Transport Layer Services
transport services and protocols
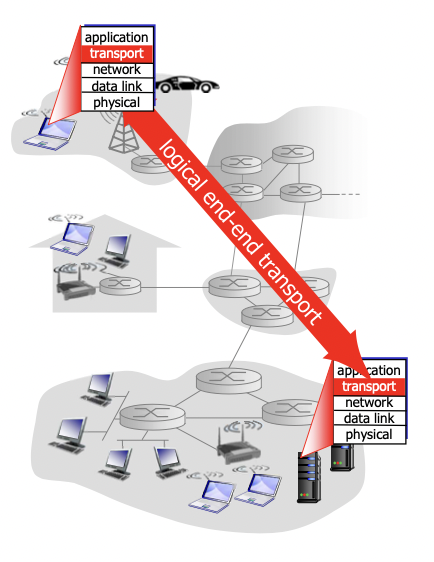
트랜스포트 레이어가 하는 일
-
서로 다른 호스트에서 돌아가는 어플리케이션 프로세스 간 logical communication을 제공한다.
-
프로토콜은 엔드 시스템에서 돌아간다
-> 코어에 있는 라우터들은 트랜스포트 레이어를 구현하고 있지 않음.(라우터들을 거쳐 데이터들이 전달되지만 트랜스포트 레이어의 입장에서는 거쳐가는 과정은 보이지 않고 두 엔드 시스템 사이의 logicla한 커뮤니케이션만 보게 됨)(라우터에서는 실제로 네트워크, 데이터 링크, 피지컬 레이어만 존재)
-> sender가 하는 일 : segment 단위로 메세지를 잘라서 트랜스포트 레이어의 헤더를 붙이고 네트워크 레이어로 보내줌
-> receiver가 하는 일 : 세그먼트들을 합쳐서 메세지를 만들고 어플리케이션 레이어로 전달 -
TCP / UDP

-
network layer : 호스트 사이의 logical communication(통신)
network layer에서 -
transport layer : 프로세스 사이의 logical communication
(참고)
호스트 -> 디바이스. ip주소를 가지고 있음
프로세스 -> 호스트 위에서 돌아가는 여러가지 프로세스들
네트워크 레이어는 데이터그램을 전송하고 라우터를 사용하여 목적지 호스트에 도달하도록합니다. 이 때, 데이터그램의 목적지 주소는 IP 주소로 지정됩니다.
호스트는 데이터그램을 보낼 때 해당 패킷을 목적지 호스트로 보내기 위해 라우팅 테이블을 사용합니다. 라우팅 테이블은 목적지 IP 주소에 따라 패킷을 어떤 인터페이스로 전달할지를 결정하는 데 사용됩니다.
데이터그램이 라우터를 거치면 라우터는 데이터그램의 목적지 주소를 검사하여 해당 호스트가 직접 연결되어 있는지 아니면 다른 라우터를 통해 전달해야 하는지를 결정합니다. 이러한 방식으로 라우팅이 이루어지며, 데이터그램은 최종적으로 목적지 호스트에 도달합니다.
따라서, 네트워크 레이어는 호스트 간의 논리적인 통신을 담당하며, 데이터그램의 라우팅 및 전송을 관리합니다.
Internet transport layer protocols
- TCP : reliable(신뢰성 있게 전달, 보낸 그대로 도착하도록), in-order delivery(보낸 순서대로 받는사람이 받음)
-> 전송 속도 조절(congestion control, flow control)
-> 커넥션을 맺어야 통신이 가능하다.(connection setup) - Udp : unreliable(신뢰성x, 중간에 날아갈 수 있음), unordered delivery(보낸 순서 상관 없이 도달)
-> 그저 전달 역할만 수행한다. - 두 서비스 모두 안해주는 것들
-> 딜레이 보장 : 언제까지 도달하도록 보장 해주는것.
-> 속도 유지 보장(bandwidth guarantee) : 예를들어 스트리밍 중에 계속 몇bps로 속도를 유지하도록 해 주는것.
—> tcp와 udp모두 둘다 보장 안해줌
multiplexing and demultiplexing
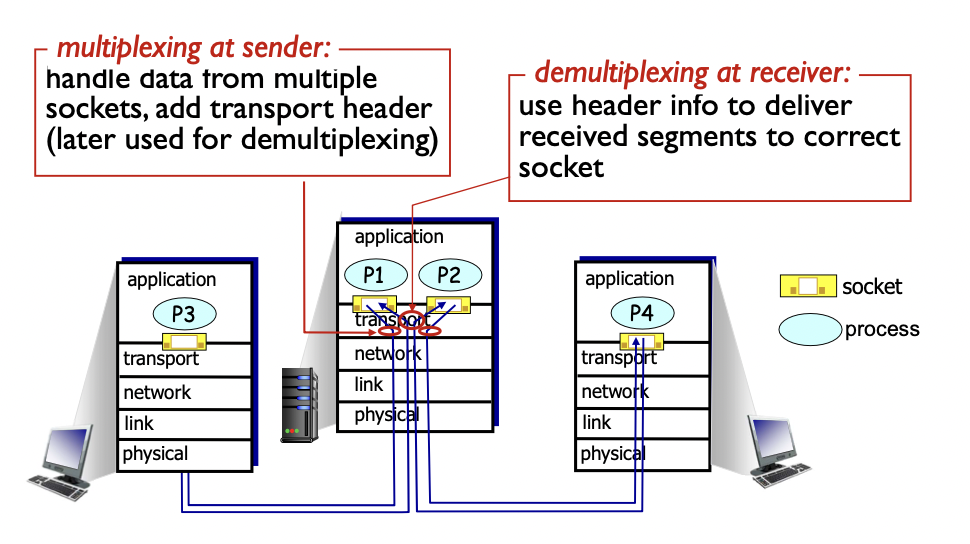
서버 컴퓨터 하나에 두개의 서버가 돌아가는 상황
-> 네트워크 레이어는 ip 주소를 보고 가기 때문에 두 클라이언트 모두 한 서버로 가고, TCP가 두 프로세스 중 어느 프로세스로 갈지 결정해 주는 역할을 한다.
-> sender에서의 multiplexing : 여러 소켓에서의 데이터를 다루기 위해 트랜스포트 헤더를 붙여서 보내준다.
-> receiver에서의 demultiplexing : 헤더를 보고 어느 소켓으로 보낼 지 결정한다.
IP주소와 같은 경우에는 네트워크 레이어에서 Segment에 추가하여, 패킷(혹은 datagram)으로 만들어서 보내게 된다.
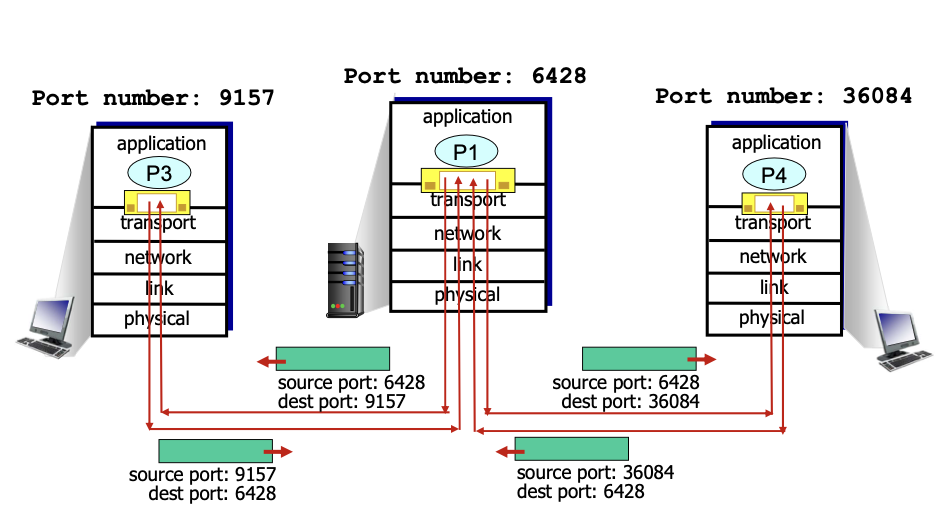
connectionless demultiplexing -> UDP
- 서버에서의 동작
- 소켓 생성
- 서버의 addr 정보를 넣어주고 바인드 해줌
- 소켓으로 부터 메세지 읽어 들임(recvfrom) -> 클라이언트의 정보를 저장
- 클라이언트쪽으로 메세지 보냄(sendto) -> 앞서 저장한 클라이언트의 정보로 보냄
- 클라이언트에서의 동작
- UDP 소켓 생성
- 서버의 정보 저장
- Sendto
- Recvfrom
-> 서버와 클라이언트 둘 다 tcp와 달리 커넥션 맺고 끊는게 없다.
- UDP 패킷을 보낼 때 목적지 주소와 포트번호를 정해줘야 한다.
-> 서버가 UDP 패킷을 받으면 헤드에 포함된 목적지의 포트 번호를 확인하고 이 포트 번호를 사용하는 소켓으로 보내줌. - 같은 목적지 주소와 같은 목적지 포트 번호를 가지고 있는 패킷은 같은 소켓으로 보내진다.
-> 보내는 쪽의 주소와 포트 넘버가 달라도 이렇게 동작함.
connection oriented demux
- TCP는 소켓을 구별하기 위해 네가지 정보를 모두 사용한다.(네 정보 모두 일치해야 같은 소켓으로 전달됨)
-> 커넥션을 맺기 때문에 가능함.(커넥션이 없으면 누가 나에게 보냈는지 모르고, 커넥션이 있으면 receiver입장에서 sender의 정보가 확실하니까 목적지가 같더라도 source가 다르면 다른 소켓으로 취급)
surce ip address / source port number / destination ip address / destination port number
- TCP 에서의 demux : receiver는 네가지 정보를 모두 활용하여 segment를 적절한 소켓으로 전달해 준다.
- 웹 서버는 TCP를 사용하는데, 클라이언트와 커넥션을 맺을 때 마다 다른 소켓을 사용한다.
-> 사용하는 포트번호와 ip 주소가 같더라도 source의 정보들이 다르기 때문
-> non-persistent HTTP는 요청마다 새 커넥션을 하기 때문에 모두 다른 소켓을 사용한다.
같은 port에 여러 소캣이 존재할 수 있는 이유는 부모 프로세스를 복사하여, 즉 fork하여 새로운 복사된 자식 프로세스를 만들어 해당 프로세스와 연결해주게 된다.
최근에는 threaded server를 통해서 하나의 프로세스 내에서 여러 개의 실행 흐름을 만들어 사용하여 프로세스를 복제하지 않고도 사용하고 있다.
connectionless transport : UDP
UDP: User Datagram Protocol
- no frills, bare bones 라고 불리는 인터넷 트랜스포트 프로토콜이다.
- best effort 서비스이다.
-> 최선을 다하긴 하는데 보장해 주지는 않는다.(최선만 다함)
-> UDP segment들은 손실될수도, 순서가 바뀔수도 있다.(out-of-order) - connectionless(커넥션이 없다)
-> UDP sender와 receiver 사이의 hanshaking이 없다.
-> 각각의 UDP segment(메세지)들이 독립적으로 처리된다. - UDP는 언제 사용하는가?
-> streaming multimedia apps : 손실이 일어나도 되고, 속도가 중요한 경우
-> DNS : 한번 사용하고 끊기 때문(+ 속도가 중요해서)
-> SNMP - reliable transfer over UDP : UDP 위로 reliable을 옮겼다(어플리케이션 레이어에서 reliaility를 만들겠다.)
-> TCP를 사용하면 reliable 기능 중복되기 때문에 UDP를 사용하고 어플리케이션 레이어에서 reliability를 구현
(참고)
http는 보통 tcp를 사용하는데(http 버전 1.0, 1.1, 2) 요즘 나오는 http/3은 QUIC를 사용한다.
-> QUIC는 트렌스포트 레이어의 새로운 서비스 인데 UDP 위에 기능들을 추가해서 만든 서비스 이다.
SNMP(Simple Network Management Protocol)는 네트워크 장비를 모니터링하고, 관리하기 위해 사용되는 프로토콜입니다. SNMP는 네트워크 장비의 상태 정보를 수집하고, 이를 관리자가 원격으로 조회하고, 분석할 수 있도록 합니다.
