1. 데이터베이스란 무엇인가
인간은 오래전부터 정보를 저장하려는 시도를 해왔다. 컴퓨터가 등장한 이후로는 데이터를 디지털 형태로 저장하면서 이를 더 체계적으로 관리하려는 움직임이 생겼다.
초기에는 텍스트 파일에 정보를 저장하는 방식이 일반적이었다. 하지만 데이터가 점점 많아지고, 여러 사용자나 시스템이 동시에 접근하는 상황이 늘어나면서 파일 기반 저장 방식에는 분명한 한계가 드러나기 시작했다.
이러한 문제를 해결하기 위해 데이터베이스(Database)라는 개념이 등장했고, 데이터를 효율적으로 관리하기 위한 시스템으로 DBMS(Database Management System)가 발전하게 되었다.
2. 왜 데이터베이스를 사용하는가
파일 기반 저장은 구현이 간단하다는 장점이 있지만 다음과 같은 한계가 있다.
- 동시 접근 제어의 어려움: 여러 사용자가 동시에 데이터를 읽거나 쓰는 경우 충돌 발생 가능
- 검색 성능 저하: 특정 데이터를 찾기 위해 전체 파일을 순회해야 함
- 데이터 무결성 유지의 어려움: 중복이나 삭제 누락, 일관성 문제 발생 가능
- 데이터 구조화 부족: 데이터 간 관계 표현이 어려움
예를 들어 고객 정보를 텍스트 파일로 저장한다면, 특정 고객을 찾기 위해 전체 파일을 읽어야 하고, 중복된 데이터를 제거하거나 구매 이력을 연결하는 등의 작업은 별도 로직으로 직접 처리해야 한다.
이러한 문제들을 해결하고 데이터를 구조적이고 신뢰성 있게 관리하기 위해 데이터베이스가 도입되었다.
3. DBMS란 무엇인가
DBMS는 Database Management System의 약자로, 데이터를 저장하고 검색하며 수정하거나 삭제할 수 있도록 도와주는 소프트웨어 시스템이다.
| 구분 | 설명 |
|---|---|
| DB | 데이터를 저장하는 공간 |
| DBMS | 데이터를 효율적으로 관리하는 시스템 |
DBMS는 단순 저장을 넘어서 다음과 같은 기능을 제공한다.
- 데이터의 저장 및 조회
- 무결성과 정합성 유지
- 사용자 접근 권한 관리
- 트랜잭션 처리 및 동시성 제어
- 백업 및 복구 기능
대표적인 DBMS로는 MySQL, PostgreSQL, Oracle, MariaDB, SQLite 등이 있으며, MongoDB나 Redis처럼 NoSQL 계열의 데이터베이스도 넓은 의미에서 DBMS로 분류된다.
4. 현재 어떤 데이터베이스가 사용되고 있을까
