(작성중) Improving Generalization in Federated Learning by Seeking Flat Minima (FedASAM+SWA)
관련 개념 조사
Federated Learning
아래 글은 해당 글을 정리하였습니다...
https://medium.com/curg/%EC%97%B0%ED%95%A9-%ED%95%99%EC%8A%B5-federated-learning-%EA%B7%B8%EB%A6%AC%EA%B3%A0-%EC%B1%8C%EB%A6%B0%EC%A7%80-b5c481bd94b7
다수의 local client와 하나의 중앙 server가 협력하여 데이터가 탈중앙화된 상태에서 글로벌 모델을 학습하는 기술. 데이터 프라이버시와 커뮤니케이션 효율성 향상을 꾀할 수 있다.
완전 탈중앙화 학습 (Fully Decentralized Learning)
연합 학습은 기본적으로 중앙 서버에서 로컬 업데이트를 받아 글로벌 모델을 수정하는 방향으로 진행됨. but 단일 서버 모델이기 때문에 단일 장애 시점(Single Point of Failure) 문제가 있고, 항상 서비스 가능한 상태는 아니다.
완전 탈중앙화 학습 (Fully Decentralized Learning)은 이를 해결하기 위해 네트워크의 커뮤니케이션 방식을 Peer to Peer Network Network 형태로 변경한다. 네트워크의 모든 노드는 그래프 형태로 연결되어 있고, 한 번의 학습 단계마다 자신의 로컬 업데이트를 연결된 이웃 노드와 교환하는 방식으로 글로벌 모델을 생성한다. 이 탈중앙 학습에서는 P2P 네트워크를 이용하기 때문에 직면하는 몇가지 문제가 있다.
-
네트워크 토폴로지 및 비동기 통신 문제
탈중앙 학습에서는 가용성이 제한된 환경에서도 학습을 잘해야 한다. P2P 네트워크는 참여 및 이탈이 자유롭기 때문에 네트워크 구성이 매번 바뀔 수 있고, 특정 노드의 통신이 불안정할 수도 있고, 메세지에 지연이 생기는 비동기 상황이다. 즉, 일반화하면 모든 노드가 완전하게 연결되어 있지만 메세지가 특정 확률로 도달하지 않는 상황에서도 견고함(robustness)를 가져야 한다. 이에 대한 대표적인 논문으로 MATCHA가 있다. -
탈중앙 SGD의 로컬 업데이트 문제
연합 학습에서는 로컬 디바이스에서 몇 번 로컬 업데이트를 한 후에 글로벌 모델과 커뮤니케이션 할건지를 결정해야 한다. 일반적으로 매 로컬 업데이트마다 다른 기기와 커뮤니케이션하는 것이 Non-IID 데이터 환경에서 수렴이 잘 된다고 알려져 있다. 하지만 이 경우 통신 비용이 증가하기 때문에 빠르게 수렴하는 것은 어렵다. -
신뢰 문제
참여와 이탈이 자유로운 P2P 네트워크로 이뤄진 탈중앙 연합 학습에서는 악의적인 공격자와 신뢰할 수 없는 데이터를 가지고 학습하는 상황도 고려해야 한다. -
개인화 (Personalization)
개인화란 연합 학습으로 생성된 글로벌 모델을 각 로컬 디바이스의 용도에 따라 변형하여 사용하는 것이다. 간단하게 UserContext 값을 입력 값에 추가하기도 하고, 최근에는 글로벌 모델을 로컬에서 fine-tuning하기도 한다.
분산 학습과 연합 학습
연합 학습은 기업 및 단체가 연합하는 Cross-silo FL과 로컬 디바이스가 연합하는 Cross-device FL로 나눌 수 있다. 분산 학습은 데이터가 여러 서버에 분산되어 저장되어 있을 때 학습하는 것을 말한다.
