로 나가면 사실상 사용할 수 없음. 하지만 AWS에 최적화된 ETL을 사용하기에 좋음
- AWS Glue는 AWS의 Serverless ETL 서비스로 아래와 같은 기능 제공
- 데이터 카탈로그: AWS Glue와 연결된 다양한 데이터 소스(S3), 데이터 데스티네이션(데이터 웨어하우스)에 대한 메타데이터(데이터의 데이터)를 가지는 곳
a. AWS Glue Data Catalog는 데이터 소스 및 대상의 메타데이터를 대상으로 검색 기능을 제공. 이는 주로 S3나 다른 AWS 서비스 상의 데이터 소스를 대상으로 함 (Redshift Spectrum의 경우에는 외부 테이블들)
- 데이터 카탈로그: AWS Glue와 연결된 다양한 데이터 소스(S3), 데이터 데스티네이션(데이터 웨어하우스)에 대한 메타데이터(데이터의 데이터)를 가지는 곳
- ETL 작업 생성: AWS Glue Studio
a. 간단한 드래그 앤 드롭 인터페이스를 통해 ETL 작업 생성 가능
b. 사용자는 데이터 소스 및 대상을 선택하고 데이터 변환 단계를 정의하는 스크립트 생성 - 작업 모니터링 및 로그:
a. AWS Glue 콘솔을 통해 사용자는 ETL 작업의 실행 상태 및 로그를 모니터링 가능 - 서버리스 실행:
a. AWS Glue는 서버리스 아키텍처를 사용하므로 사용자는 작업을 실행하는 데 필요한 인프라를 관리할 필요가 없음 (Auto Scaling)
Redshift Spectrum 실습을 위한 외부 Fact 테이블 정의