SNMP는 클라이언트-서버 구조로 구성되어 있으며, 관리자가 SNMP Manager 소프트웨어를 사용하여 네트워크 장비의 상태 정보를 조회하고, 수정할 수 있습니다. 이 때, 관리자는 SNMP Agent가 설치된 네트워크 장비에 요청을 보내어 정보를 조회하게 됩니다.
SNMP는 MIB (Management Information Base)를 사용하여 네트워크 장비의 상태 정보를 저장하고, 관리합니다. MIB는 각각의 네트워크 장비가 제공하는 정보들을 계층적인 구조로 표현한 것으로, SNMP Manager가 이를 조회하여 필요한 정보를 확인하고, 필요한 경우에는 수정할 수 있도록 합니다.
UDP : segment header
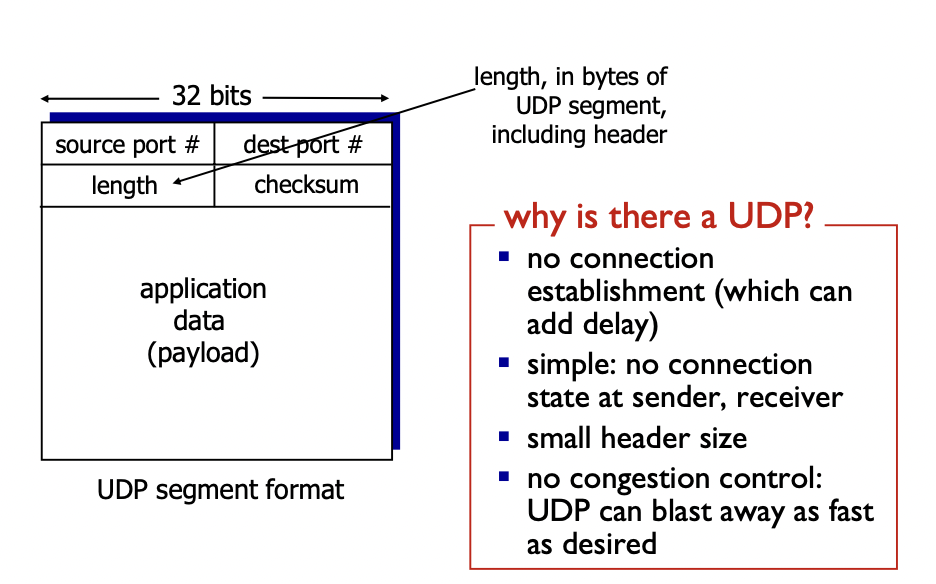
- 어플리케이션 메세지를 segment들로 나눈다.
- 헤더와 payload(데이터) 부분으로 나눈다.
- 헤더 : 8바이트(한줄에 32bit = 4byte 이므로 두줄로 구성)
-> 첫줄에 source, dest 의 포트번호(ip 주소는 네트워크 레이어의 ip헤더에 있음)
-> 둘째줄에 전체 segment의 길이(헤더 + payload)와 checksum(에러 correction을 위해 있음)
-> segment의 길이 : 16비트 -> 0 ~ 2^16-1 = 65535, 이 중 헤더의 길이가 8이므로 최대 payload의 길이는 65527
- Source Port (2바이트): UDP 패킷의 출발지 포트 번호입니다.
- Destination Port (2바이트): UDP 패킷의 목적지 포트 번호입니다.
- Length (2바이트): UDP 세그먼트 길이를 나타내며, 헤더와 페이로드(데이터)의 크기를 합한 값입니다.
- Checksum (2바이트): 오류 검출을 위한 체크섬 값입니다. 이 필드는 선택적으로 사용됩니다.
- connection일 필요없다. -> header 사이즈가 작고, delay가 보다 적고, 간단하다.
- congestion control이 없다. -> UDP는 가능한한 빠르게 보낸다.
UDP checksum
- checksum의 목적 : 전송된 segment에 대해 오류 판단
- sender
-> 세그먼트의 내용들을(헤더 + payload) 16비트로 나눠서 관리한다.
-> 16비트의 수들을 다 더해 checksum에 저장한다.(1의 보수 사용) - receiver
-> 받은 세그먼트에 대한 checksum을 계산한다.
-> 받은 세그먼트를 16비트씩 나눠서 다 더해서 checksum과 비교
-> cheksum과 다르면 에러로 판단, 같으면 에러 없다고 판단
-> 그런데 checksum이 같다고 에러가 없다는 것을 의미하는것은 아니다.(특정 부분에서 빠지고, 다른 부분에서 더해지면 총 합은 같기 때문)

- 16비트가 두개만 있다고 가정
- 두개를 더한다
-> 자리수가 올라가면 wrap around(앞의 1을 맨 뒤에 더해줌) 해준다
-> 체크섬에는 1의 보수 취해서 저장(0,1 바꿔서)

checksum을 일단 0으로 해 둔다.
-> ip pseudo 헤더 부분까지 포함하여 checksum을 계산해서 저장한다. (ip는 네트워크 레이어의 도움을 받아야함)
-> 중간에서 끝나면 16비트 만큼 나머지 0으로 채워준다.(16비트로 나누는데 앞에서 끝나버리면 나머지 부분들은 0으로 채워줌)
principles of reliable data transfer
어떻게 data를 reliable 하게 보내는가
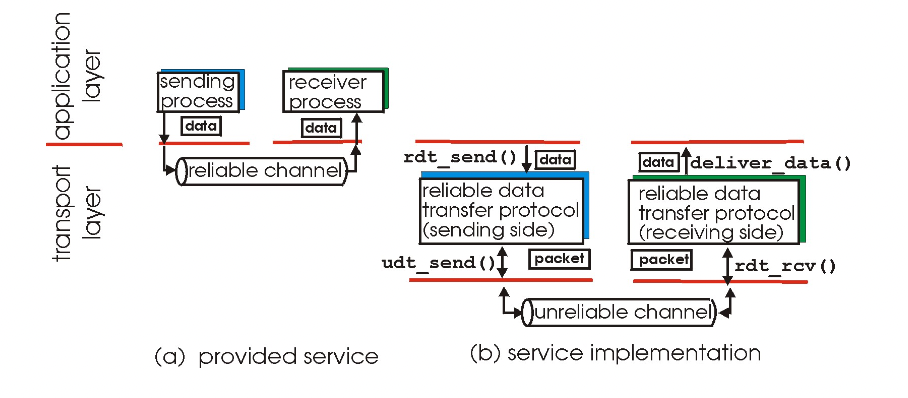
- 어플리케이션 레이어 입장에서는 보내면 reliable이 보장 된다고 생각한다.
-> 트랜스포트 레이어에서 이 부분을 구현해 줘야함. (아래 레이어들(링크 레이어)은 unreliable한 상황)
-> 그림의 네가지 함수들을 통해 reliablility 보장(rdt_send(), udt_send(), rdt_rcv(), deliver_data()) - Unreliable channel의 특징이 reliable data trnasfer protocol(rdt)의 복잡성을 결정한다.
-> 많이 unreliable 하다면 복잡해지겠고, 어느정도 커버 해준다면 덜 복잡해 지고.

데이터 전송은 한 방향이지만, 패킷 loss가 된 경우 다시 요청해야하기 때문에 control info는 양방향으로 흐르게 된다.
-> 샌더와 리시버가 동작하는 방법을 fsm형태로 설계(fsm : 시스템 동작 설명하는 방법)
RDT는 Reliable Data Transfer, UDT는 Unreliable Data Transfer로 모두 전송 계층(Transport Layer)의 프로토콜이다. RDT는 신뢰성 있는 전송을 보장하는 프로토콜을 의미하고, UDT는 신뢰성이 보장되지 않는 프로토콜을 의미한다.
Control Info는 데이터 통신에서 제어 정보를 담고 있는 메시지를 의미합니다. 이는 송신 측과 수신 측 간의 통신을 제어하는 데 사용됩니다. 예를 들어, 전송된 데이터 패킷이 손실되거나 중복되는 경우, 수신 측에서 송신 측에게 재전송을 요청하는 등의 제어 정보를 주고받을 수 있습니다.
Control Info는 데이터 통신에서 다양한 기능을 수행합니다. 이를 통해 에러 검출 및 복구, 데이터 흐름 제어, 혼잡 제어 등을 수행할 수 있습니다. 이러한 제어 정보는 네트워크 프로토콜의 일부로 구현됩니다. 예를 들어, TCP는 제어 정보를 사용하여 신뢰성 있는 데이터 전송을 보장합니다.
rdt 1.0: reliable transfer over a reliable channel
- reliable한 채널 위에 만든 경우(아래 래이어가 reliable한 경우)
- underlying channel이 완벽하게 reliable한 경우
-> bit error가 없다.
-> 패킷의 loss가 없다.
-> 할게 딱히 없다.
rdt 1.0: FSM specification
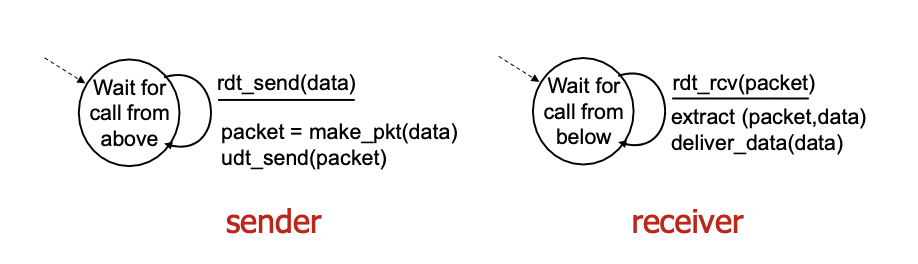
- sender : 어플리케이션 레이어가 데이터를 보내주면 패킷을 만들고(데이터에 헤더를 붙임) 패킷을 아래 레이어로 전송한다.
- receiver : 아래 레이어로부터 패킷을 받으면 패킷에서 헤더 떼서 데이터 추출하고 데이터 전달
rdt 2.0: Channel with bit errors
- 비트 에러가 발생하는 경우
-> 아래 채널이 패킷의 비트를 바꾼 경우
-> checksum을 통해 bit error를 detect한다.(오류있다는 사실만 알지 어디서 틀린지는 모름) - 에러를 복구하는 방법
-> 에러가 있는 패킷을 버리고 송신자에게 알려서 재전송 받아야 한다.
-> 이것을 위해 feedback을 해 줘야 한다.(control message를 receiver가 sender로 보내줌)
-> acknowledgements(ACKs) : sender가 receiver쪽으로 패킷을 보내면 receiver가 잘 받았다는 내용이 답긴 작은 패킷을 sender쪽으로 보냄.
-> negative acknowledgements(NAKs) : 패킷이 왔는데 checksum을 보니 에러가 있어서 에러가 있다는 내용을 sender쪽으로 보냄.
-> sender 입장에서 NAK이 오면 에러가 있다는 의미이므로 재전송하고 ACK이 오면 잘 받았다는 의미이므로 그냥 넘어감.
rdt 2.0: FSM specification
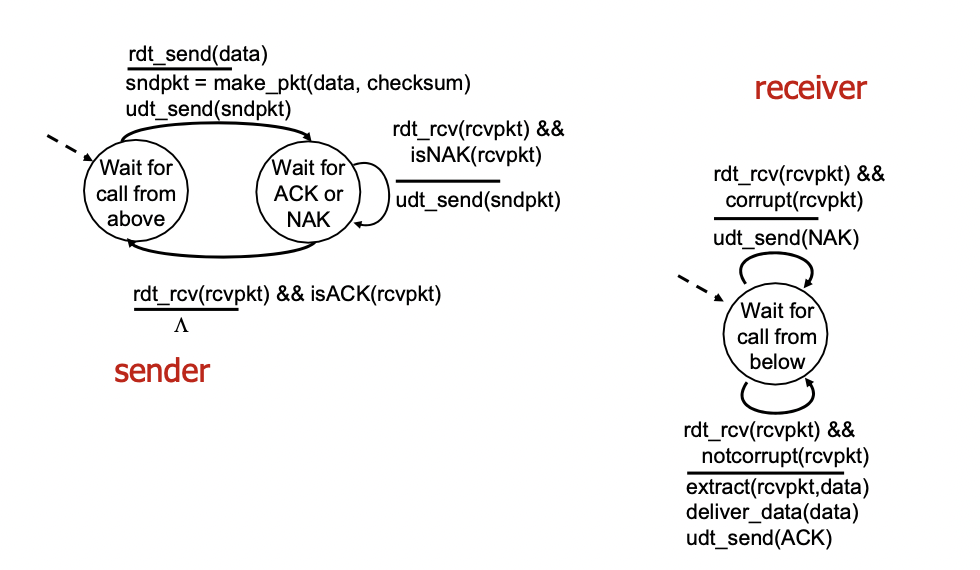
- sender
->데이터를 받으면 패킷을 만들고 보내준 후 ACK이나 NAK을 기다리는 상태로 변경(receiver의 응답 대기)
-> receiver로부터 패킷을 받고 만약 받은 패킷이 NAK이면 재전송
-> 패킷 받고 만약 ACK이라면 아무런 action 취하지 않고 상태만 변경 - receiver
-> 패킷을 받고 받은 패킷이 corrupt라면(checksum을 확인해서 에러 있는 경우) NAK을 보냄
-> 받은 패킷이 notcorrupt라면 데이터를 추출하여 전송해 주고(어플리케이션 레이어로), sender에게 ACK을 보냄
문제점
- ACK이나 NAK이 제대로 올 것이란 보장이 없다(얘네마저 비트에러가 있을 수 있음).