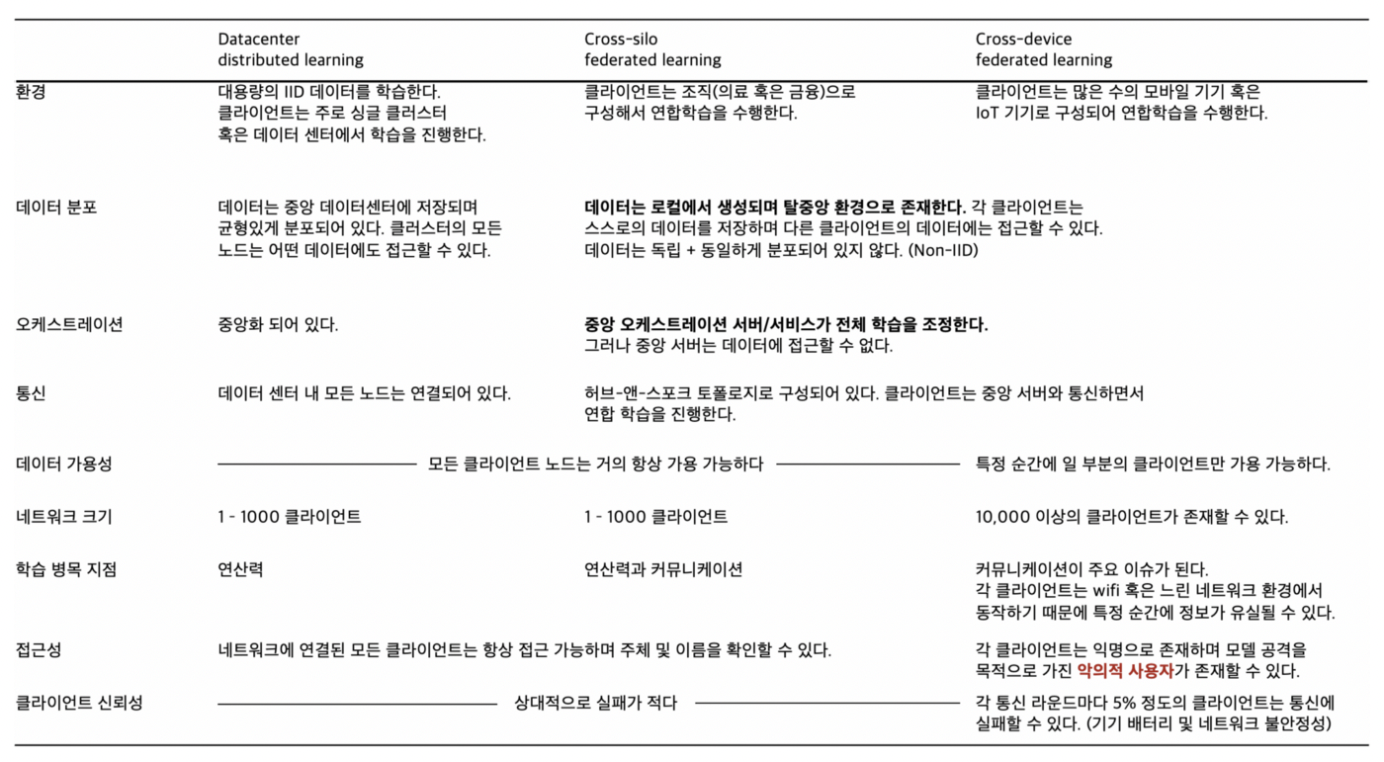
Cross-device FL에서는 클라이언트가 익명이고, 이기적으로 연산력을 아껴서 각 라운드에 가짜 정보를 제공하거나, 모델 공격을 목적으로 악의적인 정보를 제출할 수 있다. 네트워크가 불안정하여 각 학습마다 원활한 통신이 안될 수도 있다. 이러한 상황에서도 견고한 연합 학습 알고리즘을 만들어야 한다.
효율성 높이기 (Improving Efficiency)
연합 학습은 데이터는 공유하지 않으면서도 모든 데이터셋을 학습한 글로벌 모델을 만드는 것이 최종 목표이다. 하지만 각 로컬 디바이스의 데이터는 Non-IID(Independent and Identically Distributed)이기 때문에 글로벌하게 최적화된 모델을 만드는 데에 어려움을 겪고 있다.
이를 해결하기 위해 실용적 측면에서는 각 클라이언트가 자신의 데이터 일부를 중앙 서버에 제출하여 사용할 수 있는 공용 데이터셋을 만들어볼 수 있다. 하지만 이는 데이터의 보안성을 훼손함으로 부적절하다. 최근 CURG에서는 이를 해결하기 위해 데이터 증류(Dataset Distillation)을 제안하였다.