- S3에 usc라는 폴더를 각자 S3 버킷 밑에 만들고
- 그 폴더로 user_session_channel.csv 파일을 복사
- 다음으로 아래 SQL을 실행 (이런 형태의 명령은 Hive/Presto/SparkSQL에서 사용됨)
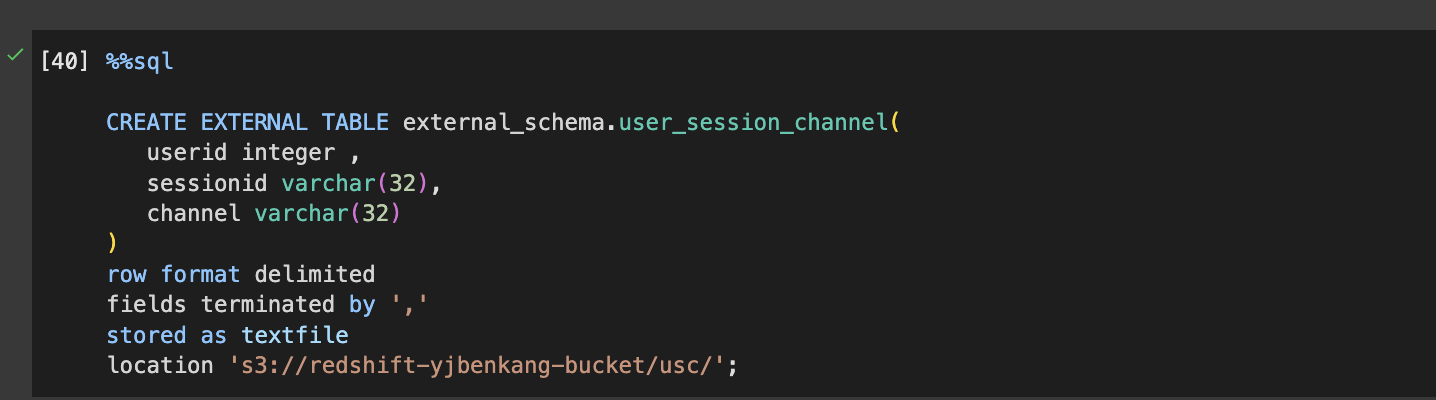
CREATE EXTERNAL TABLE external_schema.user_session_channel (
userid integer,
sessionid varchar(32),
channel varchar(32)
)
row format delimited
fields terminated by ','
stored as textfile
