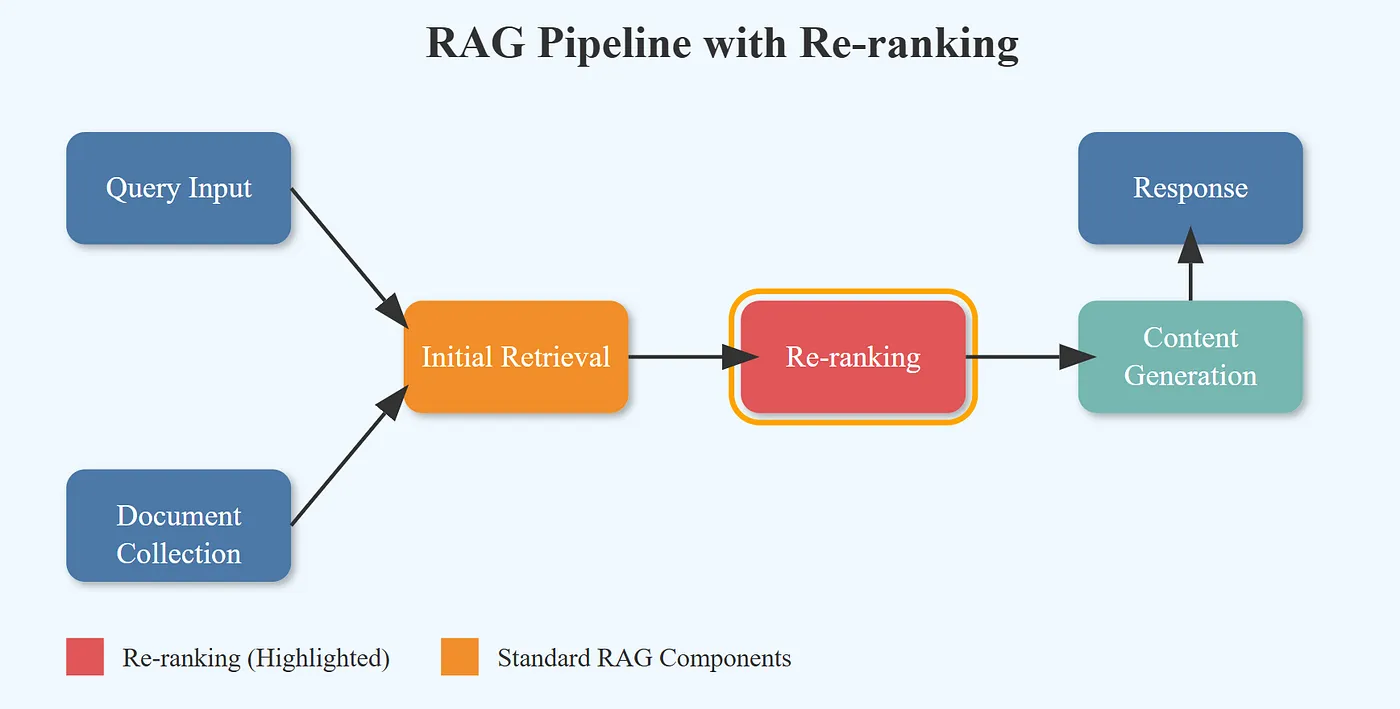
지난 번에 벡터 DB에서 코사인 유사도로만 걸러진 후보들을 LLM이 그대로 설명하다 보니 질문과 덜 맞는 정보까지 불필요하게 설명하는 문제가 있었다. 그래서 필터링 과정을 좀 더 유동적이고 똑똑하게 만들 필요가 있다고 판단했고, 중간 단계에 LLM을 하나 더 추가해서 의미 기반 필터링을 먼저 수행한 뒤, 그 결과를 가지고 최종 답변을 생성하도록 Two-Stage RAG 방식으로 구조를 리팩토링 하려고 한다.
이번에는 여기에 더해서
필터링 모델과 답변 모델을 각각 다르게 설정하면서
속도, 비용, 품질을 비교해보고 최적의 조합을 찾는 실험을 진행할 예정이다.
그 전에 먼저 Two-Stage RAG의 전체 흐름을 간단하게 정리해보겠다.
Two-Stage RAG이란?
