10872_팩토리얼
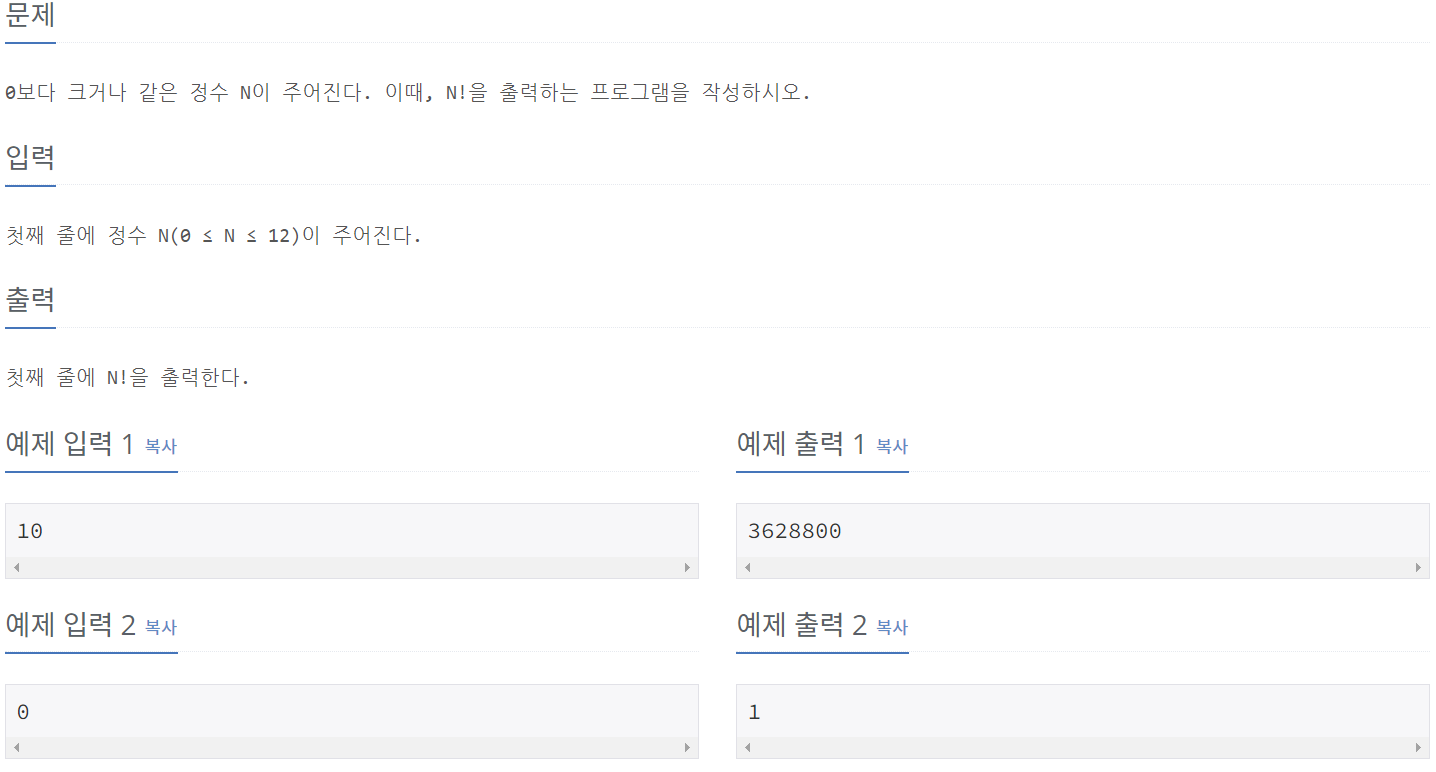
⭕풀이:
def factorial(a):
if(a > 1):
return a * factorial(a - 1)
else:
return 1
N = int(input())
print(factorial(N))⭕풀이설명
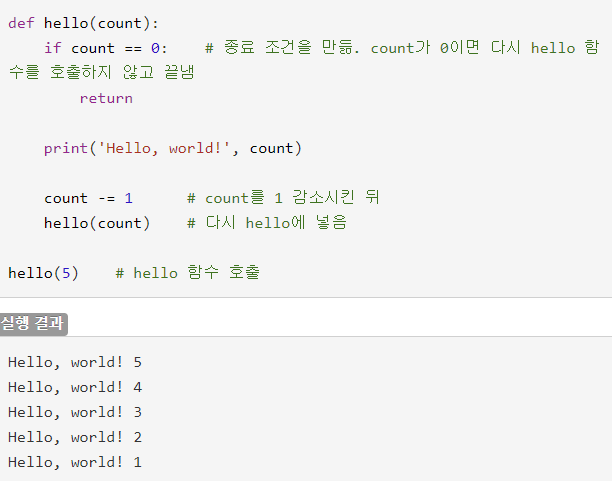
def를 통해 my_factorial(n) 함수를 정의하였습니다.
