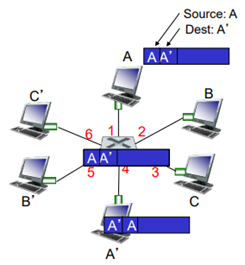
Network Layer: The Data Plane
Data plane에서 봐야할 것!!!
1. Router의 구조
2. longest prefix matching
3. IPv4
4. IPv6
5. subnet
6. DHCP(Dynamic Host Configuration Protocol)
7. NAT(Network Address Translation)
Router의 구조
router input ports, router output ports, high-speed switching fabric, routing processor
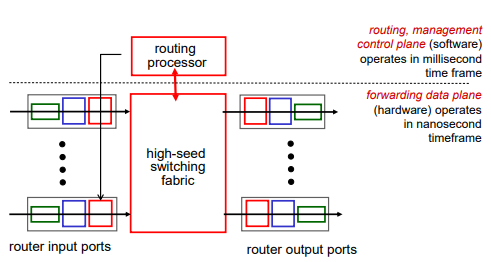
router input ports
input port memory에 forwarding table이 내장되어 있다.
이때 forwarding table은 routing algorithm으로부터 내려온다.
forwarding 시킬때, destination-based forwarding을 사용하게 되는데(전통적으로) 이때
longest prefix matching을 사용하여 앞에서부터 쭉 봐서 제일 길게 matching되는 entry를 찾아서 이 entry에 해당하는 link datagram으로 보내라고 하드웨어에 요청하게 된다.
Switching fabric
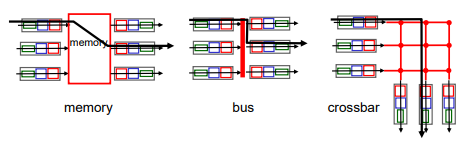
- memory : 가장 오래된 방식
- bus : line을 공유하여 한번에 하나씩 보내는 방식
- interconnection network : line을 많이 사용하여 동시에 여러 개 보낼 수 있는 방식
Input port queuing
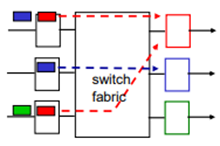
Input port에서 datagram이 들어오는 것이 fabric로 보내는 것보다 빠르다면 input port에서 queueing이 생기게 된다. 심지어 input buffer가 overflow날 경우 드랍해버린다.
output port contention : 만약에 다른 input port에서 같은 output port를 통해서 동시에 나가겠다고 요청이 들어오면, 먼저 하나가 나가고, 기다리다가 나갈 수 있다. 이로 인해 HOL Blocking이 발생할 수 있다.
Head-of-the-Line(HOL) blocking이란 queue 맨 앞에 있는 것이 line의 head부분인데, 이 head가 나가지 못하면 뒤에거까지 못 나감을 말한다.
Output port queuing
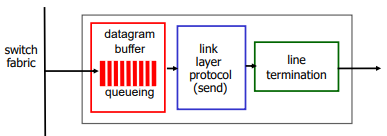
Output port에서도 Input과 마찬가지로 buffering이 된다. transmission하는 속도보다 들어오는 속도가 빠르면 buffering이 된다. 마찬가지로 손실도 날 수 있다.
그렇다면 buffer를 얼마나 주어야 할까? buffer를 많이 쓰면 delay가 엄청 늘어날 수 있다. 차라리 드랍시키는 게 낫다. 이와 같은 문제로 buffer의 크기는 중요하다.
buffer의 크기 : RTT * C / sqrt(N)
Scheduling mechanism
- FSFC(First Come, First Served) : FIFO와 같다. 선입선출(Queue)
- Priority : high priority class와 low priority class로 나누어 무조건 high priority class의 데이터를 먼저 보내고 그 다음에 low prioriy class의 데이터를 보내는 방식
- Round Robin : class를 통하여 각각의 class마다 1개의 데이터씩 순차적으로 보내는 방식
- WFQ(Weighted Fair Queuing) : RR에서 class에 가중치를 두어 높은 weight의 class를 좀더 많이 보내는 방식을 사용한다.
IPv4 Datagram format
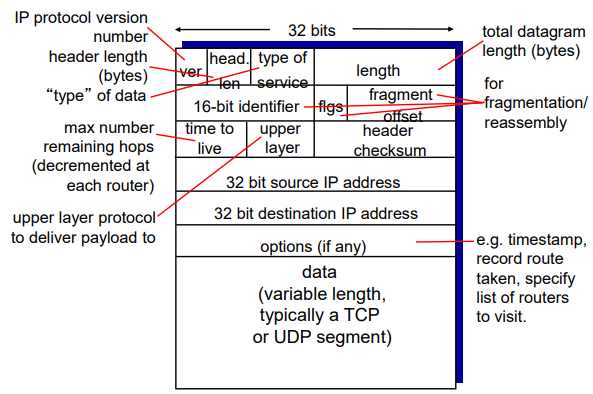
- datagram의 header는 minimum 20byte이다.
- data 부분에는 TCP나 UDP segment가 들어가게 된다.
- IP protocol version number는 IPv4인지 IPv6인지 알아야 router에서 맞게 처리하기 때문에 필요하다.
