Transform
- 원본 및 예측된 프레임 간의 차이를 주파수 도메인으로 변환
- 비디오 신호의 에너지 집중을 활용
- 공간/시간 도메인 -> 주파수 도메인
- 푸리에 변환, 이산 코사인 변환(DCT)
- 주파수 영역에서 양자화 및 엔트로피 코딩을 수행하는 것이 공간/시간 도메인에서 엔트로피 코딩을 수행하는 것보다 효율적
- 조건
- 데이터는 각각 연관성이 없이 구분 되어야 함
- 몇 개의 값으로 집중되어야 처리하기 쉬워진다는 특성
- 다시 원래의 형태로 돌아오는 가역적인 특성을 가져야함
- 원본 영상으로 돌아오지 못한다는 것은 원본 영상의 손실을 의미하므로 사용할 수 없다
- 컴퓨터가 다루기 쉬워야 함
- 데이터는 각각 연관성이 없이 구분 되어야 함
Block-Based Transform
- 이미지를 작은 블록들로 분할한 다음 각 블록마다 변환을 적용하는 기법
- 장점
- 작은 메모리에서 작동할 수 있다
- 블록 단위로 움직임을 보상하는 코딩 기법에 적합하다
- 단점
- 변환 블록을 작은 크기로 분할할 경우 오히려 변환 후에 데이터량이 많아질 수 있다
- 변환 블록을 큰 크기로 분할할 경우에도 특정영상에서 변환 후에 데이터량이 많아질 수 있다
- 블록과 블록 사이의 가장자리 경계에 모자이크같은 Blocking 현상이 나타난다
- 블록마다 양자화되는 차이에 의해 발생한다
Karhunen-Loeve Transform(KLT)
- 통계적인 방법을 사용하여 데이터 세트의 변동성을 최대화하는 새로운 좌표계를 찾는 선형 변환 방법이다
- 과정
- 데이터 세트의 공분산 행렬을 계산
- 이 공분산 행렬의 고유값과 고유벡터를 찾는다
- 고유값이 큰 순서대로 고유벡터 정렬
- 이렇게 정렬된 고유벡터가 바로 KLT의 기저 벡터가 된다
- 이렇게 변환된 데이터는 원래의 데이터보다 정보를 더 효율적으로 표현할 수 있다
- KLT의 한 가지 단점은 모든 데이터에 대한 공분산 행렬을 계산해야 한다는 점이다
- 이는 계산 복잡성이 크고, 많은 양의 데이터에 대해 사용하기 어렵다는 단점을 가지고 있다
Singular Value Decomposition(SVD)
- 임의의 행렬을 세 행렬의 곱으로 분해하는 방법이다
- A = UΣV^T로 나타낼 수 있다
- A : m x n 크기의 임의의 행렬
- U : m x m 크기의 직교 행렬
- Σ : m x n 크기의 대각 행렬
- V : n x n 크기의 직교 행렬
- Σ의 대각선 상의 원소들을 특이값(Singular Values)라고 하며, 이 특이값들은 크기 순으로 정렬된다
- 이 특이값들은 원래 행렬 A의 중요한 성질을 나타낸다
Discrete Cosine Transform(DCT)
- 신호나 이미지를 주파수 도메인으로 변환하는 방법 중 하나이다
- 이 변환은 신호를 일련의 코사인 파로 분해하는 것을 통해 이루어진다
