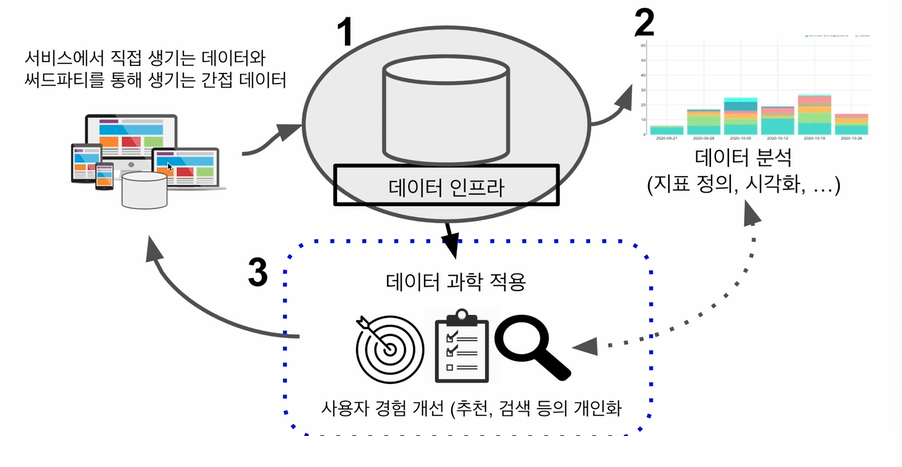
모든 데이터를 한곳으로 모으는 것이 데이터팀의 시작
그런 데이터가 모이는 데이터 분석용 전용 데이터베이스를 데이터웨어하우스라 함
데이터 웨어하우스에 데이터를 적재하는 프로세스를 데이터파이프라인, ETL이라고 하고, 이걸 Airflow에선 Dag라고 함
외부의 데이터를 데이터 시스템안 데이터웨어하우스로 가져오는 코드를 작성하고 관리하는 방법에 대해 알아볼 것
그렇게 사용되는 가장 인기있는 framework이 airflow.
airflow 이용해서 etl 데이터 파이프라인을 작성하고 관리하는 것
데이터 웨어하우스, etl 데이터 파이프라인을 총칭해서 데이터 인프라, 데이터 플랫폼이라고 함.
데이터 조직이 발전하면 여기에 빅데이터 처리 프레임웤인 스파크,하둡이 같은게 들어가고
리얼타임 처리하는게 필요하면 Kafka, SparkStream,
머신러닝이 발전하면 NoSql, 카산드라 등등해서 굉장히 많은 다른 기술들이 데이터 인프라의 일부가 됨.
가장 기본이 되는 것 데이터 웨어하우스와 etl 프로세스이다.
기반이 만들어지면 데이터분석가가 들어와서 이 정보를 활용해서 회사의 중요한 지표를 데이터기반으로 계산해서 대시보드 툴 위에서 시각화. 그 시각화에 사용되는게 태블로 루커 수퍼셋 등
데이터 기반으로 회사가 어느방향으로 움직일지 정의가 되면 데이터과학자가 들어와서 데이터 엔지니어가 모아놓은 데이터 기반으로 알고리즘 만들어서 사용자에게 좀더 개인화된 형태로 추천을 제공하거나 검색기능을 제공하고 또 운영이 중요하면 자동화를 통해서 운영비용을 줄이는 형태로 데이터 팀이 기여. 데이터엔지니어가 만들어놓은 인프라를 기반으로 두가지 형태로 데이터팀이 회사의 발전에 기여
데이터팀이 만들어놓은 인프라를 기반으로
1. 데이터 기반 과학적 의사결정
2. 데이터를 바탕으로 한 프로덕트 개선(사용자 경험 향상, 서비스 운영비용 절감)
데이터 소스 -> 다수의 ETL (by Airflow) -> 데이터 웨어하우스 -> 대시보드
데이터 소스: MySQL(프로덕션 DB), Stripe(신용카드 데이터), Mailchimp(이메일), Zendesk (서포트 티켓), Amplitude (유저 데이터), RingCentral(콜 데이터), Salesforce(세일즈 데이터)
더 정제되고 목적이 분명한 데이터를 만드는게 요약 테이블 만들기인데 이건 ELT, 보통 데이터 분석가가 수행.