- header length : 기본 20byte이나 옵션에 의해 늘어날 수도 있음
- Type of service: priority가 높은지 낮은지와 같은 정보를 담고 있다.
- TTL: 남은 hop 개수 (라우터 하나 거칠때마다 1씩 감소)
- Upper layer protocol: 상위 헤더에 대한 hint. TCP/UDP 헤더에는 따로 자신이 어떤 프로토콜인지 알리는 값이 없기 때문에 IP에서 이를 알려주고 구분함. -> UDP에서 보냈는지 TCP에서 보냈는지 구분하는데에 쓰임
- length: 전체 datagram 길이 byte단위 -> header + body
- 16-bit identifier, flgs, fragment offset: fragmentation/reassembly를 위한 field. IPv6에선 fragmentation이 없기 때문에 해당 필드도 없음
Overhead
20 bytes of TCP(header)
20 bytes of IP(header)
= 40 bytes + app layer overhead
ip datagram의 크기는 일반적으로 1500byte를 넘지 않게 한다.
IPv6
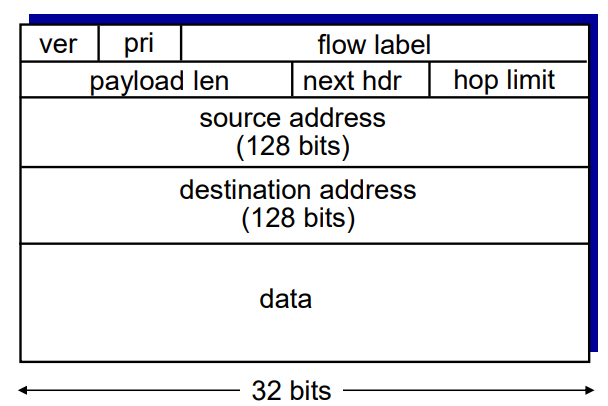
40 byte의 고정 header 크기 -> header field 사라짐
no fragmentation allowed -> 처음 보낼때부터 작은 datagram을 보낸다.
- ver : 4bit. IPv6 version에 해당하는 bit가 들어감.
- priority: flow의 datagram들 사이에서 priority를 지정
- Next hdr: 데이터에 전한달할 상위 layer 식별 + 옵션 등의 기능으로 사용함.(TCP인지 UDP인지)
- hop limit: 라우터 거칠 수 있는 횟수. 초과시 drop
- flow label: 같은 flow 안의 datagram임을 명시(아직 flow에 대한 명확한 정의는 없음)
- payload len : payload의 길이.
- 128bit의 주소들
아래는 IPv6가 단순화를 하기 위해 한 노력들..
- checksum 삭제!: checksum 계산으로 인한 overhead 감소(어차피 transport layer에도 checksum이 있음)
- fragmentation/reassembly 삭제: 긴 packet은 그냥 drop함
- option field 삭제: header 사이즈를 40byte로 고정할 수 있게 됐음.(option을 쓴다면 Next Headr 필드에 사용한다)
- ICMPv6 : 새로운 버전의 ICMP
- packet이 크면 그냥 drop 해버리기 때문에 새로운 Packet Too Big과 같은 새로운 message를 사용한다.
IPv6 -> IPv4 Tunneling
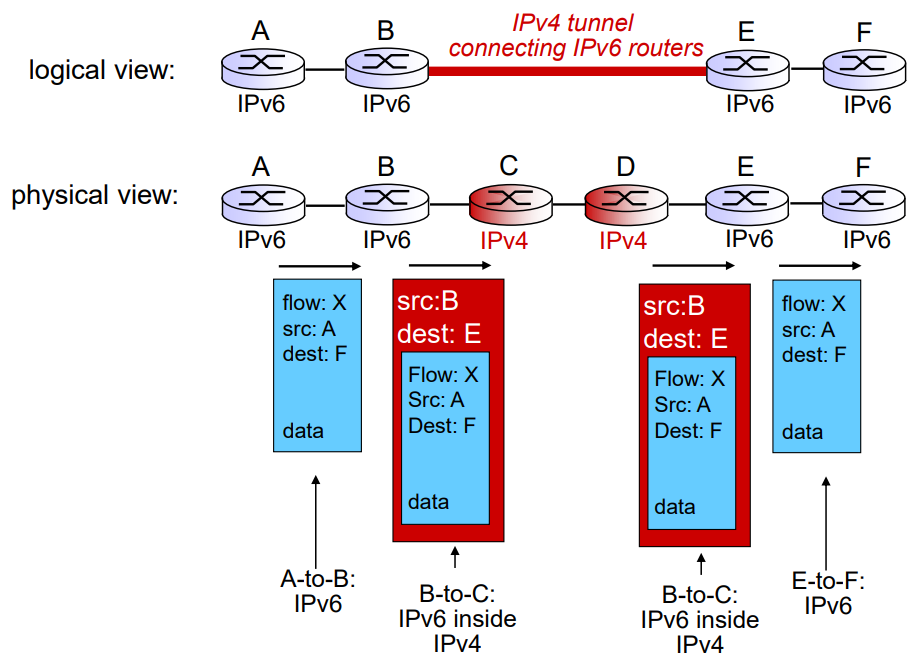
IPv4와 IPv6가 공존하는 상황이라 함은, IPv6를 인식하는 라우터와 인식하지 못하는 라우터가 있을 것이다. IPv6를 인식하지 못하는 라우터가 IPv6 datagram을 받을 때 처리하는 방법이 필요하다. 그래서 IPv4 datagram 내에다가 IPv6 datagram을 집어넣어서 IPv4 형식으로 처리할 수 있게 하는 방법인 tunneling을 고안했다.