-> ack이던 nak이던 다시 전송하면됨
-> 근데 리시버에서 이미 왔던건지, 새건지 모름
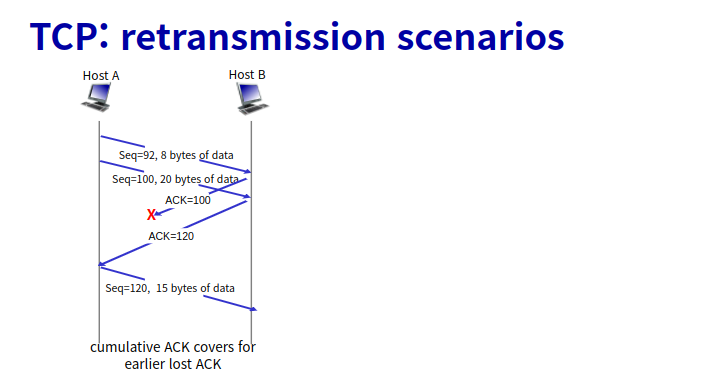
-> 그저 다시 전송하면 duplicate 가능성 있음 - duplicate 해결 방법
-> sender는 ACK,NAK에서 corrupt가 일어나면 패킷을 재전송 한다.
-> sender는 각각의 패킷에 sequence number를 붙임
-> duplicate인지 아닌지 알 수 있음
-> receiver는 받은 패킷이 왔던것이면 버리고 새것이면 처리해줌
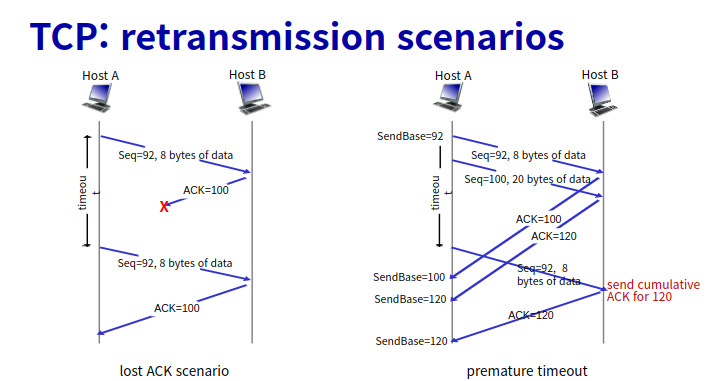
예를들어 sender가 receier에 패킷을 보내서 receiver가 ACK을 보내줬는데 sender에서 못받았다고 하자.
-> 그냥 다시 패킷을 재전송하면 receiver 입장에서 새 패킷인지 왔던 패킷인지 모른다.
-> 그래서 sender가 숫자를 붙여서 0번 패킷을 보낸다.
-> receiver가 받아서 ACK을 보내줬는데 만약 sender가 못받으면
-> sender는 다시 0번 패킷을 보낸다.
-> receiver 입장에서 0번은 왔던거니까 그냥 버리고 ACK만 보내준다.
stop and wait이라고 한다.
rdt 2.1: handles garbled ACK/NAKs
왜곡된 ACK/NAK 처리하기 -> 위에서 발생한 문제점 해결을 위해 sequence number를 이용
-> sequence number를 나타내기 위해 1비트만 사용한다(0,1만 구별 가능)
-> 이것을 통해 ACK/NAK 손실을 해결한다.
rdt 2.1: FSM specification
- sender

-> 첫 상태 : 데이터 받으면 헤더에 0 붙여서 패킷 만들고 보내고 상태 변경
-> 뭔가 받았고, corrupt이거나 NAK이면 재전송하고 상태 유지(상태 : ACK이나 NAK 0를 기다림) / 뭔가 받았고, notcorrupt이고, ACK이면 상태 변경
-> 데이터 받으면 헤더에 1 붙여서 패킷 만들고 보내고 상태 변경
-> 위 내용 반복
- receiver
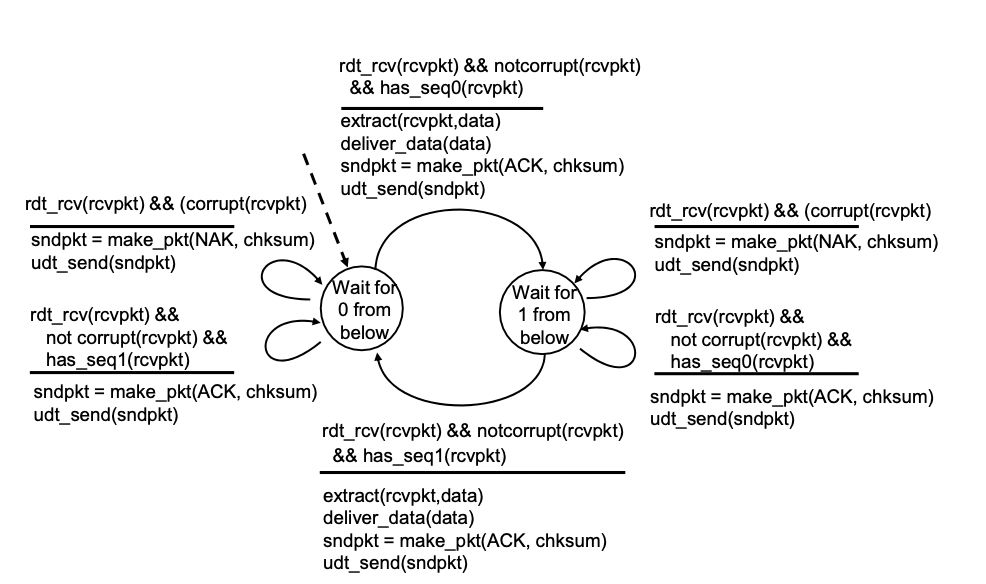
-> 0번 기다리는 상태 : 뭔가 받았는데 문제없고(notcorrupt), 0번이면 데이터 손질해서 애플리케이션 레이어로 보내주고, ACK 만들어서 샌더로 보내주고 상태 변경
-> 문제있으면 NAK 만들어서 보냄 / 문제 없는데 1번이면 ACK은 만들어서 보내줌
-> 둘 다 애플리케이션쪽으로 보내는거 없음, 상태도 변경 아님.(문제가 있거나 이미 받은 패킷이니까)
-> 1번 기다리는 상태 : 위 내용 반복
논의점
- sender
-> 패킷에 sequence number를 붙인다.
-> 0,1 만 써도 충분하다. -> stop and wait을 하기 때문
-> 받은 ACK/NAK 이 corrupt인지 확인 해야 한다.
-> ACK이 와야 다음 패킷을 보낸다.
-> 상태가 두배 많다(전에 온 넘버 기억, 어떤 넘버가 올지 대기) - sender
-> 받은 패킷이 중복된것인지 확인해야한다.
여기서 0과 1이 의미하는게, 어차피 stop and wait를 하니까... 0일때 제대로 된 정보가 왔다! 하면 1로 바꾸는거고, 1일때 0이라는 정보가 오면, 이건 옛날 데이터니까 아! ACK가 제대로 안갔구나 하고 ACK를 보내주는 고런 느낌? 그리고 이제 1일때 1이라는 정보가 오면 제대로 된거니까 0으로 상태를 바꾸고...
rdt 2.2: a NAK-free protocol
- 일반적으로 NAK을 안쓰고 ACK만 쓰는 경우가 많음 -> NAK을 안쓰도록 한거
- 기능은 2.1과 같지만 NAK을 사용하지 않는다.
- NAK 대신에 ACK 활용 : receiver는 제대로 받은 마지막 패킷에 대한 ACK을 보내준다.
-> 이것을 위해 ACK에 sequence number 넣어서 보내줌 - sender에서 받은 중복된 ACK이 NAK의 기능을 한다.
-> 중복된 ACK 받으면 현재 패킷 재전송함
rdt 2.2: FSM specification
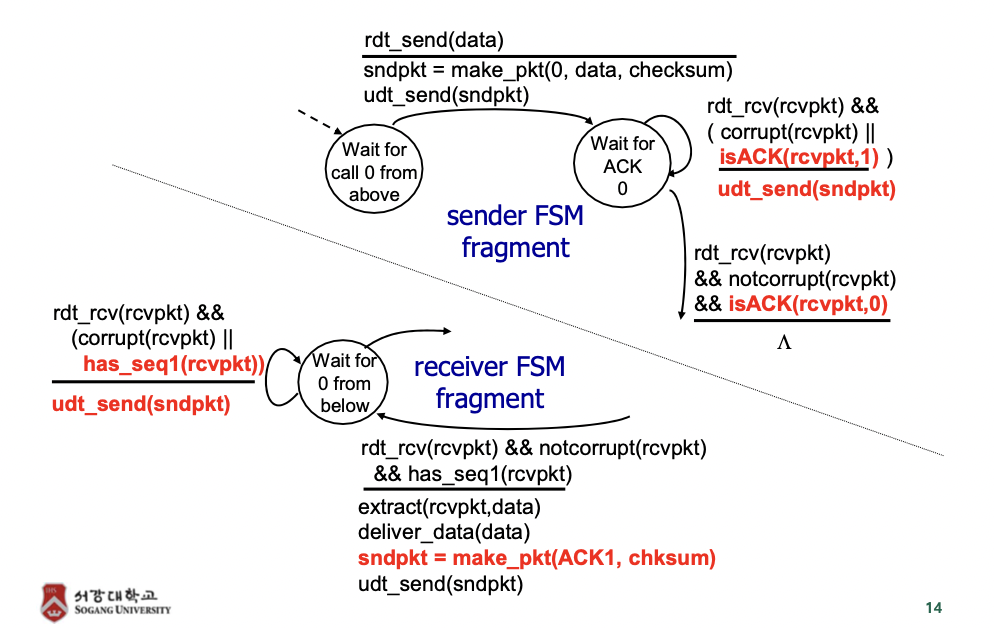
-> 2.1에서 바뀐 부분만 표현함
- sender
-> ACK 0를 기다리는 상태에서 corrupt이거나 받은 ACK이 1번이면 재전송 하고 상태 유지
-> corrupt아니고 0번 ACK이면 다음 상태로 변경 - receiver
-> 1번 패킷을 받으면
-> 상태 변경하면서(1->0을 기다리는 상태) sndpkt(ACK1을 가진 패킷) 만들고 상태 변경
-> 0 기다리는 상태에서 오류가 있거나 받은 패킷이(샌더로부터) 1번이면 sndpkt를 보내고 상태 유지
-> sndpkt에는 ACK1이 저장되어 있으니까 샌더 입장에서 재전송 해줘야 하는거
rdt 2.2는 NAK-free protocol로서, NAK 메시지 대신 새로운 ACK 메시지를 활용하여 손상된 패킷을 처리합니다. rdt 2.2는 rdt 2.1의 문제점인 ACK와 NAK의 충돌 문제를 해결하기 위해 개발되었습니다.
rdt 2.2에서는 ACK 0과 ACK 1 두 가지 유형의 ACK 메시지만 사용됩니다. sender가 패킷을 전송하면 receiver는 그 패킷을 정상적으로 받으면, 이전에 받았던 패킷의 시퀀스 번호와 함께 ACK 메시지를 보내게 됩니다. 이때, 시퀀스 번호는 이전에 받았던 패킷의 시퀀스 번호와 같습니다.
