원시값과 객체의 비교
자바스크립트가 제공하는 7가지 데이터 타입(숫자, 문자열, 불리언, null, defined, 심벌, 객체 타입)은 크게 원시 타입(primitive type)과 객체 타입(object/reference type)으로 구분한다. 이렇게 구분하는 이유는 무엇일까? 근본적으로 다르기 때문이다.
-
원시 타입의 값, 즉 원시 값은 변경 불가능한 값(immutable value)이다. 이에 비해 객체(참조) 타입의 값, 즉 객체는 변경 가능한 값(mutable value)이다.
-
원시 값을 변수에 할당하면, 변수(확보된 메모리 공간)에는 실제 값이 저장된다. 반면, 객체를 변수에 할당하면 변수(확보된 메모리 공간)에는 참조 값이 저장된다.
-
원시 값을 갖는 변수를 다른 변수에 할당하면, 원본의 원시 값이 복사되어 전달된다. 이를 값에 의한 전달(pass by value)이라 한다. 이에 비해 객체를 가리키는 변수를 다른 변수에 할당하면 원본의 참조 값이 복사되어 전달된다. 이를 참조에 의한 전달(pass by reference)이라 한다.
객체
객체는 프로퍼티의 개수가 정해져 있지 않으며, 동적으로 추가되고 삭제할 수 있다. 또한 프로퍼티의 값에도 제약이 없다. 따라서 객체는 원시 값과 같이 확보해야 할 메모리 공간의 크기를 사전에 정해둘 수도 없다.
객체는 복합적인 자료구조이므로, 객체를 관리하는 방식이 원시 값과 비교해 복잡하고 구현 방식도 브라우저 제조사마다 다를 수 있다. 원시 값은 상대적으로 적은 메모리를 소비하지만, 객체는 경우에 따라 크기가 매우 클 수도 있다. 객체를 생성하고 프로퍼티에 접근하는 것도 원시 값과 비교할 때 비용이 많이 드는 일이다. 따라서 객체는 원시 값과는 다른 값과는 다른 방식으로 동작하도록 설계되어 있다.
🎀 자바스크립트 객체의 관리 방식
자바스크립트 객체는 프로퍼티 키를 인덱스로 사용하는 해시 테이블(hash table, 해시 테이블은 연관 배열(associative array), map, dictionary, lookup table이라 부르기도 한다)이라고 생각할 수 있다. 대부분의 자바스크립트 엔진은 해시 테이블과 유사하지만 높은 성능을 위해 일반적인 해시 테이블보다 나은 방법으로 객체를 구현한다.
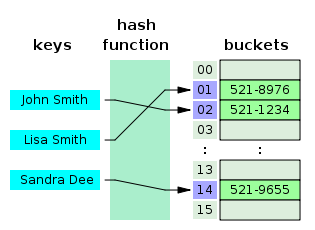
자바, C++ 같은 클래스 기반 객체지향 프로그래밍 언어는, 사전에 정의된 클래스를 기반으로 객체(인스턴스)를 생성한다. 다시 말해, 객체를 생성하기 이전에 이미 프로퍼티와 메서드가 정해져 있으며 그대로 객체를 생성한다. 객체가 생성된 이후에는 프로퍼티를 삭제하거나 추가할 수 없다.
하지만 자바스크립트는 클래스 없이 객체를 생성할 수 있으며, 객체가 생성된 이후라도 동적으로 프로퍼티와 메서드를 추가할 수 있다. 이는 사용하기 매우 편리하지만 성능 면에서는 이론적으로 클래스 기반 객체지향 프로그래밍 언어의 객체보다 생성과 프로퍼티 접근에 비용이 더 많이 드는 비효율적인 방식이다.
따라서 V8 자바스크립트 엔진에서는, 프로퍼티에 접근하기 위해 동적 탐색(dynamic lookup) 대신 히든 클래스(hidden class)라는 방식을 사용해 C++ 객체의 프로퍼티에 접근하는 정도의 성능을 보장한다. 히든 클래스는 자바와 같이 고정된 객체 레이아웃(클래스)과 유사하게 동작한다.
