0. 들어가며
이전까지는 주로 Spring MVC 기반으로 CRUD와 데이터베이스 연동 중심의 서비스를 개발해왔다.
그런데 최근에 외부 API와 통신이 많은 서비스를 만들면서, 비동기 처리의 필요성을 느꼈고, 자연스럽게 Spring WebFlux에 관심을 갖게 되었다.
처음에는 별다른 설정 없이 기존 MVC 프로젝트에 WebFlux 의존성을 추가하고, Tomcat 위에서 WebClient, Mono, Flux를 활용해 비동기 통신을 구현했다.
그 당시에는 “이게 WebFlux 방식이구나”라고 생각했지만, 이후 자료를 찾아보며 알게 된 사실은 다음과 같다.
WebFlux의 진짜 성능은 Netty 기반에서만 완전히 발휘된다.
즉, Tomcat에 WebFlux를 올려서 사용하는 건 가능한 일이지만, 완전한 논블로킹 I/O 처리가 보장되는 것은 아니었다.
이번 글에서는 이 과정을 직접 경험하며 알게 된 Spring MVC와 WebFlux의 구조적 차이, 실무에서의 판단 기준에 대해 정리해자.
1. Spring MVC
Spring MVC는 전통적인 웹 애플리케이션 개발 방식의 핵심 프레임워크로, 동기(동기적) + 블로킹 I/O 방식을 기반으로 동작한다. 이 방식을 이용하면 개발자가 상대적으로 쉽고 직관적인 로직을 작성할 수 있다.
- 전통적인 서블릿 기반의 동기 처리 방식.
- 기본적으로 Tomcat과 같은 서블릿 컨테이너(WAS) 위에서 동작하며, HTTP 요청을 하나의 스레드가 전담 처리한다.
- HTTP 요청을 하나의 스레드가 처리하며, 스레드가 요청의 처리 완료까지 대기
- 블로킹 I/O를 사용하기 때문에 요청이 많아질 경우 스레드 풀 크기에 따라 병목이 발생할 수 있다.
1.1 Servlet Architecture

- 클라이언트에서 URL 호출
- 웹서버에서 URL을 확인하여 해당 서블릿으로 요청 전달, 없으면 서블릿 클래스의 init()으로 생성
- 서블릿 컨테이너는 요청정보를 HttpServletRequest, HttpServletResponse 두 객체에 저장
- 서블릿 클래스의 service()메소드 호출 (HTTP Method에 따라 서블릿의 doGet, doPost 호출)
- 요청 처리 후 HttpServletResponse 객체에 HTTP 데이터를 담아 응답
- 웹서버가 클라이언트에 응답처리
- 서블릿의 destroy() 호출하여 GC에 의해 서블릿 종료
Spring MVC 에서는 DispatcherServlet으로 대부분의 요청을 처리한다.
DispatcherServlet Architecture
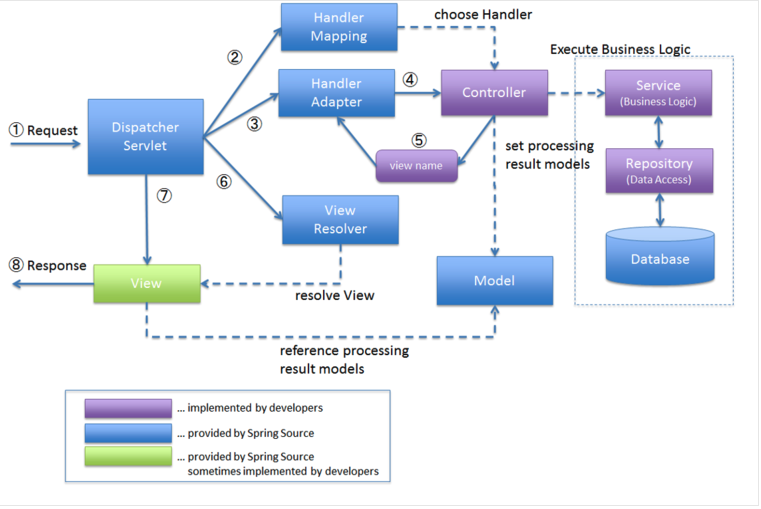
1.2 Spring MVC 요청 흐름
클라이언트로부터 요청이 들어오면, 서블릿 컨테이너(Tomcat)는 작업을 처리할 쓰레드를 하나 할당하고, 그 쓰레드는 요청 처리 완료까지 계속 점유된다.