Subnet
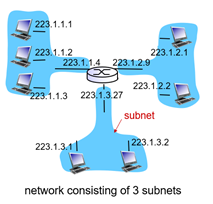
Subnet은 router를 통과하지 않고 내부에서 물리적으로 연결된 device interface들을 의미한다.
IP address는 subnet part와 host part로 구성된다.
subnet part: 같은 subnet에 있는 device들은 공통된 상위 bit를 갖는다. (115.145.~)
host part: 남은 bits는 host를 구분하기 위해서 사용된다.
Subnet을 결정하기 위해서 router로부터 각각의 interface를 분리한다. (위 그림에서 분리된 각각의 섬모양 네트워크들이 바로 subnet!
만약 subnet의 ip가 223.1.3.0/24라면 상위 24비트 까지가 subnet part임 (이때 /24를 subnet mask라고 부름)
subnet과 host 구분
위쪽 그림에서 왼쪽 subnet은 223.1.1까지 같다. 32bit중 24bit가 같고, 8bit가 다르다. 이 24bit는 subnet part로 subnet을 구별하고 나머지 8bit는 host part로 이것으로 host를 구별한다. 총 2^8(256)개의 host를 구분할 수 있는 것이다.
Subnet을 알려주기 위해 IP주소는 233.1.1.0/24 이렇게 표시한다. 즉 앞에서부터 24bit가 subnet을 의미한다는 것을 말해주는 것이다. 그리고 나머지 8bit가 host라는 것을 말해준다.
DHCP(Dynamic Host Configuration Protocol)
IP주소를 부여받는 방식
IP주소는 제한적이여서 보통 집에서 사용하는 IP는 유동적으로 받게 된다. 이 유동주소를 할당하는 방법이 DHCP이다. plug-and-play 라고 말하는데, 컴퓨터를 꽂으면 주소를 가져온다는 뜻이다.
IP주소 부족하니까 network에 접속할 때 IP주소를 한 개 주는 방식이다. network의 모든 client는 항상 IP주소가 필요하지 않다. 이 때는 회수하고 다른 사용자에게 부여한다.
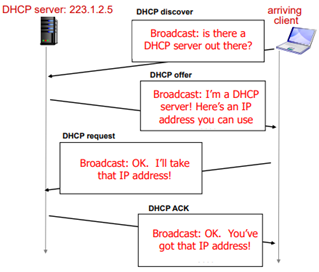
- DHCP discover
- DHCP offer
- DHCP request
- DHCP ACK
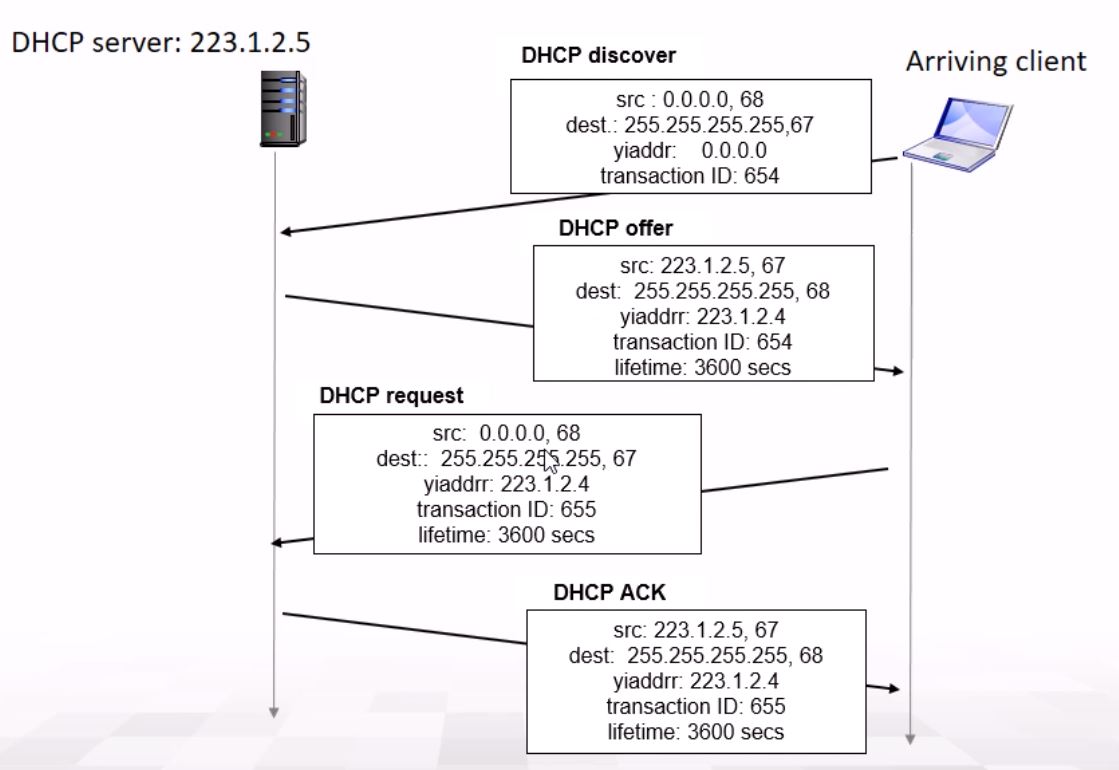
이 과정에서 client와 DHCP서버는 계속 dest에 255.255.255.255로 보내게 되는데 이는 broadcast로 message를 보낸다는 것을 의미한다!
