Encoding, Decoding
인코딩과 디코딩은 문자의 형태를 바꾸는 것이다.
Encoding(en + code) 라는 단어에서 추측할 수 있듯이 보통 영어, 한글, 숫자와 같이 인간이 알아볼 수 있는 문자를 0과 1로 이루어진 바이트 코드로 바꾸는 것이 인코딩, 반대로 바이트 코드에서 인간이 알아볼 수 있는 문자로 바꾸는 것이 디코딩이다.
인코딩 방식에는 대표적으로 ASCII, UTF-8, BASE64가 있다.
Encoding을 왜 사용할까?
인코딩을 사용하는 이유는 사람이 인식하는 문자를 컴퓨터는 인식할 수 없기 때문이다. 컴퓨터는 0과 1로 이루어진 바이트 코드만을 읽을 수 있다. 그런 컴퓨터에게 문자를 출력하게 하려면 어떻게 해야할까? 'A'라는 문자를 'A'로 출력하도록 하기 위해서는 컴퓨터와 인간이 'A'를 바이트 코드로 어떻게 표현할지 약속을 정해서 그 약속을 바탕으로 통신하면 된다. 예를 들어, 'A'를 100010으로 표현하자고 약속하면 인간은 컴퓨터에게 100010을 출력하라고 명령한다. 그럼 컴퓨터는 인간과 했던 약속을 바탕으로 100010이 'A'를 나타내는 바이트 코드임을 알게 되고 'A'를 출력할 것이다. 이 약속을 어떻게 하냐에 따라 인코딩 방식이 다른 것이다.
인코딩 종류
ASCII
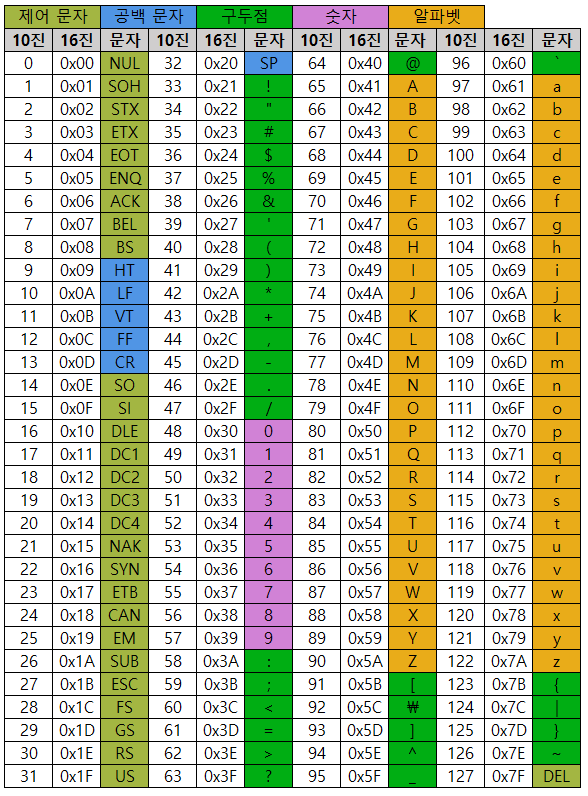
가장 초창기 인코딩 방식이다. 숫자, 영어, 기호 그리고 제어문자를 표현할 수 있다.
ASCII(아스키코드)는 1바이트로 나타낸다. 실제 아스키코드에 정의되어 있는 문자는 128(2^7)개로 7비트만 사용하면 되지만 나머지 1비트를 오류 검출용으로 시스템별로 상이하게 사용한다.
UTF-8
유니코드 테이블
앞서 살펴본 ASCII는 영어만 담고 있기 때문에 영어 이외의 문자를 사용하는 지역에서는 자신들의 모국어를 컴퓨터에 표현할 수 없는 문제가 발생했다. 이 문제를 해결하기 위해 등장한 것이 전 세계의 모든 문자, 기호를 집어넣은 유니코드이다.
4바이트의 공간을 사용하여 이론상 2^32(약 40억)개의 문자를 담을 수 있는 공간이 있지만, 현재는 0x10FFFF(약 110만)까지만 사용하고 있다.
유니코드에서 표의문자인 한자가 가장 많은 비율을 차지하고 있고 그 다음으로 '가'부터 시작하여 '힣'까지 초성, 중성, 종성의 조합으로 엄청나게 많은 문자를 만들어낼 수 있는 한글이 두 번째로 많은 비율을 차지하고 있다.
