
이번 포스팅은 람다(Lambda)에 대해서 정리하는 시간을 가지려고 한다.
처음 자바를 공부할 때, Lambda는 가독성 측면에서 나쁘게 작용하기 때문에, 가급적 사용하는 것을 지양해야 한다고 배웠다.
하지만 함수형 프로그래밍이 대세인 만큼 지금은 람다, 스트림은 개발할 때 빼놓을 수 없는 요소인 것 같다.
함수형 프로그래밍
점점 함수적 프로그래밍이 부각되어 가고있다.
그 이유는 병렬 처리와 이벤트 지향 프로그래밍에 적합하기 때문이다.
그래서 객체 지향 프로그래밍과 함수적 프로그래밍을 혼합함으로써
더욱 효율적인 프로그래밍이 될 수 있도록 프로그래밍 개발 언어들은 변해가고 있다.
람다에 대해서 알아보도록 하자.
우선 람다란
람다식 (Lambda)
람다 = 익명함수
람다는 익명 함수(anonymous function)를 생성하기 위한 식으로 객체 지향 언어보다는 함수지향 언어에 가깝다.
익명함수란?
익명함수란 함수의 이름이 없는 함수이다.
익명함수들은 공통으로 "일급객체"라는 특징을 가지고 있다.
일급 객체란 일반적으로 다른 객체들에 적용 가능한 연산을 모두 지원하는 개체를 말한다.
즉, 함수를 값으로 사용할 수도 있고, 파라미터로 전달 및 변수에 대입하기등의 연산들도 가능하다.
람다식을 이용해서 자바 코드를 매우 간결하고, 컬렉션의 요소를 필터링하거나 매핑해서 원하는 결과를 쉽게 집계할 수 있다.
람다식의 형태는 매개 변수를 가진 코드 블록이지만, 런타임 시에 익명 구현 객체(익명 함수)를 생성해서 타겟 타입을 구현한다.
람다식의 장단점
장점
- 코드의 간결성 : 람다를 사용하면 불필요한 반복문의 삭제가 가능하며, 복잡한 식을 단순하게 표현할 수 있다.
- 생산성 증가 : 함수를 만드는 과정이 생략되고 필요한 시점에 익명 구현 객체를 구현하여 사용하기 때문에 생산성이 증가한다.
- 병렬처리 가능 : 멀티 쓰레드를 활용하여 병렬처리를 사용할 수 있다.
- 지연연산 수행 : 람다는 지연연산을 수행 함으로써 불필요한 연산을 최소화 할 수 있다.
단점
- 람다식의 호출이 까다롭다.
- 람다 stream 사용 시 단순 루프 문보다 성능이 떨어진다.
- 디버깅이 까다롭다.
- 불필요하게 사용할 경우 오히려 가독성을 해칠 수 있다.
- 재귀 호출을 할 경우 효율적이지 않다.
람다의 표현식
람다는
1. 매개변수
2. 화살표(->)
3. 함수몸체
위 세가지를 이용하여 사용한다.