DHCP가 알려주는 것!
- first-hop router(default gateway)의 address.
subnet 외부와 통신하기 위해서 거쳐야하는 router, 무조건 알아야된다는 뜻. - DNS server의 이름과 IP address
- network mask (host portion과 subnet portion을 구분하기 위해서)
또한 이 모든 과정은 UDP로 이루어지는데, Client에는 아직 IP address가 없기 때문에 TCP connection을 만들 수 없어서 UDP를 사용한다.
NAT(Network Address Translation)
NAT는 "Network Address Translation"의 약자로, 네트워크 통신에서 사설 IP 주소와 공인 IP 주소 간의 변환을 담당하는 기술이다. NAT는 주로 프라이빗 네트워크에서 인터넷에 접속하기 위해 사용되며, IP 주소 부족 문제를 해결하고 네트워크 보안을 강화하는 데에도 기여한다.
NAT Router가 하는 일
- replace(outgoing)
내부망에서 나가는 datagram의 src IP를 NAT Router의 IP 주소와 임의의 portnumber로 변환해주어 내보낸다. - remember
내부망에서 나갈때 replace해준 정보에 대해 변환한 정보에 대해 table로 갖고 있어서 이를 보고 데이터를 다시 원래대로 돌려놓는다. - replace(incoming)
바깥 네트워크에서 datagram이 왔다면 다시 replace하여 원래의 IP주소와 port number하여 어떤 host가 받아야하는지 알아내서 보내게 된다.
NAT의 장점
- Subnet 내부의 모든 device를 위해서 provide ISP에게 단 하나의 IP address만 받으면 됨
- Outside world에 알리지 않고도 local network내부의 host address를 변경할 수 있음
- Local network 내부의 device의 주소 변경 없이 ISP 바꾸는 것도 가능
- 외부에서 볼때는 local address가 어떤 주소를 쓰는지 모르기 때문에 외부의 공격자로부터 더 안전하다. (Security)
NAT에 대한 논쟁
- 라우터에서 Layer 3 processing을 해야하니 오버헤드가 생길 수 있다.(TCP 헤더의 포트 넘버를 바꾼 것 -> Transport layer의 정보까지 살펴봄 -> layer를 파괴)
- IPv6를 사용하면 완전히 해결 되는데, NAT은 어찌보면 꼼수를 사용한 것이다.
- IP주소가 중간에 바꿔치기 되었기 때문에 인터넷의 철학 중 end-to-end argument를 어긴 것이다.
Network Layer: The Control Plane
여기서 알아야할거!
1. Link State(Dijkstra) vs Distance Vector(Bellman-Ford equation)
2. OSPF(Open Shortest Path First)
3. AS(Autonomous System)
4. BGP(Border Gateway Protocol)
Link State(Dijkstra) vs Distance Vector(Bellman-Ford equation)
Message Complexity
LS: N개의 노드일 때 O(n^2)만에 메시지 전달
DV: 이웃들 하고만 교환, 각 노드가 최소 cost로 수렴하기까지의 시간은 다양함.
Speed of convergence
LS: O(n^2) 알고리즘 O(n^2)메시지 요구 사용
- Oscillation 문제 발생 가능
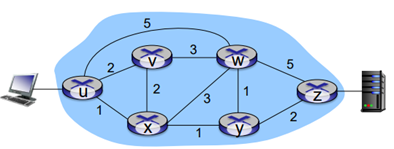
또한, link cost를 traffic volume에만 의존하도록 설계하면 route oscilation이 발생할 수 있다.. --> 따라서 link cost를 traffic의 정도로만 설정하면 안된다!!!!
아래 그림을 보자. 이렇게 불필요한 반복을 통해 route가 계속 변동할 수 있다.
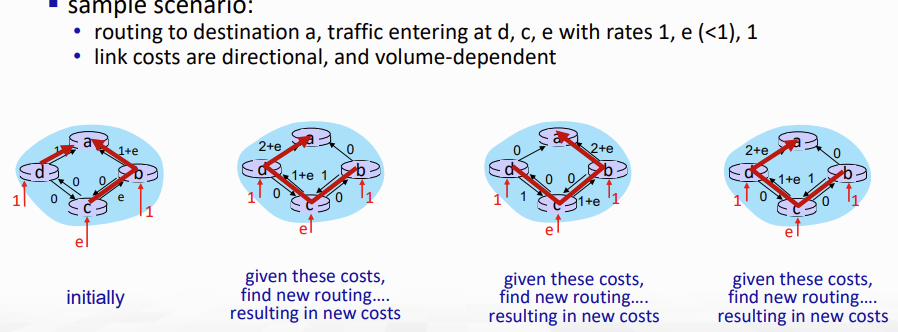
DV: 다양한 시간이 걸림.