아래는 2025년 기준 데이터베이스 인기 순위를 나타낸 그래프다.
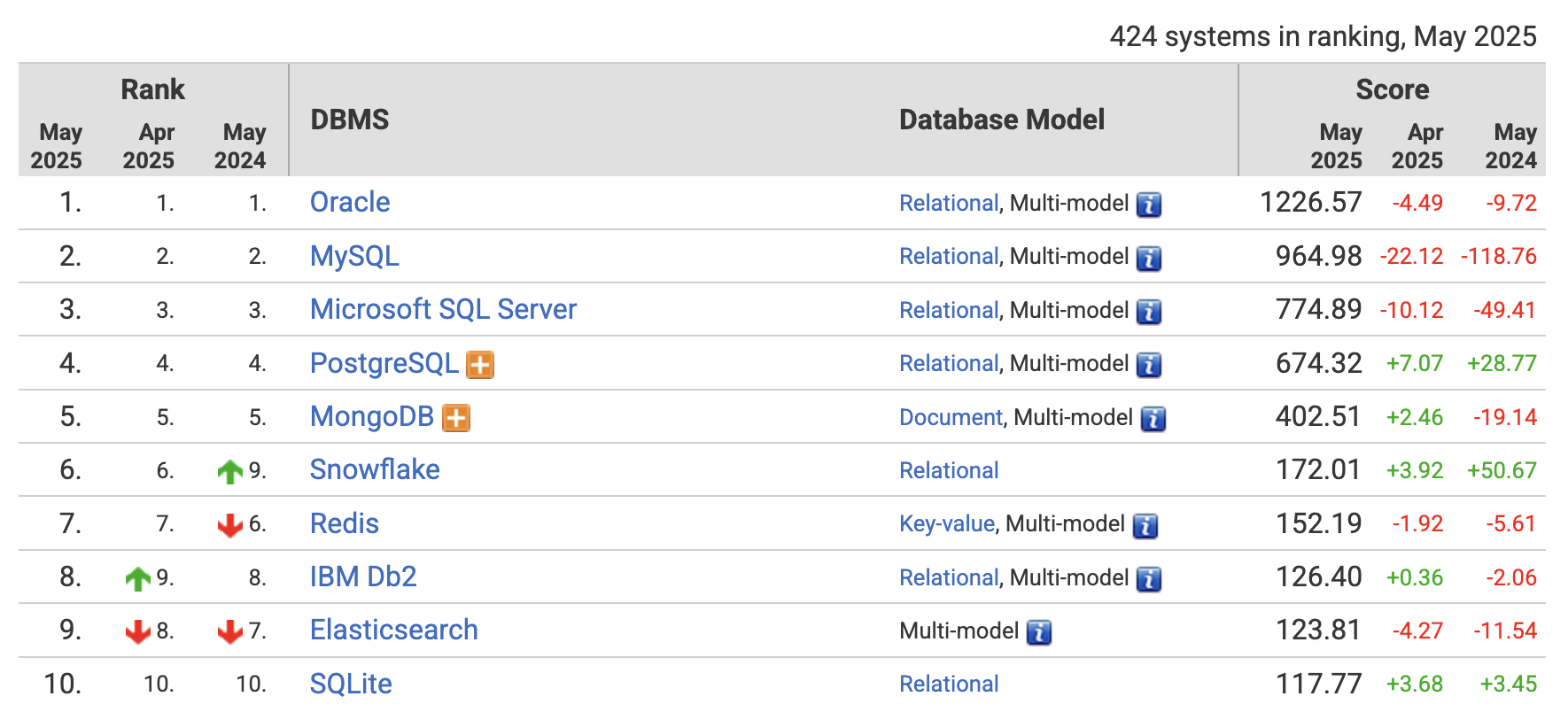
데이터를 보면 상위 대부분이 관계형 데이터베이스(RDBMS)다.
하지만 모든 문제를 관계형 DB만으로 해결할 수는 없기 때문에, 최근에는 특정 요구 사항에 맞게 NoSQL 계열의 데이터베이스와 병행하여 사용하는 경우도 많다.
5. 관계형 DB와 NoSQL, 무엇이 다를까
| 항목 | 관계형 DB (RDBMS) | NoSQL |
|---|---|---|
| 데이터 구조 | 테이블 기반 (정형 데이터) | 문서, 키-값, 그래프 등 다양한 형태 |
| 스키마 | 고정된 스키마 | 유연하거나 없음 |
| 확장성 | 수직 확장 위주 | 수평 확장에 적합 (Sharding 등) |
| 트랜잭션 | ACID 보장 | BASE 모델, 일관성은 느슨함 |
| 대표 DB | MySQL, PostgreSQL, Oracle | MongoDB, Redis, Cassandra |
NoSQL은 관계형 데이터베이스가 갖는 구조적 제약, 수직 확장 한계 등을 보완하기 위해 등장했다.
최근에는 서비스의 특성에 따라 RDB와 NoSQL을 함께 사용하는 폴리글랏 퍼시스턴스(Polyglot Persistence) 방식도 자주 활용된다.
6. 데이터는 어떻게 저장되는가?
6.1 File (.CSV)
CSV는 텍스트 기반 포맷으로, 사람이 직접 열어서 내용을 확인하고 편집하기에 용이하다.
각 행(row)은 하나의 데이터 레코드를 나타내고, 각 열(column)은 해당 데이터의 속성을 의미하며 쉼표(,)로 구분된다.
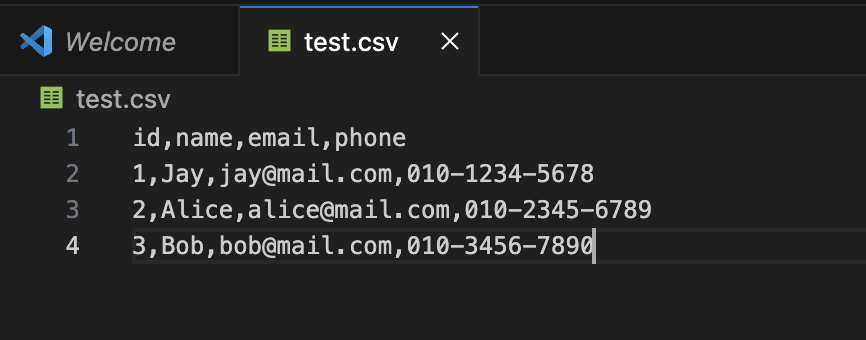
하지만 구조가 단순한 만큼 다음과 같은 단점이 있다
- 검색이나 조건 필터링 시 전체 파일을 처음부터 끝까지 순회해야 하므로 성능이 매우 떨어진다.
- 데이터 형식(문자열, 숫자, 날짜 등)에 대한 정의가 없고, 모든 데이터가 문자열로 처리된다.
- 중복 데이터 제거, 무결성 검증, 참조 관계 관리가 불가능하다.
- 동시성 처리나 트랜잭션 같은 고급 기능은 존재하지 않는다.
예를 들어 100만 건의 주문 내역이 저장된 CSV 파일에서
"2023년에 생성된 주문만 필터링"하려면, 파일을 한 줄씩 읽으면서 조건을 직접 확인해야 하며 이는 성능과 유지보수 측면에서 매우 비효율적이다.