연합 학습의 효율성과 관련된 문제 중에는 Non-IID 외에도 커뮤니케이션 비용 문제가 있다. 모바일 디바이스의 네트워크는 대역폭이 낮고 불안정하기 때문에 레이턴시가 생겨 학습 속도가 크게 떨어질 수 있다. 이를 해결하기 위한 대표적인 방법으로는 Google에서 제안한 FedAvg: Federated Averaging이 있다.
실패와 공격에 대한 안전성
머신러닝에는 기본적으로 단순 버그, 데이터 노이즈, 비신뢰 환경과 적대적 공격(Adversarial Attack)에 의한 실패 가능성이 존재한다. 연합 학습에서는 여기에 한 가지 공격 요인이 추가된다.
머신러닝은 공격자가 Input과 Output만을 볼 수 있는 블랙박스 시스템이다. 하지만 연합 학습은 중앙 서버가 모든 클라이언트에게 모델 값을 브로드캐스팅하므로 공격자가 파라미터 값을 직접 볼 수 있는 화이트박스 시스템이다. 이에 대해 크게 진행된 연구는 없다. 연합 학습을 비롯한 머신러닝 공격은 크게 Model update poisoning, Data poisoning, Evasion attack으로 나눌 수 있다.
-
Model update poisoning
모델 파라미터 자체를 수정하는 공격이다. 특정 input에 대해서만 성능을 저하시키는 targeted attack과 모델 자체의 성능을 낮추는 untargeted attack으로 나눌 수 있다. -
Data poisoning
학습 단계 이전에 데이터 자체를 오염시켜 학습이 의도하지 않은 방향으로 이뤄지게 하는 공격이다. targeted & untargeted attack 모두 수행할 수 있다. 가장 흔한 패턴은 특정 뉴런을 학습 단계에서 제외하는 network pruning이다. 특정 영역에 흰색, 검은색 patch를 붙이는 것만으로도 뉴런의 활성화 정도를 결정할 수 있다.하지만 연합 학습에서는 전체 학습 프로세스를 다루는 중앙 서버는 클라이언트 데이터에 접근할 수 없으므로 오염된 데이터를 제거할 수는 없다. 또 중앙 서버는 클라이언트가 공격 당해 해당 로컬 데이터가 오염되었는지 알 수 없다. 연합 학습에서 해당 클라이언트의 데이터가 오염되었는지 선별하는 과제는 아직 해결되지 않았다.
-
Evasion attack
Evasion attack은 배포된 모델에 통과시킬 데이터 샘플을 조정하여("Adversarial Sample") 의도하지 않은 결과를 만들어내는 공격 방법이다. 사람은 구분할 수 없는 약간의 노이즈를 추가해 loss function 값이 최대가 되게 할 수 있다. 특히 연합 학습에서는 공격자가 전체 네트워크에 공유된 모델의 파라미터 값을 볼 수 있으므로 이 공격이 훨씬 수월하게 이뤄질 수 있다.
