0. 들어가며
면접에서 "인덱스에 대해서 설명해주세요." 질문을 받았을 때 인덱스에 대해서 답변은 했지만, B-Tree 와 실제 Spring에서 인덱스를 사용했던 경험을 꼬리 질문에서 제대로 답변하지 못했다.
내 답변
인덱스는 DB에서 검색 속도를 향상시키기 위한 자료구조입니다. MySQL에서는 B- Tree 자료구조를 사용하고, 인덱스가 없으면 모든 자료를 풀 스캔하면서 비효율적인 탐색이 발생하는데 인덱스는 검색 조건을 줄여 효율적인 탐색을 가능하게 해줍니다.
- 아쉬운 부분 (꼬리질문)
- B-Tree 자료구조에 대해 답변하지 못함.
- 인덱스 실제 경험에 대해 답변하지 못함.
- 프로젝트에서는 MySQL(InnoDB)에서 자동 생성되는 PK 기반 클러스터링 인덱스만 사용해봄
1. 인덱스란?
인덱스란 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. 인덱스가 없으면 모든 데이터를 스캔하며 검색해야 한다.(비효율 탐색)
1.1 인덱스 관리
- 인덱스는 항상 최신의 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있다.
- 그렇기 때문에 INSERT, UPDATE, DELETE 가 수행될 때, 인덱스 또한 다시 정렬되어야 한다.
- 때문에 추가적인 연산이 발생하고 그에 따른 오버헤드가 발생한다.
- MySQL(InnoDB)에서는 클러스터링 인덱스를 통해 테이블 데이터가 기본 키 순서대로 정렬되어 저장된다.
1.2 인덱스의 장단점
-
장점
- 테이블을 조회하는 속도가 빨라지고 성능을 향상 시킬 수 있다.
- 전반적인 시스템의 부하를 줄일 수 있다.
-
단점
- 인덱스를 관리하기 위한 DB 저장공간 필요.
- 인덱스를 관리하는 추가작업이 필요하다.
- 자주 수정되는 데이터는 인덱스도 계속 변경되기 때문에 오버헤드가 발생.
1.3 인덱스가 유리한 경우
- 규모가 작지 않은 테이블
- 데이터의 추가, 수정, 삭제가 자주 발생하지 않는 데이터
- JOIN이나 WHERE 또는 ORDER BY에 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
2. B-Tree 인덱스 알고리즘
MySQL 에서 사용하는 인덱스 자료구조는 B-Tree 이다. B-Tree는 인덱스 칼럼의 값을 변형하지 않고, 원래의 값을 이용해 인덱싱하는 알고리즘이다.
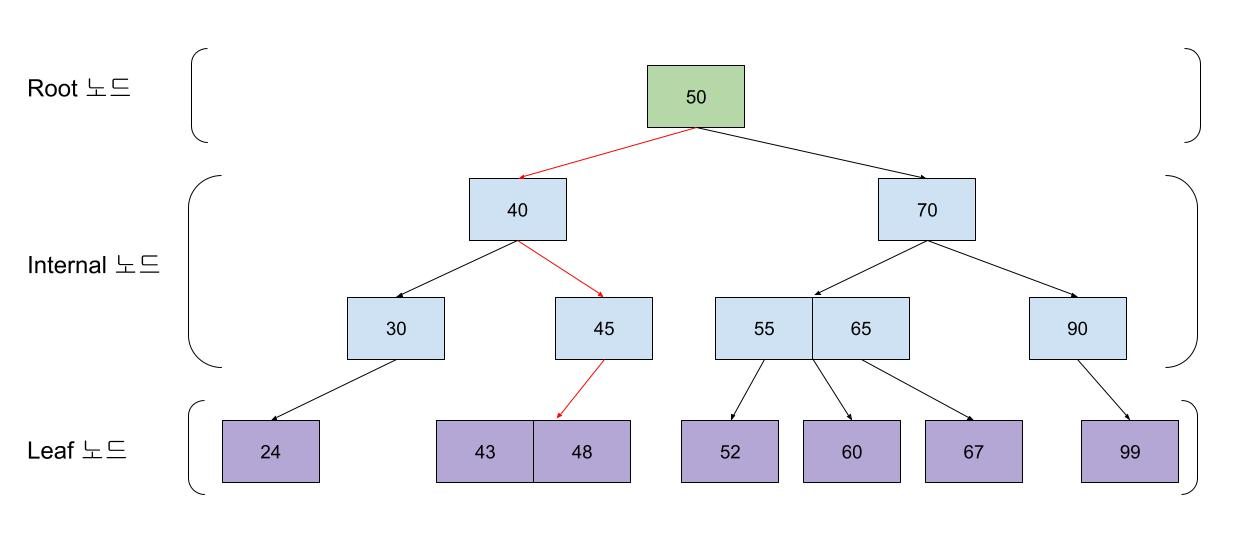
B-Tree는 최상위에 하나의 루트 노드가 존재하고, 그 하위에 자식 노드가 붙어있는 형태이다.
트리 구조의 가장 하위에는 리프노드라고 하고 트리구조에서 루트노드도 아니고 리프노드도 아닌 중간의 노드를 브랜치 노드라고 한다.
이 인덱스의 최대 장점은 어떤 데이터를 조회하든지, 이에 사용하는 조회 과정의 길이 및 비용이 균등하다는데 있다.