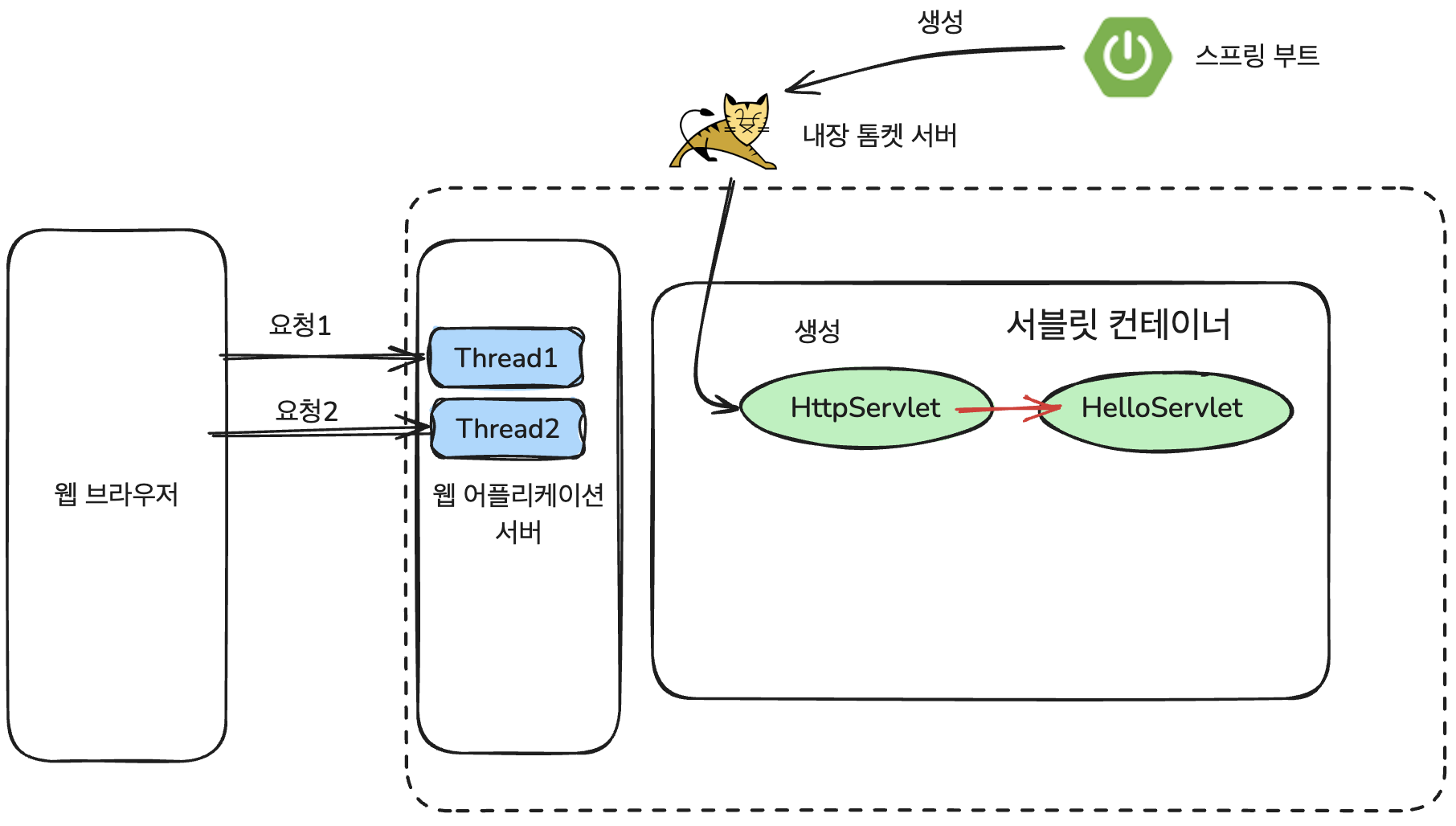
- 요청이 들어오면 Tomcat 스레드 풀에서 스레드 1개가 할당 (스레드 풀에서 스레드 할당)
- 이 스레드는 요청 → 컨트롤러 → DB 처리 → 응답까지 모든 과정을 순차적으로 처리
- 처리 중 DB나 외부 API 응답을 기다리는 동안에도 해당 스레드는 블로킹됨
- 요청 처리 완료 후에야 스레드는 반환되고, 다른 요청을 처리할 수 있음
2. Spring WebFlux
Spring WebFlux는 Spring 5에서 도입된 비동기(Asynchronous) + 논블로킹(Non-blocking) I/O 웹 프레임워크다.