라우팅 루프 문제 가질 수 있음
- Count infinity 문제도..!
이렇게 있을 때, 4가 60으로 바꼈다면 y는 x로 가는 최단 루트를 업데이트 해야됨.
주변을 보니, z를 통해서 x로 가는 루트 (z->y->x)가 5니까, 5+1을 해서 6으로 업데이트하고, 그럼 z는 또 업데이트하고...
z->x로 가는 길이 51이 될 때까지 1씩 반복하면서 업데이트한다. (51이 되면 z->x로 직접 가는 link cost가 50이라 멈춤, 하지만 만약.. cost가 1000이라면?)
해당 문제는 z가 어떤 path를 통해서 x로 가는지를 말해주지 않기 때문임.
나쁜 소식은 느리게 간다!!!!
{kind=link}
Robustness(라우터가 이상동작할 때 어떤일 이 일어나는지)
LS: 노드가 잘못된 링크 cost 브로드 캐스트 가능
- 그걸 기반해서 자기 자신의 테이블 계산
- 제한적으로 잘못된 결과
DV: 잘못된 링크가 아니라 잘못된 PATH를 전파
- black-holing
- 각 라우터의 테이블은 다른 것에 사용됨.. 오류가 네트워크를 통해 급격하게 전파
속도
LS: 브로드 캐스트로 모든 노드에게 일시에 교환, 전체 네트워크 상황을 아는 상황에서 작동
DV: 이웃하고만 정보 교환해서 시간 오래걸림
AS(Autonomous System)
- Scale
- routing table에 모든 destination의 정보를 저장할 수 없다.
- routing table 교환은 link를 마비시킬 수 있음
- Administrative Autonomy
- 각 network admin은 자신의 network 내부의 routing을 control 하기를 원한다.
이에 의해 만들어진 것이 한 지역에 있는 router들의 집합체 AS(Autonomous System)이다!
이렇게 만들어진 AS 내부끼리의 통신을 Intra AS Routing이라고 하며 AS 외부와의 통신을 Inter AS Routing이라고 한다.
- Intra AS Routing
- 같은 AS에 속한 라우터들끼리의 라우팅 알고리즘으로 DV나 LS를 사용한다.
- 한 AS 내에서 모든 라우터들은 동일한 인트라 도메인 프로토콜(OSPF, RIP(Routing Information Protocol) 등)을 사용
- Inter AS Routing
- 내부의 AS가 외부의 AS와 소통하기 위해 필요한 라우팅 알고리즘
- BGP가 거의 표준
border router(gateway router, 경계 라우터): AS와 AS를 연결해주는 라우터
AS 간의 라우팅을 할 때는 gateway router가 inter-domain routing을 동작
하나의 라우터는 intra-AS 라우팅 + inter-AS 라우팅으로 포워딩 테이블 구성: Intra-AS 라우팅 알고리즘만으로는 외부로 가는 경로를 알 수 없기 때문에, Inter-AS 라우팅 알고리즘의 도움이 필요
OSPF(Open Shortest Path First, IS-IS protocol과 동일(ISO Standard))
단거리를 우선시하는 프로토콜, 표준이 공개되어 이를 따르면 다른 라우터들과 문제없이 통신 가능
- link-state 알고리즘의 대표
- OSPF 메시지를 담은 IP 헤더가 이더넷과 같은 링크 앞에 붙음. IP 레이어 바로 위에 OSPF 메시지가 올라가서 전달됨, 그 자리에 TCP나 UDP가 대신 들어갈 수 있음
- multiple link costs metrics possible : 하나의 link에 대해서 여러 cost를 넣어줄 수 있다.(조건을 걸든 어떤 방식을 통해서라도)
- Link-state advertisement massage를 broadcast 방식으로 서로 주고받아 현재 AS의 topology map을 알게 되고, 다익스트라 수행
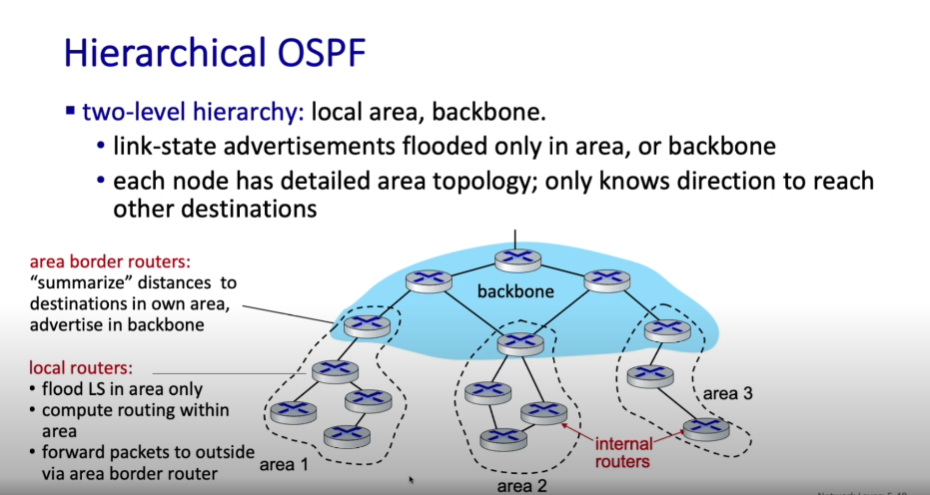
