최근 임베딩 벡터를 공부하면서 어디에 활용할 수 있을 지 찾아보다, 추천시스템(recommendation system)이라는 곳에 활용 할 수 있다는 점을 발견 했다.
추천 시스템은 우리가 실생활에 많이 접하고 있는 부분이다. 간단히 말해 상품 추천, 영화 / 드라마 추천 등 우리가 선호하고 관심 있어 하는 아이템을 추천해주는 시스템이다.
오늘 볼 논문은 추천 시스템에 대한 대략적인 개요, 사용 기술과 CHARM 알고리즘에 대해 설명하고 있다.
1.Introduction
웹 추천 시스템은 방문자들이 원하는 웹 페이지를 쉽게 찾을 수 있도록 길잡이 역할을 해준다.
추천 시스템에는 흔히 두 가지 유형이 존재
1) 콘텐츠 기반 방법 (선호하는 콘텐츠 추천)
2) 협업 필터링 기반 방법 (비슷한 성향의 다른 유저를 기반으로 추천)
이 있다.
먼저 1) 콘텐츠 기반 방법에 대해 설명.
1)의 방법은 현재 시점보다 이전에 쌓인 데이터 (즉, 논문에선 ancient DB라고 언급)를 기반으로 추천
ancient DB는 question과, ratings로 구성된다.이 방법의 단점은 기존 사용자들의 척도를 기반으로 추천하기 떄문에 적절하지 않은 추천이 나올 수 있는 단점이 존재
2) 협업 필터링 기반 방법 설명
web 서버 또는 DB에 저장 되어 있는 사용자들의 흥미에 관한 모든 정보를 수집한 뒤, 사용자들 간의 유사도를 계산
그리고 비슷한 특성을 가진 사용자는 같은 카테고리로 묶음해당 방법은 sparsity, scalability 2가지 단점이 존재
sparsity
-->값이 0인 데이터가 많을 때 발생하는 문제이다.
모든 사용자가 모든 부문에 흥미를 갖는 게 아니기 때문에 데이터가 측정되지 않거나 누락 된 경우 존재
(즉, 0의 값이 많이 존재하면 유사도를 구하지 못하는 단점이 존재)scalabilty
--> 유사도를 계산해서 추천을 하면 비교적 정확한 추천이 가능하지만 이는 사용자들의 유사도를 전부 계산해야하기 떄문에 계산량이 방대해지는 단점이 존재.
(즉, 실시간의 경우 적용할 수 없는 문제 발생)
2. COLLABORATIVE FILTERING TECHNIQUES(CF TECHNIQUES)
협력 필터핑 기술은 추천 시스템에서 아주 중요한 역할이다.
많은 수의 사용자와 아이템을 다루기 위해, 그리고 짧은 시간 내에 알맞은 추천을 하기 위해
cold start problem (쉽게 말해 새로 유입된 사용자)
synonymy (이음동의어 문제)
data noise
sparse 비율이 높은 데이터 등 여러 문제점을 맞닥뜨리게 된다.
basically CF 기술은 세 가지(A, B, C)로 나누어진다.
A. Memory-based collaborative filtering technique
1) (user - item) 간의 complete data를 기반으로 추천한다2) 대개 이웃(neighbors)의 데이터를 이용함
B. Model based collaborative filtering technique
1) a의 단점을 극복하기 위한 방법
(실시간 대응, 속도 느림, complete data가 필요한 문제)
2) 극복 위해 model이라고 불리는 작은 datasets 이용 --> 여기서 말하는 model(small datasets)는 huge datasets로 부터 특정 parameter/attribute 관련한 필요 정보만 추출 한다. (for 효율성, 속도 향상)--> 쉽게 말해, 작은 훈련용 데이터셋(model)로부터 복잡한 패턴을 인식하고 테스트 데이터 또는 real-world 데이터에 적용하여 추천을 제공
--> B 방법은 Bayesian Models, Cluster-based CF, regression-based methods 등의 방법을 포함한다.
C. Hybrid recommendation technique
--> CF와 타 추천 기술을 결합한 방법으로 , 성능이 좋아서 최근에 많이 쓰임--> 하이브리드 추천 기술도 두 가지로 나뉨
- 모든 전처리 방법을 포함 (데이터 정제, 변환, 정규화 등) 품질이 좋은 데이터로 만듦(좋은 질의 데이터 -> 알맞은 추천)
- all rule finding. 즉, 모든 연관 규칙을 찾아낼 수 있음
1, 2 이유로 하이브리드 추천 기술은 예측 성능 향상!