location 's3://redshift-yjbenkang-bucket/usc/';Redshift Spectrum 실습을 위한 내부 Dimension 테이블
-
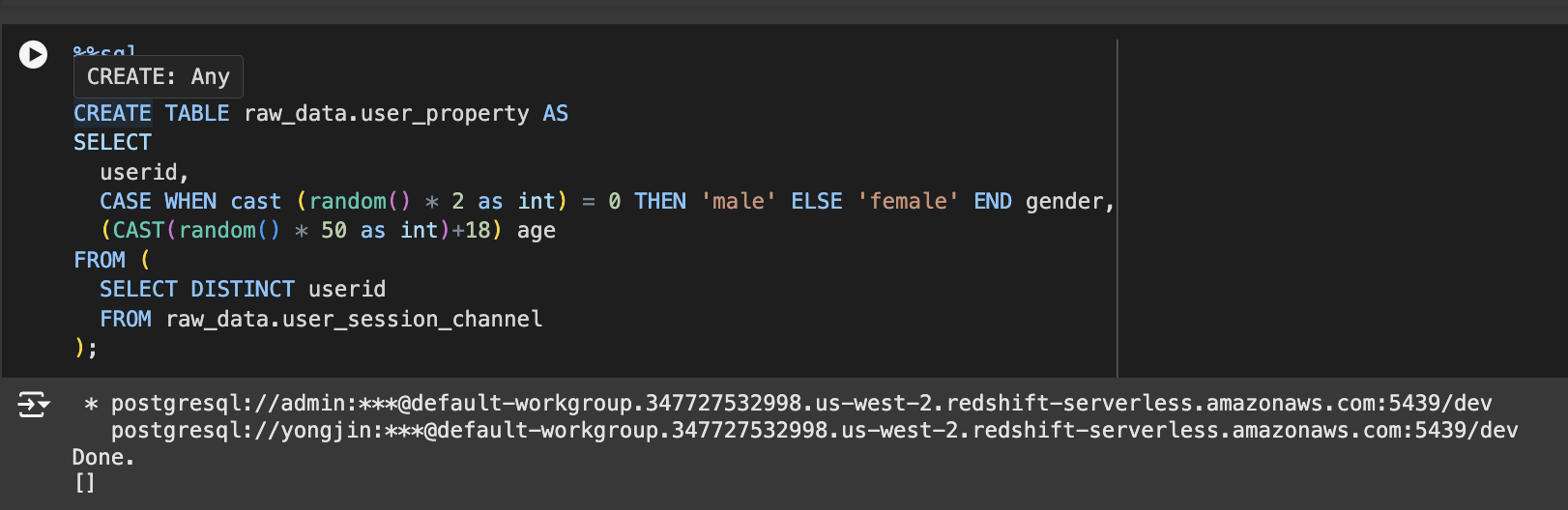
테스트를 위해 user 테이블 하나를 raw_data 스키마 밑에 생성
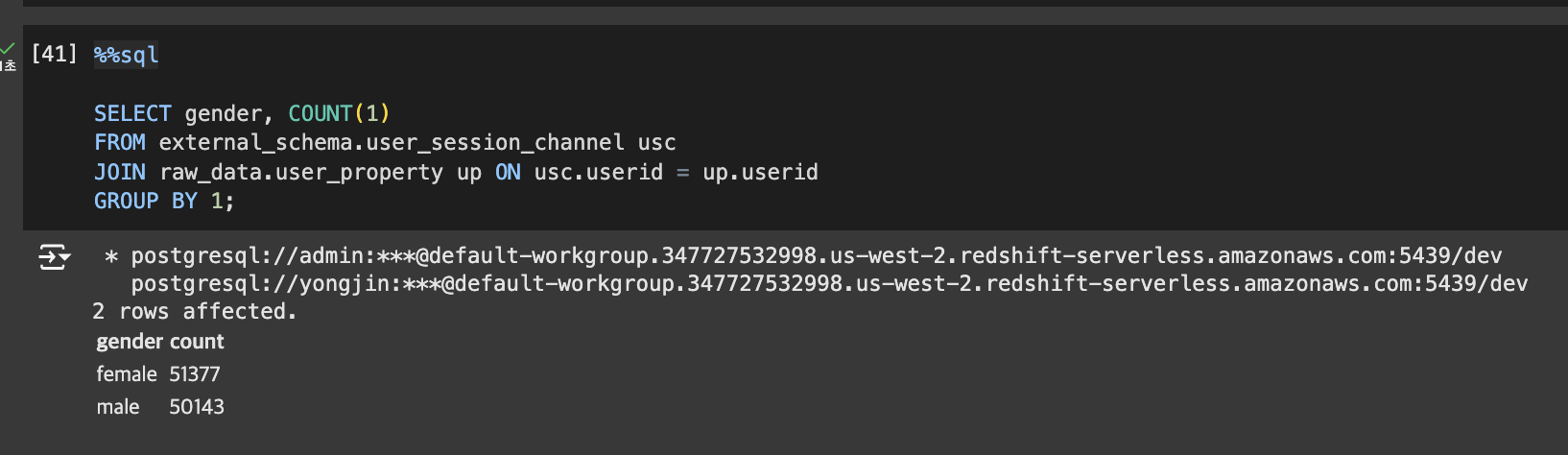
CREATE TABLE raw_data.user_property AS SELECT userid, CASE WHEN cast (random() * 2 as int) = 0 THEN 'male' ELSE 'female' END gender, (CAST(random() * 50 as int)+18) age FROM ( SELECT DISTINCT