
-
트랜스포머는 지난 2017년 NIPS에서 Transformer: attention is all you need라는 제목의 논문으로 처음 등장 하였다.
-
RNN과 LSTM을 사용한 모델과는 달리 트랜스포머는 약 3년 전에 나온 어텐션 매커니즘을 기반으로 하는 새로운 구조(아키텍처)를 제안했다.
-
오늘은 이 트랜스포머의 인코더의 구조 연산 과정에 대해 알아보고자 한다.
포스팅 이미지, 정보 등
1. Transformer 등장 배경
-
기존의 seq2seq 구조는 인코더를 지나면 하나의 context vector를 통해 입력 문장의 정보가 압축 되었다.
물론 압축된 것이 장점일 수도 있지만, 압축 된다는 것은 정보 소실이 발생할 수 밖에 없기 때문에 만에 하나 중요한 특징이 소실 된다면 큰 단점으로 작용할 수 있다. -
때문에 어텐션 매커니즘을 보정 수단으로 사용하는 것이 아니라 어텐션 만으로 인코더와 디코더를 구성하는 구조를 트랜스포머가 제안
2. Transformer 구조
- 트랜스포머(
병렬)는 seq2seq(순차적)의 가장 중요한 차이는 시퀀스 처리 구조라고 할 수 있다.
- 병렬 처리는 어떻게 하는걸까??
- Seq2Seq는 입력 단어를 동일한 임베딩 과정을 통해서 임베딩 벡터 생성 후,
이 벡터를 각 시점마다 입력으로 사용 - 트랜스포머는 병렬처리를 위해
순서 정보 보존을 위한 포지셔널 인코딩(positional encoding)을 사용한다.
- Seq2Seq는 입력 단어를 동일한 임베딩 과정을 통해서 임베딩 벡터 생성 후,
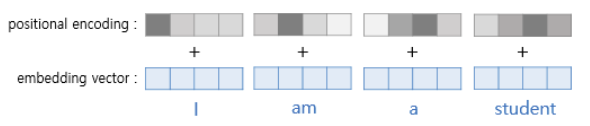
포지셔널 인코당(positional Encoding)"i am a student"를 예로 들어 설명
-
위 그림에서 알 수 있듯이 문장 내 단어의 위치에 따라 각기 다른 위치 정보 값을 더해줌으로써 위치 정보를 추가할 수 있다.
-
여기서 자세히 설명하진 않겠지만 위치별 포지셔널 인코딩 값은 sin함수와 cos함수와 같은 주기함수를 사용하여 값을 지정
-
그렇다면 트랜스포머를 이루는 인코더에 대해 더 자세히 알아보자!
3. Encoder
-
트랜스포머의 인코더는 하나의 인코더 모듈이 N번 반복되어 쌓인 구조이고, 여러 인코더 모듈은 구조가 같기 때문에 하나의 인코더 모듈을 살펴보자
-
아래 그림은 인코더 모듈의 내부 구조를 보여준다.
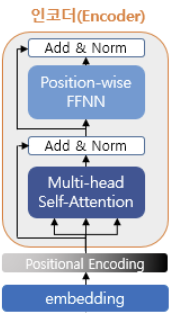
- 하나의 인코더는 세부적으로
2개 sub-layer로 나눠진다.
->self-attention,FFNN
- 이전 결과가 입력으로 들어오면 멀티 헤드 셀프 어텐션을 통해 가중치를 더 부여해야할 단어를 파악할 수 있다.
- self-attention layer를 지난 결과는 FFNN층을 지나고 한 개의 인코더 결과를 내놓는다.
- 하나의 인코더는 세부적으로
- 인코더에서 self-attention, multi-head attention, add & Norm의 역할
Self-Attention
- 어텐션 매커니즘을 적용하는 세 가지 중 하나의 방식으로, 문장 내에서 '자기 자신'을 참조하여 문맥 정보를 추출
즉, 해당 단어의 의미를 파악하는 데 중요한 문맥 정보를 찾는 것이 핵심<br>(하나의 단어(Q)가 문장 내 다른 단어(K)들과 얼마나 관련 있는지 측정하고 해당 가중치(V)를 반영)
Multi-Head Attention
- 어텐션 헤드란, 멀티 헤드 어텐션 내에서 병렬적으로 어텐션 계산을 수행하는 하나의 단위를 말함
- 입력 벡터를 여러 개의 작은 조각으로 분할하여 각 조각이 서로 다른 관점에서 병렬적으로 어텐션을 수행한 결과를 의미
(=여러 관점에서 보는 것과 같음)(=개별 어텐션 헤드 결과를 통합)
Add & Norm
- 잔여 학습(Residual learning)을 의미하고, 이를 이용하여 기울기 소실/폭발 방지하여 깊은 네트워크 구성
- 정규화(Norm) 과정을 통해 안정성과 수렴속도 높임
-
하나의 인코더를 통해 나온 결과는 다음 인코더의 입력으로 사용되며 총 N개의 인코더 모듈을 통과한 최종 결과는 다시 디코더에서 Decoder-Encoder attention에 사용된다.
-
꼭 최종 인코더의 결과가 아니어도 각 인코더의 결과만 따로 추출하여 사용하기도 한다. (이론상 각 층이 파악하는 정보가 다르기 때문)
- example)
- 1~2층: 단어 순서(order) 정보
- 3~4층: 단어 문법(Syntactic) 정보
- 5~6층: 단어 의미(Semantic) 정보
- example)
-
또한 트랜스포머의 인코더만 사용하는 BERT와 같은 모델로 단어별 임베딩, 문장 임베딩을 생성하여 regression, classification, Clustering task에 사용할 수 있다.