- hierarchical OSPF: 만약 AS가 너무 클 경우, broadcast 메시지가 부담이 되므로 하나의 AS를 여러 area로 나누어 각각 area에 OSPF가 동작하게 함
- 라우팅 테이블을 업데이트 하기 위한 트래픽을 최소화
- area 간을 이어주는 border gateway router들이 존재
- area border router: 하나의 area를 summarize해 정보를 전달
- backbone router: area들을 연결시켜주는 역할
- local router: AS 내부에 있는 router
BGP(Border Gateway Protocol)
내부 AS에서 외부 AS로 가려면 어떻게 갈지 정하는 프로토콜
- 표준은 아니지만 거의 표준처럼 동작
- 네트워크와 네트워크를 연결해 실제 인터넷이 가능하게 하는 프로토콜
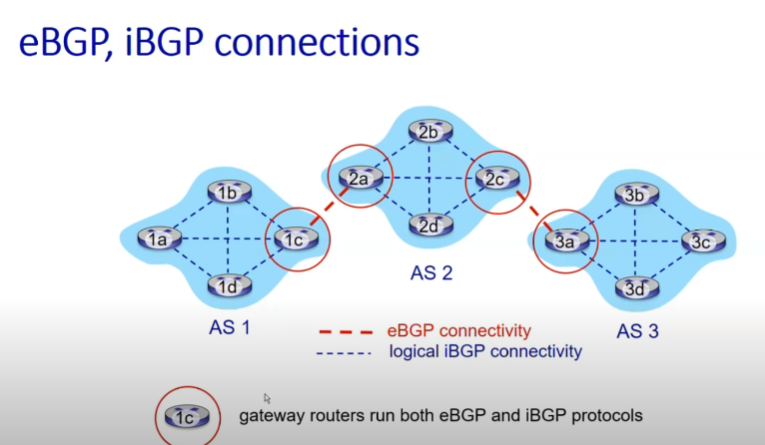
- eBGP(external BGP): 서로 다른 AS에 속하는 border router들이 주고받을 때 사용하는 프로토콜
- iBGP(internal BGP): eBGP를 통해서 얻어 온 AS 정보를 자기 AS 내부 라우터들과 공유
- reachability information와 policy를 고려하여 길 설정
- reachability information: 해당 AS를 통해 전달할 수 있는 네트워크 목적지 정보
BGP 메시지
TCP를 기반을 사용하며, BGP session은 semi-permanent TCP 연결을 사용하여 두 AS 간의 TCP 연결이 거의 항상 되어있음
메시지에 담긴 정보들
- network prefix: 보낼 수 있는 목적지 네트워크 ID
- attribute
- AS-PATH: path vector
- NEXT-HOP: 내가 그 AS로 전해주기 위해 다음으로 선택할 next hop router
BGP Message
- OPEN: TCP Connection을 만들고 authentication하는 메시지를 담아 보낸다.
- UPDATE: 만약 새로운 path가 생겼거나 너무 오래되었다면, update 메시지를 보내어 update 시켜준다.
- KEEPALIVE: TCP Connection이 연결되고, ACK 대신해서 보내는 메시지로 종종 보낸다
- NOTIFICATION: 에러 발생하면 알려주는 메시지, Connection 닫을 때도 사용
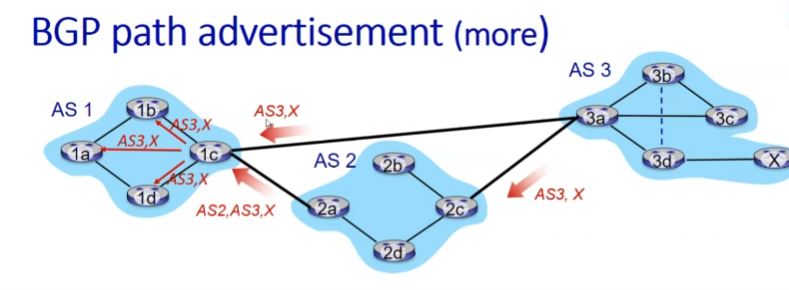
policy-based routing
intra와 달리 inter는 어떠한 path는 accept하고, 어떤 path는 decline하는 등 policy가 중요함
위의 상황에서 AS3, X와 AS2, AS3, x 중에서 어떤 것을 택할지 선택하는 것은 policy에 기반한다.
Intra vs Inter AS Routing
-
둘이 서로 달라야 하는 이유: scalability
- 모든 라우터가 한 레벨에 놓여 있다면 라우팅 테이블 업데이트 트래픽 때문에 전체 네트워크가 마비될 수 있어 AS로 구분
- AS 내에서 intra, AS끼리는 inter로 연결 -
intra는 policy 반영 X, inter는 policy 반영 O
- Inter-AS는 이익관계에 따라서 관리자가 어떻게 트래픽을 어디로 나를지 결정할 수 있다
- Intra-AS는 관리자가 하나이므로, 정책적인 결정이 딱히 필요하지 않다. -
intra는 빠르게 전달하는 것이 중요, inter는 policy가 중요
Hot Potato Routing (policy의 일종)
AS 내부에서 다른 AS로 보낼때, 목적지로 보낼 수 있는 gateway router가 여러 개 있다면 source를 기준으로 가장 cost가 작은 곳으로 보낸다. -> 그것이 실제 path의 길이가 멀든 말든
least inter-domain cost!