- DCT는 입력 데이터의 에너지를 가능한 한 적은 수의 변환 계수에 집중시킴으로써, 대부분의 계수를 0 또는 근접한 값으로 만들어 압축을 달성한다
- DCT의 한 가지 주요 단점은 이미지의 고주파 세부 정보를 잃을 수 있다는 것이다. 이는 압축된 이미지에서 블록화 현상(blocking artifact)을 초래할 수 있다
Image-Based Transform
- 전체적인 이미지 내에서 변환을 수행하는 방법
- 대표적으로 Discrete Wavelet Transform(DWT) 방법이 있다
- 장점
- 블록기반 방법보다는 이미지기반 변환 방법이 우수한 편이다
- 단점
- 전체 이미지를 한 번에 처리하기 때문에 매우 큰 메모리가 필요하다
- 블록 단위로 움직임을 보상하는 코딩 기법에는 적합하지 않다
Discrete Wavelet Transform(DWT)
- 웨이블릿 변환의 한 형태로, 신호나 데이터를 다양한 주파수 구성요소로 분해하고 각각을 다른 해상도로 분석하는 방법이다
- DWT는 신호를 다른 주파수 범위의 웨이블릿으로 분해한다. 이 과정은 일반적으로 하프밴드 디지털 필터를 사용하여 수행되며, 이 필터는 신호를 고주파 및 저주파 구성요소로 분리한다
- 고주파 부분은 세부 정보를 나타내며, 저주파 부분은 근사치를 나타낸다. 이 과정은 저주파 부분에 대해 반복적으로 수행되어, 다양한 해상도에서 신호의 세부 정보와 근사치를 얻는다
Image-Based Trnasform - Wavelet Transform
- 이미지 기반 변환 기법
- 이미지를 다양한 주파수 구성요소로 분해하고 그 각각을 다른 해상도로 분석하는 방법이다
- 저주파 필터와 고주파 필터를 이용해서 입력된 영상을 저주파 영역과 고주파 영역으로 분해하는 방법을 사용한다
- 2차원 신호에 적용할 수 있으며 필터를 여러 번 통과시킬 수 있다
- 필터를 통과시킬 때마다 해상도가 반으로 줄어든다
동작
- 2차원 영상의 각 행을 낮은 주파수 및 높은 주파수 필터(Lx, Hx)로 필터링한다
- 각 필터링된 행의 출력은 다운샘플링 되어 중간 이미지인 L(낮은 주파수 성분), H(높은 주파수 성분)을 생성한다
- 행을 기준으로 필터링을 수행했기에 행의 길이는 1/2가 된다
- L : 원본 이미지를 x 방향으로 낮은 주파수로 필터링하고 다운 샘플링
- H : 원본 이미지를 x 방향으로 높은 주파수로 필터링하고 다운 샘플링
- 한 번 필터링된 이미지 L, H에 대해 열 방향으로도 같은 작업이 수행된다 (Ly, Hy로 필터링)
- 각 필터링된 열의 출력은 다운샘플링 되어 네 개의 하위 이미지 생성한다 (LL, LH, HL, HH)
- LL은 2번 고주파 필터를 통과한 것으로써 원본 영상의 특성을 그대로 보유하고 있는 가장 중요한 영역이다
- LH와 HL은 저주파 필터와 고주파 필터가 한 번씩 적용된 것으로 LL 다음으로 중요한 영상이다
