Network Layer: The Control Plane
network-layer function에는 forwarding과 routing이 있다고 언급했었다. data plane에서는 forwarding을 담당하며, buffer를 관리하고 control plane에서는 routing을 담당한다.
control plane의 구조는 2가지 접근법이 있다.
- Per-router control (traditional)
- 각각의 router에 있는 control plane들이 서로와 상호작용하여 독립적인 routing algorithm을 통해 routing을 진행하는 것.
- 각각의 router가 path를 결정한다.
- logically centralized control (software defined network)
- Remote controller가 전체 forwarding table을 계산하고 각 router에 설치한다.
- router 내부의 control agent가 remote controller와 상호작용해서 해당 과정을 진행
Routing Protocols
라우팅 프로토콜의 목표는 src에서 dest까지의 좋은 path를 결정하는 것
- 여기서 path는 패킷이 src-dest까지 갈 때 지나가는 router들의 순서
- good은 뭐... cost도 낮고, 빠르고, congestion없는 그런게 좋은 것

link cost는 이렇게 그냥 방향 그래프로 보면 더 쉽다.
각 edge가 갖는 cost가 바로 link cost이며, 만약 연결이 없다면 INF(infinate)로 설정된다.
cost는 network operator에 의해서 설정되는데, 1일수도 있고, bandwidth의 역으로 설정될 수 있고 congestion 상태의 역으로 설정될 수 있다. (congestion이 good이면 low cost)
구체적으로 routing protocol의 분류는 아래와 같다.

글로벌은 모든 라우터가 네트워크 전체 topology와 link cost를 알고 있는 경우이며, link state 알고리즘을 사용한다.
분산형에서는 라우터가 물리적으로 연결된 이웃의 cost만 알고 있으며, 이웃의 정보를 받아 옴으로써 조금씩 업데이트한다. distacne vector algorithm을 사용한다.
-> 차이점은 맨 처음에 router가 전체 정보를 알고 있냐, 자기 정보만 알고 있냐의 차이
정적 알고리즘은 시간에 따른 경로 변경이 매우 느린 것을 의미하고, 동적은 시간에 따라서 휙휙 주기적으로 업데이트 하는 것을 말한다. 주기적으로 link cost를 업데이트 하는 것을 말함.
link state
link state 알고리즘은 우리가 익히(?) 알고있는 다익스트라 알고리즘을 사용한다.
모든 노드가 전체 network topology와 link cost를 알고 있으며, 이는 link state broadcast에 의해서 알게 된다. (모든 노드가 아는 정보가 같음)
- 한 노드에서 최소 비용 경로를 계산하기 위해 다른 전체 노드에 대한 경로를 계산해 forwarding table에 기록한다.
- k iteration후에, 최소 k만큼 떨어진 destination들까지의 거리를 계산할 수 있다.

알고리즘은 다익스트라와 같다.

간단히 설명하면, 시작 노드에서 모든 노드들에 대한 비용을 구한다. 이후 N'에 포함되지 않은 모든 노드들에 대해서 최소비용을 탐색한다. (최소라면 N'에 추가)
이후 해당 노드의 주변 노드를 다시 탐색한다.
원래 경로와 새로 추가된 경로를 거쳐서 가는 경로의 cost를 비교해 더 작은 걸로 업데이트한다.
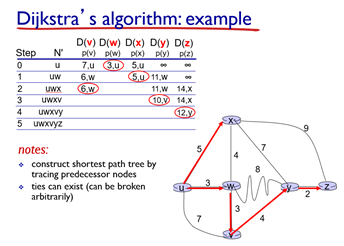
이건 다익스트라가 발생하는 과정을 표로 나타낸 것.
- u에서 모든 노드로의 cost 업데이트
- 그중 가장 작은 D(W) (3, u)선택 (같은게 여러개 있으면 아무거나 선택)
- w를 거쳐 각 노드로 갈 수 있는 cost 업데이트 (기존의 것과 비교해 더 작은 것만 남긴다.)
- 또 남은 것 중 가장 작은 D(X) (5, u)선택
- 반복
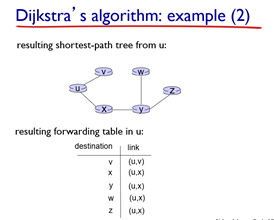
최종으로 남은 그래프는 위와 같고, 표로 나타낸 것도 포함했다. (표에는 시작 router u와 연결된 것 중 가장 첫 번째 router를 기록해둔 것이다.
시간복잡도는 O(n^2)인데, 가장 작은 노드 찾는 과정을 위 코드처럼 heap이나 priority queue에 넣고 하면 O(nlogn + e)으로 가능하다.
또한 각 router는 link state 정보를 다른 n개의 router에 broadcast해야 한다. 이 과정을 효율적인 broadcast algorithm을 사용하면 O(n)만에 link crossing이 가능하다.
- 각 라우터의 메세지가 O(n)개의 링크를 교차하면, 전체가 모두의 메세지를 받는 데는 O(N^2)이 든다.
또한, link cost를 traffic volume에만 의존하도록 설계하면 route oscilation이 발생할 수 있다.. --> 따라서 link cost를 traffic의 정도로만 설정하면 안된다!!!!
아래 그림을 보자. 이렇게 불필요한 반복을 통해 route가 계속 변동할 수 있다.
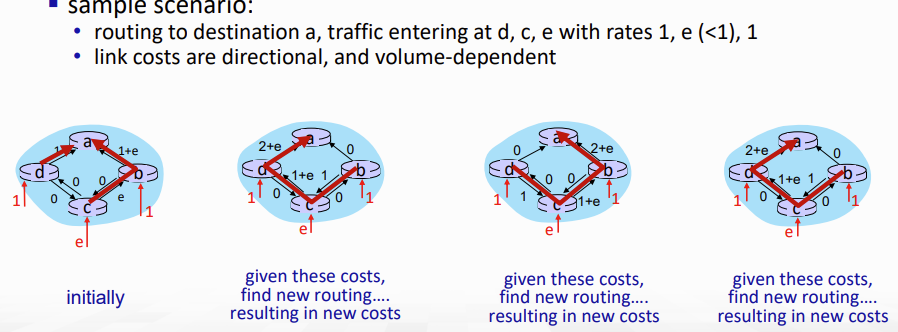
Distance Vector
Distance vector 알고리즘은 Bellman-Ford(BF) equation을 사용한다. (Dynamic programming의 한 종류)

간단히 설명하자면, 이웃 노드로 가는 비용 + 이웃에서 목적지로 가는 비용을 비교해서 최소값을 선택하는 것이다.
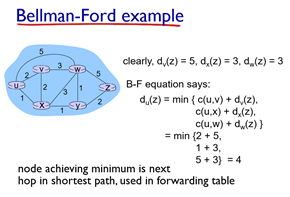
그림을 보면 이해가 더 쉽다. u에서 z로 가는 비용을 계산할 때, 인접한 라우터들 중 어떤 걸 거쳐서 가는 것이 가장 빠를지만 결정하는 것
key point
각 노드가 자신의 distance vector를 계산결과를 이웃에게 보낸다.