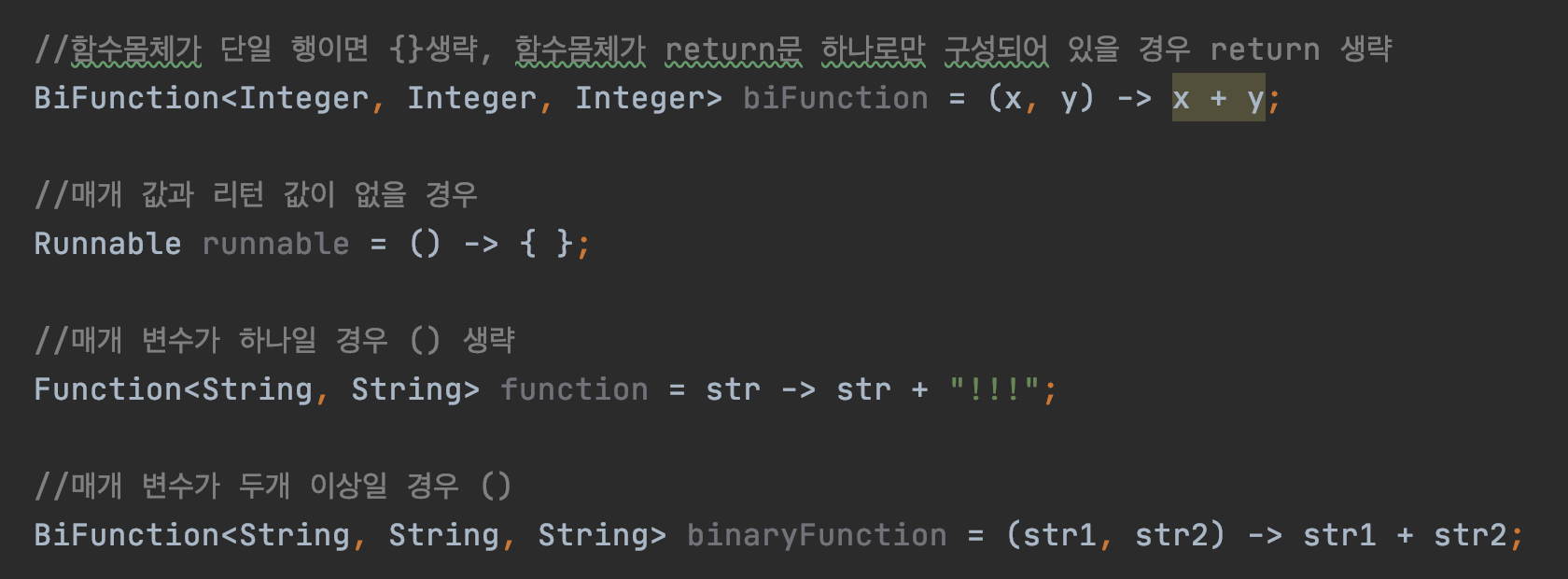
- 함수몸체가 단일 실행문일 경우 중괄호{}를 생략할 수 있다.
- 함수몸체가 리턴문으로만 이루어져 있을 경우 return은 생략한다.
BiFunction<Integer, Integer, Integer> biFunction = (x, y) -> x + y;- 매개 변수와 리턴 값이 없을 경우 () -> {...}
Runnable runnable = () -> { };- 매개 변수가 하나일 땐 ()를 생략 가능하고, 2개 이상일 때 ()를 사용한다.
//매개 변수가 하나일 경우 () 생략
Function<String, String> function = str -> str + "!!!";
//매개 변수가 두개 이상일 경우 ()
BiFunction<String, String, String> binaryFunction = (str1, str2) -> str1 + str2;
- BiFunction, Function은 아래 쪽 표준 API 함수적 인터페이스에서 다루겠다.
함수적 인터페이스
@FunctionalInterface
Functional Interface는 일반적으로 '구현해야 할 추상 메소드가 하나만 정의된 인터페이스'를 뜻한다.
익명 함수(익명 구현 객체)를 구현해서 타겟 함수에 대입해야 하는데 추상 메소드가 두 개 일경우 어떤 추상 메소드에 대한 구현인지 알 수 없기 때문이다.
이 함수적 인터페이스를 작성할 때, 두 개 이상의 추상 메서드가 선언되지 않도록 컴파일러가 체킹해주는 기능이 있다.
인터페이스 선언 시 @FunctionalInterface 어노테이션을 선언해주면 된다. 굉장히 간단하다.
@FunctionalInterface 어노테이션을 선언하면 두 개 이상의 추상 메서드를 선언할 시 오류가 발생한다.
@FunctionalInterface
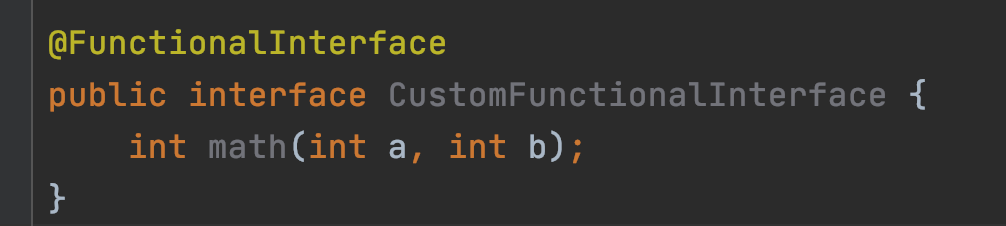
public interface CustomFunctionalInterface {
int math(int a, int b);
}
CustomFunctionalInterface customFunctionalInterface = (a, b) -> a + b;위 코드는 함수형 인터페이스 CustomFunctionalInterface를 정의하고, CustomFunctionalInterface를 a + b로 구현한 코드이다.