- HH는 고주파 필터를 두 번 통과한 것으로써 인간의 눈으로 인식하기 어려움으로 가장 중요하지 않은 영상이다
- 대부분 0에 가까운 값이 분포되어 있다
- HH 영역을 제거해줌으로써 화질을 어느정도 유지한채 영상 압축이 진행된다

Block-based Transform - DCT
- 블록 기반 변환 방법의 대표적인 기법
- 입력 신호를 여러 주파수 성분으로 분해하고, 이러한 주파수 성분을 나타내는 basis pattern을 사용하여 신호를 표현한다
- 각 영상이 각 basis pattern에 특성을 얼마나 많이 가지고 있는지에 따라서 변환 계수의 값이 달라진다
Forward DCT
- 시간 도메인에서 주파수 도메인으로 데이터를 변환하는 과정을 의미한다
- 이 변환은 신호 또는 이미지를 일련의 코사인 파의 합으로 분해한다
- 이 때, 각 코사인 파의 주파수는 그 코사인 파가 나타내는 데이터의 특성을 결정한다
Inverse DCT
- 주파수 도메인에서 시간 도메인으로 데이터를 변환하는 과정을 의미한다
- 이 변환은 코사인 파의 합으로 표현된 데이터를 원래의 시간 도메인 데이터로 복원한다

basis pattern
- DCT에서 사용되는 기본 패턴
- DCT는 입력 신호를 코사인 함수의 합으로 표현한다. 이 때 각각의 코사인 함수를 Basis라고 부르며, 이들의 집합을 DCT 베이시스 패턴이라고 부른다
- DCT basis pattern은 각 패턴이 코사인 함수의 다른 주파수를 나타내므로, 이미지나 신호의 주파수 성분을 분석하는 데 사용된다. 이를 통해, 데이터의 에너지를 집중적으로 표현할 수 있어, 압축 효율이 높아진다
양자화(Quantization)
- X의 범위를 가진 신호를 X의 범위보다 작은 Y의 범위를 가진 신호로 mapping하는 방법
- 디지털 이미지나 비디오에서 색상 또는 밝기 값을 제한된 수의 가능한 값 중 하나로 변환하는 과정을 의미한다
- 이 과정은 디지털 영상을 저장하거나 전송하기 위해 필요한 데이터의 양을 줄이는 데 사용된다
- Scalar quantizer와 Vector quantizer로 두 가지 방법이 있다
- 신호를 유한한 수의 레벨로 표현하기 위한 양자화 방법이다
Scalar quantizer
- 하나의 값에 대해서 연산이 이루어지고 하나의 출력이 나오는 방법
- 각 입력 샘플을 독립적으로 처리한다
- 일반적으로, 입력 샘플은 가장 가까운 '양자화 레벨'로 매핑되며, 이 레벨은 미리 정의된 집합에서 선택된다
- 이 방법은 간단하고 계산적으로 효율적이지만, 신호의 통계적 특성을 고려하지 않아서 양자화 오차가 클 수 있다
영상
- 실수를 가장 작은 정수로 rouding하는 것
- 실수를 정수로 rouding하고 다시 실수로 복원할 수 없으므로 양자화는 비가역적인 기법이기에 lossy coding이라고 할 수 있다

