principles of network appliations
application layer: 레이어 중 가장 위의 레이어
-> network application : 네트워크를 이용한 프로그램들
-> 이메일, 웹, 메세지 등
-> 두 가지의 application architecture가 있다. -> client-server, peer-to-peer
client-server architecture
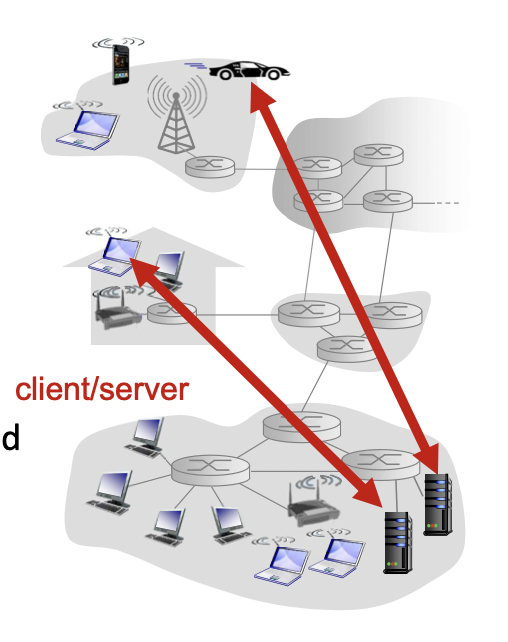
대부분의 앱들이 이 구조를 따른다.
client와 server가 존재하여 둘 사이에 데이터가 이동한다.
보통 client가 데이터를 요청하고 받고, server가 데이터 요청을 받아서 보내준다.
-
server
-> 항상 켜져있는 호스트
-> 영구적인 ip 주소(고정적 ip주소) -> 클라이언트가 접속하기 위해
-> 데이터 센터를 통해 운용되는 경우도 있음(크기가 크면 컴퓨터 여러대로 연결해가며 확장) -
client
-> 서버와 커뮤니케이션 한다.
-> 껐다 켰다 할 수 있다. (간헐적 연결)
-> ip 주소가 달라진다.(동적 ip 주소)
-> 클라이언트끼리 직접 통신하지 않는다.(통신하는 것은 p2p) -> 서버를 통해서 통신한다.
P2P architecture
동등한 peer(end system) 끼리 직접 통신한다. 새로운 peer가 나타나면 규모가 늘어난다.
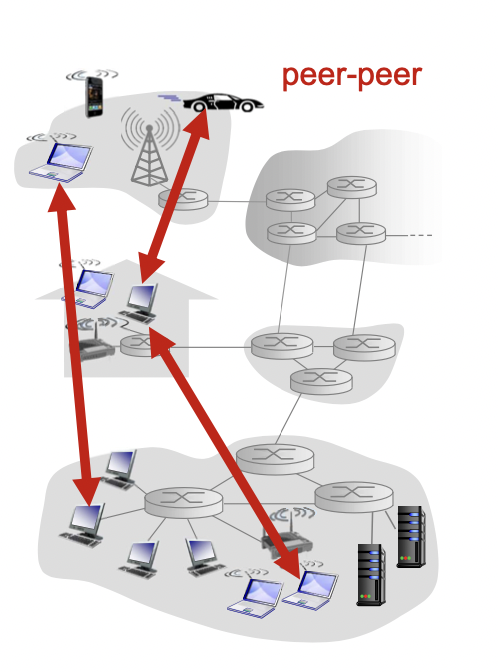
-> 항상 켜져있는 서버가 없다.(보통 작은 서버가 있긴 한데, 이 서버는 데이터 통신을 위한 서버가 아니라 peer에 대한 정보를 저장하는 서버이다. 데이터 통신은 peer끼리 한다.)
-> end system 끼리 직접 통신한다.(서로 간 서버 클라이언트 관계가 달라진다. 예를들어 내가 상대 컴퓨터에서 정보를 받아올 때 내가 클라이언트, 상대가 서버의 역할을 한다.)
-> peer 끼리 서비스를 요구, 제공한다.(self-scalability : peer가 서버 역할과 클라이언트 역할 모두 수행하기 때문에 service demands 뿐만 아니라 service capacity 까지 가져오게 된다.-> peer가 늘어나면 서버 용량이(원래 있던 peer들 + 추가된 peer들)로 자동(스스로) 확장 된다.)
-> peer들이 있었다 없어졌다 하니까 ip주소가 바뀌는 것을 고려하여 프로그램을 구성해야 한다.(관리가 복잡)
processes communicating
메세지를 주고받는 것은 호스트라기 보단 프로세스라고 보면 된다.