쉽게 말해서, 벡터 DB가 코사인 유사도 기반으로 후보군(topK)을 먼저 가져오고,
그 다음에 LLM이 이 후보들을 다시 읽고 ‘질문과 정말 맞는지’ 의미적으로 필터링한 뒤,
최종적으로 필터링된 데이터만 가지고 또 다른 LLM이 자연어 답변을 만들어주는 구조라고 보면 된다.
조금 더 자세하게 설명하면 흐름은 이렇게 된다
1단계: 벡터 검색 (Retrieve)
- 벡터 DB가 질문과 가장 유사한 문서들을 topK개 추려준다.
- 여기서는 “문장 자체의 벡터 유사도”만 비교하기 때문에,
문장 표현이 비슷하지만 실제로 질문 의도와는 덜 맞는 글도 포함될 수 있다. - 즉, 이 단계는 빠르고 싸지만 정확도가 애매한 후보군 목록을 만드는 역할이다.
2단계: LLM 필터링 (Re-Rank / Filter)
- 1단계에서 가져온 후보들을 LLM이 다시 읽고
“이 질문과 진짜로 관련 있는 게 무엇인지” 판단한다. - 이 과정은 벡터 유사도만으로는 못 잡아내는
의도 파악, 규칙 비교, 문맥 기반 판단 같은 고차원적 판단을 해준다. - 여기서 0~3개의 글만 남기도록 필터링하는 구조를 쓰면
추천 품질이 훨씬 좋아진다.
3단계: 최종 답변 생성 (Answer)
- 2단계에서 필터링된 글만을 넣고 LLM이 자연어로 추천을 만들어준다.
- 이 단계는 실제 사용자에게 보여지는 문장을 만드는 단계라
모델을 좀 더 고품질로 사용하는 경우가 많다.
Two-Stage RAG의 핵심은 “1차 후보군을 다시 의미적으로 걸러주는 단계(Re-Ranker)”인데,
이 역할을 어떤 방식으로 할지에 따라 몇 가지가 존재한다.
지금 취밋에서는 LLM이 직접 Re-Ranker 역할을 하고 있는 구조로 멀티 모델 구조는 아니다.
Re-Ranker 종류 & 비교
| 종류 | 설명 | 장점 | 단점 |
|---|---|---|---|
| 1) LLM 기반 Re-Ranker | LLM에게 "후보 중 질문과 가장 관련 있는 글만 골라라"라고 프롬프트로 지시 | - 의미 이해력이 가장 뛰어남 - 다중 조건(보증금·지역·대여방식 등) 판단 가능 - 구현 쉬움(프롬프트만 작성) | - 비용 증가 - 응답 시간 증가 - 온도/프롬프트 영향으로 약간의 변동 가능 |
| 2) Cross-Encoder Re-Ranker (HuggingFace MiniLM 등) | (query, doc) 쌍을 넣어 점수 직접 예측하는 모델 | - 빠르고 안정적 - top100→top10 재랭킹에 매우 강함 | - LLM보다 의미적 유연성이 떨어짐 - 추가 서버/환경 구축 필요 |
| 3) Cohere Rerank | 캐나다 NLP 스타트업 Cohere에서 제공 | - 매우 빠름 - 결과 일관성 높음 - 운영 부담 없음 | - 도메인 특화 정보 해석은 제한적 - API 비용 존재 - 한국어/특수 조건 성능 편차 |
LLM 기반 Re-Ranker를 선택한 이유
Cross-Encoder 기반 Re-Ranker는 쿼리와 문서를 쌍으로 넣어 직접 점수를 계산하기 때문에 정확도가 높은 편이다.
하지만 트래픽이 조금만 많아져도 연산량이 크게 늘어나 과부하가 생길 수 있고, 대부분 HuggingFace 모델이라 파이썬 서버나 별도 인프라가 필요하다는 점이 부담이었다.
Cohere처럼 상용 Re-Ranker API도 존재하고 속도와 효율이 뛰어나지만, 한국어 지원에 품질이 좀 아쉽다라는 내용이 있어서 안정적인 품질을 보장하긴 어렵다는 단점이 있었다.
결국 취밋에서는 이미 다른 도메인에서 OpenAI API 기반 LLM을 사용하고 있었고,
제목·내용·카테고리·지역·보증금·대여료·수령/반납 방식 같은 다양한 조건을 동시에 판단해야 하는 검색 기능 이 필요했고 답변에 대한 퀄리티도 제대로 받고 싶었다.
