CI / DI란 무엇이고 왜 필요할까?
회원가입이나 본인인증 기능을 붙이다 보면
생각보다 자주 보게 되는 값이 있다. 바로 CI와 DI이다.
처음 보면 둘 다 본인인증 과정에서 전달되는 값이라서 비슷하게 느껴진다.
그래서 그냥 “인증 결과 중 하나구나” 정도로 넘어가기 쉽다.
그런데 막상 서비스에 회원가입, 중복가입 방지, 기존 회원 식별 같은 정책을 붙이기 시작하면
CI와 DI를 어떻게 이해해야 하는지가 꽤 중요해진다.
이번 글에서는 CI와 DI가 각각 무엇인지,
그리고 왜 필요한지, 어떤 차이가 있는지 정리해보려고 한다.
1. 온라인 서비스에서 사용자를 식별한다는 것
서비스를 운영하다 보면
“이 사용자가 누구인가”를 판단해야 하는 순간이 생각보다 많다.
예를 들면 이런 경우가 있다.
- 이미 가입한 회원인지 확인해야 하는 경우
- 동일인이 여러 계정을 만드는 것을 막아야 하는 경우
- 본인확인 결과를 기존 회원 정보와 연결해야 하는 경우
- 외부 서비스와 동일 사용자인지 연계해야 하는 경우
문제는 이름, 이메일, 휴대폰 번호만으로는 사용자를 완전히 식별하기 어렵다는 점이다.
이름은 동명이인이 있을 수 있고,
이메일은 여러 개를 쓸 수 있고,
휴대폰 번호도 바뀔 수 있다.
예전에는 주민등록번호를 직접 수집해서 식별하는 방식이 많이 사용되었지만
개인정보 보호 이슈가 커지면서 그런 방식은 사실상 사용하기 어려워졌다.
그렇다고 서비스 입장에서 사용자 식별이 필요 없어지는 것은 아니다.
결국 주민등록번호를 직접 저장하지 않으면서도
사용자를 구분할 수 있는 수단이 필요해졌고,
그 과정에서 CI와 DI 같은 값이 사용된다.