한글 in 유니코드 테이블
알다시피 한글은 영어와 달리 초성, 중성, 종성의 조합으로 하나의 음절을 이루고 있다. 따라서 유니코드에서 한글을 표현하는데 음절형, 조합형 두 가지 방식을 사용하고 있다.
먼저, 음절형은 '가'부터 '힣'까지 한글의 모든 음절이 유니코드 테이블에 등록되어 있는 방식이다. 한글을 적으면 각 음절에 해당하는 유니코드 테이블 번호를 가져오는 방식이다.
나피리
EB8298(나) ED94BC(피) EBA6AC(리)조합형은 'ㄱ', 'ㅏ', 'ㄴ'와 같은 초성, 중성, 종성이 각각 따로 유니코드 테이블에 등록되어 있는 방식이다. 한글을 적으면 각 음절에 사용된 초성, 중성, 종성의 유니코드 테이블 번호를 가져와서 별도의 연산을 통해 하나의 음절로 조합되는 방식이다.
나피리
E18482(ㄴ) E185A1(ㅏ) E18491(ㅍ) E185B5(ㅣ) E18485(ㄹ) E185B5(ㅣ)UTF-8
앞서 살펴본 유니코드 테이블을 사용하여 인간의 문자를 다양한 방식으로 인코딩 할 수 있다. UTF-8은 이중 가장 대표적인 유니코드 인코딩 방식 중 하나로 가변 길이 인코딩이다.
유니코드의 'A'는 아스키코드와 같이 0x41에 해당하는 문자이다. 이론상 1바이트만 있으면 'A'를 표현할 수 있다. 하지만 유니코드를 표 그대로 사용하면 유니코드는 4바이트이기 때문에 1바이트로 표현할 수 있는 'A'를 4바이트로 표현해야 한다. 3바이트 만큼의 낭비가 생기는 것이다. UTF-8은 이런 낭비를 없애기 위해 1바이트로 표현할 수 있는 문자는 1바이트로, 2바이트로 표현할 수 있는 문자는 2바이트로 표현하는 가변 길이 인코딩 방식이다.
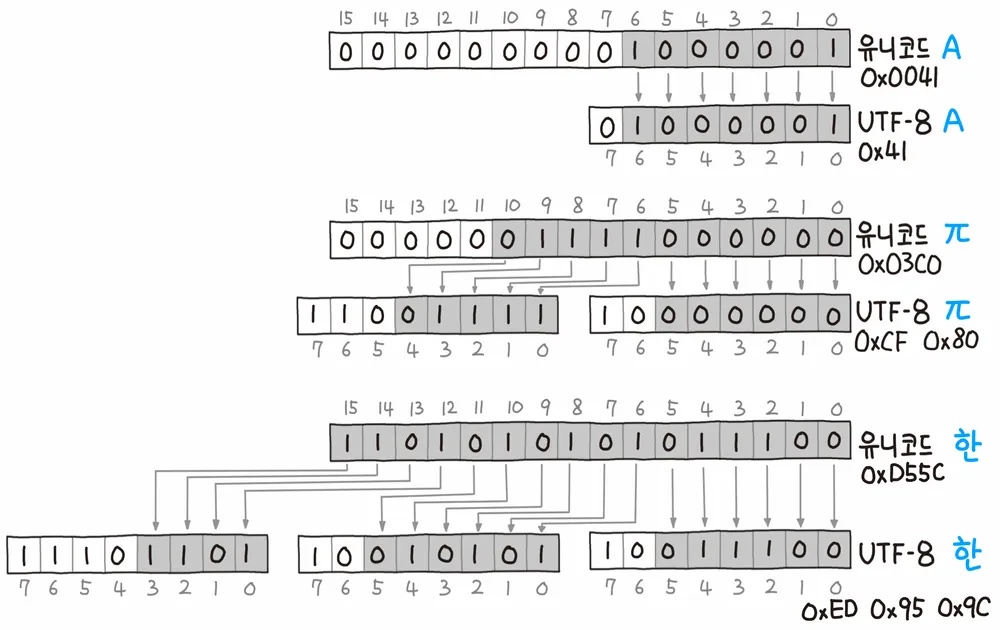
구체적인 가변 길이 인코딩 방식은 위의 사진을 참고하면 된다. 1바이트가 필요한 문자는 0으로 시작하기 때문에 ASCII와 완전히 호환된다.
BASE64
Base64는 8비트 단위의 문자를 6비트 단위로 바꾸는 인코딩 방식이다.