userid FROM raw_data.user_session_channel );Redshift Spectrum Fact + Dimension 테이블 조인
SELECT gender, COUNT(1) FROM external_schema.user_session_channel usc JOIN raw_data.user_property up ON usc.userid = up.userid GROUP BY 1;실습
외부 테이블용 스키마 생성
내부 Dimension 테이블 생성
외부 Fact 테이블 생성
Redshift의 S3 접근용 IAM Role에 권한 추가 (AWSGlueConsoleFullAccess)
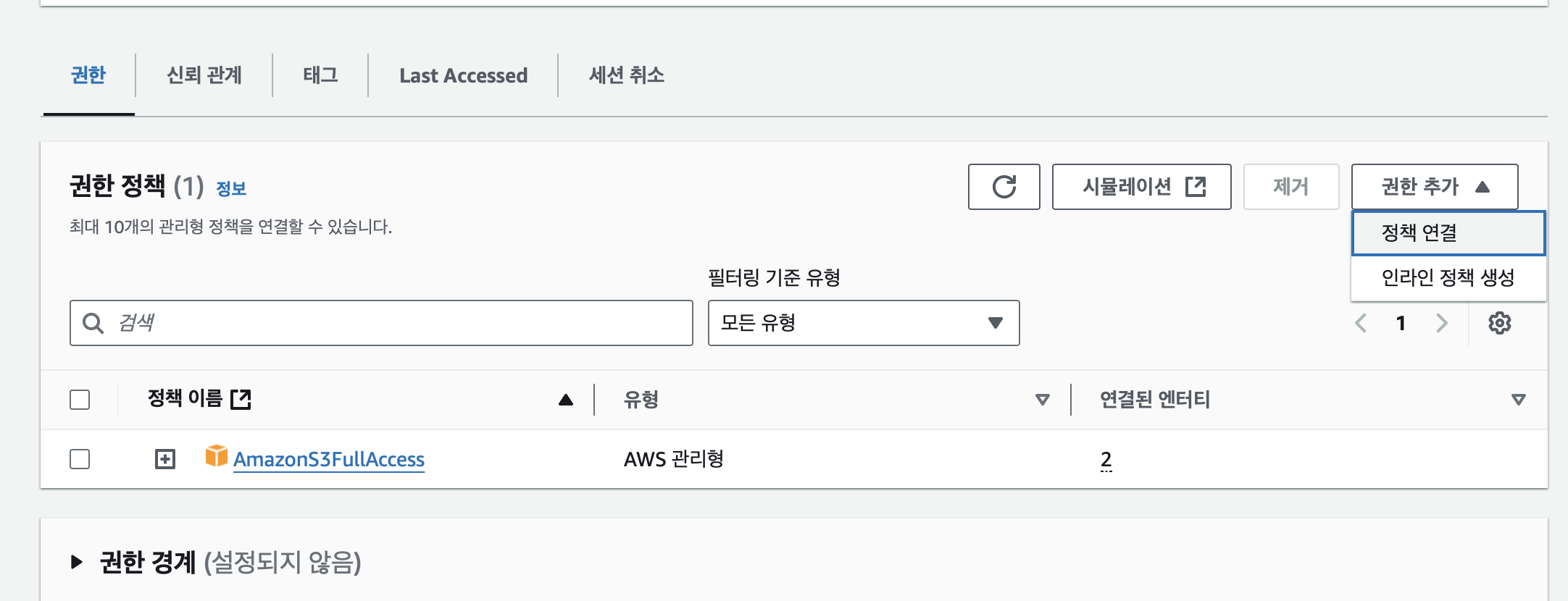
