
Section 01
Goal
컬렉션 프레임워크에 대해 간략히 정리 해보자.
Set< E > 인터페이스를 구현하는 컬렉션 클래스
- 집합의 특징을 갖는다.
중복을 허용하지 않는 특징을 갖는다.순서가 유지되지 않는 특징을 갖는다.
HashSet< E >
public static void main(String[] args) {
// TODO Auto-generated method stub
Set<String> set = new HashSet<>();
set.add("Toy");
set.add("Robot");
System.out.println("인스턴스의 수 : " + set.size());
for(Iterator<String> itr = set.iterator(); itr.hasNext();) {
System.out.println(itr.next() + '\t');
System.out.println();
}
for(String s : set) {
System.out.println(s + "\t");
System.out.println();
}
}동일 Instance가 되는 기준은 무엇인가?
-
public boolean
equals(Object obj)Object클래스의equals 메소드호출 결과를 근거로 동일 Instance를 판단 한다.
-
public int
hashCode()- 그런데 그에 앞서
Object 클래스의 hashCode 메소드호출 결과가 같아야 한다. - Object 클래스의
hashCode() 메소드를 통해 저장되는 데이터의 부류를 나눈다.- 쉽게 말해
분류를 A, B, C, D로 구분한 후 들어오는 값을 Object의 equals 메소드를 통해 구분.
- 쉽게 말해
- 그런데 그에 앞서
Hash 알고리즘(분류 기법 알고리즘)
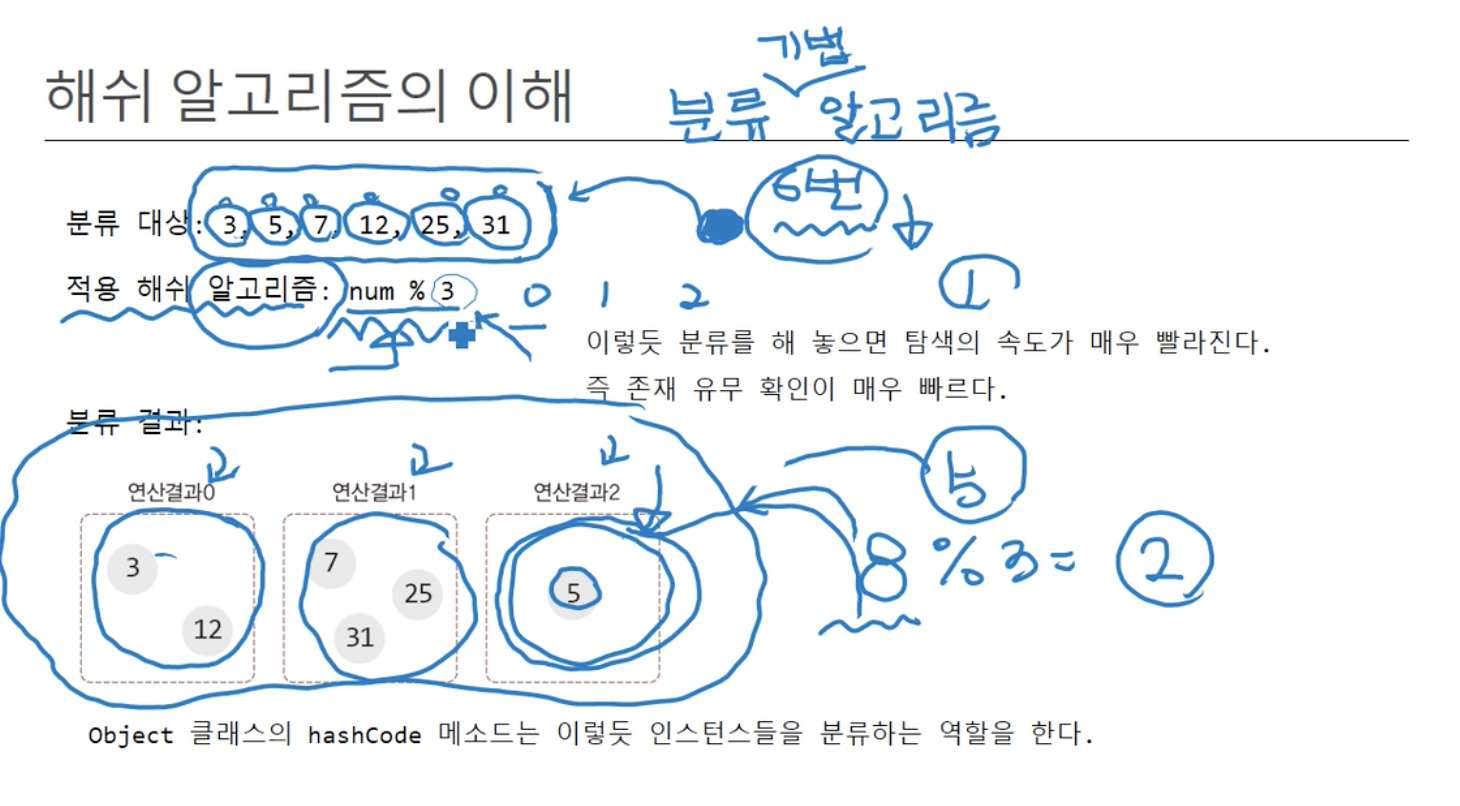
분류 대상이 하나의 집합이 된다.- 해당 집합에 데이터를 추가할 시 하나의 Instance와 들어오는 값을 일일이 비교 해야 한다면?