굉장히 간단한 예지만, 직접 함수형 인터페이스를 정의하고 람다식을 이용해 필요에 따라 구현하여 사용할 수 있다.
표준 API 함수적 인터페이스
자바는 함수적 인터페이스 java.util.function 표준 API패키지를 제공한다.
표준 API에서 한 개의 추상 메서드를 가지는 인터페이스들은 모두 람다식을 이용해서 익명 구현 객체로 표현이 가능하다.
이 표준 API 패키지에서 제공하는 함수적 인터페이스의 목적은 메서드 또는 생성자의 매개 타입으로 사용되어 람다식을 대입할 수 있도록 하기 위함이다.
java.util.function 패키지의 함수적 인터페이스는 크게
-
Consumer(소비)
-
Supplier(공급)
-
Function(매핑)
-
Operator(연산)
-
Predicate(비교)
5가지로 구분된다. 구분 기준은 인터페이스에 선언된 추상 메서드의 매개 값과 리턴 값의 유무, 타입이다.
| 종류 | 특징 |
|---|---|
| Consumer | 매개 값은 있고, 리턴 값은 없음 |
| Supplier | 매개 값은 없고, 리턴 값은 있음 |
| Function | 매개 값도 있고, 리턴 값도 있음 - 주로 매개 값을 리턴 값으로 매핑(타입변환) |
| Operator | 매개 값은 있고, 리턴 값은 없음 - 주로 매개값을 연산하고 결과를 리턴 |
| Predicate | 매개 값은 있고, 리턴 값은 없음 - 매개 값을 검사하여 boolean 리턴 |
Consumer
Consumer 함수적 인터페이스의 특징은 리턴 값이 없는 accept() 메서드를 가지고 있다.
accept() 메서드는 매개값을 소비하고 리턴하지 않는다.
| 인터페이스명(타겟타입) | 추상 메서드 | 설명 |
|---|---|---|
Consumer<T> | void accept(T t) | 객체 T를 받아 소비 |
| BiConsumer<T, U> | void accept(T t, U u) | 객체 T와 U를 받아 소비 |
| DoubleConsumer | void accept(double value) | double 값을 받아 소비 |
| IntConsumer | void accept(int value) | int 값을 받아 소비 |
| LongConsumer | void accept(long value) | long 값을 받아 소비 |
ObjDoubleConsumer<T> | void accept(T t, double value) | 객체 T와 double 값을 받아 소비 |
ObjIntConsumer<T> | void accept(T t, int value) | 객체 T와 int 값을 받아 소비 |
ObjLongConsumer<T> | void accept(T t, long value) | 객체 T와 long 값을 받아 소비 |
아래와 같이 사용할 수 있다.
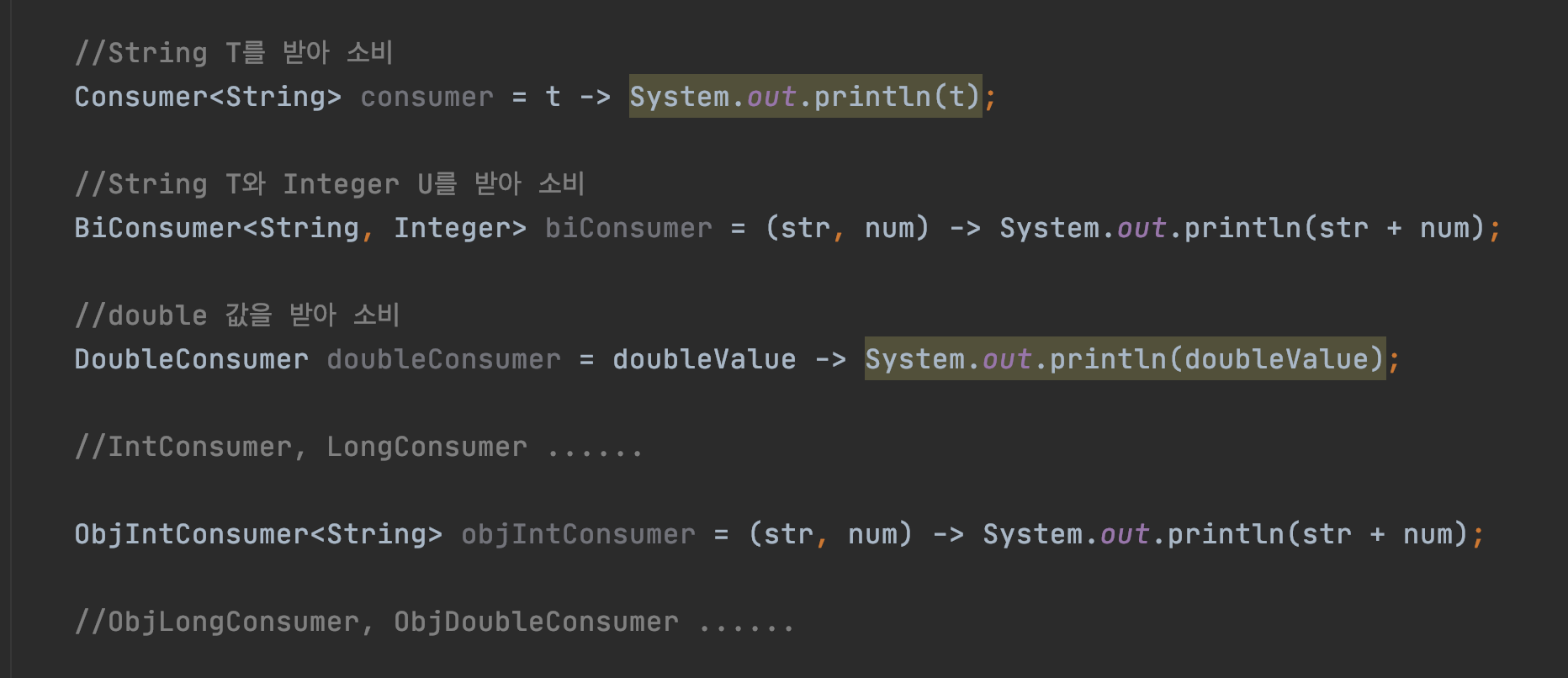
//String T를 받아 소비
Consumer<String> consumer = t -> System.out.println(t);
//String T와 Integer U를 받아 소비
BiConsumer<String, Integer> biConsumer = (str, num) -> System.out.println(str + num);
//double 값을 받아 소비
DoubleConsumer doubleConsumer = doubleValue -> System.out.println(doubleValue);
//IntConsumer, LongConsumer ......
ObjIntConsumer<String> objIntConsumer = (str, num) -> System.out.println(str + num);