프로세스 : 호스트 내부에서 동작하는 프로그램 / 실행이 되는 프로그램
-> inter process communication : 같은 호스트 내부에서 다른 프로세스 끼리 소통(OS에 의해 정의됨)
-> 서로 다른 호스트의 프로세스들은 메세지를 통해 소통한다.
client-server architecture
-> 클라이언트 프로세스 : 소통 시작(서버 쪽으로 메세지 보냄) / 웹 브라우저를 실행시키면 클라이언트 프로세스가 된다.
-> 서버 프로세스 : 연결되기를 기다림 / 웹 서버를 실행시키면 서버 프로세스가 된다.
p2p architecture
-> 프로세스가 클라이언트가 될수도 있고 서버가 될수도 있다.
-> peer A가 peer B로부터 파일을 다운로드 하면 A는 클라이언트, B는 서버 역할을 한다.
Sockets
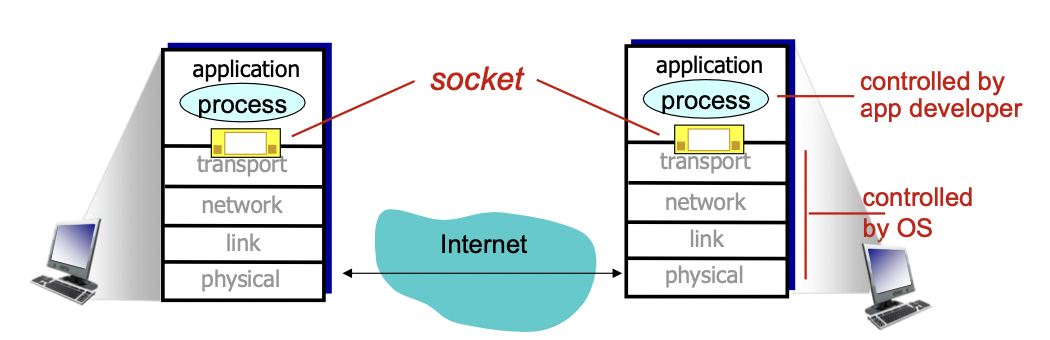
소캣: 프로세스 간 메세지를 주고 받는 인터페이스
-> 프로세스들은 소켓을 통해 메세지를 주고 받는다.
-> 어플리케이션 레이어와 트랜스포트 레이어 사이의 인터페이스라고 볼 수 있다.
-> 전체적으로 봤을 때 어플리케이션 사이의 메세지를 보내는 인터페이스 라고 볼 수도 있다.
프로세스는 어플리케이션 개발자가 관리하고, transport와 network, link, physical 레이어들은 OS가 관리한다.
Addressing process
- 메세지를 받기 위해서는 프로세스들은 identifier를 가지고 있어야 한다.
- 서버의 호스트 디바이스는 32비트 짜리 ip주소(000.000.000.000 ~ 255.255.255.255)를 가지고 있다.
- 포트넘버(16비트)를 통해 같은 호스트에서 돌아가는 많은 프로세스들을 구별할 수 있다.
포트넘버는 주로 well known port number이다.
-> 이런 서비스는 항상 이런 포트넘버를 갖는다(디폴트 값으로 보는거) : http server 80, mail server 25 등 - ip주소와 포트넘버를 알아야 웹서비스로 접근이 가능하다.
ex) 23.25.31.34:80 -> 웹서버
App-layer protocol define
메세지를 주고 받기 위해서는 프로토콜이 필요하다.
1. 메세지의 type -> 예시) HTTP 통신에는 HTTP request와 HTTP response라는 메세지 타입이 존재한다.
2. 메세지의 syntax - 전송하고자 하는 데이터의 형식, 부조화, 신호 레벨 등을 규정 -> 필드에 대한 내용
3. 메세지의 semantics - 메시지에 담겨져 있는 데이터가 실제로 무엇을 의미하는가, 메시지에 담겨져 있는 데이터를 어떻게 해석할 것인가
4. 메세지의 rules(pragmatics) - 프로세스들이 언제 메세지를 보내고 받으면 어떻게 처리할지 등
-
open protocols:
RFC에 정의되고, 해당 프로토콜 정의에 모두가 접근할 수 있다.-> interoperablity(상호운용성)
HTTP, SMTP 등등 -
proprietary protocols:
사설 프로토콜로 Skype, Zoom과 같이 해당 회사들을 통해서만 사용할 수 있는 프로토콜을 이야기한다.
what transport service does an app need?
Transport service로 뭘 사용하 것인가?