- 적용 Hash 알고리즘 :
num % 3- 여기서 3은 몇 가지의 부류로 나눌지 결정하는 숫자를 의미한다
- ex : 3 →
3 부류 - ex : 100 →
100 부류
- ex : 3 →
- 여기서 3은 몇 가지의 부류로 나눌지 결정하는 숫자를 의미한다
- 위 같이 분류를 하면 탐색의
속도가 매우 빨라진다. - 저장되는 Instance의 수는 제어할 수 없지만,
Hash 알고리즘을 통해 탐색의속도 증가.
- 적용 Hash 알고리즘 :
변하지 않는 기본 원칙
class Num {
private int num;
public Num(int n) {
this.num = n;
}
@Override
public int hashCode() {
return num % 3; // num의 값이 같으면 부류도 같다.
}
@Override
public boolean equals(Object obj) {
if(num == ((Num)obj).num) {
return true;
} else {
return false;
}
}
}
class car {
private String model;
private String color;
@Override
public int hashCode() {
return (model.hashCode() + color.hashCode()) / 2;
}
/**
* 모든 인스턴스 변수의 정보를 다 반영하여 해쉬 값을 얻으려는 노력이 깃든 문장.
* 결과적으로 더 세밀하게 나뉘고, 따라서 그만큼 탐색 속도가 높아진다.
*/
}모든 정보를 전부 반영하여 HashCode의 값을 반영하라?
무슨 소리인지 생각 해봐야 할듯..
Hash 알고리즘을 일일이 정의하기 조금 그렇다면
- public static int
hash(Object...values)java.util.Objects에 정의된 메소드, 전달된 인자 기반의 해쉬 값 반환.
@Override
public int hashCode() {
return Objects.hash(model, color);
}TreeSet< E >
set< E > 인터페이스를 구현하는 Tree< E > 클래스
TreeSet< E >의 특징
중복을 허용하지 않는다.순차적인 저장을 지원하지 않는다.- HashSet< E >과 마찬가지로
집합을 통해 데이터를 저장 한다.
TreeSet< E >의 값 참조 순서
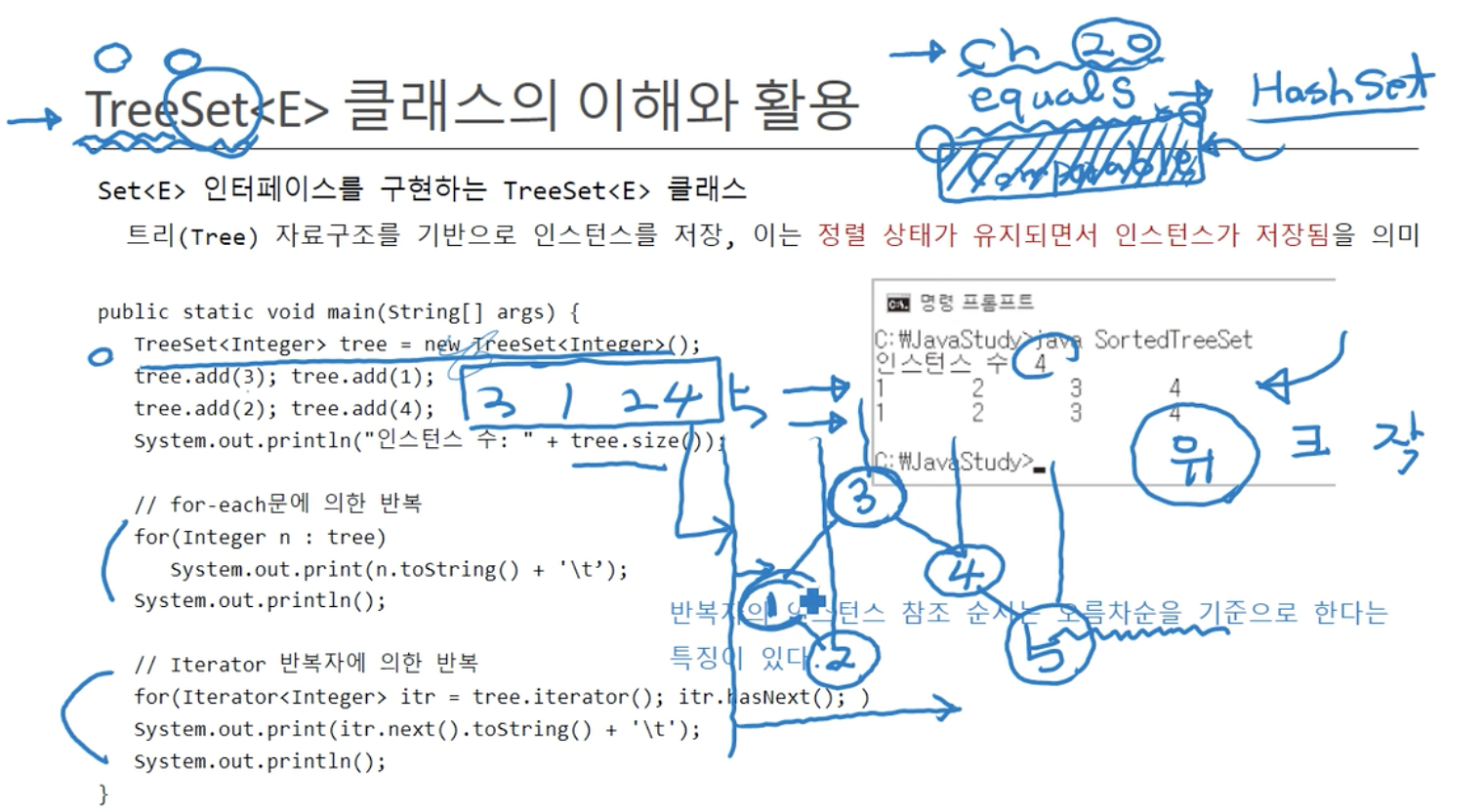
오름 차순기준으로 값의 참조가 이루어진다 → 즉 오름 차순으로 데이터를 가져온다.- 하지만
Instance가 저장이 되는데 어떤기준으로 데이터의 오름 차순을 결정 할 것 인가?- 이러한 상황에서의 정렬 기준은 프로그래머가 정하기 나름이다.
Comparable Interface의 구현을 통하여두 Instance의 크고 작음을결정할 수 있다.- Comparable Interface가 구현하고 있는
compareTo(Object o)를 구현하여 사용.
- Comparable Interface가 구현하고 있는
Comparable Interface's compareTo()
interface Comparable → interface Comparable< T >
-
