filebeat에 대해 공부해보자
01. Introduction
- filebeat는 특정한 로그 파일들을 주기적으로 스캔하여 쌓이는 데이터들을 모으는 역할을 한다.
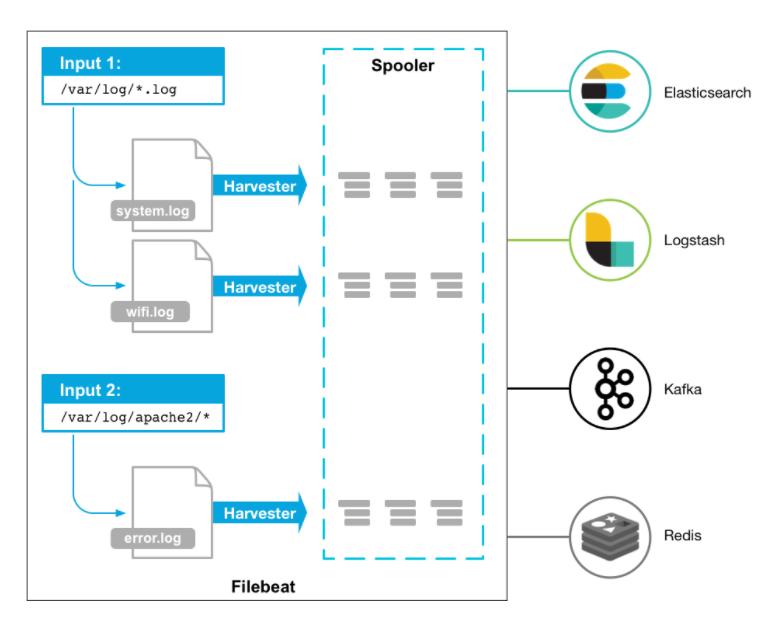
- filebeat는 Inputs, Harvesters, spooler가 주요 역할을 담당한다. filebeat에 Inputs으로 소스 파일 경로를 설정하면, Harvester가 로그를 개별 파일로 처리한다. 이벤트 발생 후 들어오는 로그 데이터는 harvester가 파일을 행 단위로 읽어 출력으로 spooler에게 보낸다. spooler에서 이벤트를 집계하고 spooler에서 구성한 출력으로 전달한다.
02. Filebeat 작동 방식
- filebeat는 주요 구성요소인 inputs와 harvesters로 구성된다.
Inputs
- Inputs는 Harvesters가 읽을 source를 찾는다.
# glob 패턴과 일치하는 모든 로그 파일을 수집한다.
filebeat.inputs:
- type: log
paths:
- /var/log/*.log
- /var/path2/*.logHarvesters
- Harvesters는 단일 파일의 내용을 읽는 역할을 담당한다. 이벤트가 발생하여 생성된 log를 Inputs에서 수집하면, harvester는 각 파일을 한 줄씩 읽어 출력으로 보낸다.
harvester가 읽은 파일의 마지막 위치는 offset으로 기록 되어 레지스트리 파일에서 관리된다. 이렇게 harvester가 읽은 파일의 위치 정보를 기록함으로써, filebeat에 장애가 발생하더라도 filebeat를 다시 기동했을 때 읽던 데이터의 위치부터 데이터를 읽을 수 있다.
또한 harvester가 출력 데이터에게 데이터를 보낸 후에 데이터를 받았다는 응답을 받지 못하면 다시 데이터를 보냄으로써 데이터의 손실을 막는다. - harvester는 하나의 파일 당 하나씩 담당하게 된다. 즉, 읽어야할 파일이 여러개가 되면 그 수에 따라서 harvester도 여러개가 된다.
- harvester는 파일을 열고 한 행씩 다 처리할 때 까지 파일은 열린 상태로 유지된다. 만약 파일이 처리되는 동안 파일이 제거되거나 이름이 바뀌면 filebeat는 계속 파일을 읽게 된다. 이렇게 상태가 유지되면 harvester가 데이터를 다 처리하고 파일을 닫을 때 까지 디스크의 공간이 예약된다.
🎈Reference

과정은 힘들지만😨 성장은 즐겁습니다🎵