여기서 정의한 my_factorial이 재귀함수 입니다.해당 함수는 입력받은 파라미터 값이 1 보다 크면 = 입력받은수 * my_factorial(n -1) 을 리턴합니다.
글을 통해 도식적으로 표현해보겠습니다.
사용자의 입력이 5인 경우
my_factorial(5) 호출
5 > 1, 따라서 5 * my_factorial(4) 호출
4 > 1, 따라서 4 * my_factorial(3) 호출
3 > 1, 따라서 3 * my_factorial(2) 호출
2 > 1, 따라서 2 * my_factorial(1) 호출
1 > 1는 거짓 따라서 1을 리턴함
★ 여기서 부터 다시 거꾸로 간다고 생각하시면 됩니다.
my_factorial(1) = 1을 리턴하였습니다.
2 > 1, 따라서 2 my_factorial(1) 호출이었는데, my_factorial(1) >= 1 이기때>문에 결국 2 1 리턴
my_factorial(2) = 2를 리턴하였습니다.
3 > 1, 따라서 3 my_factorial(2) 호출이었는데, my_factorial(2) = 2 이기때>문에 결국 3 2 리턴
my_factorial(3) = 6을 리턴하였습니다.
4 > 1, 따라서 4 my_factorial(3) 호출이었는데, my_factorial(3) = 6 이기때>문에 결국 4 6 리턴
my_factorial(4) = 24을 리턴하였습니다.
5 > 1, 따라서 5 my_factorial(4) 호출이었는데, my_factorial(4) = 24 이기>때문에 결국 5 24 리턴
my_factorial(5) = 5 * 24 = 120을 리턴하였습니다.
출처
📌필요지식
1) 재귀함수
- 함수 자기 자신을 호출하는 함수를 말합니다. 일반적인 상황에서는 잘 사용하지 않지만 알고리즘을 구현할 때, 매우 유용합니다. 보통 알고리즘에 따라서 반복문으로 구현한 코드보다 재귀함수를 이용한 코드가 좀 더 직관적이고 이해하기 쉬운 경우가 많습니다.
1-1) 사용방법
-
예약어인 def(=definition)를 이용해 함수를 생성합니다.
결과값으로 return하게 될 변수 이름을 rewult로 지정하고서 1을 선언했습니다. 아래 if조건문에서 n이 0보다 큰 경우로 제한했기 때문에 입력받는 수 n이 0인 경우에는 result값이 그대로 1으로 출력합니다. -
입력받는 수 n이 0보다 큰 경우에는 팩토리얼이 가진 n! = n*(n-1)!의 성질을 이용해 함수 자기 자신을 불러내서 코드를 작성했습니다. 이렇게 계산된 값은 result변수에 선언해 마지막에 result값을 return합니다.

-
재귀함수를 사용하려면 반드시 종료 조건을 만들어주어야 합니다.