int compareTo(Object o) → int compareTo(T o)
- 인자로 전달된 o가 작다면
양의 정수반환. - 인자로 전달된 o가 크다면
음의 정수반환. - 인자로 전달된 o가 같다면
0을 반환.
따라서 TreeSet< T >에 저장할 Instance들은 모두 Comparable< T > 인터페이스를 구현한 클래스의
- 인자로 전달된 o가 작다면
Instance이어야 한다. 아니면 예외 발생!!
Comparable< T > 가 아닌 ComparaTor< T > 인터페이스?
-
String 클래스의 정렬 기준은 사전 편찬 순으로 compareTo()를 구현 하고 있다.
-
하지만 정렬 기준을 변경하고 싶은 상황에서는?
- TreeSet< E > 인터페이스는 위 같은 상황을 해결하기 위한
생성자를 제공 한다. - public TreeSet( Comparator<? super E> comparator )
- TreeSet< E > 인터페이스는 위 같은 상황을 해결하기 위한
-
위 같은 기능을 제공 받기 위해서 해당 클래스는
ComparaTor<T> 인터페이스를 구현해야 한다.
class PersonComparator implements Comparator<Person> {
public int compare(Person p1, Person p2) {
return p2.age - p1.age;
// p2 : 50 - p1 : 4
}
}
public static void main(Stirng[] args) {
TreeSet<Person> tree = new TreeSet<>(new PersonComparator());
tree.add(new Person("Yoon", 37));
tree.add(new Person("Hong", 53));
tree.add(new Person("Park", 22));
for(Person p : tree) {
System.out.println(p);
}
}- p1이 p2보다 크면
양의 정수반환. - p1이 p2보다 작으면
음의 정수반환. - p1과 p2가 같다면
0을 반환. 기존 Comparable<T> Interface의 compareTo()를 무시 한다.
중복된 Instance의 삭제
public static void main(String[] args) [
List<String> lst = Arrays.asList("A", "B", "C", "A");
ArrayList<String> list = new ArrayList<>(lst);
for(String s : list)
System.out.println(s.toString() + "\t");
System.out.println();
// 중복된 인스턴스를 걸러 내기 위한 작업
HashSet<String> set = new HashSet<>(list);
// 원래대로 ArrayList<String> 인스턴스로 저장물을 옮긴다.
list = new ArrayList<>(set);
for(String s : list)
System.out.println(s.toString() + "\t");
System.out.println();
}
https://ym1085.github.io