
- 오늘은 딥러닝 모델 학습 시
기울기 폭발(Gradient Exploding)을 방지하는Gradient Clipping에 대해 알아보자!
Gradient Clipping
-
그레디언트 클리핑은 단어 그대로 기울기를 자르는 역할을 담당한다.
-
사실 클리핑은 모델 학습 시, 필수 요소는 아니고 필요한 경우에 사용!
-
그럼 어떤 매커니즘이고 어떻게 적용되는 지, 그 과정에 대해 살펴보자
학습 방향과 크기, 규제에는 Learning Rate, Weight decay 등 다양한 요소가 결합되어 학습의 방향, 강도가 결정되지만 해당 포스팅은 기울기 클리핑의 관점에서만 설명한다.
모든 파라미터 기울기 벡터 g의 L2 Norm
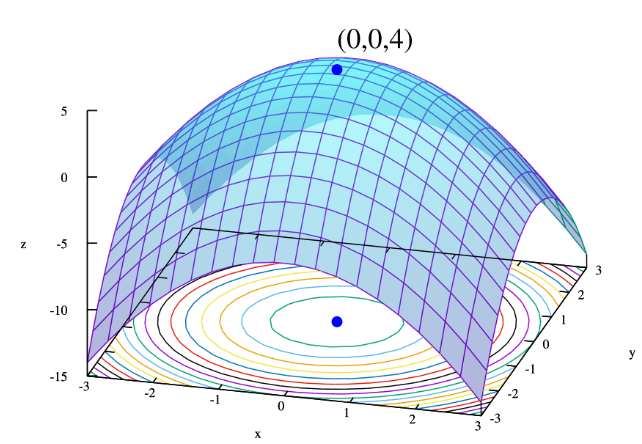
- 모델 학습은 아래 그림과 같은 n차원의 공간에서 손실(loss)가 가장 작은 지점을 향해 가는 과정이다.
- 이때 모든 파라미터의 기울기 벡터를 g라고 하면, 는 학습 과정에서 전역 최저점으로 향하는
방향,강도정보를 갖는다.
- n차원에서
n은 해당 모델 파라미터의 모든 개수를 의미
- 이때 모든 파라미터의 기울기 벡터를 g라고 하면, 는 학습 과정에서 전역 최저점으로 향하는
- 파라미터가 업데이트에는 의
L2 Norm이 반영된다.L2 Norm-
피타고라스 정리 )를 n차원으로 확장한 개념이라고 생각하면 된다.
-
각 파라미터의 기울기()는 각 축(axis)의 이동량을 나타낸다.
-
즉, 이들이 모인 의
L2_norm은 다음 업데이트의 강도를 나타낸다.
-
- 의 L2 norm
그렇다면 Clipping은 언제 사용될까?
클리핑과 max_norm
-
각 파라미터의 기울기가 너무 커지면 의 L2 norm도 커지고, 이는 업데이트 강도가 너무 강해져
학습 불안정을 야기한다. -
클리핑은
이러한 기울기 폭발로 인해 불안정한 학습을 방지하는 역할이다. -
그럼 어떻게 적용될까?
-
클리핑은 적용 시 인자로
max_norm을 사용한다. -
max_norm은 의 L2 norm의 최대치를 지정
-
즉, max_norm 값을 넘을 때 기울기 클리핑 적용
Example)- max_norm = 1.0, = 10인 경우
- 로 개별 기울기 정규화를 수행한다.
- 즉,
- max_norm = 1.0, = 10인 경우
-
- 위 예시를 아래와 같이 표현할 수 있다.
💡정리
-
클리핑은 학습 안정성을 위해 중요한 요소이지만, 오히려 학습을 방해할 수도 있다.
-
모델 학습에는 여러 기술이 있을 뿐 정해진 템플릿은 없기 때문에,
-
클리핑 적용을 선택하기 위한 가장 확실한 방법은 각 배치별
grad_norm값을 출력하여 확인해야한다.- 스텝별 grad_norm이 max_norm 값을 계속 유지한다면?
Saturation(포화)를 의미클리핑을 사용하지 않거나 max_norm을 올려주는 것이 좋다.
- 스텝별 grad_norm이 max_norm 값을 계속 유지한다면?

Data Scientist & Data Analyst