각 노드가 이웃으로부터 새로운 DV 결과를 받으면, BF방정식을 사용해 자신의 DV를 업데이트
보통 실제 상황에서 DV는 실제 최소비용 DV로 수렴한다.

즉, 각 노드는 자신의 link state를 모니터링하면서, 이웃들이 notify하는 것을 받는다. 주변의 notify가 오면 estimate를 다시 계산하고, DV가 바뀐 경우에만 이웃에게 알린다.
특징:
- iterative, asynchronous(비동기적): 반복적으로 local link cost가 변하고, 계산하며, 변화가 생기면 이웃에게 update message를 날린다.
- distributed, self-stopping: 각각의 노드가 DV 변화가 있을 때만 알린다.
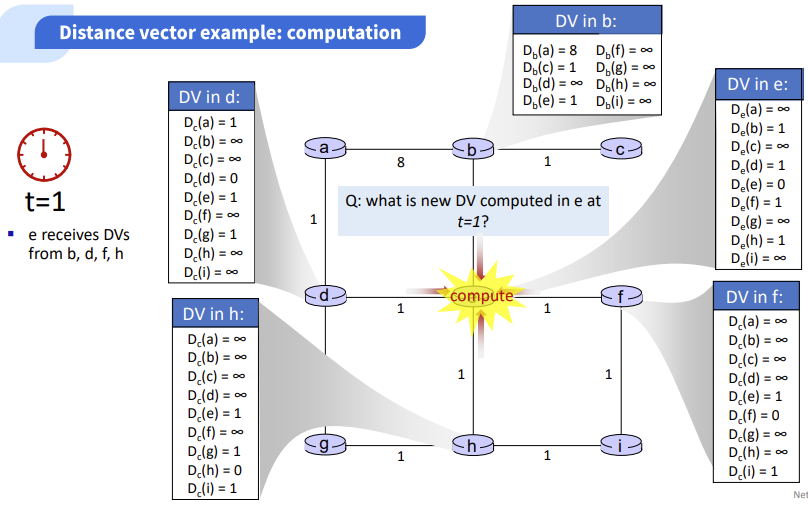
위는 t=1일 때의 DV정보 값들이다. 1일때는 바로 이웃 라우터의 정보를 받아서 거기서 갈 수 있는 정보까지 업데이트된 모습을 확인할 수 있다.
최종적으로 t만큼의 시간이 흘렀다면, t만큼 떨어진 router까지의 최단거리 정보를 계산할 수 있다.
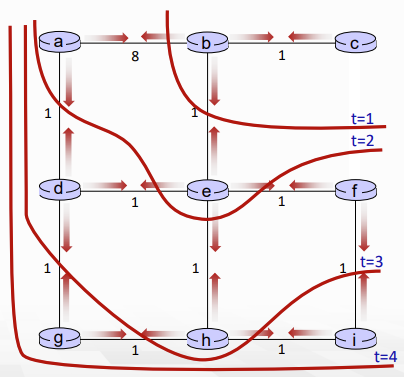
distance vector는 link가 긍정적으로 변하는 경우 빨리빨리 전파되는데, 부정적으로 변하는 경우 엄청나게 느린 속도로 전파된다. 이를 count-to-infinity problem이라고 한다.

이렇게 있을 때, 4가 60으로 바꼈다면 y는 x로 가는 최단 루트를 업데이트 해야됨.
주변을 보니, z를 통해서 x로 가는 루트 (z->y->x)가 5니까, 5+1을 해서 6으로 업데이트하고, 그럼 z는 또 업데이트하고...
z->x로 가는 길이 51이 될 때까지 1씩 반복하면서 업데이트한다. (51이 되면 z->x로 직접 가는 link cost가 50이라 멈춤, 하지만 만약.. cost가 1000이라면?)
해당 문제는 z가 어떤 path를 통해서 x로 가는지를 말해주지 않기 때문임.
LS vs DV
Message Complexity
LS: N개의 노드일 때 O(n^2)만에 메시지 전달
DV: 이웃들 하고만 교환, 각 노드가 최소 cost로 수렴하기까지의 시간은 다양함.
Speed of convergence
LS: O(n^2) 알고리즘 O(n^2)메시지 요구 사용
- Oscillation 문제 발생 가능
DV: 다양한 시간이 걸림.
- 라우팅 루프 문제 가질 수 있음
- Count infinity 문제도..
Robustness(라우터가 이상동작할 때 어떤일 이 일어나는지)
LS: 노드가 잘못된 링크 cost 브로드 캐스트 가능
- 그걸 기반해서 자기 자신의 테이블 계산
- 제한적으로 잘못된 결과
DV: 잘못된 링크가 아니라 잘못된 PATH를 전파
- black-holing
- 각 라우터의 테이블은 다른 것에 사용됨.. 오류가 네트워크를 통해 급격하게 전파
속도
LS: 브로드 캐스트로 모든 노드에게 일시에 교환, 전체 네트워크 상황을 아는 상황에서 작동
DV: 이웃하고만 정보 교환해서 시간 오래걸림
Intra-ISP routing: OSPF
사실 지금까지의 routing에 대한 공부는 약간 이상적인 상황이었다. 모든 라우터가 식별 가능해야하며, network가 flat하다는 가정 하에 계산한 것.
실제로는 당연히 그렇지 않으며, 그렇지 않은 이유가 2가지 있다.
- Scale(billions of destinations) - 크기 :
- routing table에 모든 destination의 정보 저장 불가
- routing table 교환은 link를 마비시킬 수 있음.
2.Administrative autonomy:
- Internet: network들의 network
- 각 network admin은 자신의 network 내부의 routing을 control하길 원함..
한 지역에 있는 router들의 집합체는 Autonomous System(AS, domains)라고 부른다. 이 AS 내외의 통신에는 두 가지 종류가 있다.
- intra-AS (intra-domain, 같은 AS에서의 routing)
- AS 내부의 모든 라우터들은 반드시 같은 intra-domain protocol(link state/distance vector 등)으로 동작해야 함.
- 다른 AS의 router는 다른 intra-domain routing protocol으로 동작할 수도 있음.
- gateway router: AS의 edge에는 다른 AS의 router와 연결된 놈이 있다. 그놈이 gateway
router
- inter-AS (inter-domain, AS들 사이에서의 routing)
- gateway는 intra-domain routing뿐만 아니라 inter-domain routing도 수행한다.
interconnected AS
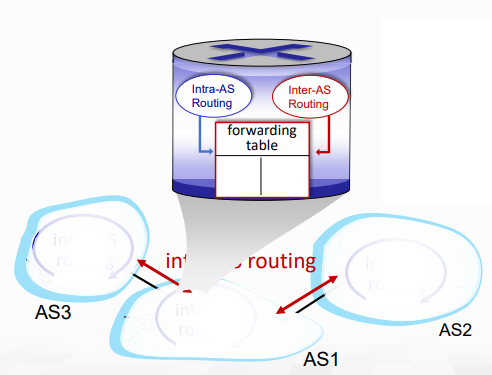
Forwarding table은 intra-AS와 inter-AS routing 알고리즘을 통해서 구성된다.