서비스구조 변경
reranker를 추가하기 위해 서비스 메서드를 하나 더 추가했고 그 LLM이 검색해서 유사한 게시글을 [32, 12] 이런 식으로 추천을 해줄 텐데 그 답변을 파싱해서 postId를 불러 올 수 있게 해주는 메서드도 구현해두었다.
private List<Long> selectRecommendedIdsWithLLM(String query, List<Post> candidates) {
String context = candidates.stream()
.map(p -> """
ID: %d
제목: %s
카테고리ID: %d
대여료: %d원
보증금: %d원
거래 방식: 수령=%s / 반납=%s
지역ID들: %s
""".formatted(
p.getId(),
p.getTitle(),
p.getCategory().getId(),
p.getFee(),
p.getDeposit(),
p.getReceiveMethod(),
p.getReturnMethod(),
p.getPostRegions().stream()
.map(r -> r.getRegion().getId())
.toList()
))
.collect(Collectors.joining("\n\n"));
String prompt = rerankPrompt.formatted(context, query);
String raw = chatClient.prompt(prompt)
.options(ChatOptions.builder()
.model("gpt-4.1-mini")
.temperature(1.0)
.build())
.call()
.content();
return parseJsonIdList(raw);
}
private List<Long> parseJsonIdList(String json) {
try {
json = json.replaceAll("[^0-9,]", "");
if (json.isBlank())
return List.of();
return Arrays.stream(json.split(","))
.map(String::trim)
.filter(s -> !s.isBlank())
.map(Long::valueOf)
.toList();
} catch (Exception e) {
return List.of();
}
}
public String searchWithLLM(String query, List<PostListResBody> recommendedPosts) {
String context = recommendedPosts.stream()
.map(p -> """
제목: %s
카테고리ID: %d
대여료: %d원
보증금: %d원
수령 방식: %s
반납 방식: %s
지역ID들: %s
""".formatted(
p.title(),
p.categoryId(),
p.fee(),
p.deposit(),
p.receiveMethod(),
p.returnMethod(),
p.regionIds()
))
.collect(Collectors.joining("\n\n"));
String prompt = answerPrompt.formatted(query, context);
return chatClient.prompt(prompt)
.options(ChatOptions.builder()
.model("gpt-5.1")
.temperature(1.0)
.build())
.call()
.content();
}
테스트
지난번 포스트에서 단일 모델 속도 테스트를 진행했을 때, 특히 빠른 응답 속도를 보여줬던 gpt-4.1-mini와 gpt-4o-mini를 이번에는 Re-Ranker 모델로 설정하고 reranker 온도 설정도 단일 모델 테스트와 동일한 환경에서 진행하기 위해 1로 고정해두었다.
그리고 답변 생성 모델(Answer LLM)은 다음과 같은 조합으로 실험할 예정이다.
- 만약 Re-Ranker가 gpt-4.1-mini라면 → gpt-5.1을 Answer 모델로 사용
- 만약 Re-Ranker가 gpt-4o-mini라면 → gpt-4.1-mini와 gpt-5.1 두 가지를 Answer 모델로 비교 테스트
이 조합들로 질문 유형별(포괄 / 중간 / 구체적 질문)로 속도와 품질을 측정하면서 이번에는 Two-Stage RAG 조합별 최적의 모델 구성을 찾아볼 예정이다.
조합 1 — 4o-mini (Re-Ranker) + 4.1-mini (Answer)
| 질문 유형 | 질문 | 추천 장비 | 응답 속도 |
|---|---|---|---|
| 포괄 | 장비 대여 추천해줘 | 맥북 14, 맥북 프로, 삼성 갤럭시북 | 4.51 s |
| 포괄 | 여행 촬영용 장비 추천 | 고프로 HERO12, 소니 A7M4, 캐논 R10 | 6.25 s |
| 중간 | 대학생 스터디용 태블릿 대여 추천해줘 | 갤럭시 탭 S9 | 4.24 s |
| 중간 | 콘솔 게임기 대여 추천 | 플레이스테이션 5, 닌텐도 스위치 OLED | 4.00 s |
| 구체 | 고성능 영상촬영 카메라 추천 | 소니 A7M4, 캐논 R10 | 3.89 s |
| 구체 | 20만원 보증금 이하 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 4.04 s |
| 구체 | 캐논 미러리스 카메라만 추천 | 캐논 EOS R10 | 3.29 s |
| 구체 | 저렴한 입문자 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 3.67 s |
평균 응답 속도 ≈ 4.24초
필터링 정확도: 중(가끔 엉뚱한 후보를 포함할 때가 있었다.)
