문제


풀이
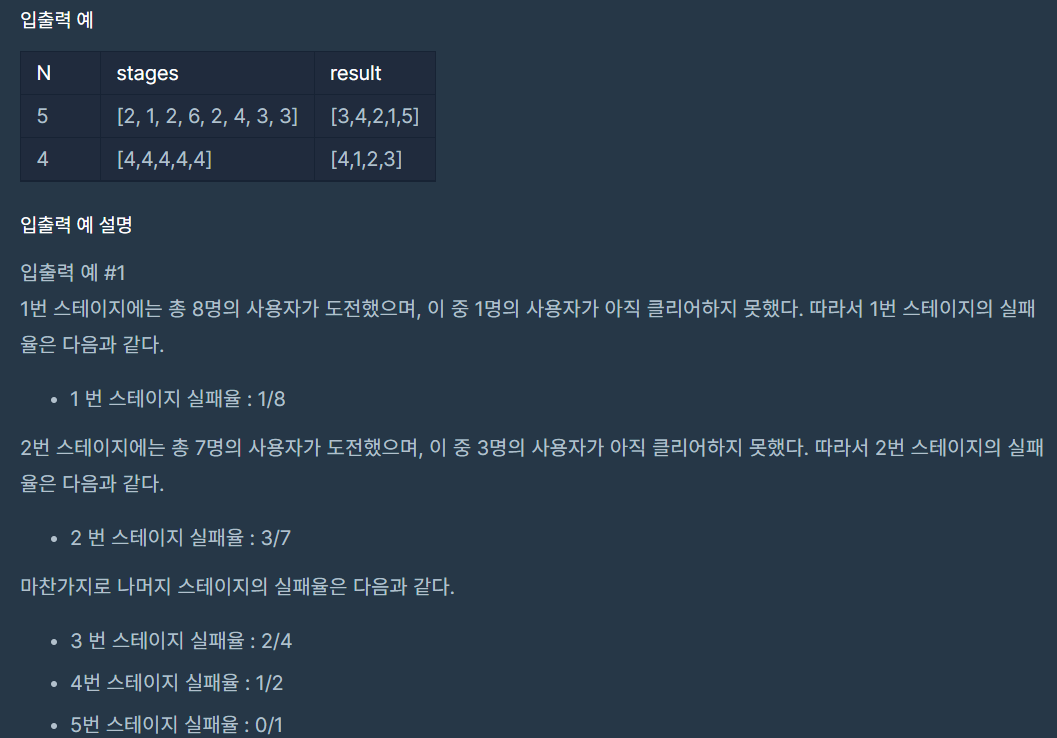
입출력 예에서도 아주 친절하게 잘 설명 해 주듯, stage n의 실패율은 n에 도전한 user의 수 / n보다 큰 stage에 도전한 user 수 + n에 도전한 user의 수 이다. 이걸 잘 풀어서 해결하면 된다.
예시로 설명
더 이해가 잘 가게 입출력 예시 N = 5, stages = [2,1,2,6,2,4,3,3] 을 예시로 설명해보겠다.
위 예시는 stage가 5까지 있고, stage 5를 깬다 == user가 N+1의 stage에 있다. 라고 이해하면 된다.
즉, [1,2,2,2,3,3,4,6] 의 형태에서
stage 5 = 5보다 큰 수 (1개) => 0명 실패 / 1명 시도
5번 도전한 수 (0개)
stage 4 = 4보다 큰 수 (1개) => 1명 실패 / 2명 시도
4번 도전한 수 (1개)
stage 3 = 3보다 큰 수 (2개) => 2명 실패 / 4명 시도
3번 도전한 수 (2개)
stage 2 = 2보다 큰 수 (4개) => 3명 실패 / 7명 시도
2번 도전한 수(3개)
stage 1 = 1보다 큰 수 (7개) => 1명 실패 / 8명 시도
1번 도전한 수 (1개)이렇게 이해하면 된다!
이 방법대로 이제 코드를 짜보자
여러 풀이법이 있겠지만, 나의 경우는 일단 n번 도전한 횟수를 먼저 계산 해주었다.