IAM - 역할에 들어가 기존에 만들어 놓은 redshift.read.s3 역할을 클릭 후 권한에서 권한추가 드롭다운 누른 후 정책 연결 클릭
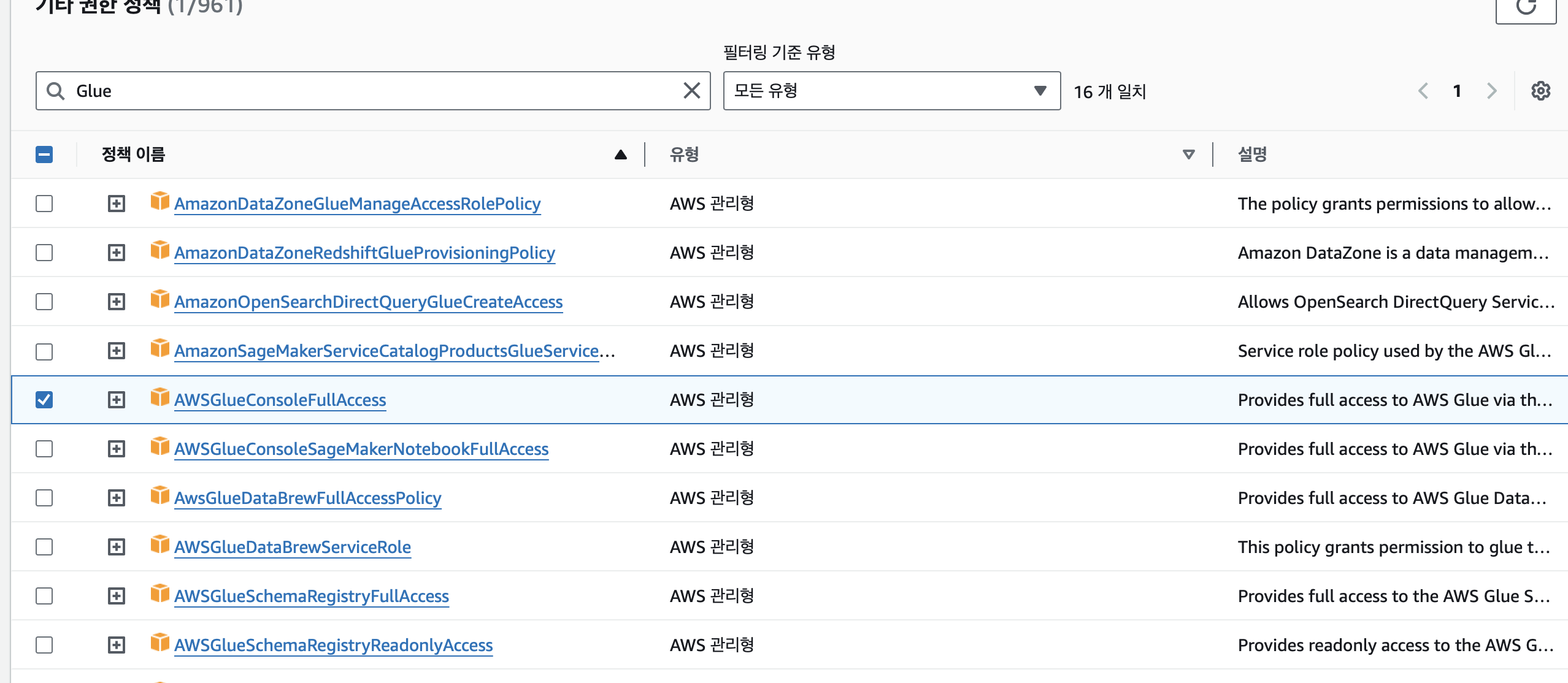
glue 검색하여 AWSGlueConsoleFullAccess 정책 선택 후 저장
S3 버킷에 새 폴더 만들고 user_session_channel.csv 파일 업로드
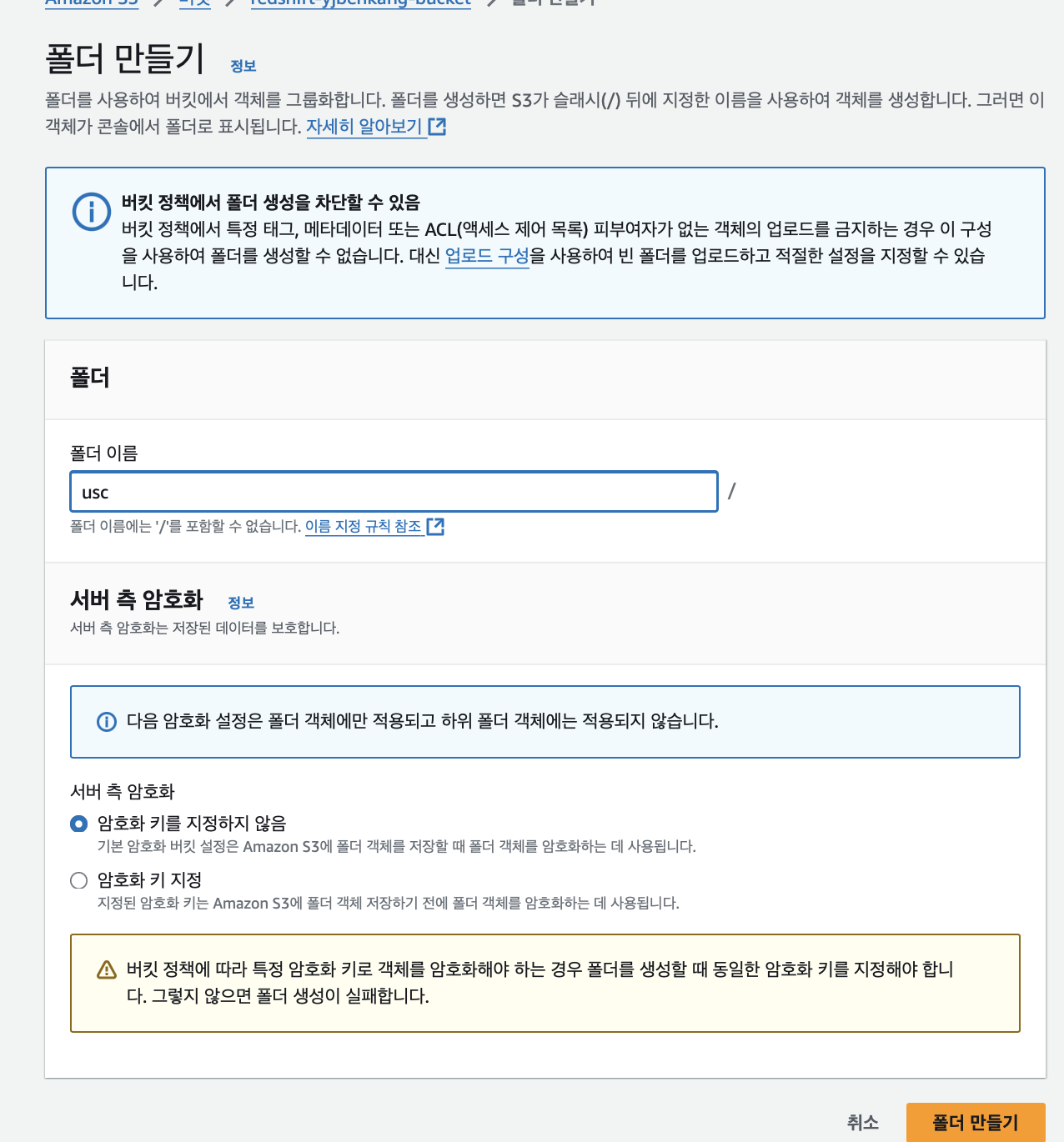
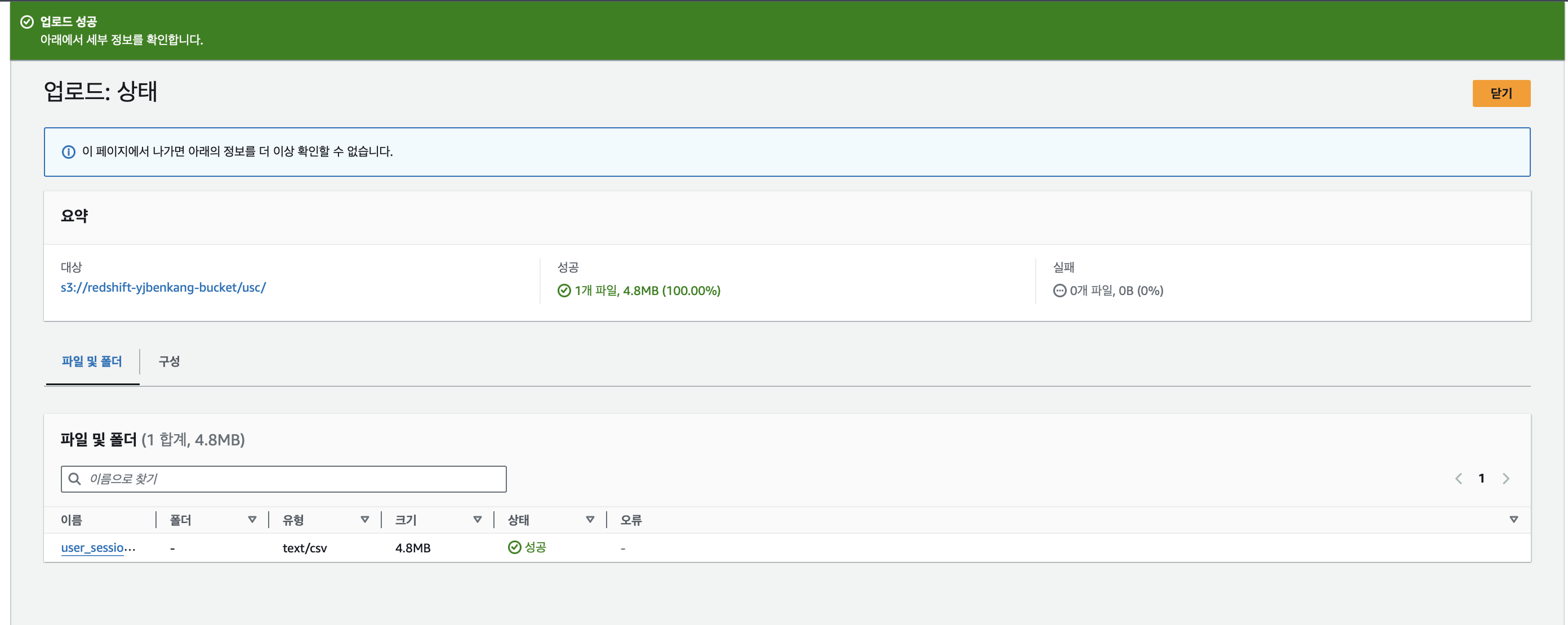
폴더 생성 후 csv파일 업로드, 위 파일을 바탕으로 외부 테이블 생성
내부 테이블과 외부 테이블 조인

keep growing