//ObjLongConsumer, ObjDoubleConsumer ......Supplier
Supplier 함수적 인터페이스의 특징은 매개 변수가 없고 리턴 값이 있는 get() 메서드를 가진다.(Consumer와 반대)
이 메서드는 실행 후 호출한 곳으로 데이터를 리턴(공급)할 때 사용된다.
| 인터페이스명(타겟타입) | 추상 메서드 | 설명 |
|---|---|---|
Supplier<T> | T get(T t) | 객체 T를 리턴 |
| BooleanSupplier | boolean getAsBoolean(T t, U u) | boolean 값을 리턴 |
| DoubleConsumer | double getAsDouble(double value) | double 값을 리턴 |
| IntConsumer | int getAsInt(int value) | int 값을 리턴 |
| LongConsumer | long getAsLong(long value) | long 값을 리턴 |
아래와 같이 사용할 수 있다.

//IntSupplier
IntSupplier intSupplier = () -> (int) (Math.random() * 6) + 1;
int num = intSupplier.getAsInt();
//Supplier<T>
Supplier<Map<String, String>> getAsMap = HashMap::new;
Map<String, String> map = getAsMap.get();Function
| 인터페이스명(타겟타입) | 추상 메서드 | 설명 |
|---|---|---|
| Function<T, R> | R apply(T t) | 객체 T를 객체 R로 매핑 |
| BiFunction<T, U, R> | R apply(T t, U u) | 객체 T와 U를 객체 R로 매핑 |
DoubleFunction<R> | R apply(double value) | double을 객체 R로 매핑 |
IntFunction<R> | R apply(int value) | int를 객체 R로 매핑 |
| IntToDoubleFunction | double applyAsDouble(int value) | int를 double로 매핑 |
| IntToLongFunction | long applyAsLong(int value) | int를 long으로 매핑 |
| LongToDoubleFunction | double applyAsDouble(long value) | long을 double로 매핑 |
| LongToIntFunction | int applyAsInt(long value) | long을 int로 매핑 |
| ToDoubleBiFunction<T, U> | double applyAsDouble(T t, U u) | 객체 T와 객체 U를 double로 매핑 |
ToDoubleFunction<T> | double applyAsDouble(T t) | 객체 T를 double로 매핑 |
| ToIntBiFunction<T, U> | int applyAsInt(T t, U u) | 객체 T와 객체 U를 int로 매핑 |
ToIntFunction<T> | int applyAsInt(T t) | 객체 T를 int로 매핑 |
| ToLongBiFunction<T, U> | long applyAsLong(T t, U u) | 객체 T와 객체 U를 long으로 매핑 |
ToLongFunction<T> | long applyAsLong(T t) | 객체 T를 long으로 매핑 |
아래와 같이 사용할 수 있다.