데이터 파이프라인이란?
ETL
- ETL : Extract, Transform and Load
- Data Pipeline, ETL, Data Workflow, DAG
- ETL (Extract, Transform, and Load)
- Called DAG (Directed Acyclic Graph) in Airflow
- 다수의 태스크가 존재하고 양방향이 아닌 한방향으로 진행됨
ETL vs ELT
- ETL : 데이터를 데이터 웨어하우스 외부에서 내부로 가져오는 프로세스
- 보통 데이터 엔지니어들이 수행함
- 누군가가의 데이터 요청에 의해서 수행됨
ex) 페이스북 광고 효율성 분석을 위한
- ELT: 데이터 웨어하우스 내부 데이터를 조작해서 (보통은 좀더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- 보통 데이터 분석가들이 많이 수행
- 이 경우 데이터 레이크(데이터웨어하우스보다 더 scalable한) 위에서 이런 작업들이 벌어지기도 함
- CTAS를 사용하는 것이 일반적, but 입력과 출력 check와 테스트가 많이 필요하고 여러 고려사항이 많음
- 이런 프로세스 전용 기술들이 있으며 dbt(오픈소스)가 가장 유명 : Analytics Engineering
- dbt: Data Build Tool
Data Lake vs Data Warehouse
- 데이터 레이크 (Data Lake)
- 구조화 데이터 + 비구조화 데이터
- 원본 있는 그대로 복제해놓는 경우가 많음
- 보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 가까움
- 보통은 데이터 웨어하우스보다 몇배는 더 큰 스토리지
- 데이터 웨어하우스 (Data Warehouse)
- 상대적으로 비싼 스토리지를 사용하므로 온갖 종류 데이터 저장하기엔 경제적 부담
- 기본적으로 관계형 데이터베이스이므로 비구조화 데이터 저장 어려움
- 보존 기한이 있는 구조화된 데이터를 저장하고 처리하는 스토리지
- 보통 BI툴들 (룩커, 태블로, 수퍼셋, ...)은 데이터 웨어하우스를 백엔드로 사용함
Data Lake & ELT
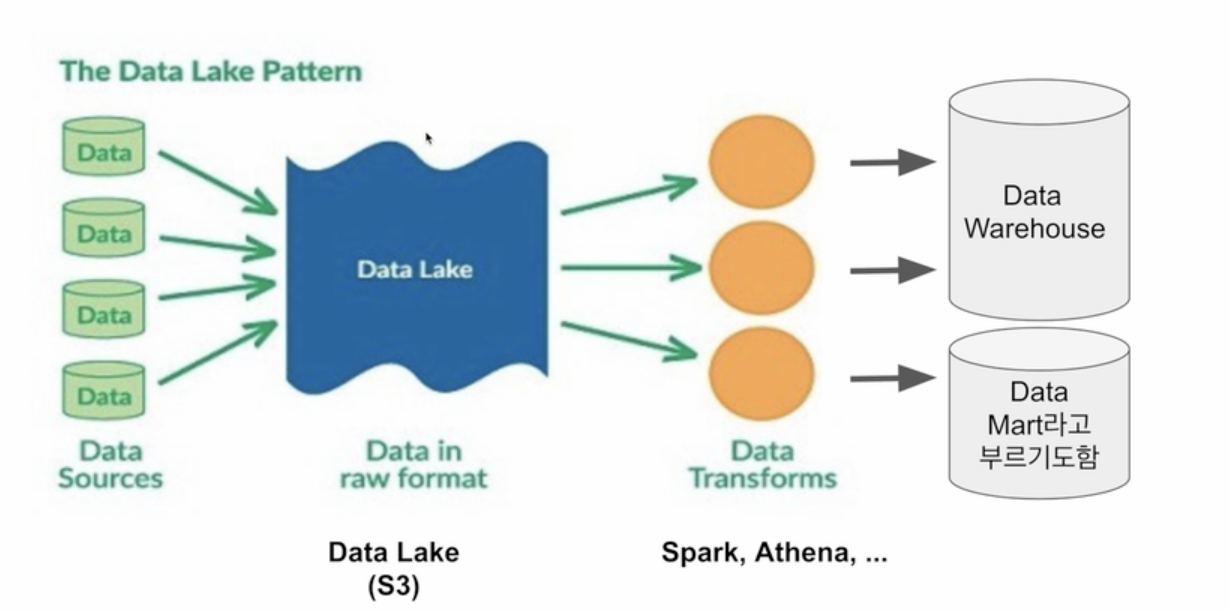
데이터 시스템이 성숙해진 회사들이 갖는 데이터시스템의 다이어그램. 많은 데이터 소스가 있을거고 있는 그대로 데이터웨어하우스에 저장하기엔 무리. 그런 데이터를 일단 데이터레이크에 저장하고 이걸 또 프로세싱해서 의미있는 것만 데이터웨어하우스에 로딩. 데이터레이크는 aws s3와 같은 스토리지. 이건 그냥 스토리지지 프로세싱하는 프로세싱 프레임워크가 연계되어있는게 아님. 보통 spark나 athena를 사용해서 데이터 레이크에 있는 데이터를 프로세싱해서 정제해서 데이터웨어하우스에 저장.
ELT는 뭐냐 ? 데이터레이크에서 정제해서 데이터 웨어하우스에 넣는 것도 ELT로 볼 수 있다.
Data Pipeline의 정의
- 데이터를 소스로부터 목적지로 복사하는 작업
- 이 작업은 보통 코딩 (파이썬 혹은 스칼라) 혹은 SQL를 통해 이루어짐
- SQL은 보통 ELT. 이미 데이터시스템안에 들어와있는 데이터를 정제하는거기 때문에 데이터 소스가 데이터웨어하우스 혹은 데이터 레이크 목적지는 데이터 웨어하우스 이런 케이스