- Inverse quantization은 Qstep을 곱해주기 때문에 scailing이라고도 할 수 있다
- Qstep Size에 따라서 화질과 bit량이 달라지게 된다
- 크면 수행한 후에 값의 범위가 크게 줄어들어 높은 압축률, 영상 화질이 크게 감소한다
- 작으면 수행한 후에 값의 범위가 적게 줄어 낮은 압축률, 화질이 좋다
QP(Quantization Parameter)
- 양자화 파라미터
- quantization step size를 결정하는데 사용된다
QP & Qstep in H.264 and HEVC
- QP는 8비트 비디오 시퀀스에 대해서 0에서 51까지의 52개 값을 가진다
- 이 값은 양자화 강도를 나타내며, 값이 증가함에 따라 양자화 정도가 강해진다
- QP가 1증가함에 따라 quantization step size가 12% 씩 증가한다
- quantization step size에 따른 화질을 선형적으로 변화시키면서 사용자에게 원하는 화질을 제공하기 위해 이렇게 설계되었다
Vector quantizer
- 여러 입력샘플을 그룹으로 묶어서 벡터화 한 후에 하나의 양자화 값으로 매핑하는 방법
- 즉, 입력 '벡터'는 가장 가까운 '코드 벡터'로 매핑되며, 이 코드 벡터는 '코드북'이라는 미리 정의된 벡터 집합에서 선택된다
- 신호의 상관 관계를 이용하여 양자화 효율을 높일 수 있지만, 계산 복잡성이 높아질 수 있다
영상
- 인코더에서 이미지를 미리 약속된 일정한 크기의 블록들로 분할하고 그 다음 각 블록과 가장 유사한 벡터를 코드북에서 찾고 코드북에서 찾은 벡터에 대한 인덱스를 bitstream에 포함시켜 전송한다
- 디코더에서는 bitstream으로부터 인덱스를 파싱한 다음에 코드북에 저장된 벡터를 불러와서 블록을 복원하게 된다
- 이 때 복원된 블록은 코드북에서 가장 유사한 벡터를 선택한 것이므로 원복블록과 정확히 일치하지 않을 수 있다
- 따라서 코드북을 어떻게 생성하는가에 따라서 벡터 양자화의 압축 성능이 달라질 수 있다
- 코드북은 인코더와 디코더 둘 다 동일한 코드북을 가지고 있다
자료
- 입력 데이터의 집합(이미지 샘플 블록)을 단일 값(코드워드)으로 매핑하고 디코더에서 각 코드워드는 입력 데이터의 원래 집합(vector)에 대한 근사값으로 복원한다
- 코드워드 : 일반적으로 양자화된 데이터를 나타냄. 코드북에 저장
- 코드북 : 양자화된 값(코드워드)의 집합
Transform & quantization in encoder and decoder
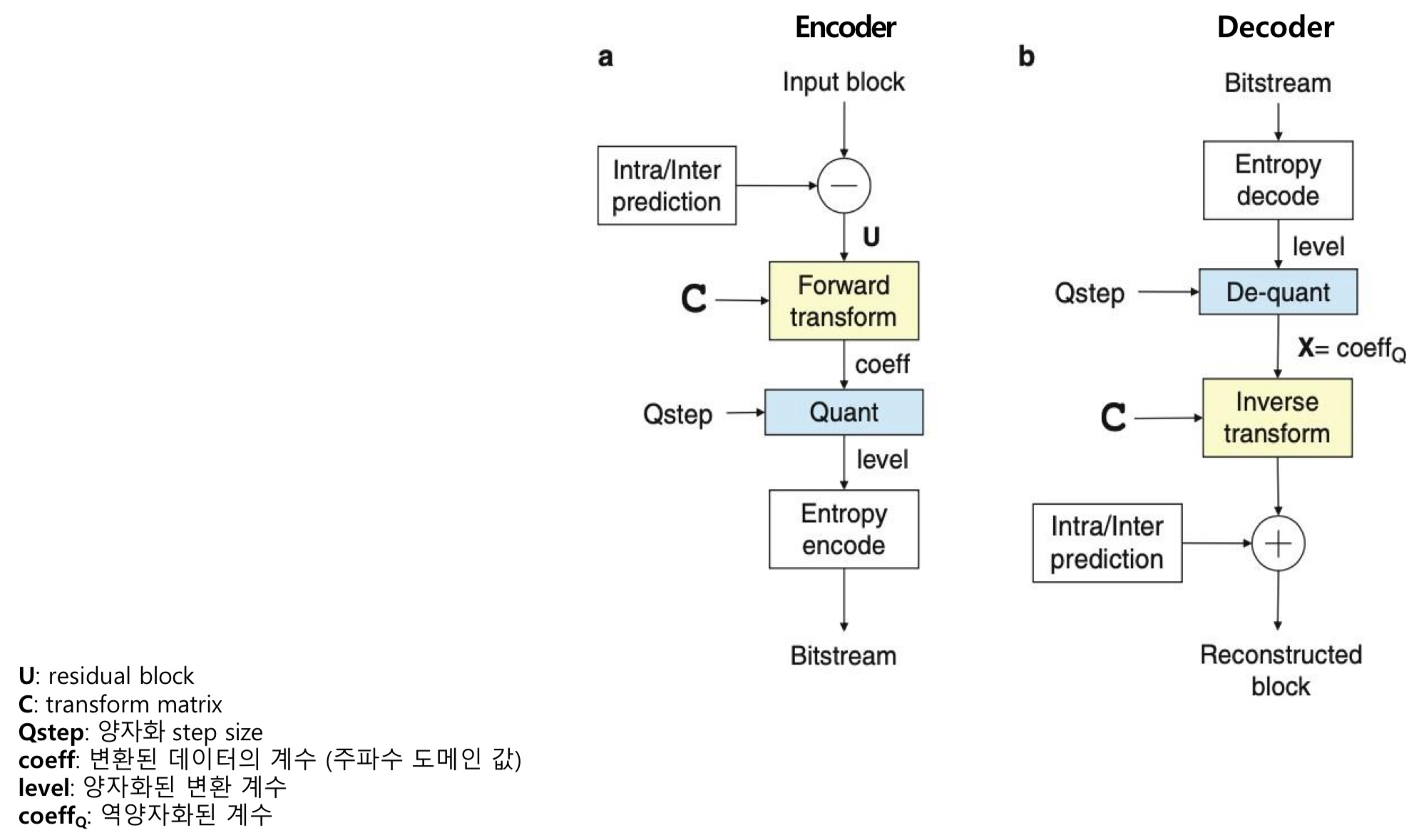
- 블록기반 비디오 코딩방법에서 Intra 및 Inter에서 발생되는 오차 신호에 대해서 변환 및 양자화 과정에 대한 그림
RQT(Residual QuadTree)
- 잔여 블록의 구조를 효율적으로 표현하기 위해 사용되는 방법이다