- intra-AS routing은 AS 안에서의 destination을 위한 entry을 결정해줌
- inter-AS & intra-AS는 external destination을 위한 entry을 같이 결정함.
Intra AS Routing OSPF
Intra-AS Routing: 실제 인터넷은 모든 네트워크가 플랫한 환경이 아닌 어떤 중앙 집중에서 가지치기 형태로 나오는, 트리 형태의 하위 계층을 가짐
scalability issue: 모든 목적지에 대해서 어떤 정보를 라우팅 테이블이 담기는 힘듦. 참여자 수가 늘어남에 따라 급격하게 성능이 악화되어 어느 이상이 되면 전혀 동작하지 않게 됨
autonomous system(AS): 동일한 네트워크 ID를 갖는 집합들(도메인). 한 기관에서 관리하는 네트워크 라우터들의 집합, 호스트들의 집합
-
각 네트워크들은 개별 관리자들이 관리하고 싶어함
-
Intra: AS 내부 라우팅. 대표적으로 distance vector와 link-state
- 같은 AS에 속한 라우터들끼리의 라우팅 알고리즘
- 한 AS 내에서 모든 라우터들은 동일한 인트라 도메인 프로토콜(OSPF, RIP 등)을 사용
-
Inter: AS 외부 라우팅
- BGP(Border Gateway Protocol, Path vector protocol)
-
border router(gateway router, 경계 라우터): AS와 AS를 연결해주는 라우터
-
AS 간의 라우팅을 할 때는 gateway router가 inter-domain routing을 동작
-
하나의 라우터는 intra-AS 라우팅 + inter-AS 라우팅으로 포워딩 테이블 구성: Intra-AS 라우팅 알고리즘만으로는 외부로 가는 경로를 알 수 없기 때문에, Inter-AS 라우팅 알고리즘의 도움이 필요
RIP(Routing Information Protocol)
Distance Vector(30초마다)를 사용하는 프로토콜로 더 이상 많이 사용하지 않는다. path에 대한 (강건성, robustness 문제) 경로의 오류가 발생하면 안됨, count to infinity 등의 문제가 있기도 해서 요즘에는 많이 사용하지 않는다.
EIGRP(Enhanced Interior Gateway Routing Protocol)
Distance Vector based
Cisco가 갖고 있던 프로토콜로 2013년에 공개됨
OSPF(Open Shortest Path First, IS-IS protocol과 동일(ISO Standard)): 단거리를 우선시하는 프로토콜, 표준이 공개되어 이를 따르면 다른 라우터들과 문제없이 통신 가능
- link-state 알고리즘의 대표
- OSPF 메시지를 담은 IP 헤더가 이더넷과 같은 링크 앞에 붙음. IP 레이어 바로 위에 OSPF 메시지가 올라가서 전달됨, 그 자리에 TCP나 UDP가 대신 들어갈 수 있음
- multiple link costs metrics possible : 하나의 link에 대해서 여러 cost를 넣어줄 수 있다.(조건을 걸든 어떤 방식을 통해서라도)
- Link-state advertisement massage를 broadcast 방식으로 서로 주고받아 현재 AS의 topology map을 알게 되고, 다익스트라 수행
- OSPF 메시지
- authentication: 인증을 통과하지 못한 메시지가 전달되면 topology map을 구성할 때 사용하지 않음
- blackhole attack 방지: 어느 링크가 많은 capacity를 가진다고 거짓 정보를 보내 모든 패킷을 그 쪽으로 보냄
- authentication: 인증을 통과하지 못한 메시지가 전달되면 topology map을 구성할 때 사용하지 않음
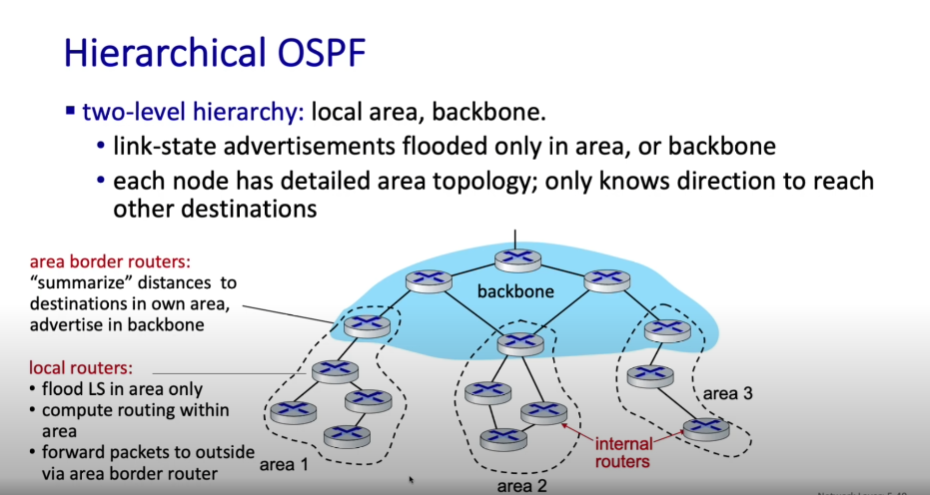
- hierarchical OSPF: 만약 AS가 너무 클 경우, broadcast 메시지가 부담이 되므로 하나의 AS를 여러 area로 나누어 각각 area에 OSPF가 동작하게 함