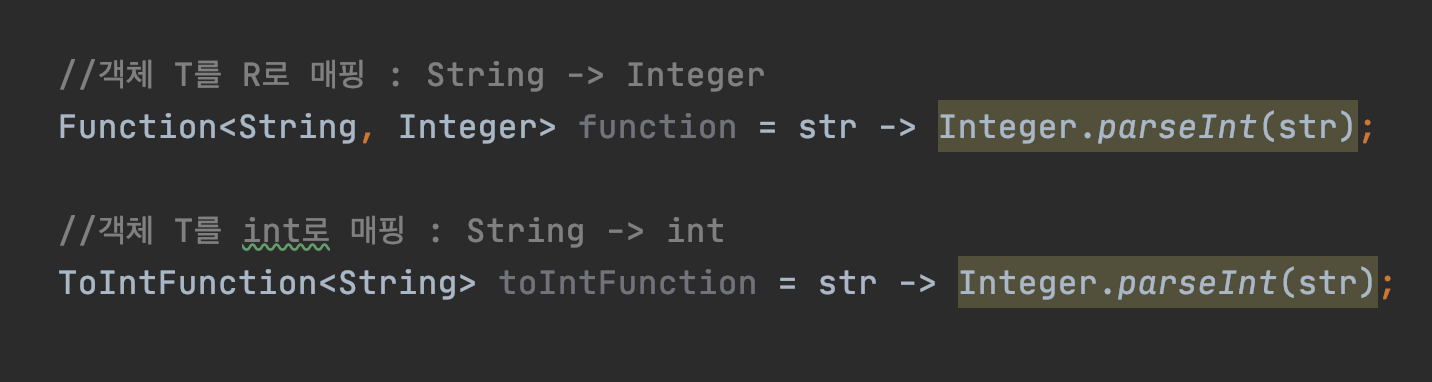
//객체 T를 R로 매핑 : String -> Integer
Function<String, Integer> function = str -> Integer.parseInt(str);
//객체 T를 int로 매핑 : String -> int
ToIntFunction<String> toIntFunction = str -> Integer.parseInt(str);Operator
Operator 함수적 인터페이스는 Function과 동일하게 매개 변수와 리턴 값이 있는 applyXXX()메소드를 가지고 있다.
Function의 applyXXX()와 다른점은, 매개 값을 리턴 값으로 매핑하는 역할이 아니라 매개 값을 이용하여 연산을 수행한 후 동일한 타입으로 리턴한다.
| 인터페이스명(타겟타입) | 추상 메서드 | 설명 |
|---|---|---|
BinaryOperator<T> | BiFunction<T, U, R>의 하위 인터페이스 | T와 U를 연산한 후 R 리턴 |
UnaryOperartor<T> | Function<T, R>의 하위 인터페이스 | T를 연산한 후 R 리턴 |
| DoubleBinaryOperator | double applyAsDouble(double, double) | 두 개의 double 연산 |
| DoubleUnaryOperator | double applyAsDouble(double) | 한 개의 double 연산 |
| IntBinaryOperator | int applyAsInt(int, int) | 두 개의 int 연산 |
| IntUnaryOperator | int applyAsInt(int) | 한 개의 int 연산 |
| LongBinaryOperator | long applyAsLong(long, long) | 두 개의 long 연산 |
| LongUnaryOperator | long applyAsLong(long) | 한 개의 long 연산 |
아래와 같이 사용할 수 있다.