- 대부분의 경우 목적지는 데이터 웨어하우스가 됨. 어떤 경우엔 목적지가 외부 시스템일 수도 있음.
- 데이터 소스의 예:
- Click stream, call data, ads performance data, transactions, sensor data, metadata, ...
- More concrete examples: production databases, log files, API, stream data (Kafka topic)
- 데이터 목적지의 예:
- 데이터 웨어하우스, 캐시 시스템(Redis, Memcache), 프로덕션 데이터베이스, NoSQL, S3, ...
데이터 파이프라인의 종류
Raw Data ETL Jobs
1. 외부(ex.페이스북 광고정보)와 내부 데이터 소스에서 데이터를 읽어다가 (많은 경우 API를 통하게 됨)
2. 적당한 데이터 포맷 변환 후 (데이터 크기가 커지면 일반 파이썬 코드로는 불가. Spark등이 필요해짐)
3. 데이터 웨어하우스 로드
이 작업은 보통 데이터 엔지니어가 함
Summary/Report Jobs
1. DW(혹은 DL)로부터 데이터를 읽어 다시 DW에 쓰는 ETL
2. Raw Data를 읽어서 일종의 리포트 형태나 써머리 형태의 테이블을 다시 만드는 용도
3. 특수한 형태로는 AB 테스트 결과를 분석하는 데이터 파이프라인도 존재
요약 테이블의 경우 SQL (CTAS를 통해)만으로 만들고 이는 데이터 분석가가 하는 것이 맞음. 데이터 엔지니어 관점에서는 어떻게 데이터 분석가들이 편하게 할 수 있는 환경을 만들어 주느냐가 관건
-> Anayltics Engineer (DBT)
Production Data Jobs
- DW로부터 데이터를 읽어 다른 Storage(많은 경우 프로덕션 환경)로 쓰는 ETL
a. Summary 정보가 프로덕션 환경에서 성능 이유로 필요한 경우
b. 혹은 머신러닝 모델에서 필요한 feature들을 미리 계선하두는 경우 - 이 경우 흔한 타켓 스토리지:
a. Cassandra/HBase/DynamoDB와 같은 NoSQL
b. MySQL과 같은 관계형 데이터베이스 (OLTP)
c. Redis/Memcache와 같은 캐시
d. ElasticSearch와 같은 검색엔진
데이터 파이프라인을 만들 때 고려할 점
데이터 파이프라인 작성시 best practices들과 기억해두면 좋은 팁
이상과 현실간의 괴리
- 이상 혹은 환상
- 내가 만든 데이터 파이프라인은 문제 없이 동작할 것이다
- 내가 만든 데이터 파이프라인을 관리하는 것은 어렵지 않을 것이다
- 현실 혹은 실상
- 데이터 파이프라인은 많은 이유로 실패함
- 버그
- 데이터 소스상의 이슈
- 데이터 파이프라인들간의 의존도에 이해도 부족
- 데이터 파이프라인의 수가 늘어나면 유지보수 비용이 기하급수적으로 늘어남
- 데이터 소스간의 의존도가 생기면서 이는 더 복잡해짐. 만일 마케팅 채널 정보가 업데이트가 안된다면 마케팅 관련 다른 모든 정보들이 갱신되지 않음
- More tables needs to be managed (source of truth, search cost, ...)
- 데이터 파이프라인은 많은 이유로 실패함
Best Practices (1)
- 가능하면 데이터가 작을 경우 매번 통째로 복사해서 테이블을 만들기 (Full Refresh)