기존 Spring MVC가 서블릿 기반의 동기 처리 모델을 따랐다면, WebFlux는 리액티브 스트림(Reactive Streams) 사양에 따라 동작하며 처리 방식 자체가 완전히 다르다.
- WebFlux는 서블릿 API에 의존하지 않으며, Servlet Container 없이도 동작할 수 있도록 설계되었다.
- 기본적으로 Netty 기반의 논블로킹 서버(reactor-netty)를 사용하지만, Servlet 3.1 이상을 지원하는 Tomcat, Jetty와 같은 서블릿 컨테이너에서도 동작 가능하다.
- 요청 처리 시 스레드를 점유하지 않고, 데이터가 도착하거나 처리가 가능해질 때까지 이벤트 기반으로 흐름을 연결한다.
- 대표적인 리턴 타입으로는 Mono (0~1개), Flux (0~N개)가 있으며, 이를 통해 데이터 스트림을 표현하고 체이닝 방식으로 비동기 흐름을 제어한다.
Spring Boot에서 spring-boot-starter-webflux 를 사용하면 기본 서버로 Netty가 설정되며, 완전한 논블로킹 체인으로 실행된다.
서블릿 기반에서 벗어나기 때문에 기존 MVC와는 필터 구조, 컨텍스트 관리 방식, 에러 처리 방식 등 많은 부분에서 차이를 가진다.
2.1 DispatcherHandler
Spring MVC 에서는 모든 HTTP 요청이 DispatcherServlet 을 통해서 요청이 처리되지만, Spring WebFlux에서는 DispatcherHandler가 그 중심 역할을 수행한다.
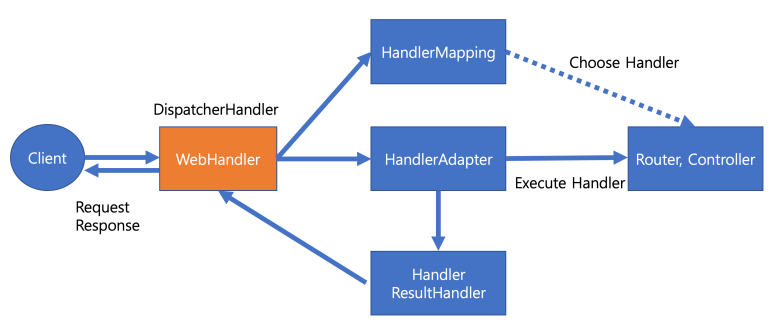
- HandlerMapping : 요청을 어떠한 Controller, Router가 처리할지 결정
- HandlerAdapter : HandlerMapping으로 선택된 Controller, Router를 호출
- HandlerResultHandler : 결과를 처리하고 응답
2.2 Spring WebFlux 요청 흐름
Spring MVC 에서는 스레드 풀에서 미리 만들어둔 스레드를 요청마다 할당 시켰다. 그래서 요청이 많을 경우 스레드 풀에 남은 스레드가 없다면 대기하는 문제가 발생한다.
하지만 Spring WebFlux 은 스레드 풀을 사용하지 않고 EventLoop 방식을 사용한다.
EventLoop 방식이란?
EventLoop(이벤트 루프)는 Java NIO 기반의 논블로킹 I/O 처리를 가능하게 해주는 Netty의 핵심 스레드 모델이다.
요청마다 하나의 스레드를 점유하는 전통적인 웹 서버(Tomcat 등)의 방식과 달리, EventLoop는 하나의 스레드가 수많은 요청을 순차적으로 비동기 처리한다.👉 즉, EventLoop는 요청을 동시에 처리하는 것이 아니라, 빠르게 돌아가며 이벤트(요청, 응답 완료, 데이터 수신 등)가 발생했을 때만 처리 하는 구조다.