3. PROPOSED METHODOLOGY
효율적인 웹 페이지 추천을 위한 방법 제안
cluster datasets에 CHARM 알고리즘 적용
(cluster dateset으로 부터 all closed itemset 빠르게 찾기 가능)CHARM 알고리즘?
--> 대용량 데이터를 다룰 수 있는 frequent pattern finding 알고리즘
--> closed frequent itemset을 찾을 수 있는 알고리즘
(closed datasets은 이 포스팅 맨 마지막과 추후 포스팅 통해 설명)제안한 방법
1) 데이터 준비 (또는 데이터 전처리, 웹 마이님 분야에서 혼용됨)
2) 웹 로그 파일 클러스터링
3) 연관 규칙 결정
(연관 규칙 ex - "A가 발생하면 B가 발생한다"와 같은 형태로 표현)
4) 웹 페이지 추천
제안한 모델의 프레임워크
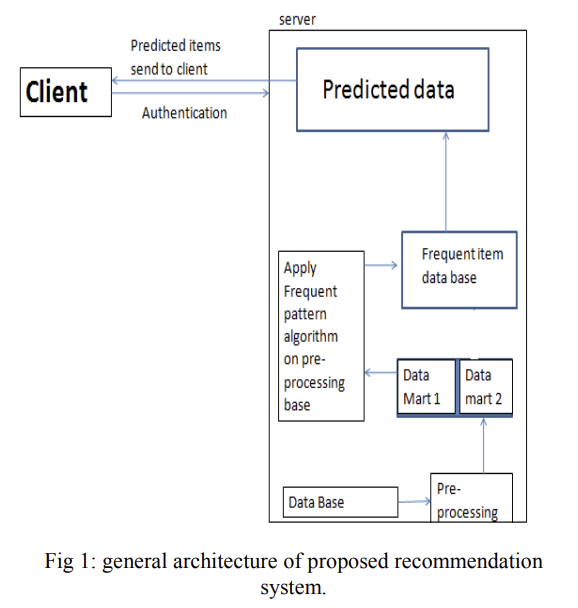
제안 방법 4가지 설명
1) 웹상에서 사용자의 상호작용은 웹 로그 파일(plain text)형태로 웹 서버에 기록되는데, 웹 로그 파일을 데이터 처리 없이 바로 사용하기엔 어렵기 때문에 전처리 진행
2) 웹 로그 파일 전처리 진행 후,
k-means, k-medoids와 같은 클러스터링 알고리즘 적용
3) 연관 규칙 결정
-> 연관 규칙은 all closed frequent itemsets을 찾는 게 중요
-> 이전에 말한 CHARM 알고리즘이 효율적으로 all~ ~ itemsets을 찾음
-> CHARM 알고리즘의 장점은 중복 규칙을 제거한다는 점!
(중복규칙 제거가 예측의 quality와 time을 향상 시키기에 효율적)
4) 웹 페이지 추천
-> 특히 새로운 사용자는 사용자의 웹 페이지 경로를 CHARM 알고리즘과 비교하고 posibility definition과 비교하여 추천
(CONCLUSION은 앞서 내용 반복이라 생략)
Closed itemsets
- PROPOSED METHODOLOGY에서 언급한 closed itemsets 추가 설명
closed itemset은 폐쇄 아이템셋으로, 연관 규칙을 찾는 기준이 된다
closed itemsets을 마트로 예를 들어 설명
-->
우유,식빵 항목을 담고 있는 X itemsets
우유,식빵,수박 세 항목을 담고 있는 Y itemsets
많은 사람이 우유와 식빵을 같이 사는 경향이 있다고 가정,
연관 규칙을 발견 하기 위해 지지도(support)를 계산한다고 했을 때,
{우유, 식빵}의 지지도가 {우유, 식빵, 수박}의 지지도가 같다면
X가 폐쇄 데이터셋이 된다.
단순히 수치로 폐쇄 데이터셋을 판단하는 것이 아니라,
X와 Y 같이 부분집합의 관계에서 subset(X)와 superset(Y)의 지지도가 같은 상황에서!
subset인 X가 폐쇄 데이터셋이 되는 것이다(rule 찾기 위해 더 작은 범위의 규칙으로 압축하는 느낌)
closed itemset에서는 다음 추천시스템 포스팅에서 정리!