Application은 Transport Layer에 service를 제공받는데, 일반적으로 TCP(Transmission Control Protocol)와 UDP(User Datagram Protocol)가 있다.
-
Data integrity(데이터 무결성)
메시지를 보내면 반대쪽 Applicaiton에서 완전하게 수신이 될것을, reliable data transfer를 Transport layer가 보장해준다.
-> reliabilty와 같은 경우 TCP는 지원이 되지만, UDP는 아니하다.
-> 파일 전송의 경우에는 100%의 reliablity가 지원되어야 하지만, 오디오는 그러하지 않아도 된다. -
Timing
딜레이 보장(효율적이기 위해 낮은 딜레이가 요구되는 상황)
-> 패킷을 보내면 반대편 서버까지 몇 초 내에 반드시 도착하는 것을 보장 -> TCP, UDP 모두 보장하지 못함
-> 전화나 게임과 같은 경우에는 Timing이 보장되어야 한다. -
Throughput(처리율)
1초에 비트가 몇 비트 전송되는가(효율적이기 위해 최소한의 처리율을 요구하는 상황)
-> Throughput 보장이 필요할 수 도 있음 / elastic app 들은 보장될 필요가 없음 -> TCP, UDP 모두 보장하지 않음
-
Security
데이터를 전달하면 알아서 encryption(암호화), data integrity(데이터의 변형이 없이 잘 전달 되는가)
-> TCP, UDP 모두 지원 X
Timing vs Throughput
Timing : 데이터를 전달하면 바로 전달되는 시간(딜레이)
Throughput : 단위 시간당 얼마나 많이 전달 되는가

데이터 손실 면에서 loss-tolerant -> 어느정도 손실이 있어도 된다 / no loss -> 손실 없어야함
internet transport protocols services
실제로 Transport layer에 있는 서비스 -> TCP & UDP
TCP(Transmission Control Protocol) Service
-
sending process와 receiving process 사이의 relibale한 transport(loss X)
-
Flow Control, Congestion Control :
Flow Control : 송신측과 수신측의 데이터처리 속도의 차이를 해결하기 위한 기법
-> 다른 경우에는 문제가 되지 않지만, 송신측이 수신측보다 속도가 빠르면 문제가 생긴다. 송신측에서 보내는 데이터의 속도가 더 빠르면, 수신측에서 제한된 저장용량(Queue)를 초과하여 데이터의 Loss가 발생할 수 있다. 따라서 강제로 송신측의 데이터 전송을 줄여서 위험을 줄이는 방법을 사용한다.Congestion Control : 호스트와 네트워크 상의 데이터처리를 효율적으로 하기 위한 기법
송신측의 데이터 전달과 네트워크의 처리속도를 해결하기 위한 방법이다.
한 라우터에 데이터가 몰릴 경우, 즉 혼잡할 경우 라우터는 자신에게 온 데이터를 모두 처리할 수 없다. 그렇게 되면 호스트들은 또 다시 재전송을 하게 되고, 혼잡을 가중시켜 오버 플로우나 데이터 loss를 발생시킨다. 따라서, 이런 네트워크의 혼잡을 피하기 위해 송신측의 데이터 전송 속도를 줄이게 된다.
-
Connection-oriented : client와 server가 통신하기 전에 커넥션을 setup하는 과정이 필요
UDP(User Datagram Protocol) Service
- 프로세스간 데이터를 전송하기만 함, unreliable data transfer
- 위의 내용들 중 아무것도 제공하지 않음

Securing TCP
Timing과 Throughput은 Transport layer에서 보장해주기 어렵다.
TCP와 UDP는 encryption, 즉 암호화가 제공되지 않으며 그렇기 때문에 데이터를 보내게 되면 그 텍스트 그대로가 전송되기 때문에 Sniffing 등의 위험이 있다.
-
Transport Layer Security(TLS) or SSL(Secure Scokets Layer)
암호화된 TCP 연결을 제공
데이터 무결성 제공
end point authentication -> 상대편이 진짜인지 위조된 것인지 확인 -
TSL은 Transport layer에 있는 것이 아니라 Application Layer에 존재한다.
-
SSL Socket API를 통해서 사용한다. -> SSL은 API를 사용한다는 뜻!
Web & HTTP
web browser - client / web server - Server
Broswer와 Server 간의 통신에 사용되는 프로토콜이 HTTP(HyperText Transfer Protocol)이다.
하나의 웹 페이지는 Object(HTML, JPEG Image, Applet, Audio 등)로 구성되어 있다.