답변 품질: 중
➡ 약 43% 속도 개선
(7.42s → 4.24s)
조합 2 — 4o-mini (Re-Ranker) + 5.1 (Answer)
| 질문 유형 | 질문 | 추천 장비 | 응답 속도 |
|---|---|---|---|
| 포괄 | 장비 대여 추천해줘 | 맥북 14, 맥북 프로, 삼성 갤럭시북 | 8.33 s |
| 포괄 | 여행 촬영용 장비 추천 | 고프로 HERO12, 소니 A7M4, 캐논 R10 | 9.83 s |
| 중간 | 대학생 스터디용 태블릿 대여 추천해줘 | 갤럭시 탭 S9 | 9.45 s |
| 중간 | 콘솔 게임기 대여 추천 | 플레이스테이션 5, 닌텐도 스위치 OLED | 6.52 s |
| 구체 | 고성능 영상촬영 카메라 추천 | 고프로 HERO12, 소니 A7M4, | 9.55 s |
| 구체 | 20만원 보증금 이하 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 6.77 s |
| 구체 | 캐논 미러리스 카메라만 추천 | 캐논 EOS R10 | 5.95 s |
| 구체 | 저렴한 입문자 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 9.58 s |
평균 응답 속도 ≈ 8.50초
필터링 정확도: 중 (가끔 엉뚱한 후보를 포함할 때가 있었다.)
답변 품질: 최상 (5.1 답변 품질 그대로 유지됨)
➡ 약 38% 속도 개선 (13.67s → 8.50s)
조합 3 — 4.1-mini (Re-Ranker) + 5.1 (Answer)
| 질문 유형 | 질문 | 추천 장비 | 응답 속도 |
|---|---|---|---|
| 포괄 | 장비 대여 추천해줘 | 맥북 14, 맥북 프로, 삼성 갤럭시북 | 8.94 s |
| 포괄 | 여행 촬영용 장비 추천 | 고프로 HERO12, 소니 A7M4, 캐논 R10 | 8.87 s |
| 중간 | 대학생 스터디용 태블릿 대여 추천해줘 | 갤럭시 탭 S9 | 7.54 s |
| 중간 | 콘솔 게임기 대여 추천 | 플레이스테이션 5, 닌텐도 스위치 OLED | 7.38 s |
| 구체 | 고성능 영상촬영 카메라 추천 | 고프로 HERO12, 소니 A7M4, 캐논 R10 | 9.32 s |
| 구체 | 20만원 보증금 이하 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 6.42 s |
| 구체 | 캐논 미러리스 카메라만 추천 | 캐논 EOS R10 | 5.96 s |
| 구체 | 저렴한 입문자 카메라 추천 | 캐논 EOS R10, 고프로 HERO12 | 8.43 s |
평균 응답 속도 ≈ 7.86초
필터링 정확도: 상
답변 품질: 최상 (5.1의 답변 품질이 그대로 유지됨)
➡ 약 42% 속도 개선 (13.67s → 7.86s)
결론
기존에는 단일 모델을 두 번 호출하는 구조로 테스트를 진행했는데, reranker를 도입해서 Two-Stage RAG 방식을 적용하니까 전체적으로 응답 속도가 꽤 개선되는 걸 확인할 수 있었다.
질문마다 편차는 있었지만, 현재 조합 중에서는 4.1 mini를 reranker로 쓰고 답변은 5.1로 가는 방식이 가장 안정적이고 품질도 좋았다. 비용도 어느 정도 절감 효과가 있어서 지금 구조에서는 꽤 적합해 보인다.
장기적으로 보면, 답변 모델을 꼭 5.1로 유지하지 않고 answer는 4.1 mini, reranker는 4o mini 같은 조합이 가장 가성비가 좋아 보인다.
reranker를 직접 도입해 응답시간을 개선해보고 RAG 구조를 더 깊게 공부하는 데도 도움이 되었고, 추후에는 LlamaIndex처럼 Cross-Encoder Re-Ranker 모델을 제공하는 프레임워크를 써보는 것도 좋을 것 같다.