- 과거 데이터가 잘못되어있어도 매번 다시 다 읽어오므로 별다른 문제가 없고 문제가 생겨도 해결방법이 간단해짐. 불필요하게 최적화하지말고 full refresh로 !
- Incremental update만이 가능하다면, 대상 데이터소스가 갖춰야할 몇 가지 조건이 있음
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요:
- created (데이터 업데이트 관점에서 필요하지는 않음)
- modified
- deleted
- 데이터 소스가 API라면 특정 날짜를 기준으로 새로 생성되거나 업데이트된 레코드들을 읽어올 수 있어야함
- 데이터 소스가 프로덕션 데이터베이스 테이블이라면 다음 필드가 필요:
Best Practices (2)
- 멱등성(Idempotency)을 보장하는 것이 중요
- 멱등성은 무엇인가 ?
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함
- 예를 들면 중복 데이터가 생기지 말아야함
- 중요한 포인트는 critical point들이 모두 one atomic action으로 실행이 되어야 한다는 점
- SQL의 transaction이 꼭 필요한 기술
- 동일한 입력 데이터로 데이터 파이프라인을 다수 실행해도 최종 테이블의 내용이 달라지지 말아야함
Best Practices (3)
- 실패한 데이터 파이프라인 재실행이 쉬어야함
- 과거 데이터를 다시 채우는 과정(Backfill)이 쉬어야함
- Airflow는 이 부분(특히 backfill)에 강점을 갖고 있음
Best Practices (4)
- 데이터 파이프라인의 입력과 출력을 명확히 하고 문서화
- 비즈니스 오너 명시: 누가 이 데이터를 요청했는지를 기록으로 남길 것
- 이게 나중에 데이터 카탈로그로 들어가서 데이터 디스커버리에 사용 가능함
- 데이터 리니지가 중요해짐 -> 이걸 이해하지 못하면 온갖 종류의 사고 발생
Best Practices (5)
- 주기적으로 쓸모없는 데이터들을 삭제
- Kill unused tables and data pipelines proactively
- Retain only necessary data in DW and move past data to DL (or storage)
Best Practices (6)
실패를 당연히 여기고, 실패했을 때 그 사고를 살펴보는 것. 왜 이 사고가 일어났는지 이해하고 재발 방지를 위함
- 데이터 파이프라인 사고시 마다 사고 리포트 (post-mortem) 쓰기
- 목적은 동일한 혹은 아주 비슷한 사고가 또 발생하는 것을 막기 위함
- 사고 원인(root-cause)을 이해하고 이를 방지하기 위한 액션 아이템들의 실행이 중요해짐
- 기술 부채의 정도를 이야기해주는 바로미터
Best Practices (7)
- 중요 데이터 파이프라인의 입력과 출력을 체크하기
- 아주 간단하게 입력 레코드의 수와 출력 레코드의 수가 몇개인지 체크하는 것부터 시작
- Summary 테이블을 만들어내고 Primary Key가 존재한다면 Primary Key Uniqueness가 보장되는지 체크하는 것이 필요함
- 중복 레코드 체크
-> 데이터 대상 유닛 테스트
간단한 ETL 작성해보기
Extract, Transform, Load
