Abstract
-
MOT의 목표
- bounding box 예측
- object들의 identity 예측
-
문제점
- 대부분의 method들은 threshold 보다 높은 점수의 detection box를 associate 하면서 identity를 얻는다
- 낮은 detection score(occluded objects)을 가진 물체들은 버려짐 → missing detection
-
해결책
-
거의 모든 detection box를 associate하면서 track
💡 Tracklet이란? : 동일한 객체를 시간에 따라 연결한 것으로 객체의 ID, 프레임 간 위치 정보, 그리고 해당 객체와 관련된 추가적인 특성을 포함 → 객체가 여러 프레임에서 감지되며 해당 객체의 움직임이 추적됨을 의미
-
Introduction
➡️ 모든 low confidence detection box들을 제거하는 것이 올바른가?? → “NO”
✅ 위 논제에서 왜 “No”가 나왔을까? 신뢰도가 낮은 detection box는 사실 가려진 물체(Occlusion Obejct)를 의미하는 것일 수 있다.Data Association
발생할 수 있는 문제점 2가지
1. non-negligible missing detection (누락)
2. fragmented trajectories (궤적이 끊어짐)
- Data Association: MOT의 핵심 기술
- detection box와 tracklet 사이의 similarty 계산 (Similarity metric)
- leverage different strategies to match them (Matching strategy)
Similarity metric
- 주요 단서: location, motion, appearance
- SORT : combines location, motion → accurate in the short-range matching
- DeepSort : appearance → helpful in the long-range matching ( 객체가 appearance similarity를 사용하면 긴 시간동안 다른 물체에 의해 가려져도 re-identify될 수 있기 때문에 )
Matching strategy
- similarity를 계산한 후 matching strategy가 object에 identity를 할당한다
- 이를 실행하기 위한 두 가지 알고리즘
- Hungarian Algorithm
- greedy assignment
- 이를 실행하기 위한 두 가지 알고리즘
BYTE
BYTE: simple, effective, generic data association method
-
모든 detection box를 high score과 low score로 나눔
-
high score detection box를 tracklet과 associate
⚠️몇몇 tracklet은 적절한 high score detection box가 없기 때문에 unmatcheh됨 (아래 원인)
1) occlusion
2) motion blur
3) size changing
-
low detection box와 unmatched tracklet을 associate
➡️ low score에 있는 object를 복구하고 background를 분리하기 위해

#3: Det로 detection box(D)와 score을 예측
#6-13: t에 따라 D_high와 D_low로 나눔
#14-16: 트랙의 새로운 위치를 예측하기 위해 Kalman filter 적용
_/ First association /
#17: Similarity #1을 이용하여 T와 D_high를 assiosciate
#18-19: Hungarian Algorithm사용하면서 unmatched detection을 D_remain에, unmatched track을 T_remain에 저장
/ Second association /
#20: Similarity#2를 이용해 T_remain과 D_low를 associate
#21: unmatched T_re-remain을 T_re-remain에 저장, unmatched low score detection box는 삭제
_/ delete background /
#22: unmatched track은 tracklet에서 제거됨
- T_re-remain ? T_lost? 2번째 association 이후 unmatched track인 T_re-remain은 T_lost에 넣어지고, 특정 프레임 수 이상(예: 30) 이상 존재할 경우에만 해당 트랙 T에서 삭제
- T_lost에 보존하는 이유 long-range association을 위해서는 track의 identity를 보존하는 것이 필요
/ initialize new tracks /
#23-25: 첫번째 association 이후 unmatched high score detection box인 D_remain으로부터 새로운 track 초기화
- D_remain은 high score임!
- Similarity#1은 D_high와 예측된 트랙T의 box 사이의 IoU나 Re-ID feature distance 중 하나로 계산될 수 있음
- Similarity#2에서는 IoU만을 사용하는것이 중요
: low score detection box는 보통 occlusion이나 motion blur 이므고 appearance feature는 믿을 수 X
→ BYTE를 다른 Re-ID based trackers에 적용하면 두 번째 연관에서는 appearance similarity을 채택하지 X - MOT에서 SOTA를 달성하기 위해 simple하고 strong한 tracker ⇒ ByteTrack
(YOLOX detector + BYTE method)
Similarity Analysis
[Table 1]
이 테이블 1 같은 경우는, MOT17과 BDD100K에서 validation set에 대한 BYTE의 first association과 second association에 사용된 상이한 similarity 측정 지표를 비교한 것이다. 가장 우수한 결과는 볼드 표시되어 있다.
BDD100K는 왜 Re-ID → IoU에서 가장 우수한 결과가 나왔을까?
low score detection box들은 보통 심각한 occlusion이나 motion blur에 의해서 발생한다. 그런데 Re-ID 특징들을 신뢰할 수 없다. (재식별하기 힘들다) 그래서 second association에서 Similarity #2에서 IoU를 사용하는 것이 중요하다. ⭐️
결과만 보더라도 Similarity #2에 Re-ID보다 IoU를 사용하는 것이 MOT17에서 MOTA가 1.0 더 큰 값을 가진다는 것을 확인할 수 있다.
