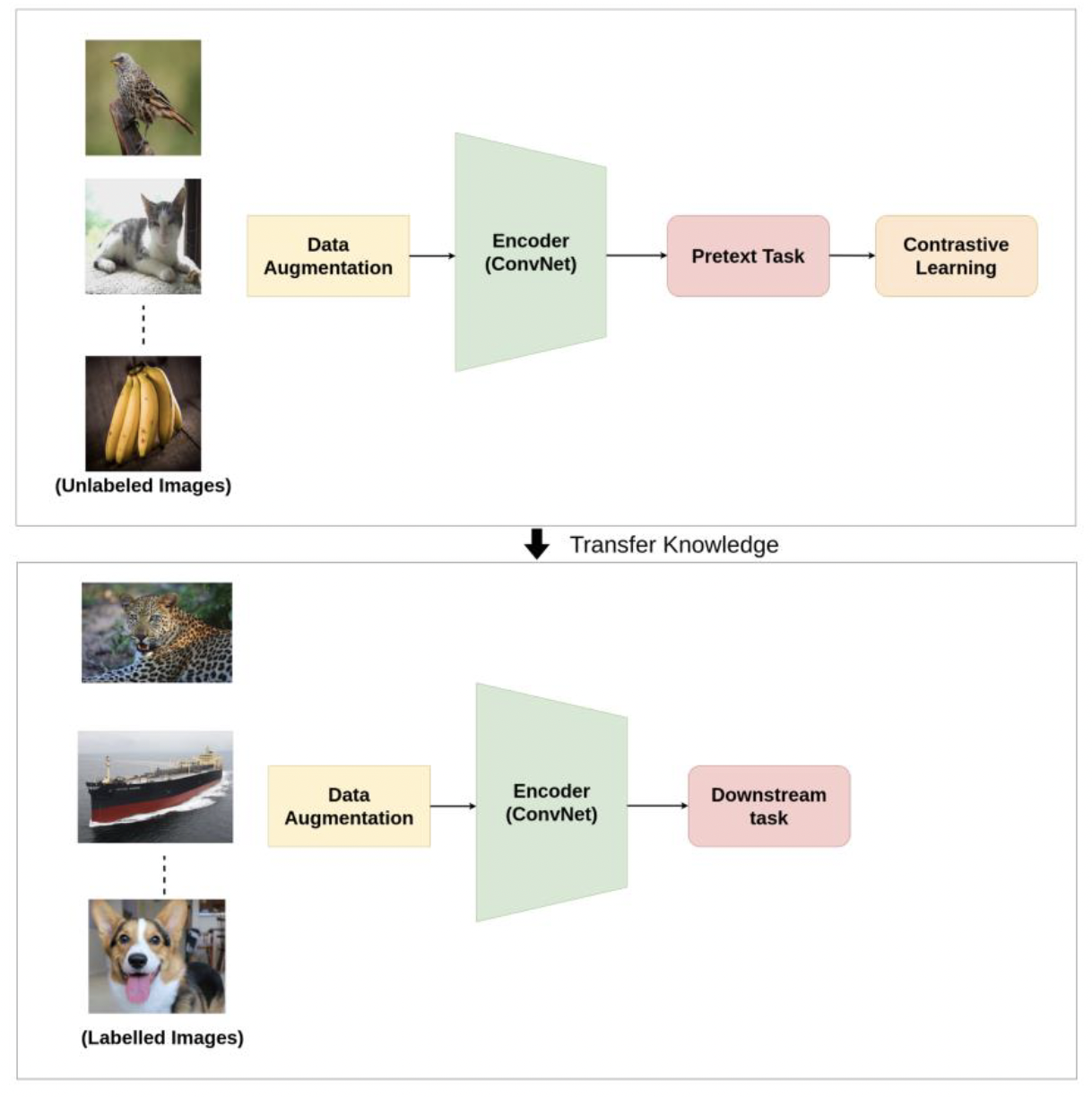
- 개괄
1) Constrative Learning이란
입력 샘플간의 비교를 통해 학습하는 방법.
self supervised learning 방법 중 하나로, 사전에 라벨을 구축하지 않는 판별 모델이다.
label이 없기 때문에 데이터 구축 비용이 적게 든다는 점 외에도
- 보다 일반적인 feature representation과
- 새로운 class에 대한 대응
이 가능하다는 장점이 있다.
2) Representation Learning
(1) 생성 모델 활용 방법
un supervised learning이기 때문에 데이터 구축 비용이 적게 듦.
저차원 학습을 표현하는 데 있어서 목적 함수가 보다 일반적임.
(2) 판별 모델 활용 방법
계산 비용이 적고, 비교적 학습이 용이함.
라벨링 데이터를 활용하기 때문에 데이터 구축 비용이 많이 듦.
클래스 판별이 목적이기 때문에 보다 지엽적인 목적 함수임.
(3) Contrastive Representation Learning이란
여러 입력 쌍에 대해 유사도를 라벨로 판별 모델을 학습함.
즉, 학습된 표현 공간 상에서 비슷한 데이터는 가까이, 다른 데이터는 멀리 위치하도록 학습하는 방법.