예를 들어, receiver가 0번 패킷을 정상적으로 받았다면, ACK 0 메시지를 보내고, receiver가 1번 패킷을 정상적으로 받았다면, ACK 1 메시지를 보냅니다. sender는 ACK 메시지를 받으면, 이전에 보냈던 패킷의 시퀀스 번호와 같은 ACK 메시지를 받은 것으로 판단하여, 다음 패킷을 전송합니다.
만약, 패킷이 손상되었다면, receiver는 해당 패킷을 버리고, 이전에 받은 패킷의 시퀀스 번호와 함께 ACK 메시지를 보내게 됩니다. sender는 ACK 메시지를 받으면, 이전에 보냈던 패킷을 재전송하게 됩니다.
이러한 방식으로, rdt 2.2는 NAK-free protocol이며, 안정적인 데이터 전송을 보장합니다.
rdt 3.0: channels with errors and loss
2번대는 비트에러에 관한 내용
3.0 : 패킷로스도 발생할 수 있는 경우(라우터에서 오버플로우가 발생해서(들어오는게 나가는거보다 빨라서) 버퍼가 꽉차서 drop되는 경우)
-> 샌더는 보냈는데 리시버가 못받은 경우
-> checksum, seq num, ACK, 재전송은 도움이 될 순 있지만 충분하지 않다.
접근
-> receiver는 아무것도 안받았으니까(패킷이 안온거니까) 동작 안함.
-> sender는 패킷을 보낸 후 ACK이 올때까지 적절한 시간동안 기다린다.
-> 이 시간동안 ACK이 안오면 재전송한다.
-> 어떤 이유로 손실이 아니라 느리게 간 것이라면 그냥 재전송 했을 경우 duplication이 발생한다.(seq num으로 방지할 수 있음)
-> 타이머를 구현해야 한다.
rdt 3.0: sender FSM specification
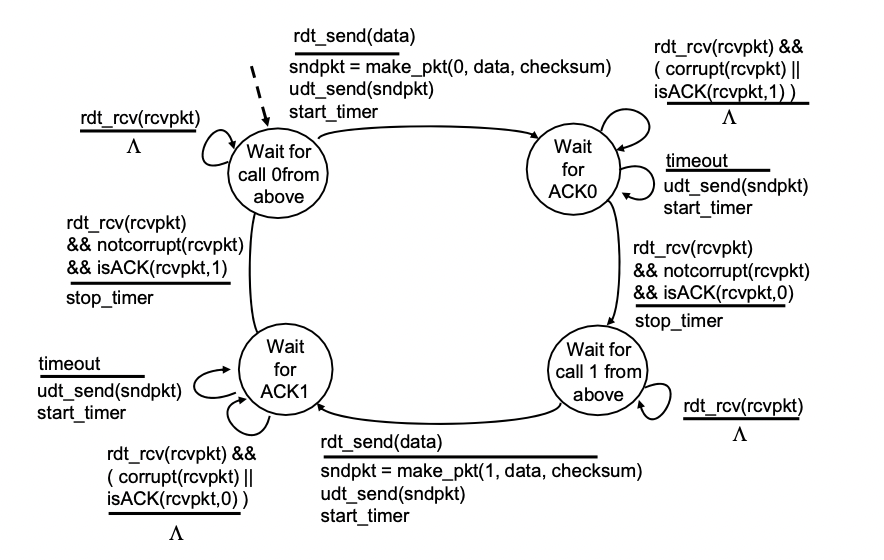
-> 초기상태 : 패킷 만들고 전송 한 후 타이머 시작해서 다음 상태로 넘어감
-> 오긴 왔는데 시퀀스 넘버가 다르거나 문제가 있으면 타이머는 그냥 흘러가도록 놔두고 상태 유지
-> 타임아웃이 걸리면 재전송하고 타이머 다시 시작 하고 상태 유지
-> ACK이 제대로 오면 타이머 스탑하고 다음 상태로 넘어감
동작과정
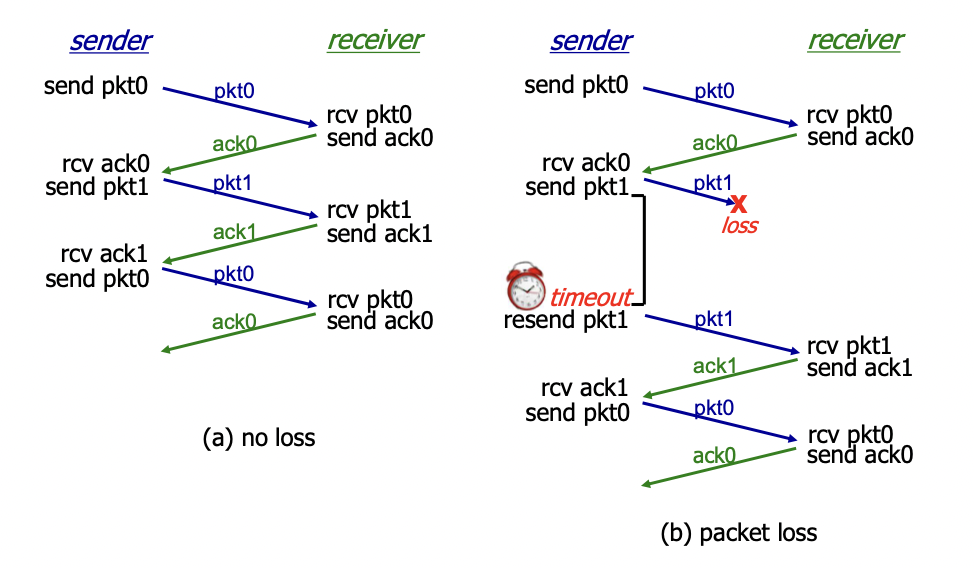
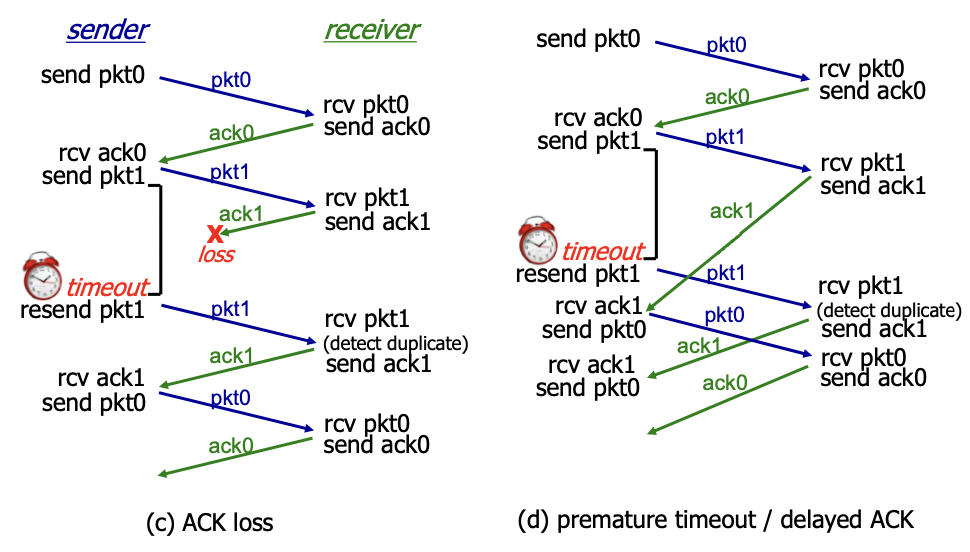
sender만 sequence number를 조작하고, receiver는 이전에 왔던 sequence number를 기억하여 구분하여 쓰게 된다.
(d) 이미지
-> 타이머를 너무 짧게 하면 제대로 보내지긴 하는데 불필요한 재전송이 많아진다
-> performance 측면에서 안좋다.
-> 반면 너무 길게 하면 loss 발생 했을때 복구까지 너무 오래 걸림
-> 적당한 타이머를 구현하는게 중요
performance of rdt 3.0
rdt 3.0은 동작은 잘하지만 성능이 안좋다(stop and wait 때문)

- 전송딜레이 : L/R = 8000bit/1Gbps = 0.008ms = 8 microsec
- 전파딜레이 : 15ms
- RTT(Round Trip Time, 왕복시간) : 15ms * 2 = 30ms
U_sender = (L/R) / (RTT + L/R) = .008 / 30.008 = 0.00027
stop and wait 때문에 ACK를 한번 보내고, 다시 패킷이 올때까지 기다리는 건데, 패킷의 전송속도인 8 microsec에 비해서, ACK를 주고 받는 shaking의 시간이 30ms로 너무 크다. Utilization이 1일때가 효율성이 가장 좋다고 판단할 수 있는데, 0.00027은 엄청 효율이 떨어지는 것이다.
network protocol, 즉 rdt3.0이 physical 자원을 제한하고 있는 것이라고 볼 수 있다.
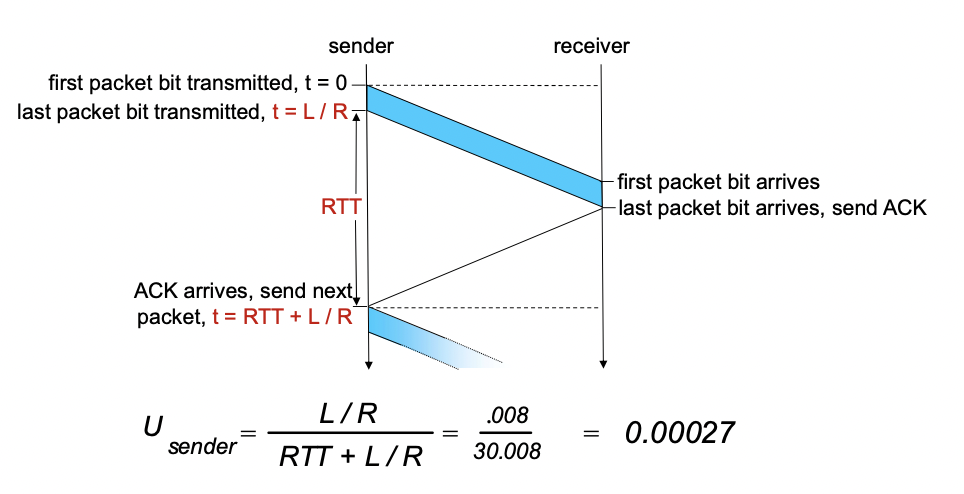
- 하나 보내고 하나 받는 방식
- 전체 시간(RTT + L/R)에 비해 파일 전송에 걸리는 시간 L/R이 너무나도 짧다.
Pipelined Protocols
- 파이프라인 프로토콜(<-> stop and wait)
-> 한꺼번에 여러개의 패킷을 보내서 여러개의 ACK을 받자.
-> 보내지는 여러 패킷들을 구별하기 위해 sequence 넘버가 늘어나야 한다.
-> 버퍼링이 필요하다.
-> go-Back-N, selective repeat 이 많이 사용된다.

정해진 개수의 여러개의 패킷을 보내고, ACK이 오는대로(하나씩 올 때 마다) 다음 패킷을 보낸다.
-> 효율성 정해진 개수배 만큼 늘어난다.
-> performance 측면에서 좋아진다.
-> 단점 : 프로토콜이 복잡해진다.
Pipelined protocols: overview
- Go-Back-N
-> 파이프 라인에 N개까지 ACK을 받지 않은 패킷을 보낼 수 있음.
-> Cumulative ack 사용(리시버는 중간에 비는 번호 없이 다 받았을 때만 ack을 보낼 수 있음. 순서대로 받다가 하나라도 안오면 그 이후로는 패킷 오더라도 ack 안보냄).
-> 타이머 하나 사용(ack 못받은 패킷중 가장 오래된 패킷이 가지고 있음. Expire(time out) 되면 모든 패킷 재전송)
-> 같이 보내진 패킷들을 한번에 관리해서 하나라도 안오면 ack 안보내니까 샌더에서 타임아웃 돼서 안온 패킷부터 재전송 하게 된다. - selective repeat
-> 안보내진 패킷만 재전송하자.
-> Individual ack 사용(따로 관리해서 받은 패킷만 ack 보내고 못받은 패킷은 ack 안보내줘서 못받은 패킷만 재전송 할 수 있게).