6.2 DB (MySQL)
관계형 데이터베이스는 데이터를 테이블(table) 이라는 구조화된 형태로 저장한다.
테이블은 행(row)과 열(column)로 구성되어 있으며, 엑셀과 유사한 형태를 갖는다.
각 행은 하나의 데이터 레코드를 의미하고, 각 열은 속성(필드)에 해당한다.
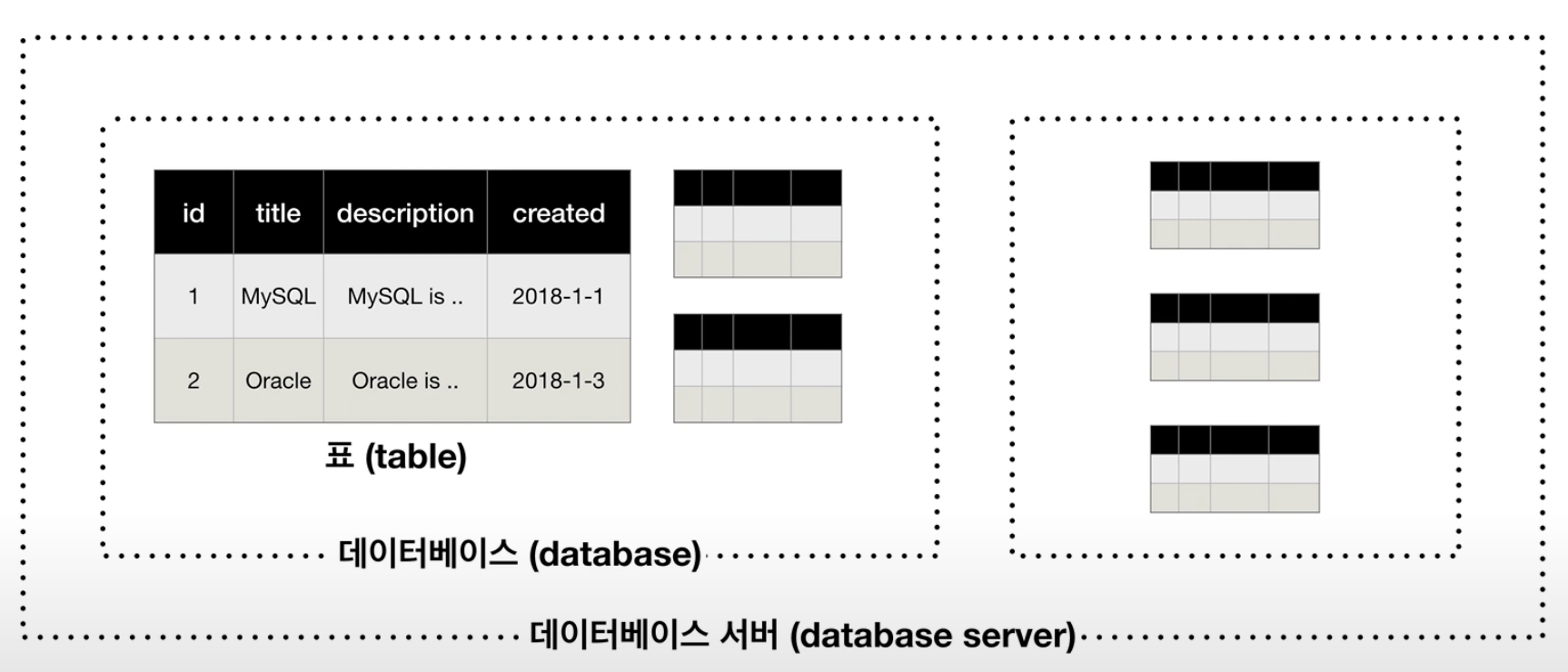
- 여기서 중요한 개념이 스키마(Schema) 다.
🔍 스키마란?
스키마는 데이터베이스에서 테이블 구조, 컬럼 타입, 제약 조건 등 메타데이터를 정의한 설계도 역할을 한다.
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100) UNIQUE,
phone VARCHAR(20)
);이 테이블의 스키마는 다음과 같은 정보를 담고 있다:
- id: 정수 타입, 중복 불가, 기본 키
- name, email, phone: 각각 문자열 타입, 길이 제한 있음
- email: 중복 불가 (UNIQUE 제약)
7. 마무리 요약
데이터베이스는 데이터를 더 안정적이고 체계적으로 저장하고 관리하기 위한 시스템이다.
파일 기반 저장 방식의 한계를 보완하고, 동시성 처리와 검색, 무결성 유지 등 다양한 문제를 해결할 수 있게 해준다.
DBMS는 현대 소프트웨어 아키텍처에서 핵심 인프라로 자리 잡고 있으며, 데이터베이스의 종류와 특성을 제대로 이해하는 것은 개발자에게 반드시 필요하다.
Next
다음 글에서는 관계형 데이터베이스(RDBMS)의 구조와 작동 원리에 대해 더 깊이 알아볼 예정이다.
테이블은 어떻게 구성되며, 데이터 간의 관계는 어떤 방식으로 정의되는지 함께 살펴보자.