ASCII에서 알파벳 소문자(26개) + 대문자(26개) + 숫자(10개) + 특수문자(2개, +,=)까지 총 64개의 문자만을 사용하여 8비트 단위의 문자열을 6비트 단위로 나누어 재편성하는 인코딩 방식이다.
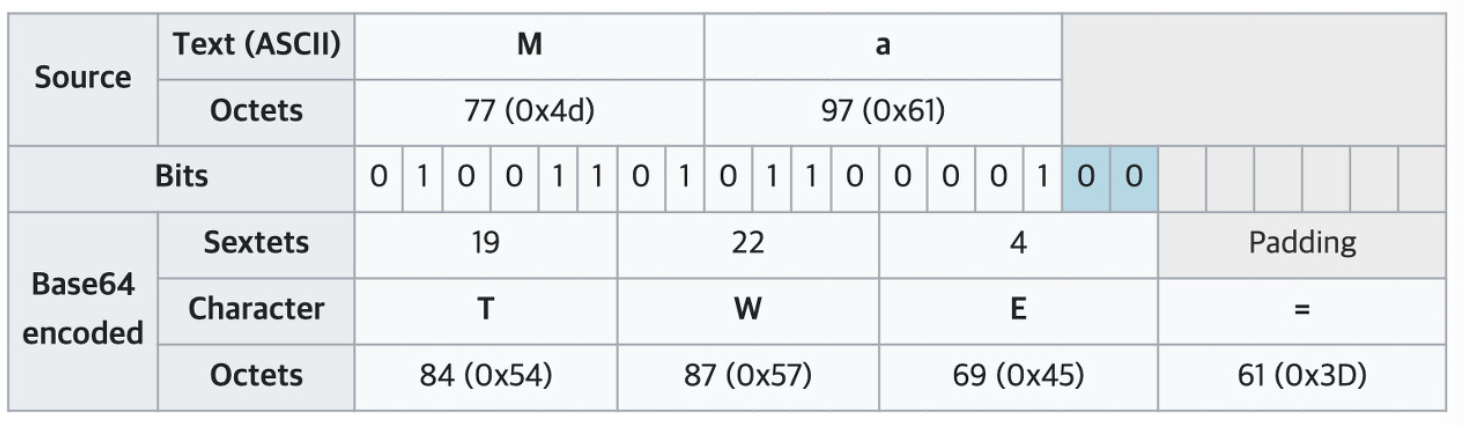
8비트 단위의 문자열을 6비트 단위의 문자열로 나누다보니 8과 6의 최소공배수인 24비트를 채운다. 그렇기 때문에 위의 사진처럼 base64 인코딩 영역이 기존의 8비트 단위의 문자열에 맞지 않는 경우가 있는데 이런 경우에는 0과 padding 문자("=")를 넣어서 24비트를 채워준다.
6비트로 나눠진 문자를 다시 문자로 나타낼 때는 8비트의 아스키코드에 매핑하여 나타낸다. 8비트짜리 문자열로 이루어진 데이터를 6비트로 나누고, 나누어진 6비트를 다시 8비트짜리 아스키코드 중 문자 + 숫자 + = 으로 매핑하는 것이다. 인코딩이 이런 방식으로 진행되다보니 예시로 3바이트(24비트)짜리 문자열이 4바이트(32비트)가 되면서 데이터의 크기가 약 1.25배만큼 만큼 커진다.
base64를 사용하면 데이터의 크기가 커지는데 왜 base64를 사용할까? 이메일과 같은 텍스트 기반 프로토콜에서 바이너리 데이터를 안전하게 전송하기 위해서이다. base64에서 사용되는 문자(알파벳, 숫자)가 아닌 제어문자는 텍스트 영역에서 특별한 용도로 사용되기 때문에 이 제어문자를 포함한 ASCII를 이용해 데이터를 전달하는데는 문제점이 발생할 수 있다. 또한, ASCII에서 오류 검출을 위해 사용하는 1개의 비트도 시스템별로 사용 용도가 다르기 때문에 ASCII를 이용한 데이터 교환은 통신에 참여하는 시스템에 따라 데이터에 변형을 일으킬 수 있다. 따라서, 시스템별로 다른 요소도 없고 텍스트를 이용해 데이터를 안전하게 전송할 수 있는 base64를 사용하는 것이다.