🥛 변경 가능한 값
객체(참조) 타입의 값, 즉 객체는 변경 가능한 값이다. 먼저 변수에 객체를 할당하면 어떤 일이 일어나는지 살펴보자.
원시 값을 할당한 변수가 기억하는 메모리 주소를 통해 메모리 공간에 접근하면 원시 값에 접근할 수 있다. 즉, 원시 값을 할당한 변수는 원시 값 자체를 값으로 갖는다. 하지만 객체를 할당한 변수가 기억하는 메모리 주소를 통해 메모리 공간에 접근하면 참조 값에 접근할 수 있다. 참조 값은 생성된 객체가 저장된 메모리 공간의 주소, 그 자체다.
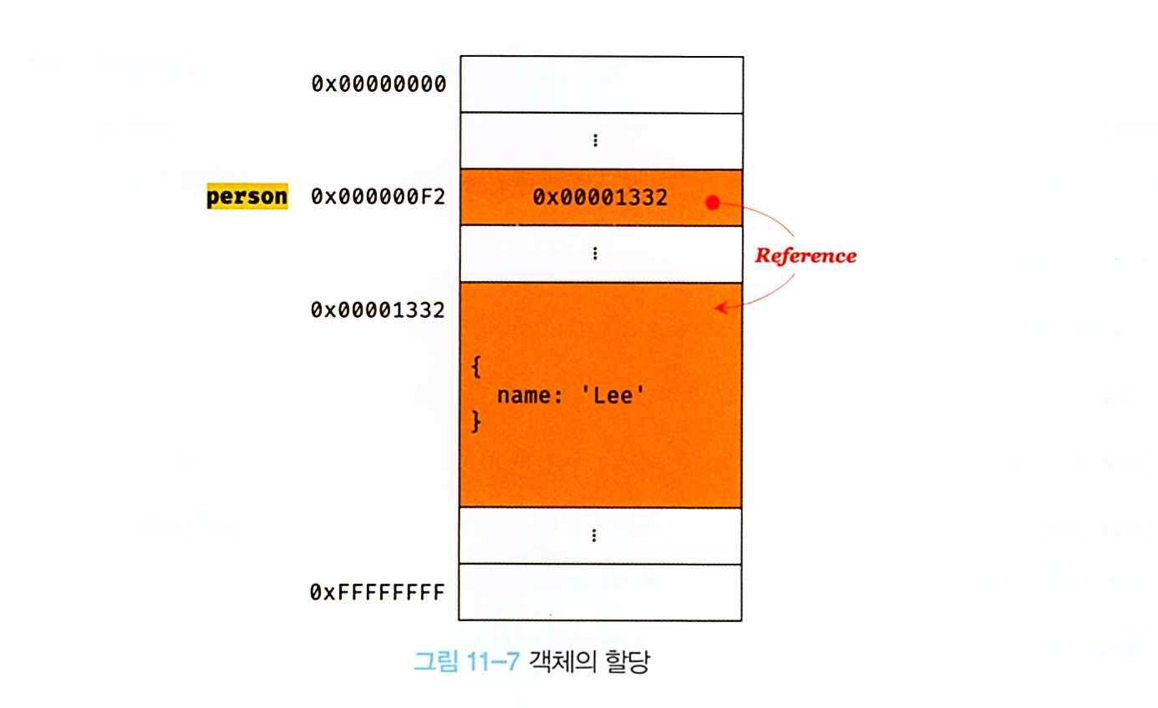
객체를 할당한 변수에는 생성된 객체가 실제로 저장된 메모리 공간의 주소가 저장되어 있다. 이 값을 참조 값이라 하고, 변수는 이 참조 값을 통해 객체에 접근할 수 있다.