-
Extract:
- 데이터를 데이터 소스에서 읽어내는 과정. 보통 API 호출
-
Transform:
- 필요하다면 그 원본 데이터의 포맷을 원하는 형태로 변경시키는 과정. 굳이 변환할 필요는 없음
-
Load:
- 최종적으로 Data Warehouse에 테이블로 집어넣는 과정
-- 모듈과 충돌로 인해 버전 맞추기 !pip install ipython-sql==0.4.1 !pip install SQLAlchemy==1.4.49 -- load %load_ext sql -- 코랩에서 redshift 접속 %sql postgresql://ID:PW@HOST_URL -- 테이블 생성 %%sql DROP TABLE IF EXISTS my_schema.name_gender; CREATE TABLE my_schema.name_gender ( name varchar(32) primary key, gender varchar(8) ); --테이블 생성 확인 %%sql SELECT * FROM kyongjin1234.name_gender;
import psycopg2 # Redshift connection 함수 def get_Redshift_connection(): host = "HOST_URL" redshift_user = "ID" redshift_pass = "PW" port = port_num dbname = "db_name" conn = psycopg2.connect("dbname={dbname} user={user} host={host} password={password} port={port}".format( dbname=dbname, user=redshift_user, password=redshift_pass, host=host, port=port )) conn.set_session(autocommit=True) return conn.cursor()
ETL 함수를 하나씩 정의
import requests def extract(url): f = requests.get(url) return (f.text) def transform(text): lines = text.strip().split("\n") records = [] for l in lines: (name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ] records.append([name, gender]) return records def load(records): """ records = [ [ "Keeyong", "M" ], [ "Claire", "F" ], ... ] """ # BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음 cur = get_Redshift_connection() # DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태 for r in records: name = r[0] gender = r[1] print(name, "-", gender) sql = "INSERT INTO kyongjin1234.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender) cur.execute(sql)데이터 확인