단, 어떤 데이터를 조회 하던지 Root 에서 부터 Leaf 페이지를 모두 거처야 하기 때문에 데이터가 적은 테이블의 단순 조회로 데이터를 조회하는 과정이 대비 조회 속도가 느린 단점이 있다.
2.1 B+Tree 와는 뭐가 다른가?
두 자료구조는 이름이 비슷하지만, 데이터 저장 위치와 검색 방식에서 차이가 있다.
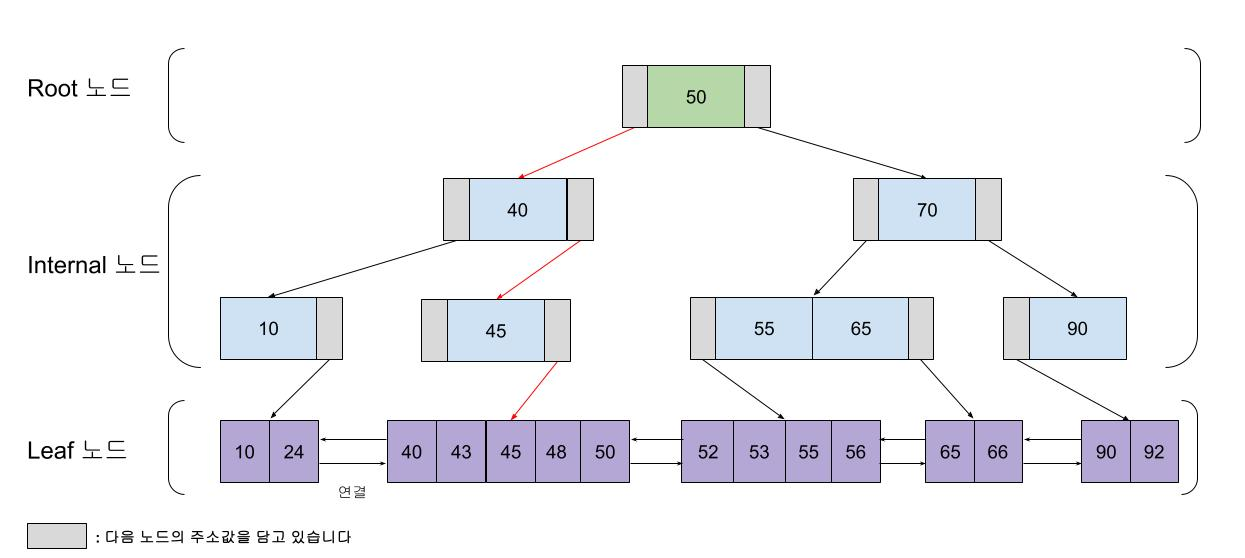
- 실제 데이터는 오직 리프 노드에만 저장
- 항상 리프 노드까지 내려가야 하기 때문에 단일 검색은 B-Tree보다 살짝 비용이 클 수 있다.
🌟 구조적 차이
- B-Tree
- 내부 노드(브랜치)와 리프 노드 모두 데이터(레코드 포인터)를 가질 수 있다.
- 즉, 중간 노드에서도 데이터를 찾을 수 있다.
- B+Tree
- 실제 데이터는 오직 리프 노드에만 저장된다.
- 브랜치 노드는 탐색을 위한 키(Key) 정보만 가지고 있다.
- 리프 노드들은 Linked List 형태로 연결되어 있어, 순차 접근 및 범위 검색이 효율적이다.
3. 마무리
면접에서 인덱스에 대한 기본적인 답변은 했지만,
- B-Tree 자료구조에 대한 꼬리 질문
- Spring에서 인덱스를 어떻게 사용했는가에 대한 질문
이 두 부분에서 구체적으로 답변하지 못했다.
보완 답변 (정리된 버전)
(1) B-Tree 자료구조에 대해서
MySQL에서 사용하는 인덱스는 B-Tree 자료구조입니다.
B-Tree는 균형 트리 구조로서, 루트 노드에서부터 브랜치 노드를 거쳐 리프 노드까지 내려가며 데이터를 탐색합니다.
이 구조 덕분에 어떤 데이터를 조회하든 탐색 깊이가 일정하게 유지되어 성능이 안정적이고, 조회·삽입·삭제가 모두 O(logN) 복잡도로 처리됩니다.
또한 인덱스 컬럼의 값을 그대로 정렬된 상태로 유지하기 때문에, WHERE 조건 검색, JOIN 키 매칭, ORDER BY 정렬 같은 연산에 유리합니다.
(2) Spring에서 인덱스 사용 경험
인덱스 자체는 DB 레벨에서 관리되지만, 애플리케이션의 쿼리 패턴에 따라 어떤 컬럼에 인덱스를 추가할지 결정한 경험이 있습니다.
예를 들어, 사용자 조회에서 email 컬럼 검색이 많아 보조 인덱스를 생성했고, EXPLAIN으로 실행 계획을 확인했을 때 풀 스캔 대신 인덱스를 활용해 조회 성능이 개선된 걸 확인했습니다.
Spring JPA에서는 @Table(indexes = …) 어노테이션으로 스키마 생성 시 인덱스를 명시할 수도 있는데, 이런 방식을 통해 인덱스를 선언적으로 관리한 경험이 있습니다.