EventLoopGroup에 총 3개의 이벤트 루프가 있다. 그리고 각 소켓이 하나씩 이벤트 루프에 바인딩된 상태이다.

- SocketChannel : 클라이언트 연결을 나타내는 객체
- EventLoopGroup : 전체 요청을 처리하는 스레드 그룹
- Processing : 요청이 처리되는 리액티브 흐름
🧐 SocketChannel 이 뭐야? MVC 사용할 때 이런거 고려 안했는데??
Spring MVC(Tomcat)에서 클라이언트가 서버에 연결하면, TCP 3-way handshake가 OS/Tomcat의 Acceptor Thread 레벨에서 처리되고,
이 연결이 성립되면 SocketChannel이 생성되어 이후 HTTP 요청/응답은 그 채널을 통해 흐르게 된다.📌 정리하면
Spring MVC에서 우리는 @Controller, HttpServletRequest 같은 고수준 API만 다루기 때문에 그 아래에서 벌어지고 있는 TCP 연결, SocketChannel 생성, 스레드 할당 같은 일들은 서블릿 컨테이너(Tomcat) 가 전부 알아서 해주고 있었던 거다.
다시 돌아와서 EventLoop 방식으로 어떻게 요청이 처리될까?
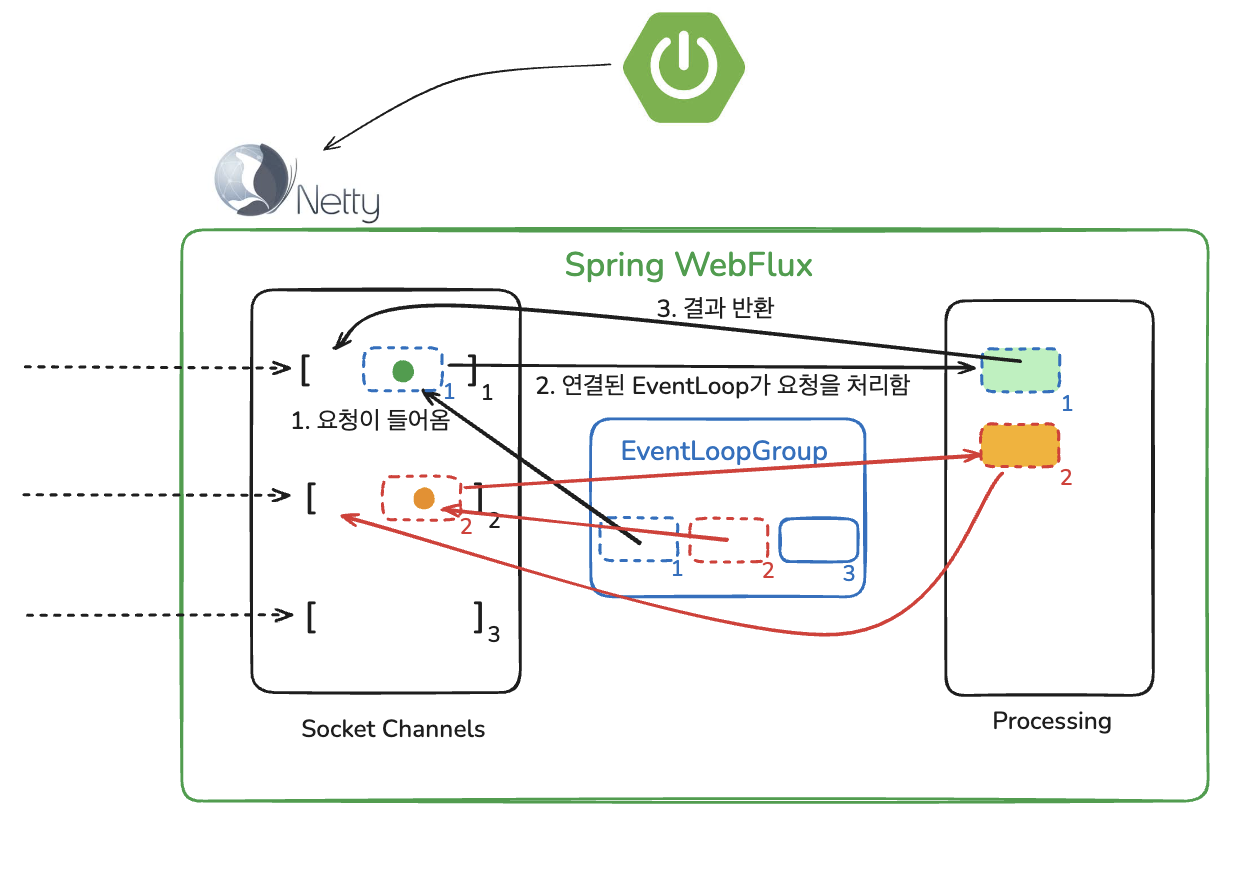
- SocketChannel 에 요청이 들어오면 (각 소켓이 하나씩 이벤트 루프에 바인딩된 상태) EventLoop 가 요청을 처리하고 반환한다.