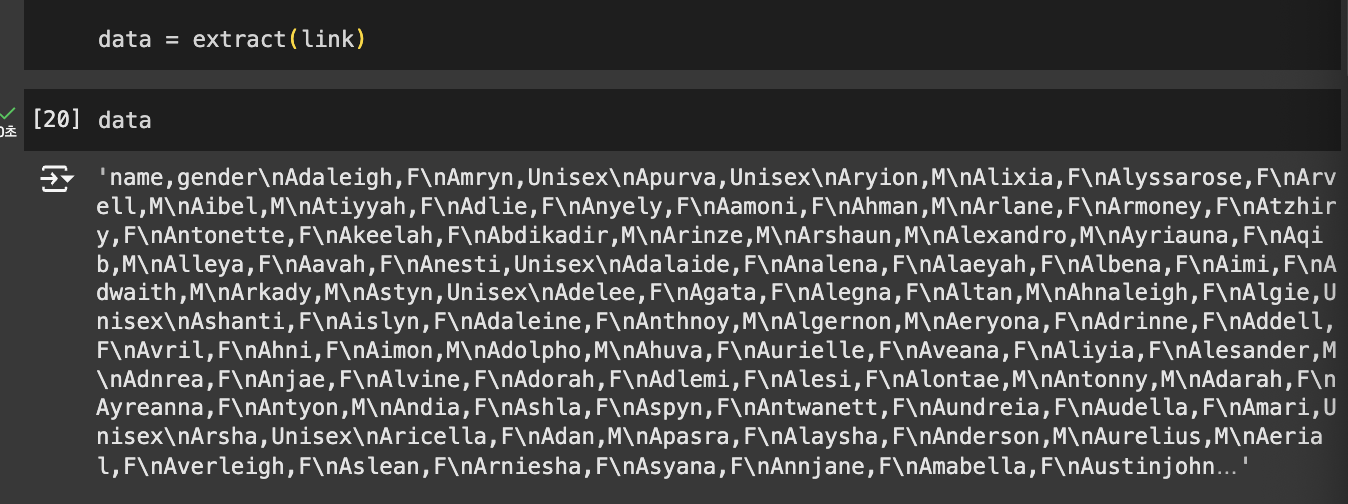
lines = transform(data)
len(lines) # 101
lines[0:10]
''' 결과
[['name', 'gender'],
['Adaleigh', 'F'],
['Amryn', 'Unisex'],
['Apurva', 'Unisex'],
['Aryion', 'M'],
['Alixia', 'F'],
['Alyssarose', 'F'],
['Arvell', 'M'],
['Aibel', 'M'],
['Atiyyah', 'F']]
'''load 후 데이터 확인
load(lines)%%sql
SELECT COUNT(1)
FROM kyongjin1234.name_gender;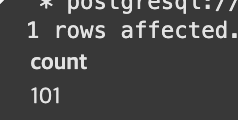
%%sql
SELECT *
FROM kyongjin1234.name_gender;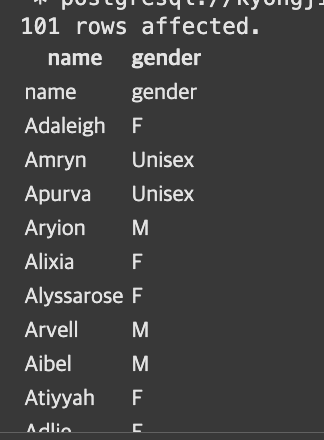
%%sql
SELECT gender, COUNT(1) count
FROM kyongjin1234.name_gender
GROUP BY gender;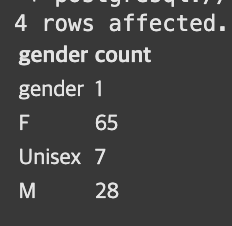
하지만 위의 코드의 경우 문제가
1. 컬럼명(gender, name)이 레코드로 인식되어 첫번째 레코드로 추가됨
2. 데이터 추가시 테이블의 데이터를 삭제해주고 추가하지 않아 멱등성이 보장되지 않음
의 문제가 있다.
1번의 문제의 경우 transform함수를 수정하여 해결할 수 있다.
def transform(text):
lines = text.strip().split("\n")
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
if name == 'name' and gender == 'gender':
continue
records.append([name, gender])
return recordsname이 'name'이고 gender가 'gender'일 경우 continue하여 다음 루프로 넘어가게끔하여 수정하였다.
2번 문제의 경우 load 함수를 수정하여 해결할 수 있다.
def load(records):
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute("DELETE FROM kyongjin1234.name_gender;")
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = "INSERT INTO kyongjin1234.name_gender VALUES ('{n}', '{g}')".format(n=name, g=gender)
cur.execute(sql)
cur.execute("END;")
except Exception as e:
cur.execute("ROLLBACK;")
print("에러 발생:", e)
BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주었으며 DELETE FROM을 먼저 수행하여 FULL REFRESH을 하는 형태로 코드를 수정하였다. 만약 코드 실행 시 에러가 발생할 경우 ROLLBACK을 실행한다.