그런 Object 들은 각각 URL(Uniform Resource Locator)이라는 주소에 의해 Addressing 된다.
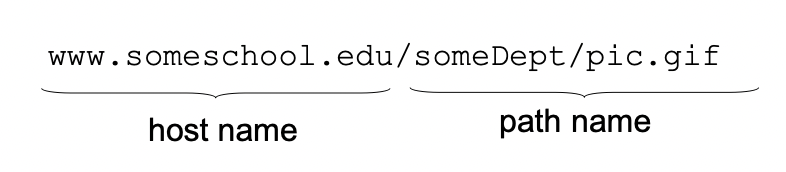
Host name / path name으로 구성되어있다.
HTTP
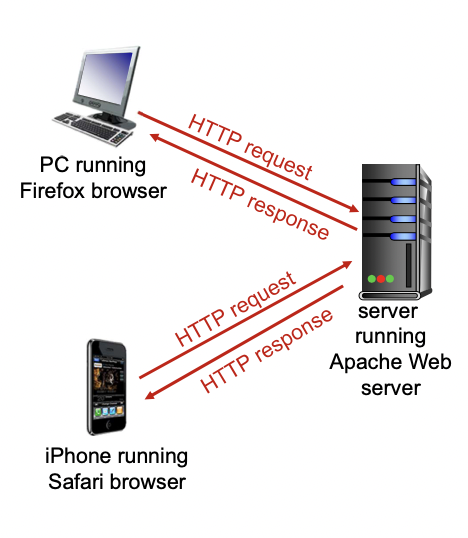
HTTP : hypertext transfer protocol
-> hypertext : 링크 달려 있어서 누르면 바로 링크로 옮겨지게 되는것.
- web에서 사용되는 Application Layer Protocol이다.
- Client / Server 모델을 따른다.
-> 클라이언트 : HTTP프로토콜을 이용하여 요청하고, 응답받고, 화면에 출력해 주는 브라우저
-> 서버 : HTTP 프로토콜을 이용하여 요청에 대한 응답으로 오브젝트를 보내주는 서버
TCP 사용 : web 페이지의 내용을 손실 없이 전달하기 위해 TCP를 사용한다.
1. Client가 Socket을 만들고 TCP Connection Request
2. Server가 client의 TCP Connection을 request를 받으면 HTTP message를 Connection으로 보낸다.
3. TCP connection을 Close한다.
Stateless
-> 서버는 클라이언트의 정보를 기록하지 않는다.(기록이 필요하면 쿠키를 사용하여 state를 관리함, http는 기본적으로 stateless)
-> 만약 state를 유지하게 되면 수많은 정보를 관리하기가 복잡하고 유지보수가 어려워진다.
stateful protocol vs stateless protocol
-> stateful protocol은 과거의 history(state)를 기록한다. (state에 따라 행동을 취해야 할 때 기억한다.)
-> 상태를 저장하기 때문에 만약 서버나 클라이언트에 문제가 생기면 state 불일치가 발생할 수 있고 조정되어야 한다. -> 관리가 복잡해진다.
HTTP Connections
- non-persistent HTTP
-> 하나의 Object가 TCP Connection을 통해 전달된 후 Connection을 close한다.
-> 여러 개의 Object가 있으면 여러 개의 Connection을 만들어야 한다.
-> 브라우저에서 병렬적으로 Connection을 생성해서 사용하게 된다.
- persistent HTTP
-> 하나의 TCP Connection을 통해 여러 개의 Object들을 전달될 수 있다.
-> 현대 대부분의 웹 브라우저들이 persistent HTTP connection을 사용한다.
Non-persistent HTTP
유저가 URL을 들어간다고 가정해 보자. (파일이 텍스트와 10개의 이미지를 참조하는 상황)


Non-persistent HTTP를 사용한다면 10개의 이미지, 즉 10개의 Object를 가져오기 위해서 10번의 TCP Conneciton을 통해서 진행해야한다.
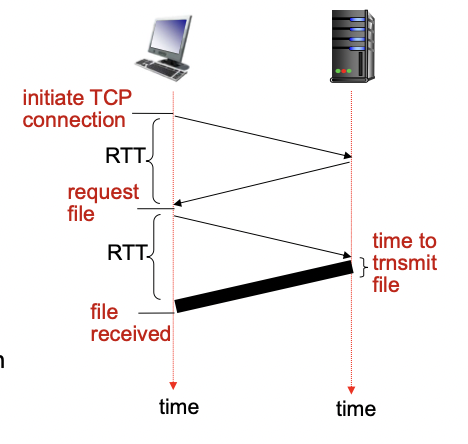
RTT(Round Trip Time) : Client에서 request를 보내고 Server에서 response를 보내주는 왕복 시간
1 RTT - 처음 TCP Connection 요청을 위해 Client - Server 요청을 주고 받는다.
1 RTT - 1 RTT를 통해서 HTTP request를 보내고 HTTP response를 통해서 file을 주고 받는다.
file transmission - 파일을 실제로 전송하는데 걸리는 시간
non-persistent HTTP response time = 2RTT + file transmission
Persistent HTTP
non-persistent HTTP의 단점:
- 한 object를 받기 위해서 2RTT의 시간이 필요하다.