[Table 2]
MOT 17과 BDD100K의 validation set에 대해 SORT, DeepSORT, MOTDT를 포함한 다른 인기 있는 association method와 BYTE를 비교하며 그 결과는 Table 2에 제시되어 있다.
[SORT와의 비교 분석]
SORT도 객체의 움직임을 예측하기 위해 Kalman Filter를 채택한다. 결과를 확인해보면,
SORT에 비해서 BYTE는 MOTA (74.6 → 76.7), IDF1 (76.9 → 79.3)으로 개선, ID (291 → 159)로 감소.
이 결과가 의미하는 것 = Low Score Detection Box가 유의미하다는 것을 의미하며 BYTE가 low score에 대해서 recover하는 능력이 뛰어나다는 것을 증명한다.
[DeepSORT와의 비교 분석]
DeepSORT는 long-range association을 강화하기 위해 additional Re-ID 모델을 활용한다.
중요 DeepSORT와 비교했을 때에도, BYTE가 DeepSORT와 비교하여 추가적인 이점이 있다.
칼만 필터가 detection box가 정확할 때 long-range association을 수행하고 더 나은 IDF1과 ID를 달성할 수 있다.
심각한 Occlusion의 경우, Re-ID가 취약하고 모션 모델이 더 안정적으로 동작한다.
[Table 3]
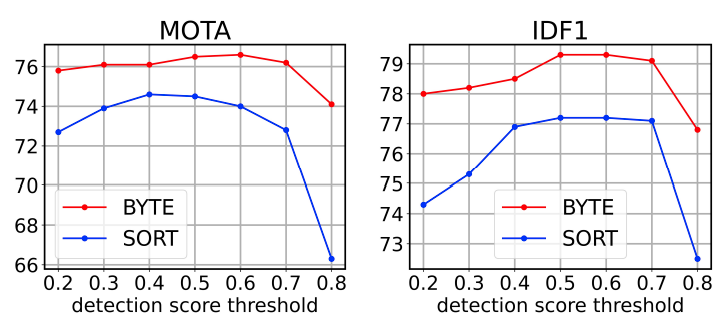
Figure 3. MOT 17에서 유효한 set이다.
BYTE와 SORT의 성능 비교이다. (detection score threshold가 다를 때)
구체적으로는 0.2에서 0.8로 detection score threshold를 바꿨을 때 SORT와 BYTE의 MOTA와 IDF1을 비교한다.
BYTE가 훨씬 Robust하다. → 변화의 폭이 더 낮다. (상하 폭 낮은 변화)
→threshold가 변화 할때마다 SORT는 지표들의 높낮이가 큼. BYTE는 다 살려주기때문에 높 → Association 잘되고있다는 뜻
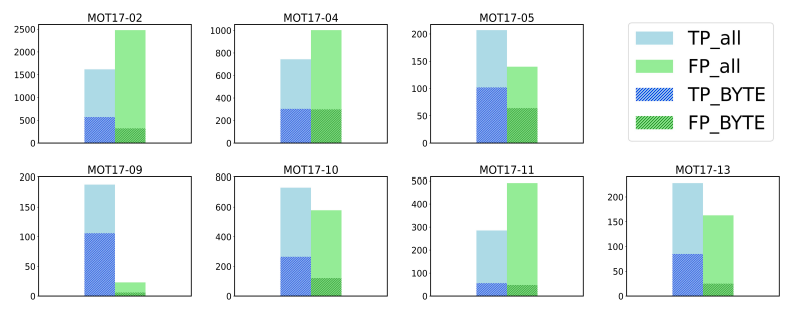
✅ **왜 Robust한지 구체적인 설명** BYTE 코드에서 Second Association에 의해서 T(high)보다 낮은 object를 recover하기 때문에 **결과적으로는 모든 detection box를 threshold를 변화에 관계 없이 고려할 수 있다.** **[Figure 4]** Figure 4. (MOT 17 validation set)
TP와 FP의 number를 비교한다.
→ 모든 low score detection box들에서도 비교를 하고 (큰 막대 그래프)
→ BYTE에서 얻어진 low score detection box들에 대해서도 비교를 한다.
이 결과에 대해서 Analysis를 진행하면…
MOT17-02는 TP_all < FP_all → 훨씬 높다. 그런데, TP_BYTE > FP_BYTE이다.
얻어진 TP는 Table 2에서 같이 MOTA를 74.6 → 76.6으로 현저하게 증가시킨다. (Table 2 돌아가서 다시 확인)
Conclusion
MOT에서 간단하고 효율적인 data association method인 BYTE에 대해 알아봄
그리고 BYTE를 사용한 strong tracker인 ByteTrack을 제시
- BYTE
- 이미 존재하는 다른 tracker에도 쉽게 적용되고 성능을 향상시킬 수 있음
- ByteTrack
- occlusion에 robust함
- low score detection box를 associating하는것을 도움
- MOT 결과를 향상시키기 위해 detection 결과를 최대한 활용하는 방법에 대해 설명
- 높은 정확도, 빠른 속소, 단순성