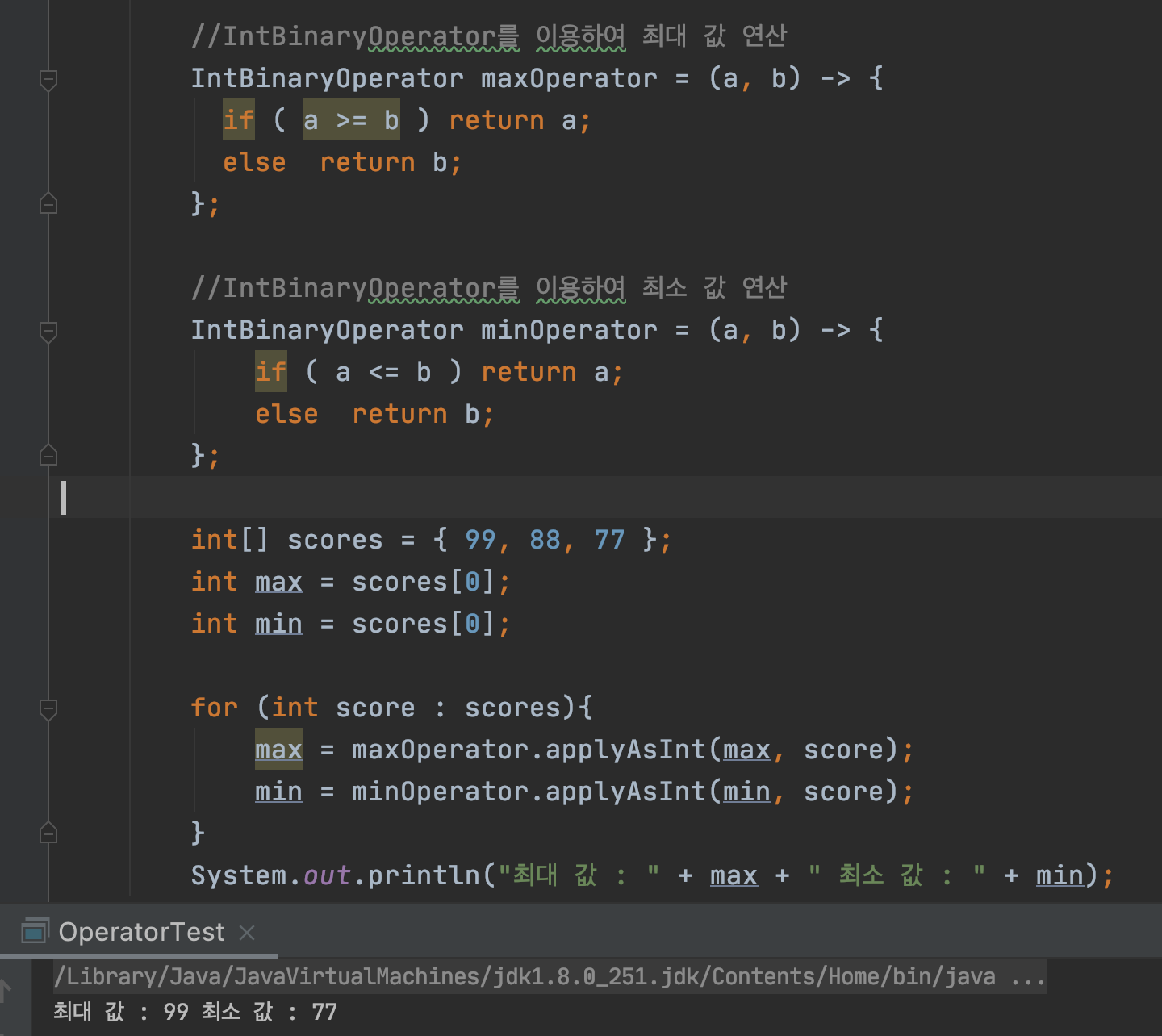
//IntBinaryOperator를 이용하여 최대 값 연산
IntBinaryOperator maxOperator = (a, b) -> {
if ( a >= b ) return a;
else return b;
};
//IntBinaryOperator를 이용하여 최소 값 연산
IntBinaryOperator minOperator = (a, b) -> {
if ( a <= b ) return a;
else return b;
};
int[] scores = { 99, 88, 77 };
int max = scores[0];
int min = scores[0];
for (int score : scores){
max = maxOperator.applyAsInt(max, score);
min = minOperator.applyAsInt(min, score);
}
System.out.println("최대 값 : " + max + " 최소 값 : " + min);Predicate
Predicate 함수적 인터페이스는 매개 변수와 boolean 리턴 값이 있는 test() 메서드를 가지고 있다. 이 메서드는 매개 값을 비교하고 boolean 값을 리턴한다.
| 인터페이스명(타겟타입) | 추상 메서드 | 설명 |
|---|---|---|
| BiPredicate<T, U> | boolean test(T t, U u) | 객체 T와 U를 비교 |
| DoublePredicate | boolean test(double value) | double 값을 비교 |
| IntPredicate | int test(int value) | int 값을 비교 |
| LongPredicate | boolean test(long value) | long 값을 비교 |
아래와 같이 사용한다.