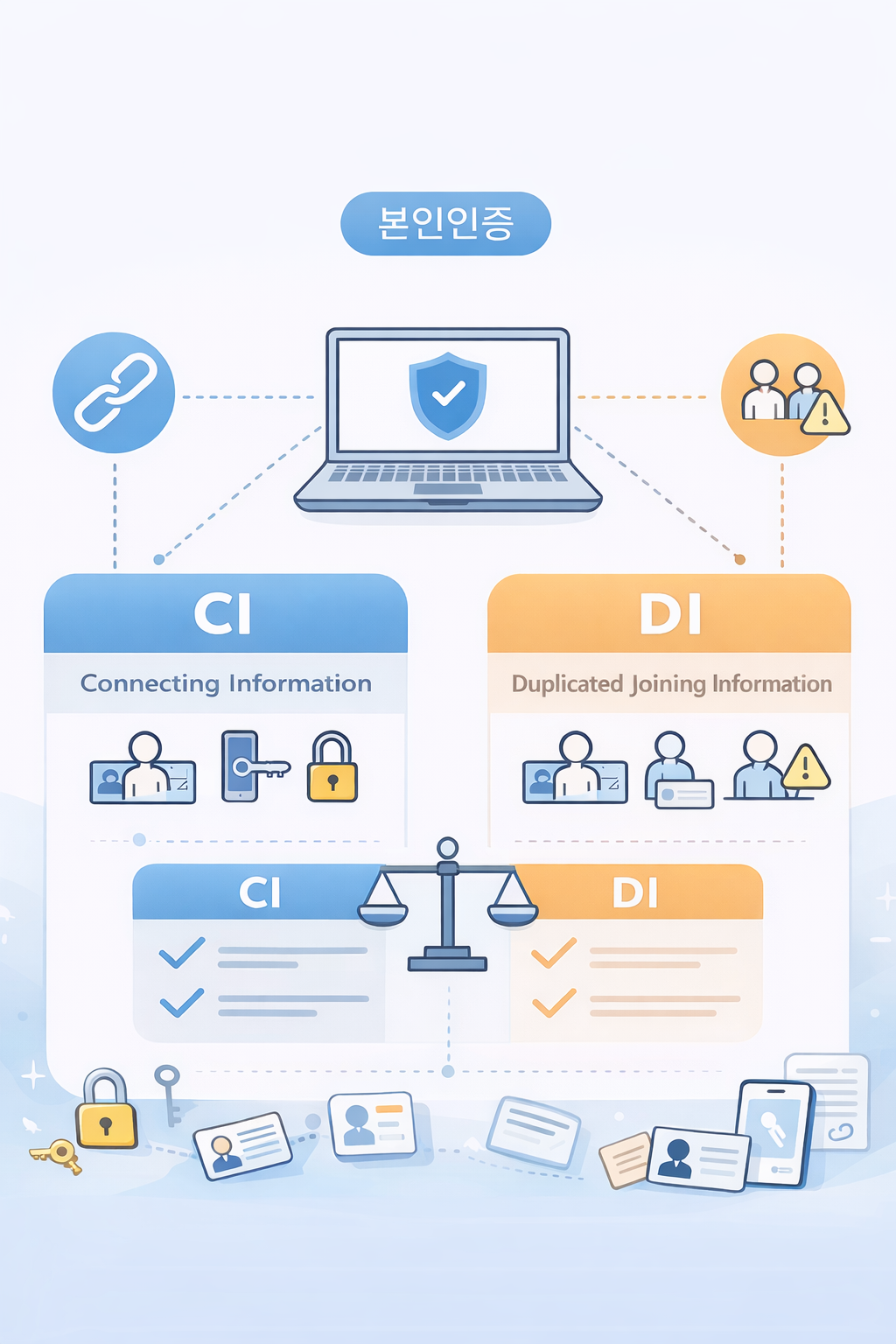
2. CI란?
CI는 Connecting Information의 약자이다.
쉽게 말하면
서로 다른 서비스에서도 같은 사람을 비교적 일관되게 식별할 수 있도록 하기 위한 값이라고 이해하면 된다.
본인확인기관을 통해 생성되는 값이고,
동일한 사람이라면 서비스가 달라도 같은 값으로 전달될 수 있다는 점이 핵심이다.
즉, CI는 단순히 “본인인증을 했다”는 결과가 아니라
이 사용자가 다른 곳에서도 같은 사람인지 연결해서 볼 수 있는 기준값에 가깝다.
CI의 핵심 특징
CI를 볼 때 가장 중요한 포인트는 연계 가능성이다.
- 같은 사람이라면 서비스가 달라도 동일한 값으로 볼 수 있다.
- 서비스 간 사용자 매핑이 필요한 경우 활용할 수 있다.
- 내부 식별뿐 아니라 외부 연계 관점에서도 의미가 있다.
예를 들어
A 서비스에서 본인인증한 사용자가
B 서비스에서도 같은 사람인지 확인해야 한다면
CI가 하나의 기준이 될 수 있다.
3. DI란?
DI는 Duplicated Joining Information의 약자이다.
DI는 CI와 달리
특정 서비스 내부에서 동일 사용자인지 판단하거나 중복가입 여부를 확인하기 위한 값에 더 가깝다.
즉, DI는 “우리 서비스 안에서 이 사용자가 이미 가입한 적이 있는가”를
판단하는 데 초점이 있다.
처음 보면 CI와 비슷하게 느껴질 수 있지만,
DI는 범용적으로 여러 서비스를 연결하기 위한 값이라기보다는
서비스 내부 식별 성격이 강한 값이라고 보는 편이 맞다.
DI의 핵심 특징
DI를 이해할 때는 로컬 식별이라는 관점이 중요하다.
- 특정 서비스 내부에서 동일인 여부를 판단하는 데 적합하다.
- 중복가입 방지 같은 정책에 활용할 수 있다.
- 서비스 간 연계용 식별값으로 보기에는 한계가 있다.
즉, DI는
“여러 서비스에서 같은 사람인지”보다는
“우리 서비스 안에서 같은 사람인지”에 더 가깝다.
4. CI와 DI의 차이
CI와 DI는 둘 다 본인확인 과정에서 다루게 되는 값이지만
실제로는 쓰임새가 다르다.
가장 큰 차이는 활용 범위이다.
CI
- 서비스 간 연계 식별에 활용 가능
- 동일 사용자를 넓은 범위에서 식별하는 데 유리
- 범용성이 있는 식별값
DI
- 특정 서비스 내부의 중복가입 확인에 적합
- 동일 사용자의 가입 이력 확인에 유리
- 로컬 성격이 강한 식별값
정리하면 아래처럼 이해하면 된다.
CI는 연계 중심의 식별값이고,
DI는 내부 중복 확인 중심의 식별값이다.
이 한 줄로 기억해두면 헷갈릴 일이 많이 줄어든다.
5. 왜 이런 개념을 알아야 할까?
처음에는 이게 그냥 인증사 문서에 나오는 용어처럼 보일 수 있다.