🖥️ // 할당이 이뤄지는 시점에 객체 리터럴이 해석되고, 그 결과 객체가 생성된다.
var person = {
name: 'Lee'
}
// person 변수에 저장되어 있는 참조 값으로 실제 객체에 접근한다.
console.log(person); // {name: "Lee"}일반적으로 원시 값을 할당한 변수는 "변수는 O값을 갖는다" 또는 "변수의 값은 O다"라고 표현한다. 하지만 객체를 할당한 변수는 "변수는 객체를 참조하고 있다" 또는 "변수는 객체를 가리키고(point) 있다"고 표현한다. 위 예제에서 person 변수는 객체 { name: 'Lee' }를 가리키고(참조하고) 있다.
원시 값은 변경 불가능한 값이므로, 원시 값을 갖는 변수 값을 변경하려면 재할당 외에는 방법이 없다. 하지만 객체는 변경 가능한 값이다. 따라서 객체를 할당한 변수는 재할당 없이 객체를 직접 변경할 수 있다. 즉, 재할당 없이 프로퍼티를 동적으로 추가할 수도 있고, 프로퍼티 값을 갱신할 수도 있으며, 프로퍼티 자체를 삭제할 수도 있다.
🖥️ var person = {
name: 'Lee'
}
// 프로퍼티 값 갱신
person.name = 'Kim';
// 프로퍼티 동적 생성
person.address = 'Seoul';
console.log(person); // {name: "Kim", address: "Seoul"}
(그림 11-7의 주황색 영역에 {name: "Kim", address: "Seoul"}가 들어간다)
원시 값을 갖는 변수의 값을 변경하려면 재할당을 통해 메모리에 원시 값을 새롭게 생성해야 한다. 하지만 객체는 변경 가능한 값이므로 직접 수정이 가능하다. 이때 객체를 할당한 변수에 재할당을 하지 않았으므로, 객체를 할당한 변수의 참조 값은 변경되지 않는다.
객체를 변경할 때마다 원시 값처럼 이전 값을 복사해서 새롭게 생성한다면 명확하고 신뢰성이 확보되겠지만, 객체는 크기가 매우 클 수도 있고, 원시 값처럼 크기가 일정하지도 않으며, 프로퍼티 값이 객체일 수도 있어서 복사(deep copy)해서 생성하는 비용이 많이 든다. 즉, 메모리의 효율적 소비가 어렵고 성능이 나빠진다.
메모리의 효율적 사용, 객체 복사 생성 비용 절감을 통한 성능 향상이, 바로 객체가 변경 가능한 값으로 설계된 이유다. 어느 정도의 단점을 감안한 설계다.
객체의 이러한 구조적 단점에 따른 부작용이 있는데, 그것은 원시 값과는 다르게 여러 개의 식별자가 하나의 객체를 공유할 수 있다는 것이다.
🎀 얕은 복사(shallow copy)와 깊은 복사(deep copy)
1. 객체의 경우
객체를 프로퍼티 값으로 갖는 객체의 경우, 얕은 복사는 한 단계까지만 복사하는 것을 말하고, 깊은 복사는 객체에 중첩되어 있는 객체까지도 모두 복사하는 것을 말한다.
🖥️ const o = { x: { y: 1 } };
// 얕은 복사
const c1 = {...o};
console.log(c1 === o); // false
console.log(c1.x === o.x); // true
// lodash의 cloneDeep을 사용한 깊은 복사
// "npm install lodash"로 lodash를 설치한 후, Node.js 환경에서 실행
const _ = require('lodash');
// 깊은 복사
const c2 = _.cloneDeep(o);
console.log(c2 === o); // false
console.log(c2.x === o); // false
❓lodash 뭐더라
얕은 복사와 깊은 복사로 생성된 객체는 원본과는 다른 객체다.
즉 원본과 복사본은 참조 값이 다른 별개의 객체다. 하지만 얕은 복사는 객체에 중첩되어 있는 객체의 경우 참조 값을 복사하고, 깊은 복사는 객체에 중첩되어 있는 객체까지 모두 복사해서 원시 값처럼 완전한 복사본을 만든다는 차이가 있다.