파이썬 string의 인코딩 방식
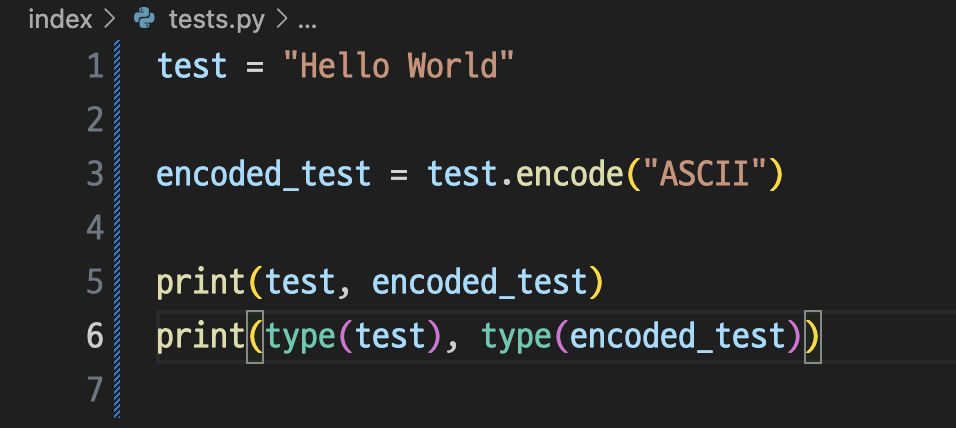
<class 'str'> <class 'bytes'>파이썬에서 string 자료형과 인코딩된 데이터의 자료형을 확인하면 인코딩하기 전의 자료형은 string 자료형, 인코딩된 데이터는 bytes 자료형으로 표시되는 것을 볼 수 있다. 인코딩된 데이터는 기계어로 구성되어있기 때문이다.
여기서 의문이 하나 들었다. string 자료형도 컴퓨터가 이해를 하려면 결국 기계어로 인코딩 될 것인데 string 자료형은 어떻게 인코딩이 될 것인지 궁금해졌다.
string 자료형의 인코딩 방식은 string을 구성하고 있는 문자의 종류에 따라 달라진다.
만약 string이 유니코드 기준 1바이트로 표현할 수 있는 문자(ASCII)로만 구성되어 있다면 모든 문자를 1바이트로 나타내는 ASCII를 이용한다.
만약 string이 유니코드 기준 2바이트로 표현할 수 있는 문자(한글, 한자, 기타 다른 모든 언어)가 포함되어 있다면 모든 문자를 2바이트로 나타내는 UCS-2를 이용한다.
만약 string이 유니코드 기준 4바이트로 표현할 수 있는 문자(이모지)가 포함되어 있다면 모든 문자를 4바이트로 나타내는 UCS-4를 이용한다.
아래의 테스트를 통해 원리를 쉽게 이해할 수 있다.
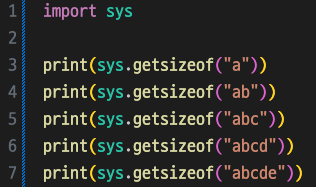
결과
50, 51, 52, 53, 54 (49는 메타데이터 크기)
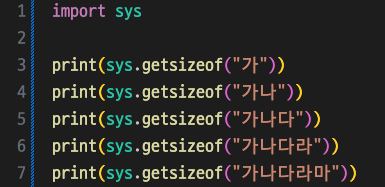
결과
76, 78, 80, 82, 84 (74는 메타데이터 크기)
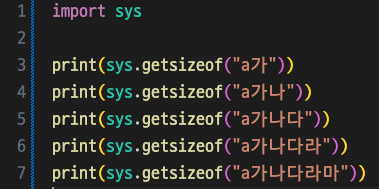
결과
78, 80, 82, 84, 86 (76은 메타데이터 크기)
ASCII표에 포함되는 'a'도 2바이트로 인코딩된 것을 알 수 있다.
인코딩과 암호화의 차이점
인코딩과 암호화는 문자의 형태를 바꾼다는 점에서는 같은 개념인 것 같지만 엄연히 다른 개념이다.
인코딩은 문자를 숨기려는 의도가 없다. UTF-8, ASCII 등 많은 사람들이 알고 있는 일정한 규칙을 이용해 문자의 형태를 바꾼 것이기 때문에 아무나 디코딩을 하여 원문을 확인할 수 있다.
암호화는 문자를 숨기려는 의도가 있다. 이 문자를 볼 권한이 있는 사람들만 알고 있는 key를 이용하여 문자의 형태를 바꾼 것이기 때문에 key가 없는 사람은 원문을 확인할 수 없다.
(굳이 구태여 UTF-8, BASE64등을 이용해서 암호화를 했다고 주장할 수 있지만 흠 전 세계 사람들이 알고있는 알고리즘을 이용해서 문자의 형태를 바꾼 것을 암호화라고 할 수 있을까?)