- 라우팅 테이블을 업데이트 하기 위한 트래픽을 최소화
- area 간을 이어주는 border gateway router들이 존재
- area border router: 하나의 area를 summarize해 정보를 전달
- backbone router: area들을 연결시켜주는 역할
Inter AS Routing BGP
BGP(Border Gate Protocol): 내부 AS에서 외부 AS로 가려면 어떻게 갈지 정함
- 표준은 아니지만 거의 표준처럼 동작
- 네트워크와 네트워크를 연결해 실제 인터넷이 가능하게 하는 프로토콜
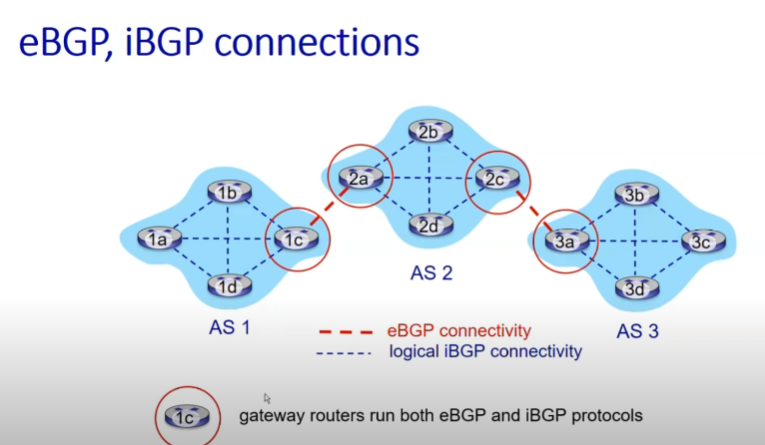
- eBGP(external BGP): 서로 다른 AS에 속하는 border router들이 주고받을 때 사용하는 프로토콜
- iBGP(internal BGP): eBGP를 통해서 얻어 온 AS 정보를 자기 AS 내부 라우터들과 공유
- reachability information와 policy를 고려하여 길 설정
- reachability information: 해당 AS를 통해 전달할 수 있는 네트워크 목적지 정보
BGP 메시지: TCP를 기반(신뢰성 필요)
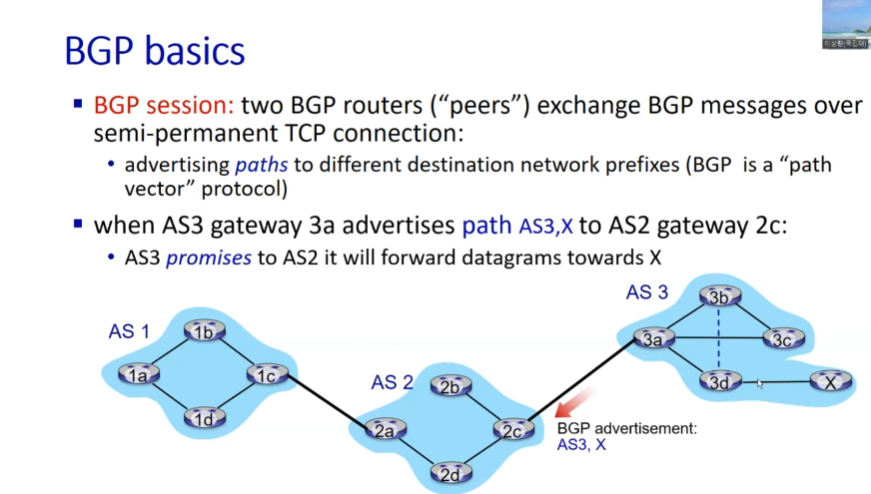
-
semi-permanent: 완벽하진 않지만 두 AS 간에 TCP 연결이 거의 항상 되어 있음
-
특정한 destination network prefixes를 목적지로 가진 데이터그램을 전달하기 위한 path 정보
-
ex) AS 64520이 AS 64512와 BGP 메시지 주고받기
- AS 64520 -> AS 64512 메시지: 192.168.24, 192.168.25 등을 AS 64600 등을 거쳐서 64700으로 내가 보낼 수 있다고 알림
-
path vector 프로토콜: 전달되는 정보가 패스를 말해주는 벡터 형태 ex) 642, 646, 647
- 어느 AS가 다른 AS로 포워드해서 내가 데이터그램을 전해주겠다고 약속
-
메시지에 담긴 정보
- network prefix: 보낼 수 있는 목적지 네트워크 ID
- attribute
- AS-PATH: path vector
- NEXT-HOP: 내가 그 AS로 전해주기 위해 다음으로 선택할 next hop router
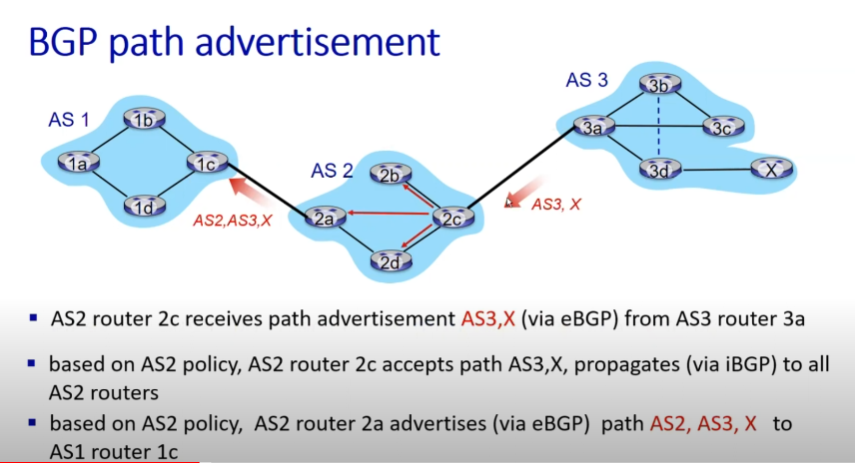
ex) AS2(2a, 2b, 2c, 2d), AS3(3a, 3b, 3c, 3d, x)
- AS3의 border router인 3a가 AS3에 X 네트워크가 있음을 알아냄
- AS2의 border router인 2c에게 eBGP로 알려 줌
- 2c는 iBGP로 내부 다른 라우터들에게 전달 A. X가 가지고 있는 network prefix + path 정보(AS3, X) + NEXT-HOP(2c)
- 따라서 AS2 내부 라우터들은 X에 속한 네트워크 ID가 목적지인 데이터그램은 next-hop인 2c에게 전달하면 AS3와 X를 거쳐 도착 가능함을 알 수 있음
policy-based routing: intra와 달리 inter는 어떠한 path는 accept하고, 어떤 path는 decline하는 등 policy가 중요함
- ex) ISP(Internet Service Provider)인 A, B, C 존재, 고객 w는 A, x는 B와 C, y는 C와 연결
- A는 B와 C에게 Aw로 가는 path vector를 담은 BGP 메시지 전송
- 따라서 B는 BAw라는 path vector를 가짐, 이를 x에 알려줌
- 그러나 B와 C는 경쟁 업체이므로 C에게는 이를 알리지 않음. C가 자신을 통해 보내면 자신의 bandwidth 등의 자원이 소모되므로
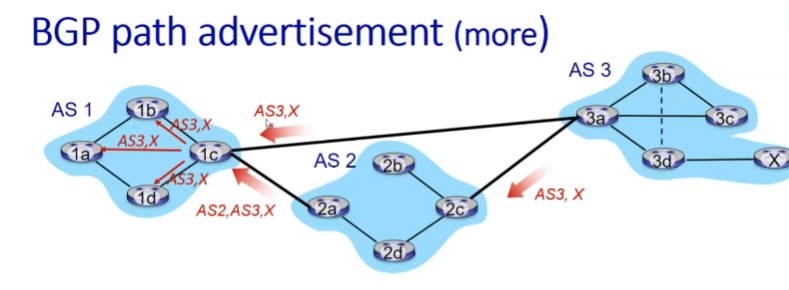
위의 상황에서 AS3, X와 AS2, AS3, x 중에서 어떤 것을 택할지 선택하는 것은 policy에 기반한다.