- Connection을 만들 때마다 OS Overhead(메모리 확보 등등의 시간)가 소모된다.
- 브라우저들은 TCP Connection을 병렬적으로 여러개 생성해서 object를 받게 된다.
persistent HTTP:
- server가 connection을 끊지 않고 계속 유지한다.
- HTTP message를 connection이 연결된동안 계속 주고 받을 수 있다.
- 한 개의 Object를 위해서 1 RTT만을 필요로 한다.
HTTP request message
HTTP message의 type은 request와 response가 존재한다.
HTTP request message의 Syntax는 ASCII(human-readable format, 사람이 읽을 수 있는 방식)로 이루어져있다.
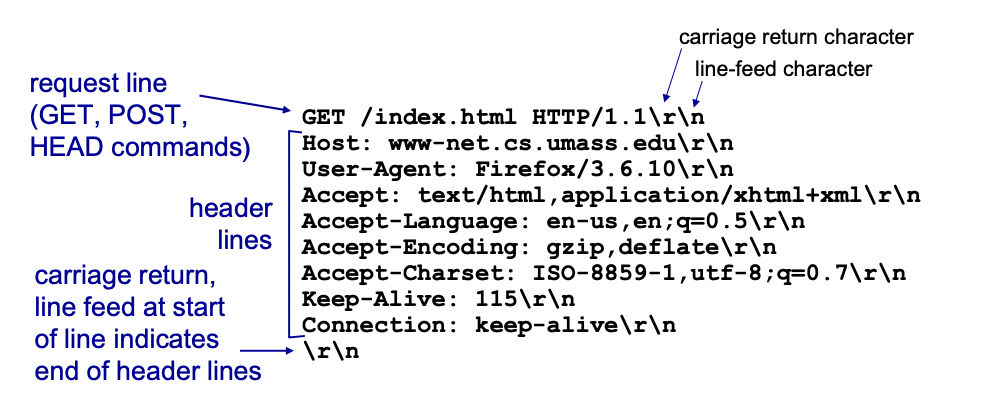
-> \r\n으로 줄바꿈
-> keep-alive : 115 -> 115초 동안 Connection을 유지해라(반응 없으면 닫아라)
-> connection : keep-alive -> connection을 유지해라(persistent)
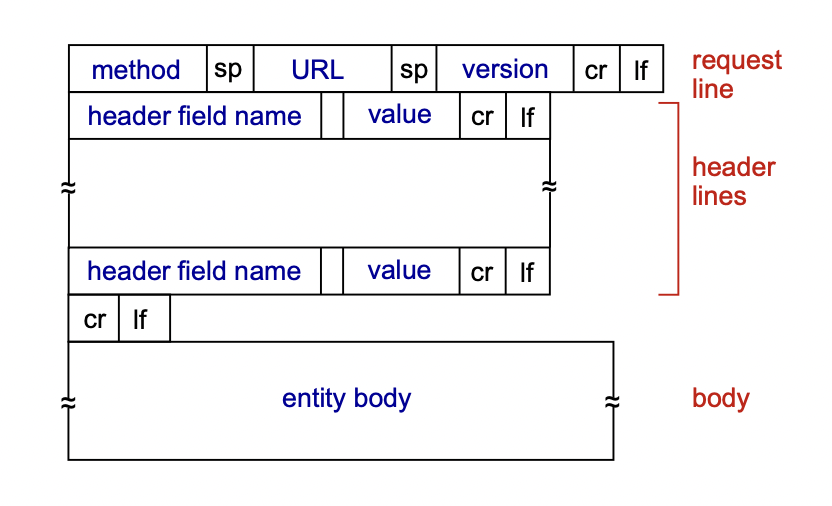
- header : body를 전달하는데 필요한 값.
- body : 진짜 전달하는 내용물
Uploading form input
POST method :
- 사용자로부터 form input, 혹은 file 등의 body로부터 데이터를 전달받아서 server에 올릴때 사용하는 메서드이다.