- 이벤트 루프는 단순한 스레드일 뿐이며 일반적으로 이벤트 루프를 태스크 단위로 처리하기 위한 경량 메커니즘을 가지고 있다.
- 따라서 컨텍스트를 자주 전환한다.
- 블로킹 작업을 만나기 전까지 이벤트 루프는 Spring MVC의 워커 스레드와 거의 유사하게 동작한다.
- 적은 수의 EventLoop 스레드가 모든 요청을 돌기 때문에 한 요청이 CPU를 오래 점유하면 → 나머지 요청까지 줄줄이 밀린다.
💡 EventLoop가 블로킹되는 상황에서 Spring WebFlux가 어떻게 반응하는지는 다음 기회에 자세히 다뤄보겠다. 이번 글에서는 먼저 EventLoop 방식의 전체 흐름과 구조부터 이해하자.
3. Spring MVC vs Spring WebFlux
Spring에서 HTTP 요청을 처리하는 대표적인 두 가지 방식인 Spring MVC와 Spring WebFlux는 근본적으로 I/O 처리 방식, 스레드 모델, 확장성 전략이 다르다.
3.1 구조적 차이
| 항목 | Spring MVC (Tomcat) | Spring WebFlux (Netty 기반) |
|---|---|---|
| 처리 모델 | 동기 + 블로킹 | 비동기 + 논블로킹 |
| 스레드 모델 | 요청 1건당 스레드 1개 점유 | 적은 수의 EventLoop로 수천 건 처리 |
| 기본 서버 | Tomcat, Jetty, Undertow 등 서블릿 컨테이너 | Netty (기본), Undertow 등 비서블릿 |
| Socket 처리 | Socket → Thread → 요청 처리 | Socket → EventLoop 고정 → 요청 순회 처리 |
| 요청 흐름 | DispatcherServlet 기반 | DispatcherHandler + 리액터 스트림 기반 |
| 스레드 수 설정 | maxThreads=200 등 명시적 설정 | reactor.netty.ioWorkerCount (기본 CPU x 2) |
| 개발 난이도 | 직관적, 학습 비용 낮음 | 리액티브 패러다임 숙지가 필요 |
3.2 성능 관점 차이
| 항목 | Spring MVC | Spring WebFlux |
|---|---|---|
| 트래픽 처리 구조 | 요청 수만큼 스레드 소모 → 수백~수천 개 필요 | 적은 수의 스레드로 많은 요청 처리 가능 |
| CPU 부하 | 스레드 많아 → context switching 부담 | 스레드 적지만, 한 스레드당 연산 집중도 높음 |
| 블로킹 작업 허용 | 허용 (스레드 점유로 격리 가능) | ❌ 절대 지양해야 함 (EventLoop가 멈춤) |
| GC 부담 | 요청당 객체 생성 많음 | 오래 걸리는 요청이 많을 경우 오히려 압박 가능 |
| 실수 여지 | 상대적으로 적음 | 작은 실수도 전체 병목으로 이어짐 |
3.3 어떤 상황에서 어떤 걸 쓰면 좋을까?
Spring MVC와 Spring WebFlux는 각각의 강점이 뚜렷한 만큼 서비스의 특성과 요구 사항에 따라 선택 기준이 달라져야 한다.
-
전통적인 웹 서비스, JSP 기반 페이지 렌더링, 파일 업로드가 필요한 경우 (Spring MVC)
- 전통적인 웹 애플리케이션 구조에서는 JSP 렌더링, 파일 업로드, 세션 기반 인증 등을 자주 사용
- 이러한 기능들은 서블릿 기반의 동기식 처리 모델에 최적화되어 있기 때문에 Spring MVC를 사용하는 것이 훨씬 안정적이고 구현도 간단합니다.