Hot potato routing: 실제 패스 길이를 따지지 않고, 더 가까운 border router에게 무조건 전달
- 밖으로 보내야 하는 데이터그램을 내부에서 오래 잡고 있으면 내부의 자원을 많이 사용
- 전체 네트워크 관점에서는 이기적이지만, AS의 관리자가 선택할 수 있는 policy 중 하나
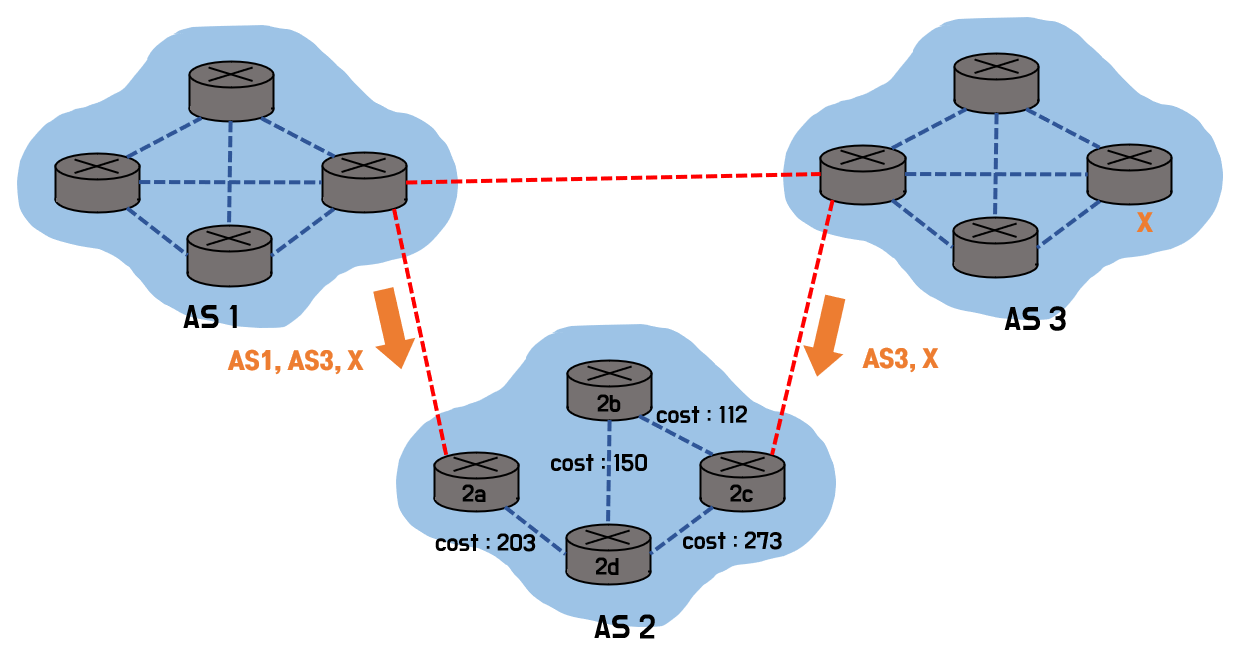
뜨거운 감자를 잡을 경우 그냥 무지성으로 던져버리는 것 처럼, 그냥 무조건 Next-Hop이 짧은 link를 선택한다. 즉, 위의 경우에서는 2d라우터에서 Next-Hop이 짧은 2a 라우터로 전송한다.
Intra-AS routing과 Inter-AS routing 비교
-
둘이 서로 달라야 하는 이유: scalability
- 모든 라우터가 한 레벨에 놓여 있다면 라우팅 테이블 업데이트 트래픽 때문에 전체 네트워크가 마비될 수 있어 AS로 구분
- AS 내에서 intra, AS끼리는 inter로 연결
-
intra는 policy 반영 X, inter는 policy 반영 O
- Inter-AS는 이익관계에 따라서 관리자가 어떻게 트래픽을 어디로 나를 지 결정할 수 있다
- Intra-AS는 관리자가 하나이므로, 정책적인 결정이 딱히 필요하지 않다.
-
intra는 빠르게 전달하는 것이 중요, inter는 policy가 중요
BGP Policy Achievement via Advertisements
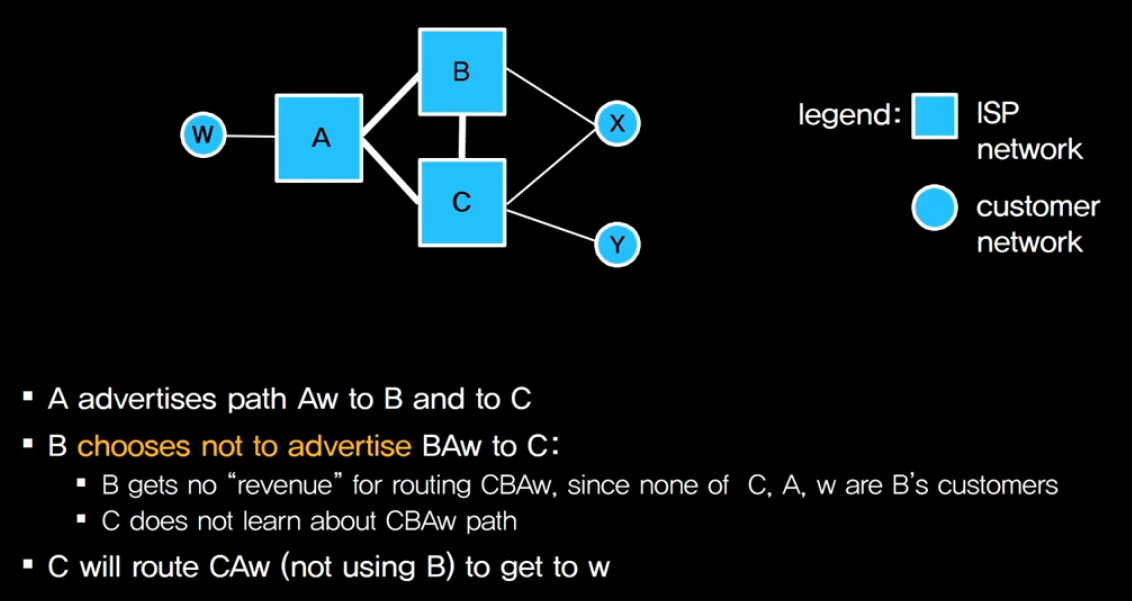
그림과 같은 네트워크가 있다고 가정 합니다.
네모로 되어 있는 A, B, C 네트워크는 ISP,
여기서 B와 C는 서로 경쟁 관계의 인터넷 서비스 Provider입니다.
ISP : Internet Service Provider 인터넷 제공 업자들의 네트워크
그리고 고객 네트워크들을 W, X, Y 라고 표현했습니다.
그러면 A와 B와 C는 각각 개별적인 AS이기 때문에
서로간에 BGP 메시지를 주고 받을 텐데
A는 B와 C한테 Aw라는 네트워크로 가려면
결국 A를 통하면 W로 갈 수 있다는 정보(path vector 정보)를 가르쳐 줍니다.
그러면 B는 BAw라는 경로 vector 정보(path vector 정보)를 알게 됩니다.
이것을 X측에 전달 해 X는 ‘W로 보내려면 B와 A를 통과해서 W로 갈 수 있구나’
라는 것을 알 수 있겠지만 B는 C한테는 알려 주지 않는다는 겁니다.
그에 대한 이유로는 이런 경우를 생각해 봅니다.
C의 입장에서 C와 A 사이에 링크를 전달해서 가면 되는데
C가 이 링크의 bandwidth를 아껴 보겠다고 B를 통과해서 보낼 수도 있다는 겁니다.
그렇게 했을 경우에 B는 괜히 링크의 bandwidth만 소모되게 되고,
내부 노드의 자원도 소모되기 때문에 포워딩 해 주기 싫을 것 입니다.