-> 각각의 패킷에 대한 타이머 사용.(ACK이 오면 타이머 끄고 expire 되면 그 패킷만 재전송 하면 됨)
-> 타임아웃 된 패킷에 대해서만(ack 못받은 패킷) 재전송
-> 각각의 패킷에 타이머를 실행시킴
Go-Back-N
sender
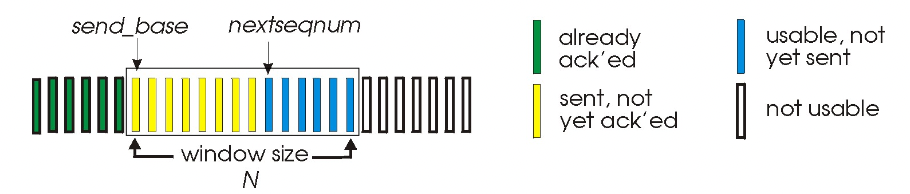
- k-bit를 써서 패킷들을 seq num을 통해 구별한다.
- 필요한 parameter : send_base, window size, nextseqnum
window size : n개까지 한번에 보낼 수 있다라는 것을 알려주는 파라미터
send_base : 전송할 수 있는 윈도우의 가장 앞의 패킷
nextseqnum : 다음으로 보내질 패킷의 시퀀스 넘버
초록색 : 보내고, 이미 ACK까지 받은 패킷
노란색 : 보냈지만 아직 ACK를 못받은 패킷
파란색 : 데이터가 있어서 보낼 수는 있지만, 아직 보내지 않은 패킷
슬라이딩 윈도우 : 사이즈 N은 유지하고, 패킷 보낼 때마다 한칸씩 옆으로 이동
- ACK(n): n번까지 ACK를 다 받았다는 의미 -> cumulative ACK
-> ack이 날아가서 못받더라도 패킷만 잘 전달 됐으면 그 다음 ack이 오면서 앞에꺼 까지 acknowledge 해 줄 수 있다. 이런식으로 누적ack 사용
-> 예를들어 패킷 1,2,3,4 를 보내고 다 잘 전달 됐는데 2,3번 ACK이 날라간 경우 ACK(4)를 통해 앞에것들이 잘 왔다는 것을 알 수 있다.
-> duplicate ack을 받을 수 있음 - oldes in-flight packet 에 대한 타이머
-> in-flight = outstanding = set but not acked
-> 아직 ack 못받은 애중 시퀀스 넘버가 가장 앞에 있는거
-> 얘에 대해서 타이머를 가지고 있다 = 타이머를 하나만 가지고 있다. - timeout(n) : n이라는 시퀀스 넘버에서 타임아웃이 걸렸으면 n부터 전부 다시 보냄
GBN: sender extended FSM
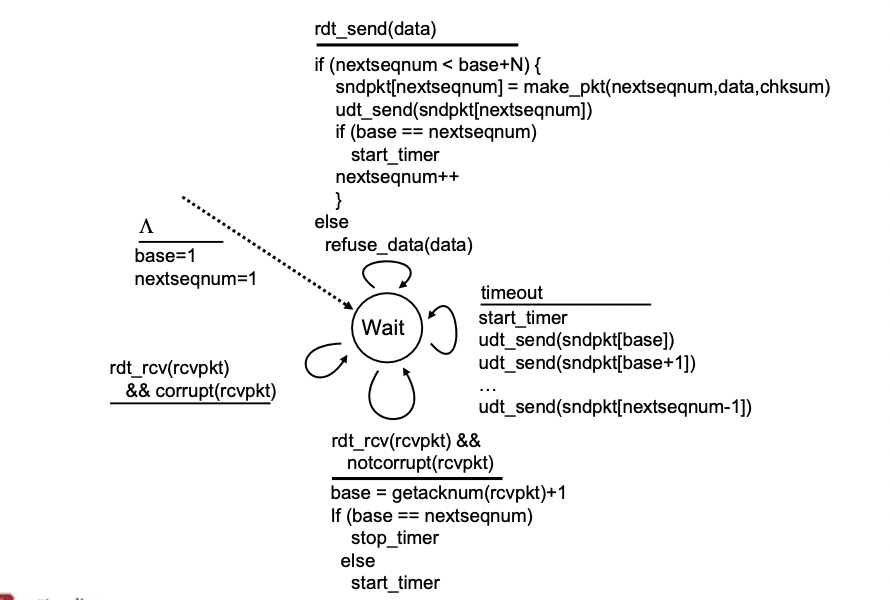
- 하나의 스테이트
-> 이벤트에 따른 반응만 있다. - 애플리케이션에서 데이터를 보내줬을 때
-> 만약 nextseqnum이 base + N 보다 작으면(윈도우 안에 존재하는 경우) 패킷에 헤더 붙이고 네트워크 레이어로 보낸다.
-> 이 과정을 진행 한 후 만약 base == nextseqnum 이면(in-flight packet이면) 타이머 시작
-> nextseqnum++
-> 만약 윈도우 안에 있는 애들이 다 보내진 경우라면 refuse(버퍼링) - timeout 일 때
-> 타이머를 다시 시작하고 베이스 부터 nextseqnum-1 까지 데이터를 다시 전부 재전송한다. - 데이터를 받고 notcorrupt 일 때
-> 베이스에 ack 넘버 + 1을 해준다.
-> 예를 들어 현재 베이스가 5인데 ACK(6)이 오면 베이스를 7로 해준다.
-> 만약 베이스가 nextseqnum이면 타이머 스탑, 아니면 타이머 0부터 재시작 - ack을 받았는데 corrupt일 때
-> 아무 동작 안함
GBN: receiver extended FSM
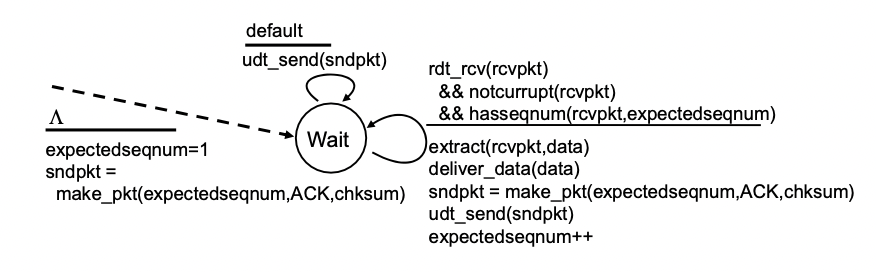

- 타임아웃이 걸리면 어차피 sender가 다 보내주기 때문에 기억할 필요가 없다
-> 단순함 - Ack-only : 어떤 데이터가 오면 항상 ACK을 보내주는데 cumulative ack이기 때문에 in order(중간에 빵구 없이 순서대로 온것)중 시퀀스 넘버가 가장 큰거 보내준다.
-> 예를 들어서 3번 빵구면 expectedseqnum인 A2만 ack으로 보냄. 4번이 와도 2번 보냄. 그리고 2번 이후에 오는 패킷들은 걍 다 버림(discard)
-> 샌더 입장에서 똑같은 번호를 가진 ack을 중복하여 받을 수 있다.
-> expectedseqnum만 기억하면 된다. - out-of-order packet
-> 빵구 이후에 오는 패킷들(순서에 안맞게 온 애들 예를들어 123와야 하는데 132오는 패킷도 포함)은 버리고 버퍼링하는것도 없음.
-> ack을 보내주긴 함. - 초기 상태 : expectseqnum=1로 해 주고 그 번호로 ACK 만든다.
-> 올것들이 제대로 온 상황 : 처리 잘 해주고 보내주고 expectseqnum++
-> default(에러가 있다거나 패킷이 깨졌거나 원하는 번호가 아니거나 등) : 이전에 만들었던 패킷 보내줌
-> 예를 들어 현재 ACK(3)까지 만들어진 상황에 5번 패킷이 오면 ACK(3)을 보내줌. 만약 패킷이 깨져서 와도 ACK(3) 보내줌.
- ACK-only: 해당 시점까지 제대로 받은 packet 중에서, 가장 높은 sequence number로 ACK을 보냄.
- duplicate ACK 발생 가능
- rcv_base만 기억하면 된다.
- out-of-order packet에 대해서는..
- 버리거나, buffer에 저장해두거나 구현에 따라서 달라짐.
- buffering할 수도 있고 안 할 수도 있음.
동작 과정
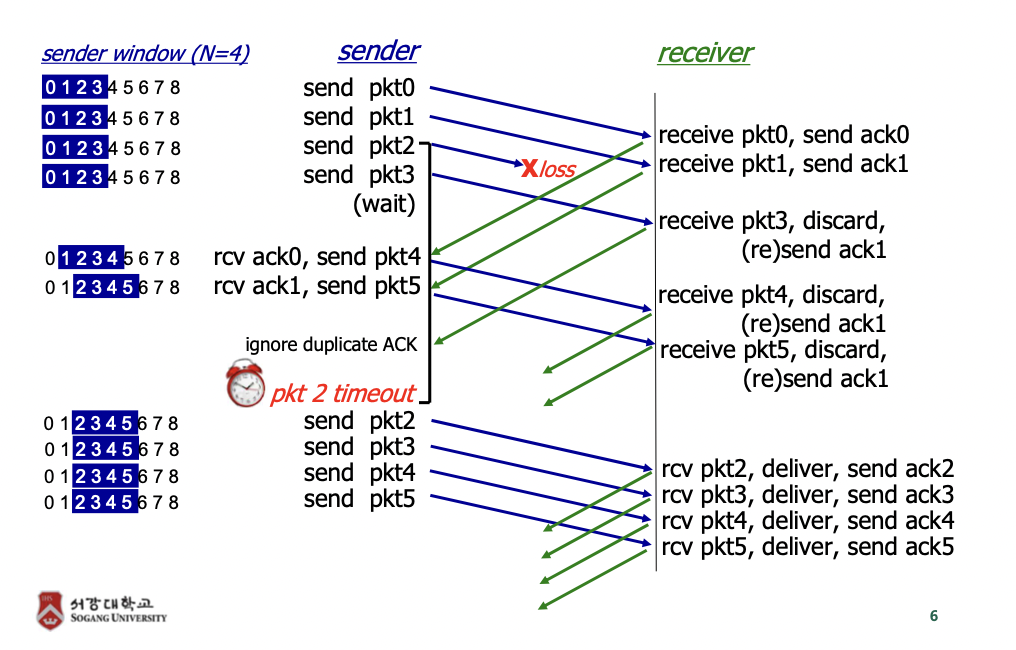
Selective repeat
- Go-Back-N의 비효율성을 해결하기 위한 방식
- receiver는 제대로 받은 모든 packet들에 대해서 개별적으로 ACK를 날림 (not cumulative)
- 상위 layer로의 최종적 in-order delivery를 위해 필요에 따라 packet을 buffering한다.
- Sender는 unACKed packet에 대해서 각각 timeout/retransmit 한다.
- sedner는 각 unACKed packet당 timer를 유지해줘야 한다.
- 그러나 timer는 OS에서 아주 귀중한 resource임...
- Sender window
- 연속인 sequence number들 (~N)
- 전송된, unACKed packet의 sequence number를 제한한다.
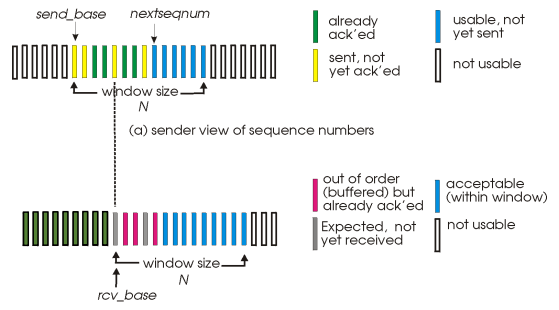
- ACK이 loss되어 timeout되는 경우 sender는 해당 packet만 retransmit
- receiver에게 잘 도달하면, 연속된 sequence number 중 가장 높은 수로 window 이동
Sender
- 만약 window에서 다음으로 가능한 sequence number라면 packet을 보낸다.
- timeout(n): packet n만 다시 보내고, timer restart
- [sendbase, sendbase+N]안의 ACK(n)이 오면, packet n이 받아졌음을 마킹한다.