다른 task로 fine tuning할 때 모델 구조 수정 없이 이뤄질 수 있어서 간편함.
- Example - Instance Discrimination
Unsupervised Feature Learning via Non-Parametric Instance Discrimination(Zhirong Wu et al., 2018)에서 처음 제안된 CRL Task이다.
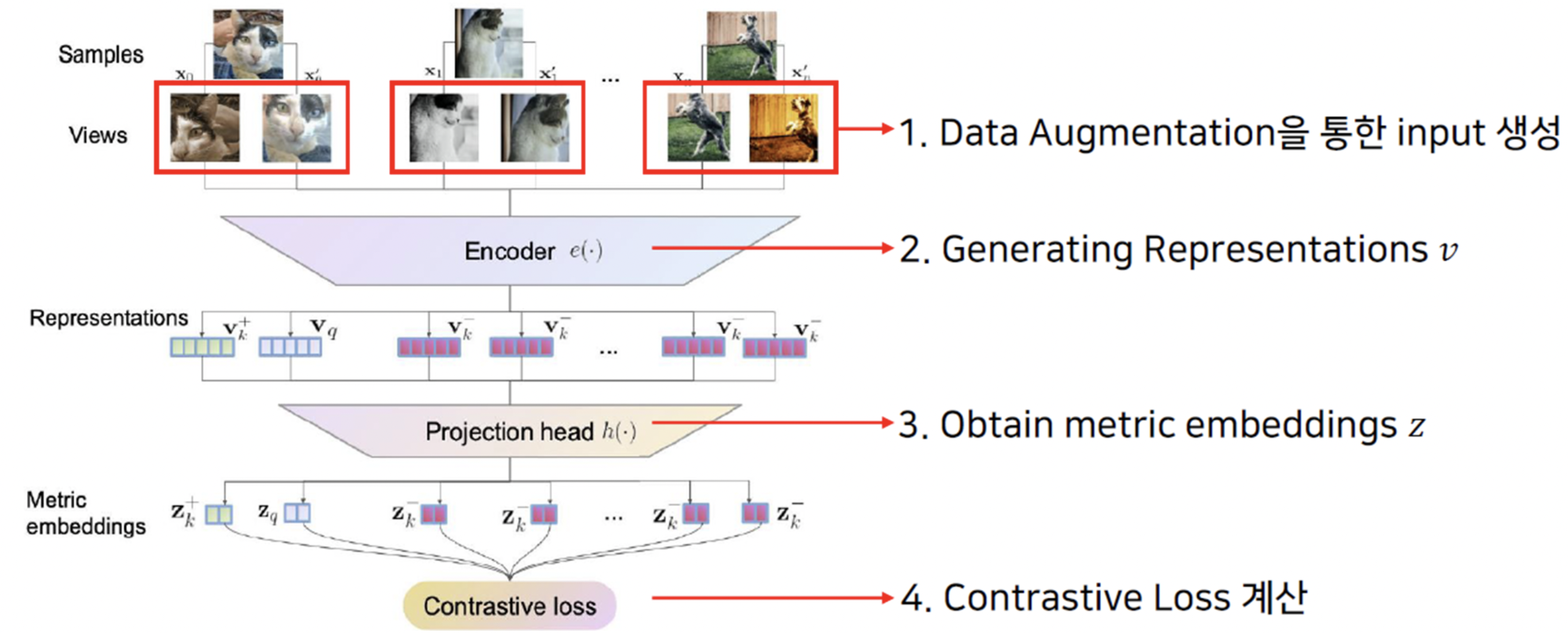
1) Data Augmentation을 통한 positive pair, 다른 이미지와의 negative pair 생성
- 이때 Semantic을 훼손하지 않으면서 특정 level에 한정되지 않는 Augmentation을 주는 것이 중요하다.
2) Generating Representation (=Feature Extraction) - Encoder로는 어떤 backbone을 써도 괜찮다. 위 논문에서는 ResNet-18을 사용했다.
3) Projection Head
2)에서 얻은 Representation vector의 차원을 줄여주는 과정이다. 보통 간단한 MLP를 쓰고, unit vector normalization을 해준다.
이 벡터로 이후 Constrative metric(loss)를 계산하기 때문에 feature representation space에서 metric space로 projection 했다고도 생각할 수 있다.
4) Loss 계산
InfoNCE, NT-Xent 등이 많이 쓰인다. infoNCE (NCE stands for Noise Constrative Estimation)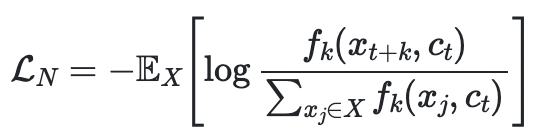
one positive sample ~ p(x_t+k | c_t), N-1 negative sample ~ p(x_t+k)일 때 infoNCE에 따라 최적화하면
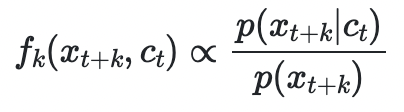
가 된다.
출처
https://daebaq27.tistory.com/97
https://paperswithcode.com/method/infonce

:):):)