하지만 실제로는 회원 정책, 계정 설계, 예외 처리 방식까지 연결된다.
예를 들어 이런 판단이 필요하다.
5.1 기존 회원 식별
사용자가 다시 본인인증했을 때
기존 회원으로 볼 것인지, 신규 회원으로 볼 것인지 판단해야 한다.
5.2 중복가입 방지
같은 사람이 여러 번 가입하는 것을 어디까지 막을지 정해야 한다.
5.3 탈퇴 후 재가입 정책
탈퇴한 회원이 다시 가입했을 때
이전 이력을 어떻게 볼 것인지도 정책에 따라 달라진다.
5.4 외부 서비스 연계
제휴 서비스나 계열 서비스와 사용자를 연결해야 한다면
어떤 기준값을 사용할지 명확해야 한다.
즉, CI와 DI는 단순히 응답 필드 하나의 문제가 아니라
서비스가 사용자를 어떤 기준으로 식별할 것인지에 대한 설계 문제이다.
6. 무조건 CI가 더 좋은 걸까?
이 부분은 처음 보면 오해하기 쉽다.
CI가 더 넓은 범위에서 식별할 수 있으니
“그럼 CI만 쓰면 되는 거 아닌가?”라고 생각할 수 있다.
하지만 실무에서는 그렇게 단순하게 보면 안 된다.
왜냐하면 서비스마다 필요한 식별 수준이 다르기 때문이다.
- 서비스 간 사용자 연계가 필요하다면 CI가 더 적합할 수 있다.
- 내부 중복가입 확인 정도만 필요하다면 DI로 충분할 수도 있다.
- 불필요하게 넓은 범위의 식별 체계를 도입하면 오히려 과한 설계가 될 수 있다.
기술적으로 더 강해 보이는 값을 쓰는 게 항상 정답은 아니다.
중요한 건 우리 서비스 요구사항에 맞는가이다.
즉, 먼저 정해야 할 질문은 이것이다.
우리 서비스는 사용자를 어디까지 식별해야 하는가?
이 질문이 먼저 정리되어야
CI를 중심으로 볼지, DI를 중심으로 볼지 판단할 수 있다.
7. 개발 관점에서 주의할 점
CI/DI는 인증 연동만 끝났다고 끝나는 영역이 아니다.
실제로는 그 이후가 더 중요하다.
예를 들어 아래 같은 부분은 반드시 같이 봐야 한다.
- 회원 테이블에서 어떤 값을 식별 기준으로 저장할지
- 재인증 시 기존 회원과 어떤 기준으로 매핑할지
- 중복가입 차단 기준을 어디까지 둘지
- 탈퇴 회원 처리와 재가입 정책을 어떻게 가져갈지
- 개인정보 최소 수집 원칙과 충돌하지 않는지
여기서 중요한 건
값을 받는 것과 그 값을 정책적으로 사용하는 것은 완전히 다른 문제라는 점이다.
API 연동이 끝나면 구현이 끝난 것처럼 느껴질 수 있다.
그런데 실제 운영에서는
식별값 하나 때문에 회원정책, 예외처리, 고객문의 대응 방식까지 다 달라질 수 있다.
그래서 CI/DI는
“인증 API 응답값”으로만 보면 안 되고
회원 식별 정책의 일부로 봐야 한다.
8. 정리
CI와 DI는 둘 다 본인확인 과정에서 등장하는 값이지만
역할은 분명히 다르다.
- CI: 서비스 간 연계 식별에 더 적합
- DI: 서비스 내부 중복가입 확인에 더 적합
결국 중요한 것은
CI와 DI의 정의를 외우는 것이 아니라
우리 서비스가 사용자를 어떤 범위까지 식별해야 하는지를 먼저 정하는 것이다.
본인인증 연동을 준비하고 있다면
API 명세를 보기 전에 먼저 아래 질문부터 해보는 것이 좋다.
- 우리는 기존 회원을 어떤 기준으로 식별할 것인가?
- 중복가입은 어디까지 막을 것인가?
- 외부 서비스와 사용자 연계가 필요한가?
이 기준이 정리되면
CI와 DI도 훨씬 덜 헷갈리게 보이게 된다.
마무리
처음에는 CI와 DI가 이름도 비슷하고 둘 다 인증 결과처럼 보여서 헷갈리기 쉽다.
하지만 조금만 기준을 잡고 보면 생각보다 차이는 명확하다.
CI는 연계,
DI는 내부 중복 확인이다.
실무에서는 이 차이를 정확히 이해하고 있어야
회원가입, 본인인증, 계정 통합, 중복가입 방지 같은 정책을 설계할 때 덜 흔들리게 된다.