- 만약 n이 가장 작은 unACKed packet이라면, window base를 다음 unACKed sequence number로 이동시킨다.
- 즉, sendbase는 UnACKed 된 packet 중 가장 작은 값.
Receiver
- Packet n이 [rcvbase, rcvbase+N-1]안에 있다면...
- ACK(n)을 보낸다.
- 순서가 바꼇다면, buffer에 저장
- 제 순서인게 왔다면, 위로 올려주고(deliver buffered), window를 다음 not-yet-received packet으로 옮겨준다.
- [rcvbase-N, rcvbase-1]안의 packet이 왔다면 ACK이 loss됐음을 의미하기 때문에 ACK(n)을 다시 보내줌.
- 다른 경우는 무시 (ACK packet이 loss된 경우. packet은 ignore하고 reACK(n))
- Go-Back-N보다 효율적으로 보이지만, 모든 unACKed packet에 timer가 있어야하기 때문에 overhead가 더 크다.
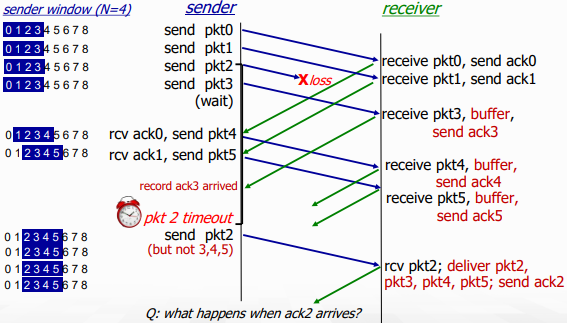
Selective repeat Dilemma
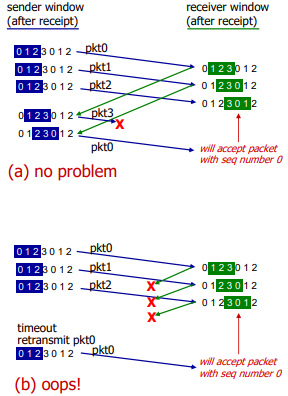
이를 막기 위해선 sequence number / 2 >= window size 여야만 한다.
Connection-oriented transport: TCP
TCP
- point to point: one sender, one recevier. (1대1 통신)
- reliable, in-order byte stream
-> byte만 처리하며, message는 application layer가 처리
-> message boundary들이 없음 - full duplex(bi-directional) dta:
-> 같은 connection에서는 양방향 data flow
-> MSS: Maximum segment size가 존재
-> 보통 1460 byte
== MTU(Maximum Transfer Unit) 1500byte - Header 40byte (TCP 20, IP 20) - cumulative ACKs
- pipelining: TCP congestion과 flow control은 window size를 설정한다
-> congestion window size와 flow control window size가 1개씩 존재 - Connection-oriented
-> data 교환 전에 sender와 receiver는 handshaking으로 connection을 초기화한다. - Flow controlled
-> sender는 receiver를 압도하는 양을 보내지 않는다.
TCP Segment
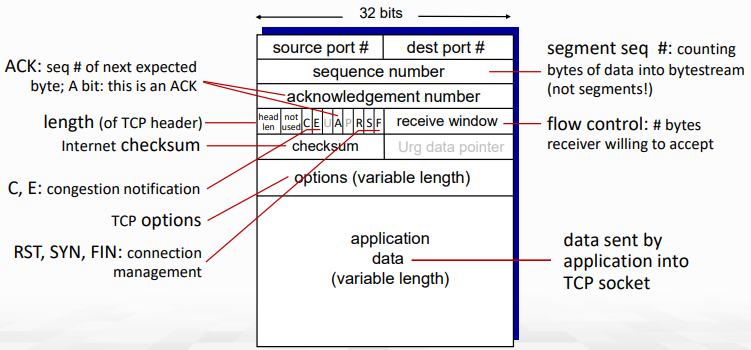
- port 확인은 TCP/UDP가 동일하다
- Sequence number: packet에 담긴 byte의 bytestream에서의 시작 위치 (#번째 segment를 가리키는 것이 아니다!)
- RST, SYN, FIN: connection management용
- 각각 reset(close channel), syncronize, finish를 의미
- Acknowledgements: 다음으로 받고싶은 (기대중인) byte의 시작 위치
- cumulative ACK의 기능을 하게 된다.
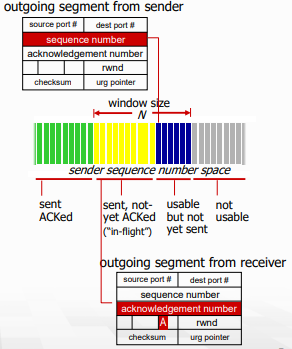
- Q. receiver는 out-of-order packet을 어떻게 handle?
A. TCP spec은 그런거 모름. 구현자에 따라 달림
TCP seq. numbers, ACKs
Sequence numbers
예를 들어, TCP로 전송되는 데이터가 "Hello World!"라고 가정해봅시다. 이 데이터는 아래와 같이 바이트 스트림으로 구성됩니다.
48 65 6c 6c 6f 20 57 6f 72 6c 64 21여기서 첫 번째 세그먼트는 5바이트의 크기로 "Hello"를 포함하고, 두 번째 세그먼트는 7바이트의 크기로 " World!"를 포함합니다.
이 때, 첫 번째 세그먼트의 Sequence number는 0으로 설정됩니다. 따라서, 두 번째 세그먼트의 첫 번째 바이트는 전체 데이터에서 5번째 바이트인 "o"입니다. 따라서, 두 번째 세그먼트의 Sequence number는 5가 됩니다.
이렇게 Sequence number를 설정함으로써, 수신측은 전송된 데이터를 바이트 단위로 조립하면서 데이터의 유실 여부와 순서 등을 검사할 수 있습니다.
piggy backing
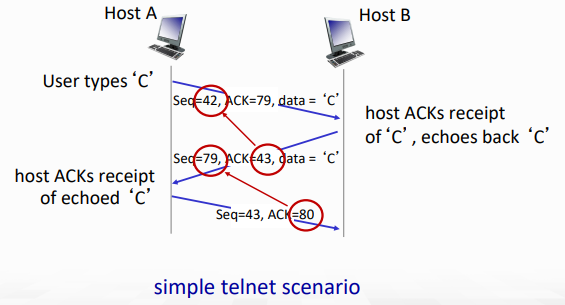
- 데이터 'C'가 1byte라서 Seq #와 ACK #이 1씩 오르는 모습을 확인할 수 있다.
- 그건 그렇고 ACK packet에 data가 같이 들어있는 모습도 볼 수 있는데
- 이를 piggy backing이라고 한다.
- receiver가 data를 보내야하는 상황에서 발생하며, TCP segment에 ACK flag field 덕분에 이것이 가능한 것!
- ACK flag가 set이면 그건 ACK packet으로 여겨지며, application data field에는 ACK과 무관하게 데이터를 담을 수 있다.
TCP RTT(Round Trip Time), Timout
Q. TCP timeout 값은 어떻게 설정할까?
RTT보단 길어야되는데, RTT가 너무 다양하다!
Too Short: 일찍 timeout되어 불필요한 재전송이 많아짐
Too Long: segment loss에 대한 reaction이 느려짐
Q. RTT는 어떻게 계산할까?
SampleRTT
- segment 전송부터 ACK 수신까지의 시간을 측정
- retransmittion은 무시해야됨. ( retransmit하는 동안 ACK이 도착할 수 있으니까.. )
SampleRTT는 다양할 것이기 때문에 RTT를 좀 더 부드럽게 계산하고자 함
단지 지금의 SampleRTT가 아니라 몇몇 최근의 측정값들을 평균내서...
EstimatedRTT
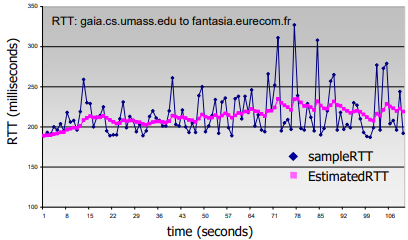
- EstimatedRTT = ( 1 - a ) previous_EstimatedRTT + a current_SampleRTT
- exponential weighted moving average(간단히 이동평균)을 써서 계산
- 최근 값이 영향을 더 많이주고, 과거의 값은 점점 영향력이 떨어진다는 점이 포인트
- 보통 a값은 0.125정도를 준다.
- 음? EMA 필터다...
TimeoutInterval
- EstimatedRTT에 safety margin을 더한 값.
- TimeoutInterval = EstimatedRTT + 4 * DevRTT
- DevRTT = (1-b) DevRTT + b |SampleRTT - EsitmatedRTT| (b는 보통 0.25)
- DevRTT는 EstimatedRTT에서 파생된 SampleRTT의 이동평균임
TCP Reliable data transfer
TCP는 rdt(reliable data transfer) 서비스를 IP의 unreliable service 위에서 동작한다.
- pipelined segments 전송을 사용한다. -> 윈도우를 설정해놓고 여러 개의 패킷을 보낼 수 있다.
- cumulative acks를 사용한다. -> ack가 오게 되면, 그 이전의 ack들을 다 받았다는 것을 확인하게 된다.
- single retransmission timer -> Go-Back-N 방식을 사용하여 timer를 한개 사용한다.
Retransmissions는 다음과 같은 상황에 발생한다.
- timeout 발생
- duplicate acks
TCP는 Selective Repeat 방식보다 Go-Back-N 방식을 선호하는데, 이는 다음과 같은 이유 때문입니다.
첫째, Selective Repeat 방식에서는 수신측에서 패킷을 저장하기 위한 버퍼가 필요합니다. 이는 많은 메모리를 필요로 하며, 메모리의 낭비가 발생할 수 있습니다.
둘째, Selective Repeat 방식에서는 수신측에서 각 패킷마다 ACK를 보내야 합니다. 이는 패킷 송신과정에서 불필요한 오버헤드가 발생하며, 네트워크 지연을 더 악화시킬 수 있습니다.
반면에 Go-Back-N 방식은 패킷 손실이 발생하면, 재전송을 위해 이전에 보낸 모든 패킷을 재전송하므로 패킷의 순서가 꼬일 수 있습니다. 하지만 이는 패킷이 몇 개 없는 경우에만 문제가 되며, 대부분의 경우에는 큰 문제가 되지 않습니다. 따라서 Go-Back-N 방식이 더 효율적이며, 대부분의 TCP 구현에서 이 방식을 사용합니다.
TCP Sender
- Event: application으로부터 data가 도착함
- sequence number와 함께 segment를 만듦
- sequence number는 segment의 첫 번째 bte의 byte-stream number임
- 이미 작동 중인게 아니라면, timer를 시작
- oldest unACKed segment에 대해서 실행중인 timer를 생각해서..
- expiration interval은 TimeoutInterval
- Event: timeout
- timeout을 일으킨 segment 재전송 후 timer 재시작(Go-Back-N하곤 살짝 다름, 그 이전의 모든 것들을 요청하는 것이 아닌 segment 하나만 재전송)
- Event: ACK 도착
- 만약 이전까지 unACKed segment인 ACK이 도착한거라면 ACKed로 업데이트
- 여전히 unACKed segment가 있다면 timer 시작
Fast Retransmit
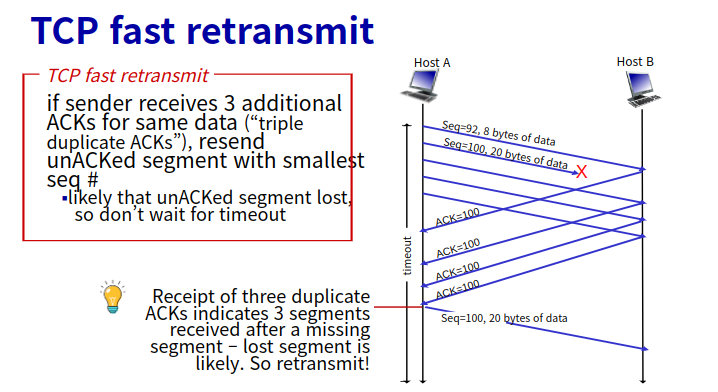
Fast retransmit은 타이머의 타임 아웃 기간이 상대적으로 너무 길어 타이머가 종료되기 전이라도 중복된(duplicate) ACK를 3번 받으면 바로 재전송을 하는 기능이다. 손실된 패킷을 재전송하기 전 발생하는 긴 지연시간을 줄여준다.