- QuadTree는 데이터 구조 중 하나로, 2차원 공간을 효율적으로 표현할 수 있다
- 각 노드는 4개의 자식 노드를 가지며, 이는 2D 공간을 4개의 구역으로 분할하는 것을 나타낸다
- HEVC에서, RQT는 잔여 블록의 크기와 모양을 동적으로 조정하는 데 사용된다
- 이는 비디오 데이터의 다양한 특성에 맞게 코딩을 최적화하고, 따라서 압축 효율을 향상시키는 데 도움이 된다
- 16X16 부터 64X64 크기의 가변 블록의 크기를 지원한다
- 오차 신호에 대한 변환에서도 유연한 변환 크기를 지원한다
Transform skip mode
- 기존 DCT 변환 후 고주파 부분이 양자화로 인한 손실이 발생하게 되면서 글자 혹은 선과 같이 급격한 edge로 구성되어 있을 때 잡음이 생기는 문제를 해결해주는 방법이다
- 이 모드는 특정 조건 하에서 변환 과정을 건너뛰어 압축 효율을 향상시키고 코딩 복잡성을 줄이는 데 사용된다
Frequency dependent scaling
- 이미지 블록의 주파수 성분에 따라 다른 양자화 파라미터를 적용하는 방법이다
- 이는 이미지의 특정 주파수 성분을 강조하거나 약화시키는데 사용될 수도 있다
- 양자화 행렬을 저장하는데 필요한 메모리를 줄이기 위해 16x16 및 32x32 양자화 행렬은 8x8 행렬을 통해서 생성된다
- HEVC에서 미리 정의된 default 양자화 행렬 외에 사용자가 임의로 정의한 행렬을 사용할 수 있다
- 추가적인 flags인 SPS나 PPS를 통해서 default 행렬을 사용할지 혹은 사용자가 임의로 정의한 행렬을 사용할지에 대한 정보가 전송된다
- 사용자 정의 행렬이 사용되는 경우 각 주파수 성분의 위치마다 양자화 스텝 사이즈가 bitstream에 포함돼서 전송된다
Multiple transform selection(MTS) in VVC
- 각 변환 블록에 대해 여러 가지 가능한 변환 중에서 최적의 변환을 선택할 수 있도록 하는 기능이다
Explicit MTS - 명시적
- CU_level index(mts_idx)는 어떤 변환 커널이 적용되었는지를 나타내기 위해 신호를 보낸다
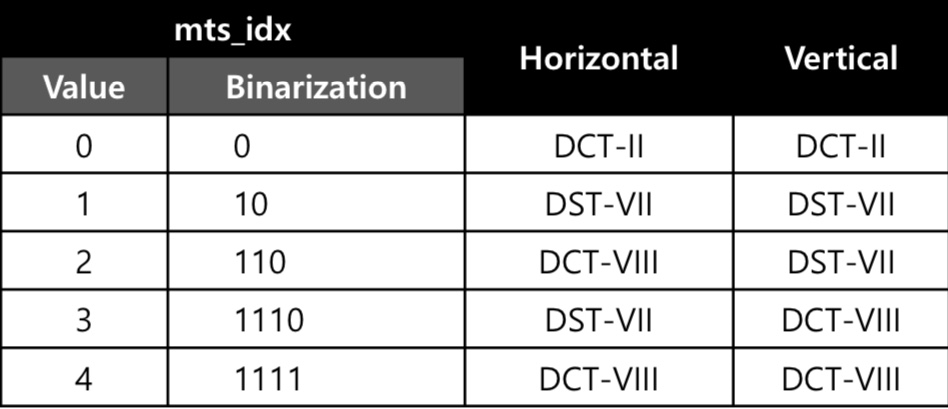
Implicit MTS - 묵시적
-
블록 크기를 기반한 경우
-
서브 블록 변환이 적용되지 않은 경우에만 동작한다
-
trTypeHor = ( nTbW >= 4 && nTbW <= 16 ) ? 1 : 0
-
trTypeVer = ( nTbW >= 4 && nTbW <= 16 ) ? 1 : 0
- 0: DCT-II
- 1: DST-VII
- 현재 블록의 가로 및 세로 크기가 4이상이고 16 이하일 때 DST-7 사용, 그 외에는 DCT-2 사용
-
-
서브 블록 변환이 사용된 경우
Sub-block transform(SBT) in VVC