01. n번 도전 횟수 계산
stages.sort() # stage sort
answer = { x: 0 for x in range(1,N+2) } # stages에 1~N+1까지 담겨있음
# stage마다 user count
for key,_ in answer.items():
answer[key] = stages.count(key)stage를 sort한 뒤, dictionary의 형태로 stage를 도전한 user의 count해준다.
stage마다 count를 하고 나서 부터는 단순하다. stage n의 실패율 = n에 도전한 user의 수 / n보다 큰 stage에 도전한 user 수 + n에 도전한 user의 수 의 공식에 따라 실패율을 계산해주는것이다.
02. 실패율 계산
Try 01
실패율을 계산하는데, 처음에는 1~N까지 n에 도전한 user의 수와 n보다 큰 stage에 도전한 user의 수를 이중for문으로 계산해주었다. 그러나, 이 방법대로 하니 런타임 에러가 상당히 많이 발생했다. 시간 단축을 위해 stage에 도전한 user의 수를 dp로 만들어서 수정해주었다.
# 실패율
result = []
for i in range(1,N+1):
# 분자 : n번 도전 횟수
n_try = answer[i]
# 분모 : n보다 큰 수
n_more = 0
for j in range(i,N+2):
n_more +=answer[j]
result.append([n_try/(n_more+n_try),i])
# 스테이지 번호를 실패율의 내림차순으로 정렬 , 크기가 동일하면 오름차순부터
result.sort(key=lambda x :(-x[0],x[1]))
return [i for _,i in result]Try 02
큰 stage부터 작은 stage로 실패율을 계산해주었다. dp[i]는 i보다 큰 stage 도전 횟수로 설정하였다.
위 예시를 다시 가져와서 설명해보자면
[1,2,2,2,3,3,4,6] 의 형태에서
dp[i]는 i보다 큰 수를 의미한다.
stage 5 = 5보다 큰 수 (1개) == dp[5] = 1
5번 도전한 수 (0개)
stage 4 = 4보다 큰 수 (1개) == dp[4] = dp[5] + 5번에 도전한 수
4번 도전한 수 (1개)
stage 3 = 3보다 큰 수 (2개) == dp[3] = dp[4] + 4번에 도전한 수
3번 도전한 수 (2개)
stage 2 = 2보다 큰 수 (4개) == dp[2] = dp[3] + 3번에 도전한 수
2번 도전한 수(3개)
stage 1 = 1보다 큰 수 (7개) == dp[1] = dp[2] + 2번에 도전한 수
1번 도전한 수 (1개)코드는 아래와 같다.
# 실패율
result = []
dp = [0]*(N+2)
for i in range(N,0,-1):
# 분자 : i번 도전 횟수
n_try = answer[i]
# dp[i] = i보다 큰 수
dp[i] = answer[i+1] + dp[i+1]
# 분모 : i보다 큰 수 + i번 도전 횟수
n_more = dp[i] + n_try
try:
result.append([n_try/n_more,i])
except:
# zero division
result.append([0,i])
result.sort(key=lambda x :(-x[0],x[1]))
return [i for _,i in result]
코드
def solution(N, stages):
stages.sort() # stage sort
answer = { x: 0 for x in range(1,N+2) } # stages에 1 ~ N+1까지 담겨있음
# stage마다 user count
for key,_ in answer.items():
answer[key] = stages.count(key)
# 실패율
result = []
dp = [0]*(N+2)
for i in range(N,0,-1):
n_try = answer[i] # 분자 : i번 도전 횟수
dp[i] = answer[i+1] + dp[i+1] # dp[i] = i보다 큰 수
n_more = dp[i] + n_try # 분모 : i보다 큰 수 + i번 도전 횟수
try:
result.append([n_try/n_more,i])
except:
# zero division
result.append([0,i])
result.sort(key=lambda x :(-x[0],x[1]))
return [i for _,i in result]
후기
dp를 여기서 써먹다니! 많이 발전했다~ :)