스프레드 문법({...o})을 사용할 때 객체의 중첩된 구조까지 완전히 복사하는 게 아니라, 최상위 레벨에서만 새로운 객체가 생성되고, 중첩된 객체는 참조가 복사됩니다. 즉, o와 c1는 최상위에서는 서로 다른 객체지만, 내부에 있는 x 객체는 여전히 같은 객체를 참조하고 있기 때문에 o.x === c1.x가 true로 나옵니다.
스프레드 문법은 얕은 복사(shallow copy)를 수행하기 때문에,
최상위 레벨에서만 새로운 객체를 만들고, 그 안에 중첩된 객체는
그대로 참조를 공유하게 됩니다. 그렇기 때문에 o와 c1는 최상위에서는 다르지만, 내부 속성인 x는 동일한 참조를 가리키게 되는 것이죠.
그래서 중괄호가 하나 벗겨지지 않은 것처럼 보이는 이유는 사실
중첩된 객체가 그대로 유지되기 때문입니다.
중첩된 객체까지 모두 새로 복사하는 깊은 복사(deep copy)가 필요하다면, structuredClone() 함수나 lodash의 cloneDeep 같은 방법을 사용할 수 있습니다.
2. 원시 값의 경우
참고로 다음과 같이 원시 값을 할당한 변수를 다른 변수에 할당하는 것을 깊은 복사, 객체를 할당한 변수를 다른 변수에 할당하는 것을 얕은 복사라고 부르는 경우도 있다.
const v = 1;
// "깊은 복사"라고 부르기도 한다.
const c1 = v;
console.log(c1 === v); // true
const o = { x: 1 };
// "얕은 복사"라고 부르기도 한다.
const c2 = 0;
console.log(c2 === o); // true🍶 참조에 의한 전달
여러 개의 식별자가 하나의 객체를 공유할 수 있다는 것이 무엇을 의미하는지, 그리고 이로 인해 어떤 부작용이 발생하는지 확인해 보자.
var person = {
name: 'Lee'
}
// 참조 값을 복사(얕은 복사)
var copy = person;객체를 가리키는 변수(원본, person)를 다른 변수(사본, copy)에 할당하면 원본의 참조 값이 복사되어 전달된다. 이를 참조에 의한 전달이라 한다.
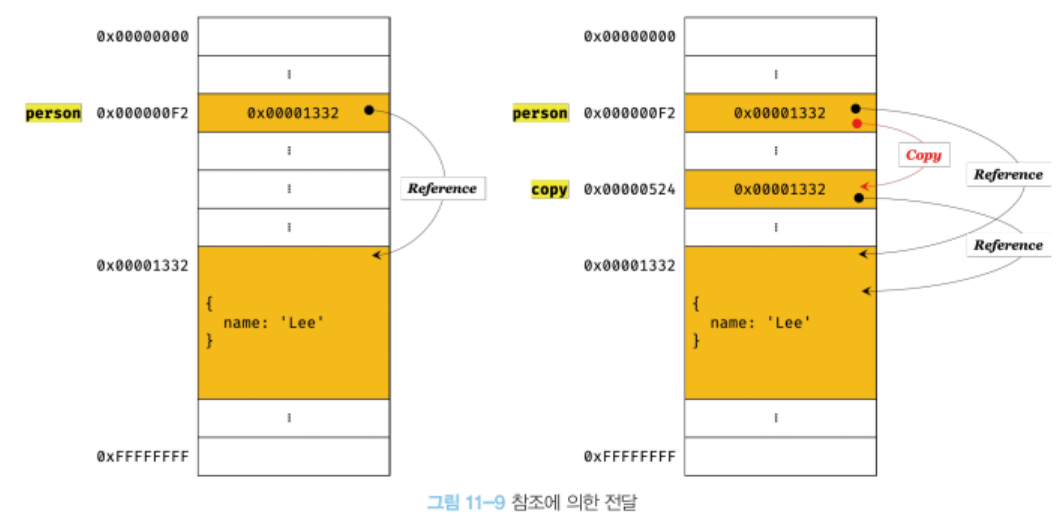
원본 person을 사본 copy에 할당하면, 원본 person의 참조 값을 복사해서 copy에 저장한다. 이때 원본 person과 사본 copy는 저장된 메모리 주소는 다르지만 동일한 참조 값을 갖는다. 다시 말해, 원본 person과 사본 copy 모두 동일한 객체를 가리킨다. 이것은 두 개의 식별자가 하나의 객체를 공유한다는 의미다. 따라서 원본 또는 사본 중 어느 한쪽에서 객체를 변경(변수에 새로운 객체를 재할당하는 것이 아니라, 객체의 프로퍼티 값을 변경하거나 프로퍼티를 추가, 삭제)하면 서로 영향을 주고받는다.