일부러 알려 주지 않음으로써 C가 W쪽으로 보내야 될 정보를
B를 통과해서 가지 않도록 만드는 Policy가 구현되게 됩니다.
BGP Route Selection
- local preference value attribute를 비교
- 짧은 AS-Path
- closest Next-hop router : hot potato routing
- additional criteria
- 모두 같으면 IP 주소를 4byte의 integer라고 생각했을때 가장 작은 값으로 보내게 된다.
BGP (Border Gateway Protocol)는 대표적인 Inter-AS (Autonomous System 간) 라우팅 프로토콜입니다. BGP는 다음과 같은 주요 작업을 수행합니다:
라우팅 정보 교환: BGP는 서로 다른 자율 시스템 (AS) 간에 라우팅 정보를 교환합니다. 자율 시스템은 ISP (Internet Service Provider), 기업 네트워크 등과 같은 독립적인 네트워크를 의미합니다. BGP는 이러한 자율 시스템 간에 경로 정보를 교환하여 인터넷 상에서 패킷의 전달 경로를 결정합니다.
AS 경로 선택: BGP는 다양한 경로 중에서 가장 적합한 경로를 선택합니다. 이를 위해 BGP는 경로 속성 (예: AS 경로 길이, AS 경로 품질) 및 정책을 고려하여 최적 경로를 결정합니다. BGP는 경로 선택 알고리즘을 사용하여 여러 경로 중에서 가장 우선순위가 높은 경로를 선택하고 전파합니다.
대규모 네트워크 연결 관리: BGP는 대규모 네트워크 연결을 관리합니다. 인터넷은 많은 ISP와 기업 네트워크로 구성되어 있으며, BGP는 이러한 다양한 네트워크 간의 연결을 제어하고 유지합니다. BGP를 사용하여 네트워크 간의 연결을 설정하고 해제하며, 라우팅 루프를 방지하고 네트워크의 안정성을 유지합니다.
외부 경로 공지: BGP는 AS 내부의 라우팅 정보를 외부에 공지합니다. 자신의 AS에서 수신한 경로 정보를 BGP를 통해 다른 AS에 전파함으로써 인터넷 상에서의 경로 결정에 참여합니다. 이를 통해 인터넷 네트워크 간의 연결성을 제공하고 패킷의 전달을 가능하게 합니다.
BGP는 인터넷의 핵심적인 구성 요소로서 대규모 네트워크의 라우팅 및 연결 관리에 필수적인 역할을 수행합니다.
SDN control plane
전통적으로 네트워크 계층은 분산적으로 라우팅을 처리를 했었다.
라우터별로 기본적으로 라우터마다 라우팅 알고리즘이 동작하고 라우터들끼리 통신해서 전체적인 라우팅을 처리하도록 만들어졌었다.
전통적인 방식에서는 라우터가 하드웨어랑 위에서 특별한 하드웨어가 존재하고 라우터에서 돌아가는 특정 OS가 있었다. 시스코라는 스위치 만드는 회사에서는 시스코 전용 OS를 만들어 사용했고, 그 위해서 지원하는 몇가지 프로토콜들을 위에서 일종의 소프트웨어를 올려서 같이 판매를 했다. 라우터 하나에 하드웨어뿐 아니라 os 소프트웨어까지도 포함되어 판매가 되었었다. 이 상황에서 네트워크 계층에 새로운 기능을 추가하고 싶으면 중간에 미들박스라는 것을 새로 추가했다. 미들박스도 하드웨어로 만들어서 판매했다. 방화벽, 로드벨런서 같은 경우는 새로운 미들박스를 구해서 하나씩 추가함으로써 네트워크를 동작하는 방식을 취했었다.
어느 순간부터는 네트워크 컨트롤 플레인에 대해서 다시 생각해보는 기회가 생겼다.
-> 기능이 바뀌면 관련된 sw만 바꿔서 할 수 있으면 좋지 않을까라는 생각이 기반이 되었다. SDN 방식을 고려하게 되었다.
굳이 중앙집중형으로 컨트롤 플레인을 만들어야 하나. 어떤 정점이 있을까
-> 네트워크 관리가 쉬워진다.
-> 하나의 라우터가 잘못설정되어있을 때 전체 네트워크에 영향을 미치는 문제를 해결할 수 있다. 트레픽을 처리하는 과정에서 좀더 유연하게 처리할 수 있다. 내가 원하는 경로로 패킷을 이동할 수 있도록 하나하나 세팅할 수도있다.
SDN을 사용함으로써 이전에는 라우터가 잘못 구성되는 경우도 있었는데 이를 피할 수 있고, traffic flow에 대한 유연성을 더 좋게 만들 수 있었다. 그래서 table-based forwarding 프로그래밍을 하게 된 것이다. (centralized 프로그래밍). 지금까지는 분리된 프로그래밍이었다.
그래서 table-based forwarding에 API를 하나 둬가지고 이부분을 OpenFlow API를 제공해주어 프로그래밍을 줄 수 있었다. 이 OpenFlow는 control plane을 open(누구나 쓸 수 있게)으로 구현하였다.
Traffic engineering
traffic이 한번에 많이 들어 왔을 때 잘 관리해주기 위한 기술이다.
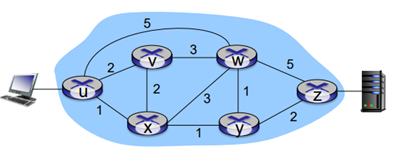
u에서 z로 보내려면은, 기존에는 라우팅 알고리즘을 돌려서 경로를 결정해야한다. 그런데 역으로 생각해서 경로를 먼저 정해주고 보내주는 것은 어떨까?
예를 들면 u-z로 보낼 때 uvwz를 통해서만 traffic을 지나갈 수 있게 경로를 만들어주려고 한다. 그리고 x-z로 보낼 때 xwyz를 통해서만 지나갈 수 있게 만드려고 한다. 이것은 기존 라우팅 프로토콜로 불가능하다.
=> 이런 경로를 SDN에서 프로그래밍 해주는 것이다.
u-z로 보내는데 traffic을 분할하고 싶다. 절반은 uvwz로, 절반은 uxyz로. 이것은 load balancing하는 것인데, 라우팅 알고리즘이 두개 필요로 하게 된다. 그래서 기존 라우팅 프로토콜은 불가능하다.
=> 이런 경로를 SDN에서 프로그래밍 해주는 것이다.
SDN-controlled switches
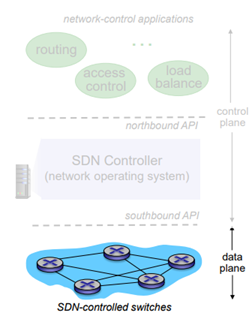
data plane은 SDN control 되어있는 SDN-controlled switch들이다. 이것들은 스위치 기능을 해주는 하드웨어이다.
이 내부에는 flow table이 있어 table 기반의 switch control이다. software에 의해 control 되는 API가 존재하는데 이 API는 OpenFlow를 통해서 단일화되어 있는데, 어떤 것이 control 가능한지, 어떤 것이 안되는지 이런 것들이 정의되어 있다. 그리고 이 controller하고 communication해야 하므로 이에 대한 protocol이 있는데, 이 protocol은 OpenFlow에 의해서 정의가 되어있다.