- 변환 블록의 일부에만 변환을 적용하여 효과적인 신호 표현을 가능하게 한다
- 기본적으로, 전체 변환 블록에 대해 단일 변환을 적용하는 대신, SBT는 변환 블록을 두 개의 하위 블록으로 분할하고, 각 하위 블록에 대해 별도의 변환을 적용한다
- 이를 통해 각 하위 블록의 특성에 맞게 적절한 변환을 선택할 수 있어, 변환 효율이 향상된다
- 화면간 예측된 CU에서만 허용한다
VVC에서의 2차 변환
- 주로 잔차 블록의 변환을 향상시키는데 사용된다
- VVC에서, 첫 번째 변환 단계는 주로 예측 오류 즉, 원본 블록과 예측 블록 간의 차이를 인코딩하는데 사용된다
- 이후, 2차 변환은 이 첫 번째 변환 단계 후의 잔차 블록에 적용된다
- 2차 변환은 첫 번째 변환 후에 여전히 존재하는 블록 내의 패턴을 더 잘 표현하도록 설계되어 있다. 이는 특히 첫 번째 변환 단계에서 완벽하게 제거되지 않은 블록 내의 고주파 성분을 인코딩하는데 유용하다
Low-Frequency Non-Separable Transform(LFNST)
- 주로 저주파 영역의 신호를 처리하는 데 사용되며, 변환의 결과는 별도로 분리할 수 없다
- 이 변환은 대부분의 에너지(즉, 정보)가 저주파 영역에 집중되는 신호나 영상에 특히 유용하다
- 주파 비분리 변환의 결과는 분리할 수 없다는 점에서 다른 주파수 변환과 차별화된다. 이는 변환의 결과를 별도의 부분으로 분리하여 각 부분을 독립적으로 처리할 수 없다는 것을 의미한다
- 이러한 특성 때문에, 이 변환은 신호의 전체적인 구조와 패턴을 유지하는 데 더 유리하며, 따라서 신호의 전체적인 특성을 보존하는 데 중요한 역할을 한다
- DCT-2를 사용하는 화면내 예측 블록에서만 적용한다
- MIP 및 ISP에서는 사용되지 않고 있다
- Intra Prediction mode에 따라서 LFNST mode set가 설정된다
- 하나의 LFNST set에는 두 개의 LFNST 커널이 있다
VVC에서의 양자화
- 저비트율을 지원을 위해서 양자화 파라미터의 최대값이 51에서 63으로 확장했다
- Dependent Quantization을 지원한다
Dependent Quantization
- 정 조건에 따라 양자화 단계 크기를 조정하는 프로세스를 나타낸다
- 일반적으로 코딩 효율을 향상시키기 위해 사용된다
- 예를 들어, 특정 블록이 높은 에너지를 가지고 있거나, 주변 블록과 유사한 패턴을 가지고 있을 경우, 이 블록에 대한 양자화 단계 크기를 줄여 더 정확한 표현을 가능하게 할 수 있다
- 반대로, 낮은 에너지를 가지거나 주변 블록과 다른 패턴을 가진 블록에 대해서는 양자화 단계 크기를 늘려 데이터를 더 많이 줄일 수 있다
출처 및 참조
- MPEG뉴미디어포럼/한국방송∙미디어공학회 2023 Summer School
- 김경용, Ph.D., (주)윌러스표준기술연구소

공부 기록