Hessian eigenspectrum
논문 선정 이유
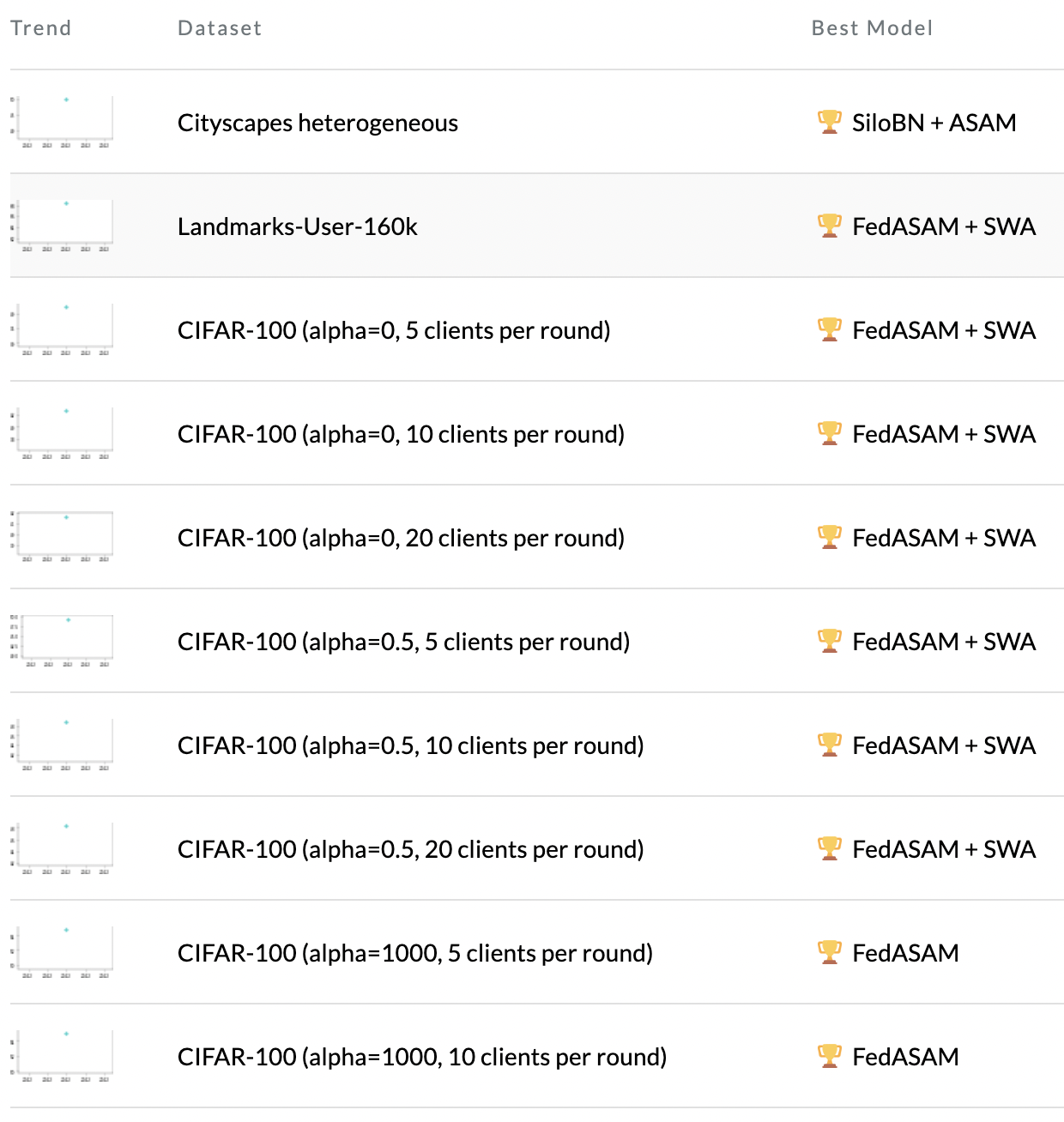
한 모델이 sota를 거의 다 찍었길래... 궁금해졌다. 근데 논문이 어떻게 37페이지...
Abstract
연합 상황에서 학습된 모델은 종종 heterogeneous scenarios를 만날 때 generalizing에 실패하고 성능이 저하되는 어려움을 겪는다. 우리는 모델의 generalization capacity 부족을 sharpness of the solution에 연관지으며 이를 loss의 geometry와 Hessian einspectrum의 관점에서 보고자 한다.
우리는 클라이언트를 로컬에서 Sharpness-Aware Minimization (SAM)이나 SAM의 adaptive version (ASAM)으로 학습하고, server-side에 averaging stochastic weights(SWA)를 적용하는 것이 FL에서의 generalization을 높이고 centralizes model과의 차이를 줄일 수 있게 해준다는 걸 보였다. 파라미터를 uniform low loss를 갖는 neighborhood에서 찾는 것은 모델이 flatter minima로 수렴하게 하여 homo/hetero scenario 모두에서 generalization을 높였다.
I. Introduction
FL은 local data를 공개하지 않으면서(maintaining their privacy), distributed clients로 prediction을 학습하는 것이다. local data의 non-iid 문제는 poor generalization 문제를 불러왔다.
이에 대해 관련 연구들은 global과 local의 solution을 align하여 client drift를 줄일 수 있도록 local objective를 regularizing하는 데에 집중했다. 그에 반해 더 나은 minima를 찾기 위한 loss func의 explicit optimization은 거의 주목받지 못했다.
model의 generalization과 loss surface의 sharpness 사이의 관계에 집중한 몇몇 논문들은 derived genralization bound의 minimization(??) 이나 SGD trajectory에 따라(어떻게?) 모델 parameters를 averaging하는 것에 기반한 효과적인 방법을 제안했다.