Duplicate ACK 수신을 통해 세그먼트가 손실되었음을 감지한다. 손실된 경우 수신 측은 여러 중복 ACK들을 발생시킨다. 송신자는 동일한 데이터에 대해 3개의 ACK를 수신하면 ACK 된 데이터 이후의 세그먼트가 손실된 것으로 가정한다.
Duplicate ACK는 비정상적인 순서(out-of-order)의 패킷이 수신될 시 수신 측에서 발생시키기 때문에 현재까지 ACK가 완료된 패킷 다음 패킷이 손실 난 상태에서 그다음 패킷들이 계속 수신되는 경우이다.
TCP Receiver
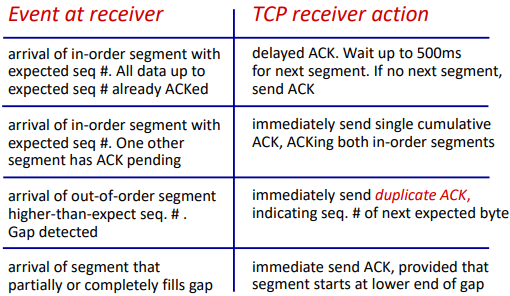
- Event: In-order segment가 도착
- cumulative ACK(이전까진 모두 ACK을 보낸것)를 사용하기 때문에 500ms 정도를 다음 패킷을 기다리고 보낸다. delyed ACK
- Event: In-order segment가 왔는데, pending중인 아직 ACK이 안된 segment가 있음
- in-order segment에 대한 각각의 single cumulative ACK를 합쳐서 보낸다.
- Event: Out-of-order segment가 도착
- 이전의 duplicated ACK을 보냄
- Event: 만약에 out of order segment를 저장하고 있었는데 부분이나, 갭 전체를 채워주는 segment 도착
- ACK을 보내고, segment start를 갭의 끝에서 가장 낮은 번호로 보냄.(맨 왼쪽)
- 중요한 것은 Packet이 오면 바로 ACK하는게 아니라, 좀 기다렸다가 마지막꺼에만 ACK을 보낸다. (cumulative ACK)
- 실제로 2개씩 packet을 받아서 ACK한다고 함..
TCP flow control

Q. 만약 network layer에서 전달되는 data의 속도가 application layer에서 socket buffer를 비우는 속도보다 빠르면 어떻게 되냐?
A. Buffer overflow (Loss)
Socker buffer에서 overflow로 인해 drop되면 cost가 너무 높아짐..
TCP segment header에서 flow control field가 여기에 사용됨
Flow Control
receiver는 sender를 control한다. 그래서 sender는 너무 많이 보내서 receiver의 buffer가 overflow되지 않도록 너무 많이, 너무 빨리 보내지는 않는다.
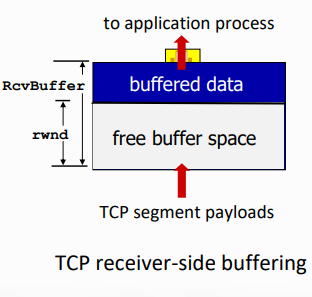

- TCP receiver는 TCP header의 rwnd field(receive window field) 안의 free buffer space 값을 전달한다.
- RcvBuffer는 socket option을 통해서 사이즈를 설정할 수 있다. (default는 4096)
- 많은 OS는 RcvBuffer를 자동으로 조절한다.
- sender는 rwnd 받아 unACKed in-flight data의 총량을 제한한다. (window size 조절로써 제한)
- receive buffer가 overflow되지 않음을 보장
TCP connection management
- data를 교환하기 전에, sender/receiver는 handshake를 한다.
- connection 설립을 합의하고 (둘 다 connection하고 싶은지)
- connection parameter들의 합의함 (starting sequence number 등)
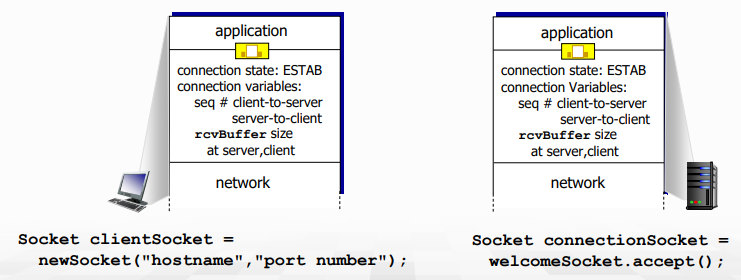
Why not 2-way handshake?
- delay가 다양하며, message loss로 인한 message 재전송, message reordering의 문제가 있다.
- 결정적으로 상대방의 state를 못 보는 상황에서, 2-way로는 정보가 너무 부족하다.
- half open connection problem이나 dup data accept problem 가능..
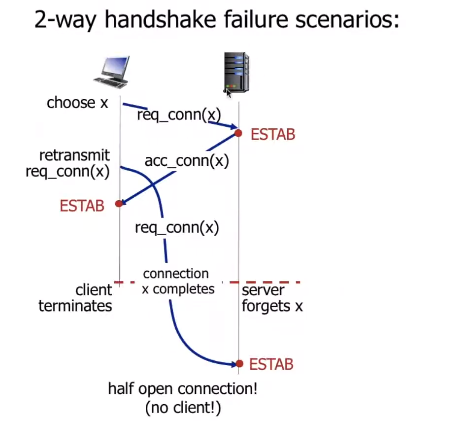
half open connection(no client!)

TCP 3-way handshake
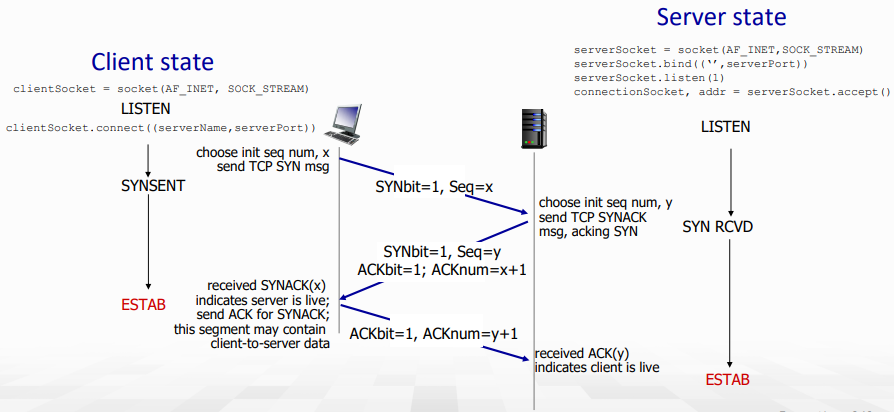
- 처음 client는 TCP SYN msg를 보낸다. (TCP segment header에 있던 SYN flag set)
client는 SYNSENT 상태 (NOT ESTAB), seq = x - server는 SYN packet을 받으면 SYNACK을 날린다.
server는 SYN RCVD상태 (NOT ESTAB), seq = y & ACK = x+1 - client는 SYNACK에 대한 ACK 패킷을 날린다.
이때 client에는 connection ESTAB, ACK = y+1
해당 packet에는 data 포함 가능 (piggy backing)
-> 보통은 첫 연결에 client가 데이터 포함할 일이 없음... - server가 ACK을 받으면 server 또한 connection ESTAB!
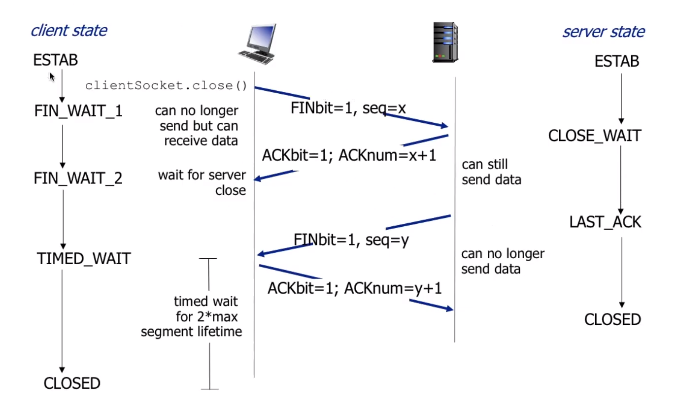
Closing TCP connection
- client와 server는 connection의 자신 쪽을 각자 닫는다.
- FIN bit가 1로 set된 TCP segment를 날림
- 도착한 FIN에 ACK으로 응답함
- FIN을 받았을 때, 그에 대한 응답에 FIN과 ACK을 합쳐서 날릴 수 있음
- 동시에 FIN을 교환하는 상황도 handle 가능!
Congestion control
congestion의 용어 정리를 먼저 해보자. congestion이란 network에서 handling할 수 없을 정도의 속도로 너무 많은 source가 보내지는 상황을 이야기한다.
congestion 때문에 발생할 수 있는 문제는 아래와 같다.
- long delay (라우터 buffer에서의 queuing delay)
- packet loss (라우터의 buffer overflow)
몇 번이고 언급했지만, flow control과 congestion control은 다르다.
- flow control: receiver가 sender에게 너무 압도 당하지 않도록 보내는 packet 수를 제한하는 것
- congestion control: network에 너무 많은 packet으로 인한 overhead(congestion)을 막기 위해 보내는 packet 수를 제한하는 것
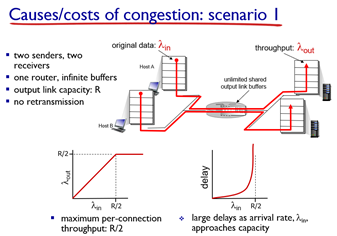
가장 먼저 무한한 버퍼를 갖는 router에 2명의 host와 2대의 서버가 있다고 하자. 그럼 2개의 flow가 있게 된다. 이 상황에서의 특징은 아래와 같다.
- buffer가 무한하기 때문에 재전송은 발생하지 않는다. (packet loss가 일어나야 재전송임)
- 아래 그래프에서 볼 수 있 듯 R/2까지만 속도가 증가하고, 더는 증가하지 않는다. (flow가 2개니까)
- 또한 라우터에 들어오는 속도가 R/2에 가까워질수록 queuing delya는 기하급수적으로 상승한다.
- 이유는 저번에도 다뤘듯, 이 속도가 average이기 때문에 실제로는 dynamic(random)해서 버퍼에 쌓이게 됨..
- congestion의 cost는 queuing delay가 된다.
이후 buffer가 유한한 상황이라고 가정해보자. buffer가 유한하면 packet loss가 발생할 수 있고, packet loss가 발생하면 retransmit도 발생한다. 즉, 실제로 보내는 양이 전체 packet 양보다 더 늘어나게 된다.
- 만약 sender가 router buffer가 사용가능할 때만 보내면 위의 상황과 같아지지만, 실제로는 buffer state를 알 수가 없다..
- 또한 loss시의 retransmit을 위해 TCP에서는 오리지날 Data를 저장할 buffer를 유지해야 한다.
- 다시 app은 그냥 tcp를 한 번 호출할 뿐이기 때문에 TCP에서 임의로 다시 application layer의 데이터를 가져올 수가 없다..!
- 재전송시 이 TCP buffer에서 데이터를 보낸다.
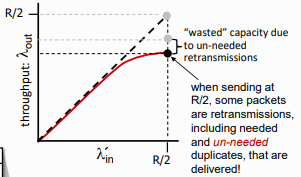
때문에 이렇게 retransmission으로 낭비된다.
또한 실제로는 Premature timeout 등으로 인한 unneeded duplicates가 존재하게 되는데, 때문에 여기서 더 손실이 발생해 최종적으로 위와 같은 그래프가 된다.
이쯤에서 congestion을 발생시키는 2가지 요인을 살펴보자
1. receiver throughput보다 더 많은 work (retransmission)
2. unneeded retransmissions: 같은 packet의 multiple copy가 link로 전달되는 상황...
마지막으로 더 많은 host가 더 많은 router을 경유해서 서버에 도달하는 시나리오이다.

path에 2개 이상의 라우터가 있는 경우이다. 이때, 위 그림에서 빨간색 flow의 실제 in rate(람다'in)이 계속 증가한다고 가정해보자. 그렇게 되면, 같은 라우터를 공유하는 파란색 flow의 packet은 모두 버려지게 되고, blue throughput은 0에 수렴하게 된다.