URL method :
- Get method를 사용한다.
- Body를 사용하지 않고 Client가 서버로 URL을 통해 전달해 준다.

Method types
HTTP/1.0:
- GET
- POST
- HEAD -> Server에 response에 object와 같은 것을 보내지 말고, header만을 요청하는 메서드
HTTP/1.1:
- GET, POST, HEAD
- PUT -> 파일을 특정한 위치, 특정한 URL field에 올려달라고 요청하는 메서드, 파일 업로드
- DELETE -> 특정 URL field에 있는 파일을 지워달라고 요청하는 메서드, 파일 삭제
HTTP response message
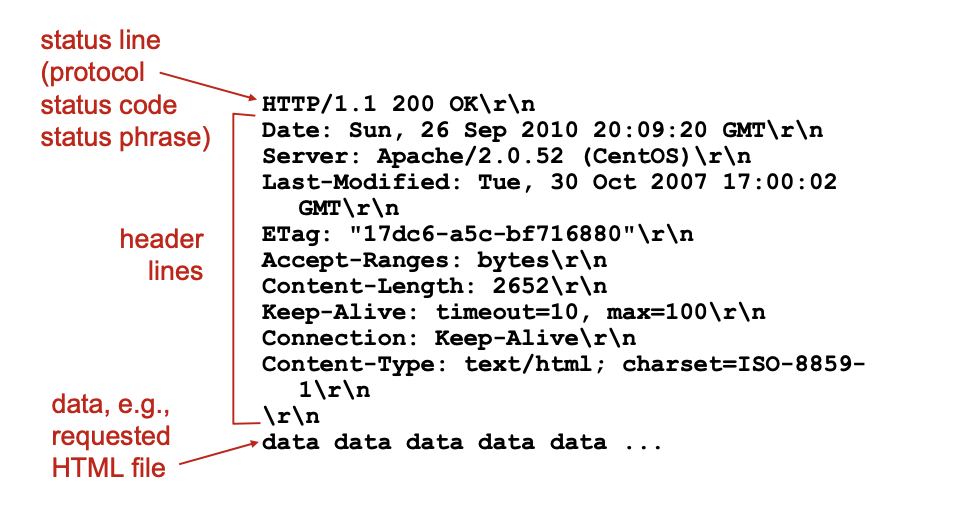
메세지 중 Last-Modified -> 마지막 바뀐 날짜 저장 -> 캐쉬 사용할 때 웹 서버에서 last modified를 보고 캐쉬에 저장된것 보다 최신인 것이 있으면 그것을 사용하고 없으면 캐쉬 그대로 사용!
200번대 성공
300번대 리다이렉션 메시지
400번대 클라이언트 에러
500번대 서버 에러
User-server state: cookies
- HTTP 서버는 stateless로 상태를 기록하지 않지만, 기록이 필요한 경우가 있다.
-> 이럴 경우 Cookie가 사용된다. - Cookie : 작은 데이터 조각으로 사용자의 컴퓨터(클라이언트)에 저장된다.
-> 서버가 클라이언트를 기록하기 위한 서비스에 사용된다.
-> 로그인, 장바구니, 게임 점수, 방문 기록 등
- HTTP response message에도 cookie header line이 있다.
- HTTP request message에도 cookie header line이 있다.
- host, 유저가 cookie file를 갖고 있게 되고, user의 browser에서 이를 관리한다.
- web site에서도 cookie를 저장하고 있는 데이터베이스가 있다.
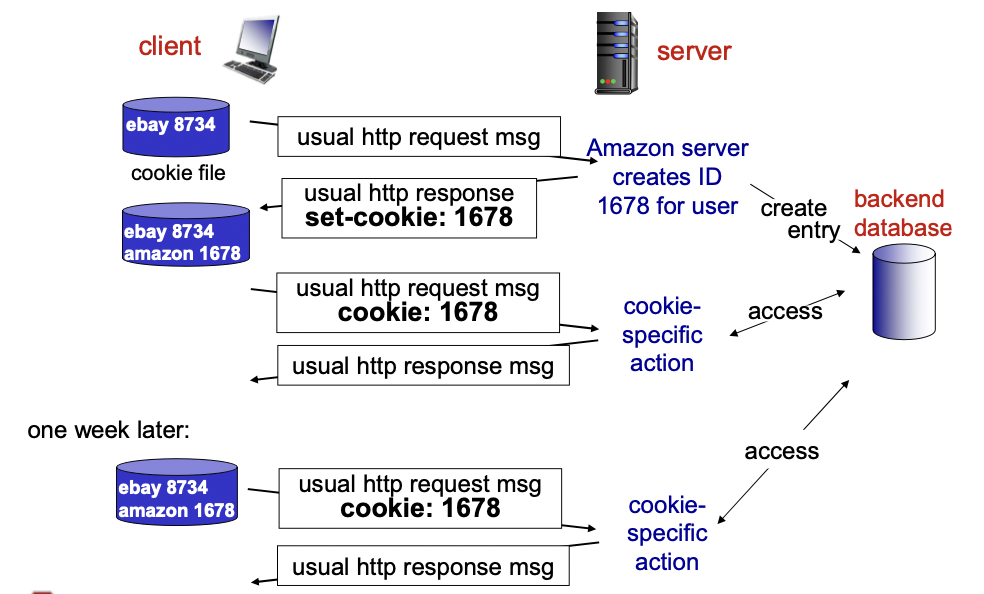
- 클라이언트가 서버로 request 메세지를 보낸다.