우리는 local training 동안 model이 해당 local distribution에 overfit하여 average of update가 local minima에서 상당히 떨어져 있을 거란 가설을 세웠다. 또 수렴 속도도 느려진다. 이를 해결하기 위해 우린 federated scenario의 loss landscape를 분석하여 model이 sharp minima로 수렴하여 poor generalization을 보인다는 것을 발견했다. 해결책으로, explicit하게 flat minima를 찾을 수 있도록 SAM이나 ASAM을 client side에 적용하고, SWA를 server side에 적용할 것을 제안한다.
II. Related Works
Statistical Hegerogeneity in Federated Learning
FedAvg는 multiple local SGD에 기반한 standard optimization method를 정의하였다. Server side aggregation은 client update의 weighted average였다. 이 방법은 iid 상황에서는 잘 됐지만 non-iid에서는 local model이 서로 멀리 떨어져 central model을 global optimum에서 떨어뜨리는 client drift 효과로 잘 안됐다.
그 후 많은 연구들이 local model들이 global one에서 멀리 떨어지지 않도록 하는 local optimization regularization을 시도했다. client들의 model을 averaging하거나 gradient를 모으는 것은 이들이 제한된 데이터를 본다는 점 때문에 global model에서 suboptimal performance, oscillation을 불러왔다. 이 때문에 다른 쪽의 연구자들은 serverside에서 momentum과 adaptive optimizer를 사용해 aggregation stage를 향상시키는 데 집중했다.
본 연구에서는 loss surfaced와 convergence minima를 살폈다. 이를 위해 우리는 추가적인 communication cost 없이 explicit하게 uniformly low-loss neighborhood의 parameter를 얻는 데에 집중했다. local convergence가 flatter minima를 향하게 함으로써 global model의 generalization 능력을 높일 수 있었다. server side에서의 cyclical average of stochastic weights로 더 넓은 weight space를 살펴 더 넓은 wider optima를 얻을 수 있었다.
Real-word Vision Scenarios in Federated Learning
Large-scale Classification
분류를 위한 Synthetic federated datasets
Semantic Segmentation
- Prototypical representation
protonet - 각 class의 prototype representation까지의 거리를 계산하여 classification을 수행함.
참고 : https://rhcsky.tistory.com/9
SS in FL은 보통 medical imaging에서 많이 쓰인다. prototypical repr을 이용한 object segmentation에 집중한 연구도 있다. 최근 FL 적용 연구는 자율주행을 다뤘다. 하지만 어떤 것도 loss land scape, convergence minima 등에 관심을 주진 않았음.
Domain Generalization
여러 domain의 data를 받을 때, DG는 domain-agnostic(비종속적) 모델을 만드는 것을 목표로 한다. 우리 연구는 unseen domain을 classf하거나 SS 하는 것 또한 향상시킬 수 있다.
Flat Minima and Generalization
- Flatness
dimension of the region connected around the minimum in which the training loss remains low.
잘... 이해가...
논문 36, 20은 학습 중 지속적으로 loss sharpness와 value를 최소화해 flatter minima, smoother loss surface를 찾는 SAM을 제안함. SAM은 parameter re-scaling에 민감하여 loss sharpness와 generalization gap간의 관계를 약하게 할 수 있다. ASAM은 이 문제를 adaptive sharpness를 도입함으로써 해결했다.
논문 22, 17은 SGD로 찾은 local optima가 거의 일정한 loss의 path를 연결하고 이들을 weight space에서 ensamble하는 것은 network의 성능을 높일 수 있다.
III. Behind the Curtain of Heterogeneous FL
Federated Learning: Overview
수식으로 문제 정의하기
FL : based on central server exchanging messages with K distributed clients.
각 device k는 X에 속한 N_k개 이미지로 이뤄진 privacy-protected dataset D_k에 대한 접근 권한을 갖고 있다.
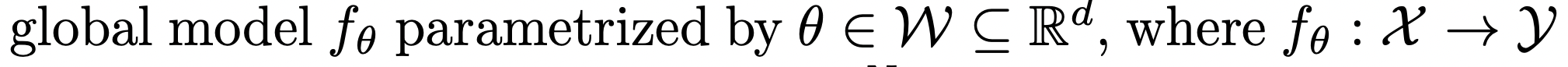
목표는 f_theta를 학습하는 것! theta의 구조는 모든 device에서 동일하다고 가정한다.