-
외부 API를 연동하거나, WebClient를 중심으로 구성된 API Gateway 서비스라면 (Spring WebFlux)
- 요즘은 하나의 서비스가 여러 외부 API를 비동기적으로 호출해서 결과를 조합하는 구조가 많다.
- 이럴 경우 WebFlux의 논블로킹, 비동기 처리 모델이 훨씬 유리
- 전체 I/O 흐름을 논블로킹으로 유지할 수 있어서 적은 스레드 수로도 많은 요청을 처리할 수 있는 구조를 만들 수 있습니다.
4. Spring WebFlux 사용 방법
사용 방식은 크게 두 가지로 나뉜다.
4.1 Netty 기반 핸들러 방식 사용
가장 기본적인 WebFlux 사용법은 함수형 라우터 + 핸들러 구조이다.
Netty와 직접적으로 연결되는 방식이며, 프레임워크의 개입이 적고 최소한의 설정으로 구성
예시 코드 – 함수형 라우팅 방식
@Configuration
public class RouterConfig {
@Bean
public RouterFunction<ServerResponse> route() {
return RouterFunctions
.route(GET("/hello"), request -> ServerResponse.ok().bodyValue("Hello, WebFlux!"));
}
}이 방식은 RouterFunction과 HandlerFunction을 조합하여 라우팅을 정의한다.
Spring MVC처럼 @Controller를 사용하지 않고, 훨씬 선언적으로 동작한다.
특징
- Netty 기반 구조를 더 잘 보여줌
- 리액티브 함수형 스타일에 익숙하면 유연하고 강력
- 작은 서비스나 마이크로 서비스에 적합
4.2 Spring MVC 스타일로 사용하는 방법
Spring WebFlux는 기존 MVC 개발자에게 익숙한 방식도 제공.
@RestController와 @GetMapping, Mono, Flux 리턴 타입만 변경하면 WebFlux처럼 동작한다.
예시 코드 – 어노테이션 기반
@RestController
public class HelloController {
@GetMapping("/hello")
public Mono<String> hello() {
return Mono.just("Hello, WebFlux!");
}
}- 내부적으로
DispatcherHandler를 통해 처리되며 - 실제 서버는 Netty를 사용하지만 개발자는 거의 MVC처럼 사용 가능
특징
- 기존 Spring MVC와 유사한 코드 스타일
WebClient,R2DBC, 리액티브 어댑터와 함께 사용 가능- 점진적 WebFlux 전환에 적합 (서블릿 없이도 비동기 처리 가능)
4.3 어떤 방식을 써야 할까?
| 상황 | 추천 방식 |
|---|---|
| 라우팅 정의를 코드로 제어하고 싶다 | Netty 함수형 방식 (RouterFunction) |
| 기존 MVC 스타일 유지하고 싶다 | 어노테이션 기반 방식 |
| 경량 마이크로서비스 또는 간단한 API 서버 | 함수형 방식 |
| 리팩토링 중이거나 점진적 도입 중 | 어노테이션 방식 |
5. 마무리
처음 WebFlux를 쓸 때는 그냥 WebClient, Mono, Flux를 쓰면
“이게 비동기 처리구나” 하고 넘겼다.
Tomcat 위에서 잘 돌아가길래, 그게 WebFlux 방식인 줄 알았다.
그런데 알고 보니, WebFlux가 가진 진짜 장점은 Netty 위에서 논블로킹으로 작동할 때만 제대로 드러난다는 걸 나중에야 알게 되었다.
Spring MVC는 구조가 직관적이고, 트랜잭션 처리나 복잡한 연산이 있을 때 안정적으로 쓰기 좋다. 반면 WebFlux는 가볍고 빠른 요청을 동시에 많이 처리할 때 강한 구조이다. 단, 블로킹 작업이나 무거운 로직이 섞이면 오히려 더 느려질 수 있다는 것도 직접 겪으며 배웠다.
기술을 선택할 땐 이게 좋은 기술인가? 보다 우리 서비스에 맞는 방식인가?가 더 중요하다고 느꼈다.