- 서버에서는 ID를 하나 만들어서 쿠키로 세팅하고 클라이언트로 response 해 준다. 동시에 관련 정보들을 데이터베이스에 저장한다.
- 다시 접속할 때 쿠키 번호를 request 메세지에 담아서 함께 보낸다.
- 서버에서는 해당 쿠키에 맞는 것을 데이터베이스에서 찾아서 response 해 준다.
- client에 cookie file이 없으면 서버에서 ID를 생성하고, response msg에 쿠키를 포함하여 보내준다. 그리고 cookie의 id를 데이터베이스에 저장한다.
- client에 cookie file이 있으면, request msg에 cookie file을 함께 보내고, server의 데이터베이스에서 사용자의 state에 해당하는 response msg를 보내준다.
- 이 때 HTTP가 state를 저장하는 것이 아니라 쿠키가 state를 저장하고 있는 것이고, HTTP는 쿠키를 전달만 해주는 것이다.
Web caches (proxy server)
목표 : client의 요청을 origin server의 관여가 없이 만족하는 것

데이터 제공 서버는 origin server이고, proxy server는 클라이언트와 origin 서버 사이에 있는 개체이다.
용도 : origin 서버로부터 데이터를 자주 가져오는데, 자주 가져오는 오브젝트들을 proxy에 저장하면 origin 까지 갈 필요 없이 proxy로 부터 받아오면 된다. 실제 서버에 비해 사용자에 가깝게 위치한다.
과정
- 브라우저에 setting 되어 있어야 한다.
- proxy의 cache에 오브젝트가 존재하면 오브젝트를 바로 반환받는다.
- proxy의 cache에 오브젝트가 없다면, origin 서버에 오브젝트를 request해서 reponse 받아서 클라이언트에 전달해 준다. 그리고 새 데이터를 cache에 저장한다.
More about web caching
1. 캐쉬는 클라이언트와 서버의 역할 모두 수행한다.
-> 클라이언트로 부터 오는 request에 대해서는 서버 역할
-> origin 서버에게 요청할 때는 클라이언트 역할
2. 특정 ISP에서 캐쉬를 운영한다.
-> 대학교, 회사 등
3. web caching을 사용하는 이유
-> 클라이언트 입장에서 데이터를 빠르게 가져올 수 있다.(response time을 줄일 수 있다.)
-> 트래픽을 줄일 수 있다.(캐쉬를 사용하지 않으면 클라이언트의 모든 request가 origin 서버로 가기 때문에 bottleneck이 걸릴 수 있는데, 캐쉬를 사용하면 proxy 서버로 request가 분산되기 때문에 트래픽이 줄어든다.)
-> 인터넷 상에 많이 존재한다.