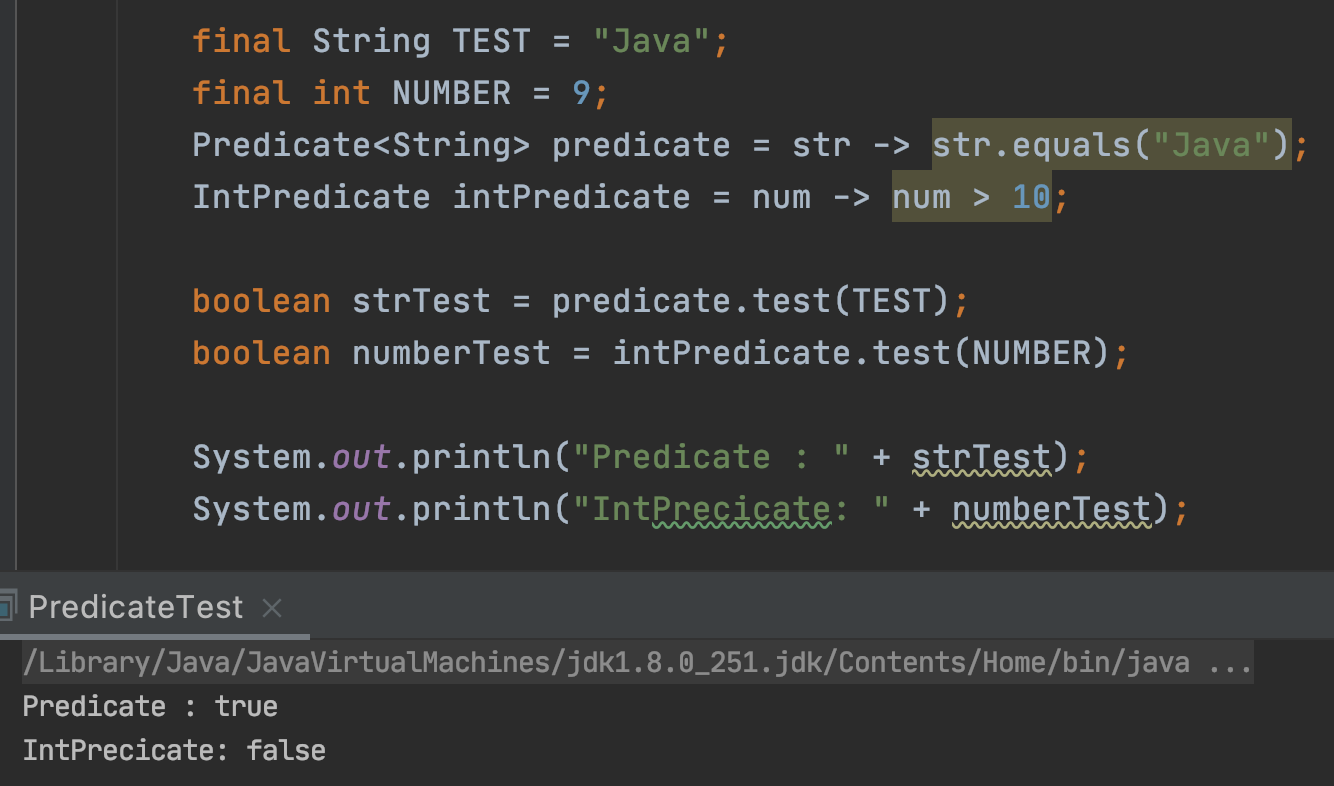
final String TEST = "Java";
final int NUMBER = 9;
Predicate<String> predicate = str -> str.equals("Java");
IntPredicate intPredicate = num -> num > 10;
boolean strTest = predicate.test(TEST);
boolean numberTest = intPredicate.test(NUMBER);
System.out.println("Predicate : " + strTest);
System.out.println("IntPrecicate: " + numberTest);