SDN controller
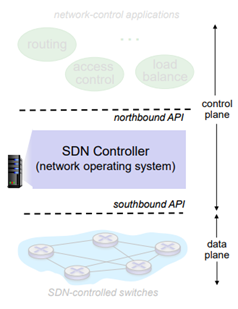
하드웨어 switch 위에는 SDN controller가 있다. 이 controller는 network OS로 생각하면 된다. Network에 대한 상태정보를 갖고 있다. 그래서 실제 application들과 SDN-controlled switches들의 중간역할을 하게 된다. 그래서 SDN controller는 각각 분산적으로 구현이 된다. performance, scalability, fault-tolerance 등을 해결하기 위한 역할을 한다.
network-control applications
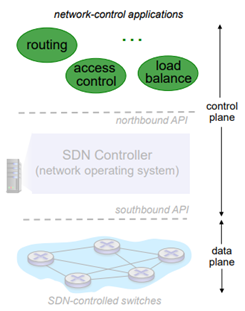
맨 위에 network-control application들 있다. 이게 핵심적인 routing, load balance, access control과 같은 부분이 있다. 여기서 중요한 것은 unbundled이다. 밑에 있는 하드웨어와 독립되어 있다. routing vendor 또는 SDN controller와 분리시킬 수 있다. 이 부분만 다른 vendor를 통해 할 수 있다. 다만 API를 통해서만 하면 된다.
SDN controller에 들어가는 요소들
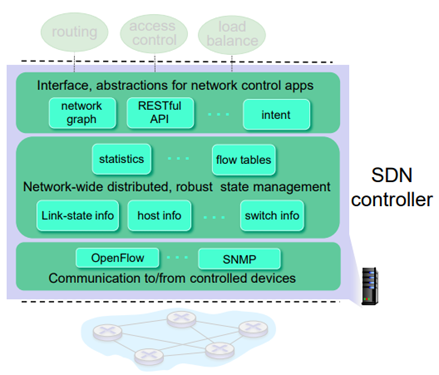
- communication layer : switch하고 통신하는 부분. OpenFlow나 SNMP가 있다. 이런 네트워크를 관리하는 protocol들이 붙어있다.
- Network-wide state management layer : 분산된 switch, router들에 대한 정보들이 DB에 저장이 된다. link-state에 대한 정보, host 정보, 물리적인 switch정보들이 중간에 쌓인다. 그러면 이것으로부터 통계를 뽑아내고 flow table도 만든다.
- interface layer : 바깥 routing이랄지, 맨 위에 있는 프로그램을 실제 하기 위한 API들이 있다.
OpenFlow protocol
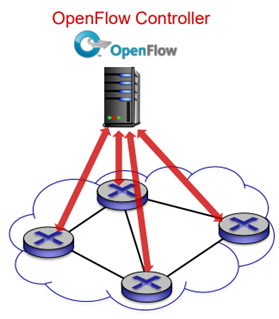
각각의 controller와 switch로부터 공통된 정보를 주고받는 역할을 한다. 여기서는 message를 주고 받기 위해서 TCP가 사용된다(암호화를 선택적으로 선택). 그리고 OpenFlow message를 만들기 위해 세가지 클래스를 만들어놨다. (controller-to-switch, asynchronous(switch to controller), symmetric(msic))
- OpenFlow: controller-to-switch messages
Controller에서 switch로, 위에서 아래로 내려가는 것이다. 이 때는 어떤 message가 내려갈까?
- features : controller가 어떤 switch features에 대한 쿼리를 보내서 switch가 응답한다.
- configure : controller가 어떤 parameter를 설정하는 것이다.
- modify-state : OpenFlow tabale을 추가, 삭제 및 수정한다.
- packet-out : controller가 switch port에서 어떤 패킷을 보내라고 요청한다.
- OpenFlow: switch-to-controller messages
switch에서 controller로, 아래서 위로 올라가는 messages이다.
- packet-in : 어떤 패킷을 controller에다가 전달한다.
- flow-removed : switch에 있는 어떤 flow table entry를 삭제되었다는 것을 알려준다.
- port status : controller에다가 내 port가 바뀌었다고 알려준다.
network opertor들은 OpenFlow messages를 통해 바로 프로그램하는 것은 아니다. 이것은 공통되도록 정해지는 것이고, 실제 모든 것은 controller에서 작동한다. 즉 네트워크의 효율적 운용을 위해서 기능을 잘 분리시켜 놓았다는 것이다.
example
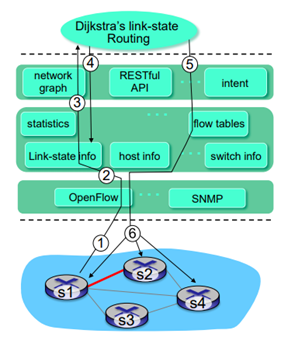
- s1이 controller에다가 link failure가 생겼다고 OpenFlow protocol을 통해서 알려준다.
- 중간에 있는 SDN controller가 이를 받고, 자신의 link state information을 업데이트 한다.
- 이 내용을 위쪽으로 올려서 다이제스트라 알고리즘이 이 변화를 적용해서 알고리즘을 돌리게 된다.
- 이 알고리즘의 계산 결과(route 정보)를 밑으로 내려준다.
- 맨 위에 있는 routing application이 계산된 Flow table을 밑으로 내려준다.
- controller가 OpenFlow 통해서 밑에 있는 모든 switch들에게 이렇게 적용하라고 뿌려준다.
예시(그냥 있다 정도만....)
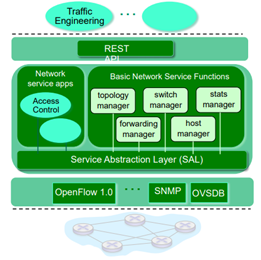
- ODL(OpenDaylight) controller
맨 아래는 이 때까지 했었던 동일한 내용이고, 중간이 핵심부분이다. 어떤 식으로 관리할 수 있게 만들었느냐가 각 Controller마다 다르게 할 수 있는 부분이다. ODL에서는 Network service application을 분리하고 Basic Network Service Functions이라고 해서 여러 manager들로 구성을 해서 구현을 하였다.
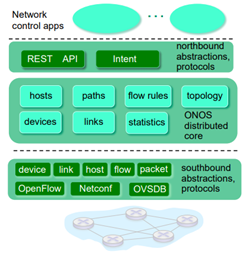
2.ONOS controller
맨 아래 부분이 좀 더 추가되긴 했지만 비슷한 구조이다. 중간 부분은 host, devices… 등등으로 구성된다. distributed core 이 부분에 대해서 많이 계산했다. service reliability라던지, performance scaling 등등… 이런 부분을 고려해서 만들었다.
SDN : selected challenges
SDN은 2010년 이후에 나온 기술로, 나온지가 오래되지는 않았다. 몇 년 되지는 않았지만 급속도로 시스템에 파고들고 있다. 실제 모바일 쪽, 5G 기관망에서도 SDN의 철학이 다 들어가 있다.