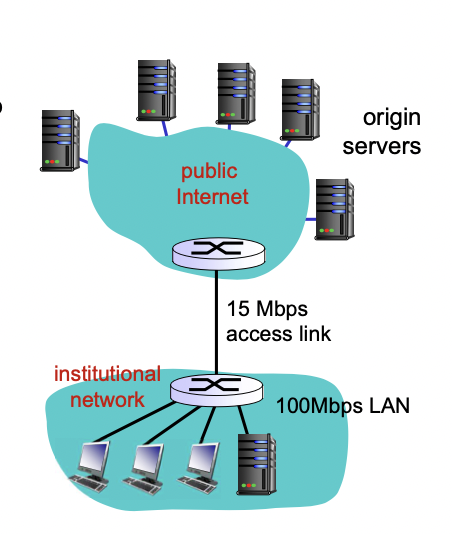
가정상황
- 오브젝트의 사이즈 : 1Mbits
- 브라우저가 origin 서버에 요청하는 평균 횟수 : 15/sec -> 초당 15번
- origin 서버로부터 라우터까지 걸리는 시간 : 2초
- access link에서의 딜레이 : 0.01초
- access link rate : 15Mbps
결과
- 초당 15번 요청하는데 오브젝트의 사이즈가 1Mbits이므로 초당 15Mbits -> 15Mbps의 요청
-> LAN 활용도 : 15Mbps/100Mbps -> 15%
-> access link 활용도 : 100%
-> access link utilization이 100%면 queueing delay가 발생한다.(congestion at access link)(La/R = 1)
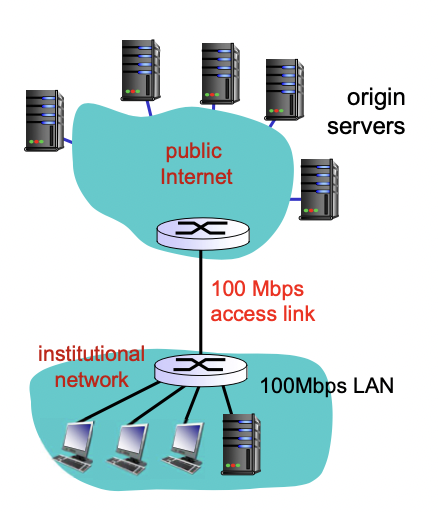
해결법 1
access link를 늘린다. -> 기존의 15Mbps를 100Mbps로 늘림
-> access link 활용도 15/100 -> 15%
-> queueing delay 해결(딜레이는 origin 서버에서 받아오는 시간 2초 + access link에서 딜레이 0.01초 = 2.01초 정도밖에 안걸림)
-> 비싸다는 단점이 있다.

해결법 2
웹 캐쉬 설치 -> 캐쉬에 있을 확률(web cache hit rate) : 0.4로 가정
-> 40%의 requeset는 캐쉬에서 가져오기 때문에 0.01초 걸림
-> 60%만 origin 서버에 요청하기 때문에 access link 활용도 0.6(엑세스링크에 걸리는 부하 줄어듬)
-> 60%의 request는 2.01초 걸림
-> 가격이 싸다.
!!!!위에 계산하는 부분들이 굉장히 중요할 것으로 보임!!!!
Conditional GET
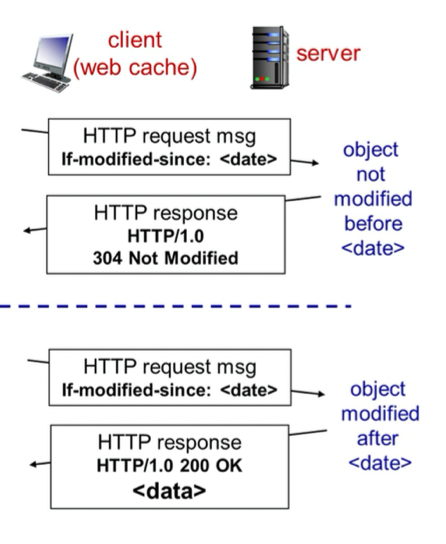
웹 캐쉬의 문제점 : origin 서버의 파일의 오브젝트가 바꼈을 수 있다.(업데이트 됐을 수 있다.), 실시간으로 보여주는 것(뉴스, 주식 등)을 캐쉬에서 가져오는 것은 의미가 없다.
-> 오브젝트가 변했는지 확인하는 방법 : conditional-get -> GET method의 옵션에 if문을 달아준다
-> If-modified-since: <날짜>
-> 만약 날짜 기준으로 안바꼈으면 웹 캐쉬 에서 받는다.
-> 만약 날짜 기준으로 바꼈으면 origin 서버에서 받는다.
동작 방식
-> 클라이언트가 웹 캐쉬에 요청
-> 웹 캐쉬가 서버에 요청
-> 데이터가 안바꼈으면 서버에서 웹 캐쉬로 304 Not Modified 메세지 response
-> 캐쉬의 데이터 클라이언트에 전송
-> 데이터바 바꼈으면 서버에서 웹 캐쉬로 200 메세지랑 데이터 reponse
-> 캐쉬 업데이트 하고 클라이언트에 데이터 전송!
출처 및 참고
https://velog.io/@kms9887/%EC%BB%B4%ED%93%A8%ED%84%B0-%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-2.-Application-Layer1
Computer Networking A Top-Down Approach 7-th Edition / Kurose, Ross / Pearson

{kind=link}