BGP Route Selection
- local preference value attribute를 비교
- 짧은 AS-Path
- closest Next-hop router : hot potato routing
- additional criteria
모두 같으면 IP 주소를 4byte의 integer라고 생각했을때 가장 작은 값으로 보내게 된다.
SDN(Software Defined Network)
Traffic Engineering
traffic이 한번에 많이 들어 왔을 때 잘 관리해주기 위한 기술이다.
ICMP(Internet Control Message Protocol)
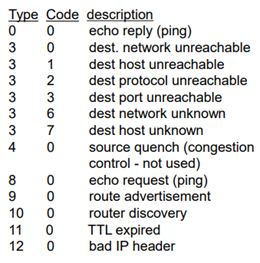
인터넷 상에서 보내고 받고 하는 수많은 control에 대한 부분을 해결해주는 protocol이다. 그래서 host나 router에서 사용된다. 주로 error reporting에 많이 사용된다. ping을 사용하여 echo (한 번 보내면 다시 오는)를 잘 갖고 오는지 확인한다.
그래서 destination network가 unreachable하거나 destination host가 unreachable하다… 등등 이런 여러 에러 메시지들 또는 ping같은 것에 의해서 사용되는 것이 ICMP이다.
ICMP 자체는 네트워크 계층의 프로토콜인데, IP 위에 올라간다. ICMP message는 type, code를 정의해놓고 8byte 정도의 message로 IP datagram에 넣는다.
Traceroute

출발지에서 도착지까지의 경로의 상태를 살펴보는 traceroute가 ICMP 이다. traceroute하는 과정을 살펴보자.
UDP로 보내는데, 일단 맨 처음 TTL=1로 찍어서 보낸다. TTL은 라우터 한번만 건너겠다는 뜻이다. 그러면 그 한 번에 담긴 시간과 정보들이 있다. 그리고 TTL=2로 찍어서 보낸다. 라우터를 두번 건너띄게 되고, 건너갈 때마다 각각에 대한 측정된 delay, 시간을 종합하면 전체 경로, node에 대한 정보를 수집할 수 있다. 그 때 사용하는 것이 ICMP로 하는 것이다.
그래서 ICMP message 내에 라우터의 이름이나 주소가 들어가 있다. delay도 계산 가능하다. 결국 destination host에 도착하게 되면, port unreachable message를 type3, code3으로 바꿔서 주면 source는 멈추게 된다.
SNMP (Simple Network Management Protocol):
SNMP는 네트워크 장비 및 시스템의 관리와 모니터링을 위한 프로토콜입니다. SNMP는 에이전트와 매니저 간의 통신을 통해 장비의 상태, 성능, 이벤트 등 다양한 정보를 수집하고 설정할 수 있습니다. SNMP는 주로 네트워크 관리 시스템에서 사용되며, 간단하고 효율적인 방법으로 네트워크의 상태를 모니터링하고 관리하는 데에 활용됩니다.
NETCONF:
NETCONF는 네트워크 장비의 구성 및 설정을 관리하기 위한 프로토콜입니다. NETCONF는 XML 기반의 프로토콜로, 네트워크 장비의 구성 변경 및 관리 작업을 원격으로 수행할 수 있도록 지원합니다. NETCONF는 에이전트와 클라이언트 간의 통신을 통해 네트워크 장비의 설정 정보를 읽고 수정할 수 있는 표준화된 방법을 제공합니다.
YANG (Yet Another Next Generation):
YANG은 네트워크 장비의 데이터 모델링 언어로, NETCONF와 함께 사용되는 XML 기반의 언어입니다. YANG은 네트워크 장비의 구성 및 상태 데이터를 기술하는 데에 사용되며, 표준화된 데이터 모델을 제공하여 네트워크 장비의 구성 및 상태 정보를 효율적으로 관리할 수 있도록 도와줍니다. YANG은 네트워크 장비의 기능 및 특성에 대한 명세를 작성하고, 이를 기반으로 NETCONF 프로토콜을 통해 네트워크 장비를 관리할 수 있습니다.
Link Layer
여기서 알아야 할 것!
1. Error detection
2. MAC(Multiple Access Control) protocol: Channel patitioning & Random access & taking turns
3. ARP(Address Resolution Protocol)
4. Ethernet
5. VLAN 요약
6. MPLS(Multiprotocol label switching)
Error Detection
parity checking

CRC(Cyclic Redundancy Check)

MAC(Multiple Access Control) Protocol
Channel Partitioning
채널을 잘게잘게 쪼개서 channel을 여러 개의 sub channel로 만든다. channel을 잘게 나눠서 하는 approach가 보통 무선 셀룰라 시스템에서 많이 시도해 왔다. time slot으로 쪼개는게 TDMA, frequency로 나눈게 FDMA. code로 쪼개는 게 CDMA. 3세대에서 사용된 셀룰라 시스템이 CDMA 기술을 활용했던 것이다.