- closer host가 router의 모든 data를 점유하게 되는 것.
- 점점 더 많은 packet이 버려지면, 파란색 flow의 first hop router 또한 점점 많아지는 retransmit에 의해 마비된다...
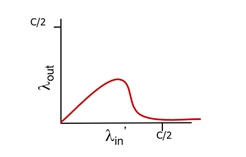
결국 최종 그래프는 위와 같다.
여기서 또다른 congestion cost (congestion의 원인)을 찾을 수 있다.
-
packet drop시, 해당 packet을 위해 사용된 upstream transmission capacity와 buffering이 모두 낭비(버려짐)된다!
-
파란 flow의 throughput이 0에 가까워지면, 파란 flow에 들어간 모든 자원이 낭비되는 것이며, 그렇게되면 그 자원을 쓸 수 있었던 다른 flow들 또한 throughput이 0에 가까워진다...
최종적으로 네트워크 전체가 붕괴하게 된다.
보면 하나의 flow가 7~80%를 차지하는 순간 output rate가 급격히 감소한다.- 최종적으로 요점만 살펴보자.
-
throughput은 capacity를 초과할 수 없다. (이 경우 R/2)
-
최대 capacity에 가까워질 수록 delay는 증가한다.
-
loss와 retransmission은 effective throughput을 감소시킨다. (보내는 양이 더 느니까..)
-
Premature timeout으로 인한 un-needed duplicated packet은 또 effective throughput을 감소시킨다.
-
Upstream transmission capacity와 buffering은 downstream의 packet loss를 증가시킨다.
Congestion control
congestion control은 두 가지로 나눌 수 있는데, 하나는 네트워크의 도움을 아예 받지 않는 end-end congestion control이고, 다른 하나는 Network-assisted congestion control이다.
End-end congestion control
- Network로부터의 명시적 feedback 없음 (network의 정확한 상태 모름)
- loss나 delay를 관찰하면서 congestion인 것을 추론함.
- TCP에서 사용하는 접근법!
Network-assisted congestion control
- Flow가 congested router를 지나게 되면, Router가 sending/receving host에게 직접 feedback을 날린다.
- congestion level이나 sending rate 설정 등을 지시할 수 있다.
- TCP ECN, ATM, DECbit protocol 등에서 사용한다.
TCP congestion control
얼만큼의 data를 network로 보낼 수 있는지 알아내는 방법과, 어떻게 destination에 닿을 수 있는지 등을 자세히 배울 것이다.
여기서 주의할 점은 무턱대고 낮은 rate로 데이터를 보내면 안되는 것이, 너무 적은 data가 network상에 있으면, 이는 Network의 under utilization을 의미하게 된다. (네트워크 관계자들에게 이는 sin이다!)
또한 이렇게 하기 위해서 두 가지 접근 방법이 있을 수 있다. 바로 congestion이 발생하면 그때 처리하는 것(congestion detection)과 congestion이 발생할 것 같은 상황을 감지해서 의도적으로 피하는 것(congestion avoidance)가 그것이다.
그럼 이제부터 Dynamic한 network 상황에서 적당한(congestion이 발생하지 않는 수준에서 최대의 속도)로 데이터를 보내는 기법들에 대해서 알아보자.
AIMD: Additive Increase, Multiplicative Decrease
TCP에서 가장 많이 쓰는 기법 중 하나로, Congestion detection에 속하는 기법이다. 접근은 이제 조금씩 보내는 양을 늘리다가, congestion 발생시(loss 발생시) sending rate를 줄이는 것이다.
- Additive Increase: loss가 감지될 때까지, 매 RTT마다 1MSS(Maximum Segment Size)만큼 보내는 양을 늘린다(= cwnd를 늘린다).
- Multiplicate Decrease: loss 감지시, 보내는 양을 절반으로 줄인다.
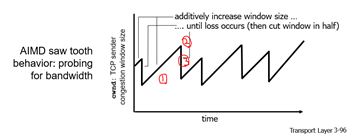
위 그래프를 보면 이해하기가 더 쉽다. (톱날 모양이라서 Sawtooth behavior라고 한다.)
Network resource는 유동적으로 변하기 때문에 따로 threshold값을 사용하진 않는다.
Q. 한 번에 줄일때 왜 발생하지 않을 정도로만 줄이지 반씩 줄이냐?
A. 실제 network에는 무수한 host들이 존재하기 때문에 너무 dynamic해서 계산을 통해 줄이는 것은 쉽지 않다. 또한, 이렇게 확 줄여야 congestion 해소가 빨라진다.
Q. MIAD(두배씩 늘리고, congestion시 1씩 감소)로 해보면 어때?
A. Congestion해소가 너무 느려진다... congestion 발생시 모든 host가 불편함을 느끼기 때문에 이를 빨리 해결하는 것도 관건임.
이 때 언제 반으로 줄이는지에 대해서도 여러 방법이 존재한다.
- Triple duplicate ACK을 통해 loss가 감지되는 경우 Cut half (= TCP Reno)
- Timeout으로 인해 loss 감지시 Cut to 1 MSS (= TCP Tahoe, 더 오래됨)
이를 통해 전체적인 TCP sending을 살펴보자.
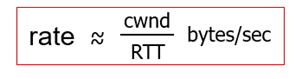
- cwnd(Congestion WiNDow)만큼의 byte를 보내고, RTT만큼 ACK을 기다린다. 그리고, 다시 그만큼 byte를 보낸다.
- TCP sender는 inflight data수가 cwnd를 초과하지 않도록 transmission을 제한한다.
- inflight data = LastByteSent - LastByteAcked <= cwnd
- cwnd는 network congestion을 관찰하면서 조절된다. (TCP congestion control로 구현됨)
transmission rate ≈ cwnd/RTT bytes/sec
-> cwnd가 크면, 더 많이 보낼 수 있다.
TCP Slow Start
TCP는 connection이 시작되면, 첫 loss 전까진 지수적으로 증가한다. 이때 처음 보내는 양은 1MSS이기 때문에 라고 부른다. 이후 한계값까지 2배씩 보내는 양을 늘림(doubling).
1MSS -> 2MSS -> 4MSS(2MSS, 2MSS) -> 8MSS(2MSS, 2MSS, 2MSS, 2MSS, 2MSS, 2MSS, 2MSS, 2MSS) -> loss 발생... -> 4MSS -> 5MSS -> 6MSS -> 7MSS -> .. -> 13MSS -> loss -> 7MSS -> 8MSS ...
- 해당 증가는 모든 ACK을 받았을 때 2배씩 증가시킨다.
- Host는 단순히 ACK 하나 받을 때마다 2개의 packet을 보내는 식으로 구현할 수 있다.
초기 속도는 느리지만, 기하급수적으로 증가한다.
- 1개씩 올리면 최대 throughput에 도달하기까지 시간이 너무 오래걸림...
- 당연히 bandwidth 사용률도 낮아짐..
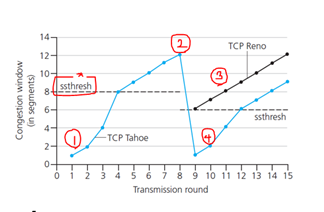
최종적으로 TCP에서 loss detection과 reaction
1. ss_threshold값까진 지수함수적으로 증가.
2. 이후 AIMD로 증가
3-1. timeout 발생시 (징후 발생, Tahoe의 경우) cwnd를 1로 초기화, ssthresh값도 다시 최종 도달한 값의 절반으로 바꿈.
4. 이후 다시 ssthresh값까진 지수함수 적으로 증가, 이후 AIMD
3-2. 혹은 3ACK 발생시, TCP Reno의 경우 해당 시점의 절반 cwnd에서부터 다시 AIMD로 증가(3 Duplicate ACKS 적용시에)

최종 TCP congestion control을 FSM으로 그린 그림이다. slow start를 보면, 처음 ssthresh값은 64KB로 설정되어 있으며, cwnd = cwnd + MSS로 doubling해주는 모습을 확인할 수 있다. 만약 cwnd가 ssthresh를 넘는 경우 congestion avoidance로 넘어가서, dupACK이 3개가 될 때까진 AIMD로 증가시킨다.
congestion avoidance에서는 dupACK이 3개가 되면 fast recovery로 넘어가고, ssthresh값을 현재 cwnd/2로 cwnd는 ssthresh+3으로 설정된다. timeout시 ssthresh는 똑같이 현재 cwnd/2로 설정하지만 cwnd 자체는 1MSS로 줄인다.
3dupACK의 경우 최소한의 packet이 receiver까지 도달했음을 의미한다. (덜 심각)
즉, timeout으로 인한게 더 심각하다! (그래서 cwnd를 1MSS로 파괴해버림)
이 fast recovery에선 여전히 window size만큼의 dupACK이 더 올 수 있기 때문에, 해당 dupACK에 대한 처리를 해준다. 최종적으로 timeout이 되면 slow start로, New ACK이 오면 congestion avoidance로 이동한다.
congestion avoidance, 즉 AIMD가 실행되었을 때, 다음과 같이 증가하게 된다.
cwnd = cwnd + MSS (MSS/cwnd)
10 = 10 + 1 1/10
근데, 결론적으로 ACK는 총 10개가 올 것이다. 따라서... 결론적으로는 1이 더해지게 되는 것이다.
하지만 중간 중간에 늘어나는 양이 있기 때문에 좀 더 받긴 한다.
TCP CUBIC
만든 동기:
아무리 한 host가 congestion을 줄인다고 해도 bottleneck link의 congestion state가 드라마틱하게 변경되지는 않는다.
- Wmax는 congestion loss가 감지됐을 때의 sending rate라고 하자.
- loss시 rate와 window를 절반으로 줄이고, 처음에는 Wmax를 빠르게 키우고 Wmax에 가까워질수록 더 천천히 증가하도록 만든 것.
그래프는 아래와 같다.
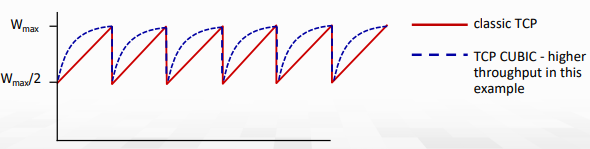
K를 TCP window가 Wmax에 가까워지는 시점이라고 하자. (K는 조절가능) 이때 window는 time과 K 사이의 거리에 3제곱으로 속도를 증가시킨다.
- K에서 멀면 더욱 빠르게 증가
- K에서 가까우면 더욱 느리게 증가
위 그래프에서 congestion이 없는 상황을 가정해 연장하면 아래 그래프가 그려진다.
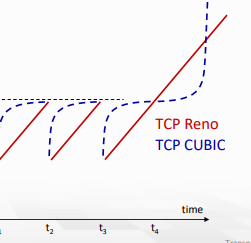
K에 가까울수록 느리고, 멀수록 빠르기 때문에 처음엔 느리게 오르다가 나중엔 급격히 오르는 모습을 볼 수 있다.
- congestion 상황은 짧은 시간내에 바뀌지 않기 때문에 해소된 후에 빠르게 다시 최대 throughput을 점유할 수 있는 방법이다.
Delay-based TCP congestion control
TCP는 일부 라우터에서 packet loss가 발생할 때까지 TCP sending rate를 증가시킨다. 이때 bottleneck link에서 packet loss가 발생하게 된다.
-
많이 보내봐야 congestted bottleneck이 존재하면, end-end throughput은 늘어나지 않는다.
-
Keep end-end pipe just full, but not fuller
- queue가 비는 것은 link under-utilization을 의미. 안좋음
- bottleneck link가 계속해서 transmitting하도록 유지, 하지만 delay나 buffering은 피하도록..
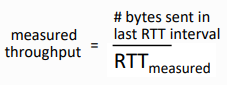
- RTT min값을 구해두고, cwnd/RTTmin을 해서, 이 값과 현재의 측정 값을 비교. 차이가 많이 나면, 선형으로 증가시키고, 차이가 적게나면 선형으로 감소시키기.
이렇게 congestion을 의도적으로 피하는 기법이 congestion avoidance이다. congestion 후에 control을 하면 이미 loss를 경험하게 되는 것이니까 좋지 않다. 반면 delay-based에서는 queue가 길어지면 sending rate를 낮춰 loss가 나기 전에 handling한다.
- 배포된 TCP들 중 일부는 이런 delay-based 접근법을 사용한다.