🖥️ var person = {
name: 'Lee'
};
// 참조 값을 복사(얕은 복사), copy와 person은 동일한 참조 값을 갖는다.
var copy = person;
// copy와 person은 동일한 객체를 참조한다.
console.log(copy === person); // true
// copy를 통해 객체를 변경한다.
copy.name = 'Kim';
// person을 통해 객체를 변경한다.
person.address = 'Seoul';
// copy와 person은 동일한 객체를 가리킨다.
// 따라서 어느 한쪽에서 객체를 변경하면 서로 영향을 주고받는다.
console.log(person); // {name: "Kim", address: "Seoul"}
console.log(copy); // {name: "Kim", address: "Seoul"}
결국 "값ㄹ에 의한 전달"과 "참조에 의한 전달"은 식별자가 기억하는 메모리 공간에 저장되어 있는 값을 복사해서 전달한다는 면에서 동일하다. 다만, 식별자가 기억하는 메모리 공간, 즉 변수에 저장되어 있는 값이 원시 값이냐 참조 값이냐의 차이만 있을 뿐이다. 따라서 자바사크립트에는 "참조에 의한 전달"은 존재하지 않고 "값에 의한 전달"만 존재한다고 말할 수 있다.
앞서 언급했듯, 자바스크립트의 이 같은 동작 방식을 설명하는 정확한 용어가 존재하지 않는다. 이런 이유로 "값에 의한 전달"이나 "참조에 의한 전달"이라는 용어를 사용하지 않고, "공유에 의한 전달"이라고 표현하는 경우도 있다. 하지만 이 용어 또한 ECMAScript 사양에 정의된 자바스크립트의 공식적인 용어는 아니며, 자바스크립트의 동작 방식을 정확히 설명하지 못한다.
따라서 이 책에서는 전달되는 값의 종류가 원시 값인지 참조 값인지 구별해서 강조하는 의미에서 "값에 의한 전달"과 "참조에 의한 전달"로 구분하여 부른다. 다만 자바스크립트에는 포인터(pointer)가 존재하지 않기 때문에, 포인터가 존재하는 다른 프로그래밍 언어의 "참조에 의한 전달"과 의미가 정확히 일치하지 않는다는 점에 주의하기 바란다.
🖥️ var person1 = {
name: 'Lee';
}
var person2 = {
name: 'Lee'
}
console.log(person1 === person2) // false
console.log(person.name === person2.name) // true( === 일치 비교 연산자는 변수에 저장되어 있는 값을 타입 변환하지 않고 비교한다.)
객체를 할당한 변수는 참조 값을 가지고 있고, 원시 값을 할당한 변수는 원시 값 자체를 가지고 있다. 따라서 === 일치 비교 연산자를 통해 객체를 할당한 변수를 비교하면 참조 값을 비교하고, 원시 값을 할당한 변수를 비교하면 원시 값을 비교한다.
객체 리터럴은 평가될 때마다 객체를 생성한다. 따라서 person1 변수와 person2 변수가 가리키는 객체는 비록 내용은 같지만 다른 메모리에 저장된 별개의 객체다. 즉, 두 변수의 참조값은 전혀 다른 값이다.
하지만 프로퍼티 값을 참조하는 person1.name과 person2.name은 값으로 평가될 수 있는 표현식이다. 두 표현식 모두 원시 값 'Lee'로 평가된다.
( 출처 : 모던 자바스크립트 Deep Dive, 이웅모, 위키북스 )