잘게 채널을 나눠서 채널 한개한개를 쓰고자 하는 사용자에게 할당해주면 되곘다고 한 것이다. 다만 이 channel partitioning할 때 channel을 나눠주는 역할을 하는 장치가 필요하다. centralized된 누군가가 해주어야 한다.
- TDMA(Time Division Multiple Access)
- FDMA(Frequency Division Multiple Access)
FDMA는 지속적으로 한 사용자에게 bandwidth를 주는 것이기 때문에 리소스를 계속 끊임없이 사용하는 경우에 유리하다.
Random Access
MPLS(Muliprotocol Label Switching)
MPLS는 "Multi-Protocol Label Switching"의 약자로, 네트워크에서 데이터를 전송하는 데 사용되는 프로토콜입니다. MPLS는 패킷 스위칭 기술로서, 데이터를 효율적으로 라우팅하고 전송하는 데 도움을 줍니다.
MPLS는 패킷에 라벨(label)이라고 하는 헤더를 추가하여 작동합니다. 이 라벨은 출발지와 목적지 사이의 경로를 식별하는 역할을 합니다. 라벨은 패킷이 네트워크를 통과할 때마다 재배치되며, 라우터들은 라벨을 보고 패킷을 적절한 경로로 전달합니다. 이렇게 함으로써 네트워크에서 패킷의 전송 경로를 사전에 정의할 수 있으며, 라우팅 테이블을 검색하고 처리하는 데 필요한 시간과 리소스를 줄일 수 있습니다.
MPLS는 다양한 통신 프로토콜을 지원하므로 "Multi-Protocol"이라는 이름이 붙었습니다. 이는 IP(Internet Protocol), Ethernet, ATM(Asynchronous Transfer Mode) 등 다양한 프로토콜과 함께 사용할 수 있다는 것을 의미합니다. 따라서 MPLS는 다른 네트워크 기술과 통합될 수 있으며, 효율적인 데이터 전송과 품질 보장(QoS) 기능을 제공하는데 도움이 됩니다.
ARP(Address Resoulution Protocol)
MAC 주소가 어떻게 IP주소를 알까? 이것을 해결해주는 프로토콜이다. ARP table은 LAN에 연결된 각각의 node가 가지고 있다.
<IP address; MAC address; TTL>
여기서 TTL은 매핑관계가 고정되어 있다고 생각하지 않아, 20분 마다 갱신하도록 하기 위해 있다. 그래서 20분 마다 이 매핑이 유효한지 체크한다. 그래서 각각의 host는 MAC 주소와 IP주소가 부여되어 있다.
Router는 IP address를 보고, Ethernet switch는 MAC Address를 본다.
MAC Address와 같은 경우 같은 LAN을 벗어나는 경우 source가 Switch의 MAC Address로 변형되며, dest 또한 스위치의 ARP 테이블에서 알고 있는 dest MAC address로 변형하여 보내주게 된다.
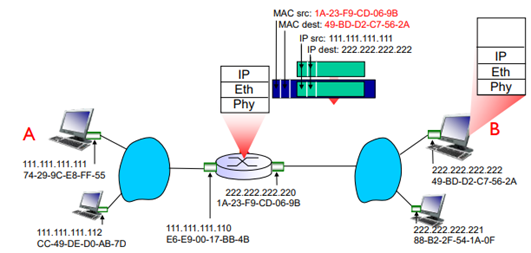
Router는 switch와 달리 flood를 하지 못하며, Routing Algorithm을 사용한다.
하지만 Router와 Ethernet switch 모두 store and forward한다는 점에서 비슷하다.
self-learning, selective send, forwarding
Switch: frame filtering/forwarding
1. 들어온 link, sending host의 MAC 주소를 기록한다.
2. MAC destination address를 가지고 스위치 테이블을 index한다.
3. 만약에 있으면 frame이 destination으로 갔는지 체크한다. 문제 있으면 드랍, 없으면 forwarding. 만약에 없으면 flood한다. (모두 뿌려본다. broadcast)

data (payload) : IP datagram이 encapsulation해서 들어간다.
preamble : 어떤 이더넷 상에서 데이터를 전송하는데 데이터의 시작부분을 detection하는 것이 preamble이다. 항상 7byte의 일정한 패턴을 집어 넣는데, 이 패턴 bit를 읽어서 이게 preamble이라고 판단되면 정보를 읽기 시작한다. synchronize 목적으로 사용하는 것이다.
addresses : 6byte. MAC address를 넣는다. destination, src를 각각 6byte로 집어넣는다.
type : higher layer protocol에 대한 indicate를 집어넣는다. 지금은 뒤에 붙는게 전부 IP지만 초창기에는 IP가 아니고 여러 protocol이었다. 그래서 network 계층의 여러 protocol에 대비하기 위해 type이 있었다.
CRC : error recovery하는 목적으로 붙이는 것이다.
Ethernet은 unrelable, connectionless 하다.
connectionless : handshaking이 없다.
unreliable : ACK나 NAK를 보내지 않는다. 다른 계층에서 하는 것이다. (TCP 등에서 한다)