그래서 좀 전에 보듯이 controller들을 dependable하게 만들 수 있을까. 즉 얼마나 더 신뢰할 수 있을까. reliable의 상위개념이라고 보면 된다. performance-scalable, secure distributed system. 이런 부분들을 control plane을 얼마나 더 잘 설계할 것인가 하는 이슈가 계속 남아있음. real-time이라던지 ultra-secure 이런 mission-specific한 요구조건들을 맞추도록 어떻게 잘 설계할 것인가는 아직도 연구가 이루어지고 있다.
ICMP : Internet Control Message Protocol
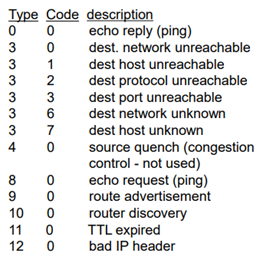
인터넷 상에서 보내고 받고 하는 수많은 control에 대한 부분을 해결해주는 protocol이다. 그래서 host나 router에서 사용된다. 주로 error reporting에 많이 사용된다. ping을 사용하여 echo (한 번 보내면 다시 오는)를 잘 갖고 오는지 확인한다.
그래서 destination network가 unreachable하거나 destination host가 unreachable하다… 등등 이런 여러 에러 메시지들 또는 ping같은 것에 의해서 사용되는 것이 ICMP이다.
ICMP 자체는 네트워크 계층의 프로토콜인데, IP 위에 올라간다. ICMP message는 type, code를 정의해놓고 8byte 정도의 message로 IP datagram에 넣는다.
traceroute

출발지에서 도착지까지의 경로의 상태를 살펴보는 traceroute가 ICMP 이다. traceroute하는 과정을 살펴보자.
UDP로 보내는데, 일단 맨 처음 TTL=1로 찍어서 보낸다. TTL은 라우터 한번만 건너겠다는 뜻이다. 그러면 그 한 번에 담긴 시간과 정보들이 있다. 그리고 TTL=2로 찍어서 보낸다. 라우터를 두번 건너띄게 되고, 건너갈 때마다 각각에 대한 측정된 delay, 시간을 종합하면 전체 경로, node에 대한 정보를 수집할 수 있다. 그 때 사용하는 것이 ICMP로 하는 것이다.
그래서 ICMP message 내에 라우터의 이름이나 주소가 들어가 있다. delay도 계산 가능하다. 결국 destination host에 도착하게 되면, port unreachable message를 type3, code3으로 바꿔서 주면 source는 멈추게 된다.
네트워크 관리란?
autonomous system (또는 domain) 안에는 대략 1000개 정도의 component들이 상호작용하고 있다. 나름 복잡한 시스템이다.
비행기라던지, 핵발전소라던지, 주로 이런데서 모니터링하고 컨트롤 한다. 이것처럼 네트워크 사업자는 지켜보고 관리해줄 필요가 있다. 그래서 이런 것에 대한 프로토콜이 있다. 네트워크 관리는 deployment, integration, coordination, monitor, test 등등 이런 모든 것에 대한 control을 한다. 결국 QoS의 요건이 resonable한 cost로 제공이 되는지, performance가 제공이 되는지 등등 이런 것들을 확인하기 위해서 control하고 관리하고 하는 것들을 네트워크 관리라고 부른다.
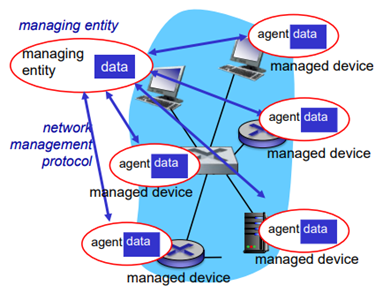
관리를 받는 device들 (router, switch, host 등) 을 각각의 managed device라고 하면 이 device들이 데이터를 전달해서 하나의 어떤 관리체계를 만든다. 그것을 Management Information Base (MIB)라고 부른다. 이 MIB 내에 모든 각각 device들의 object들의 현재 상태들이 다 저장이 된다.
각각의 host들이 하나의 agent이고, 그 안에 data가 있다. 그러면 위 그림의 위쪽 managing entity가 있고, MIB를 돌리는 무언가가 있어야 한다. (server일 수도 있다.) 이 컴퓨터에서 managing entity가 있어서 여기서 MIB를 전부 관리하게 된다. 그래서 각각의 agent하고 주고받으면서 각각의 data들을 가져오는 것이다.
managing entity와 managed device간에 뭔가를 주고 받는데에 대한 프로토콜이 필요해진다. 이 프로토콜의 대표적인 예로 SNMP가 있다.
SNMP(Simple Network Management Protocol)
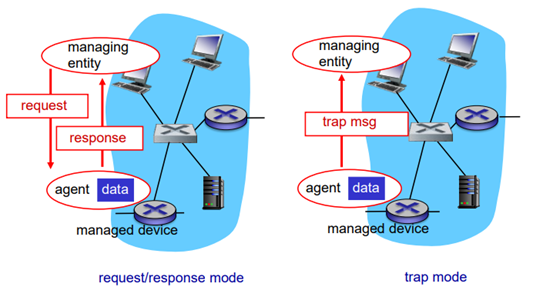
SNMP는 Simple Network Management Protocol의 약자이다. MIB 정보를 보내는 방법에는 두가지가 있다.
-
request/response mode : managed device 각각에다가 request 보내서 response하는 일반적인 mode.
-
trap mode : 어떤 변화가 생겼을 때 데이터들을 같이 유지하는 방식이다. 자기가 갖고 있는 entity가 변화가 생겼을 때, 변화에 대한 것들을 managing entity 서버에 전달해준다. 특별한, 예외적인 상황을 보고해주는 방식이다.
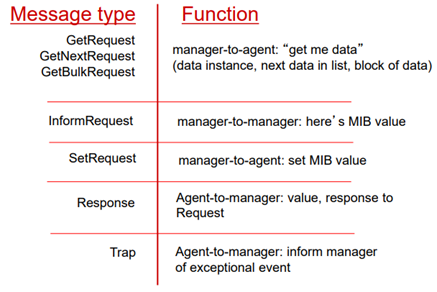
SNMP protocol에는 이와 같이 message type이 정의되어 있다. 주고받는 것에 대한 정보라고 생각하면 된다. trap은 agent가 manager에게 전달하는 예외적인 상황에서 발생한다. request는 어떤 특정 MIB value에 대해서 요청할 수 있다. 그래서 manager가 agent에게 "get me data". 나한테 데이터를 다 보내게 하는 것이다. manager가 agent에게 MIB value를 set하라고 명령할 수도 있다.
출처 :
ttps://velog.io/@cyw320712/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-5-Network-layer-control-plane-1https://cyj893.github.io/network/Network9/
https://ddongwon.tistory.com/97
https://team00csdu준다.tistory.com/149
https://m.blog.naver.com/haryan96/221854872834
https://junghyun100.github.io/Inter-AS-Routing-BGP(2)/
https://inyongs.tistory.com/73