10870_피보나치 수 5
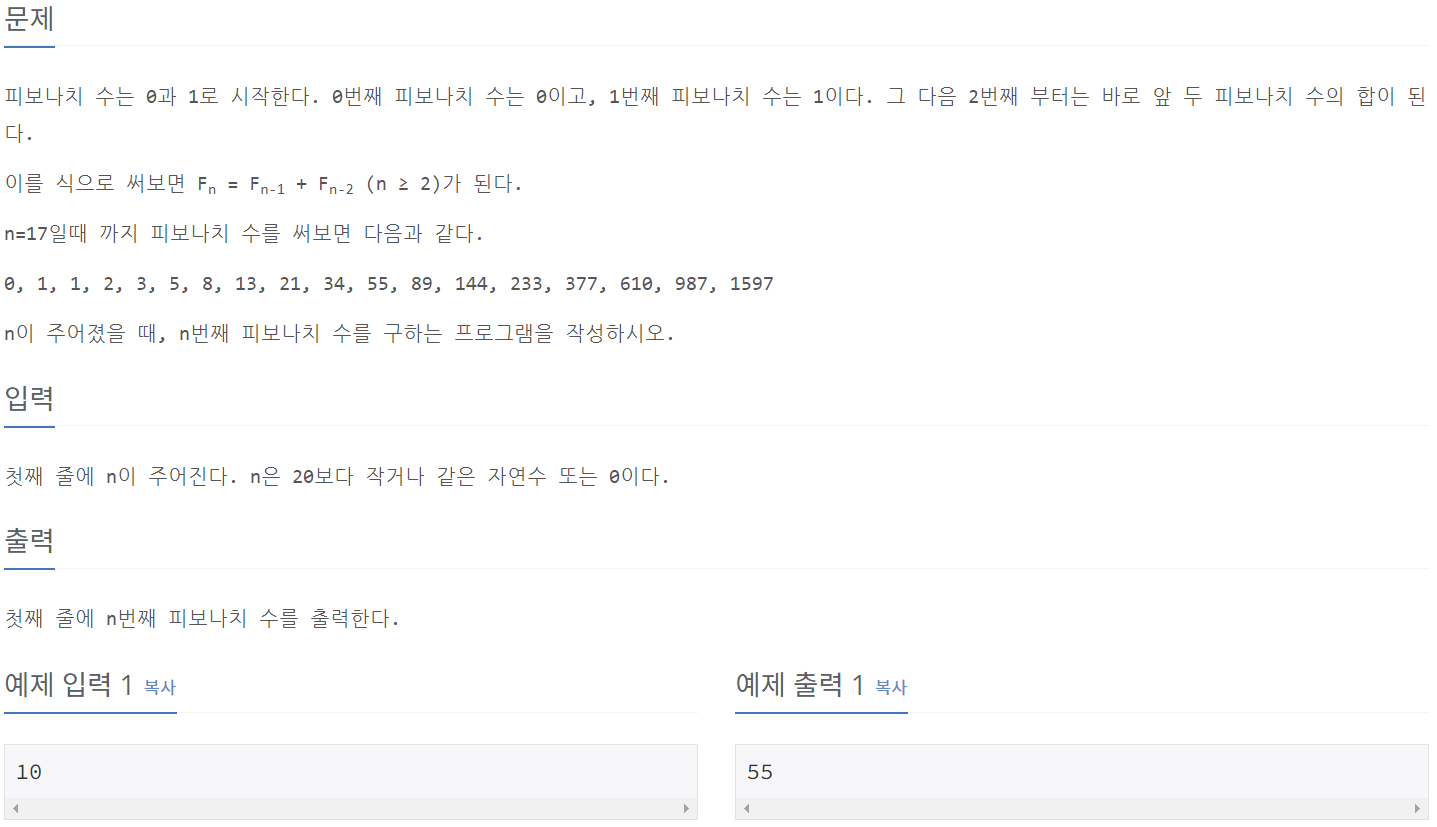
⭕풀이:
def fibonacci(a):
if a <= 1: #a가 1보다 작거나 크면,
return a #finonacci(a) = a 이다. 이유는 이 함수(fibonacci함수)의 return은 fibonacci(a-1) + (a-2)이기 때문에 a가 2보다 같거나 커야 하기 때문입니다.
return fibonacci(a-1) + fibonacci(a-2)
a = int(input())
print(fibonacci(a))25501_재귀의 귀재


⭕풀이:
import sys
input = sys.stdin.readline
def recursion(s, l, r): #isPalindrome(s, 0, len(s)-1)의 값을 recursion(s, l, r)로 가져와 recursion함수를 돌린다.
global cnt # 함수 내에서 전역 변수로 cnt를 활용하기 위해 global로 명시해준다.
cnt += 1 # isPalindrome 함수를 이용해 주어진 입력값인 문자열이 팰린드롬인지 여부를 판단하려고 한다. 또, 판별하는 과정에서 recursion함수를 몇 번 호출하는지 셀 것이다.
if l >= r: #r이 0보다 작거나 같다면,(=해당 문자열이 한 글자이거나 한 글자도 없다면, 해당 문자열의 길이에서 1을 뺀 값이 0보다 작거나 같다는 건 해당 문자열이 한 글자이거나 없다는 것과 같음.)
return 1 #def recurison(해당문자열) = 1이다.
elif s[l] != s[r]: #그렇지 않고, 문자열의 l번째 값(=문자열의 첫번째 값)이 문자열의 r번째 같(=문자열의 마지막 값)과 같지 않다면,
return 0 #def recurison(해당문자열) = 0이다.(=해당 문자열은 팰린드롬이 아니다.)
else: #그렇지 않고, 문자열의 l번째 값과 문자열의 r번째 값이 같다면,(=문자열의 첫 번째 글자와 마지막 글자가 같다면,)
return recursion(s, l + 1, r - 1) #def recurison(해당문자열, 0, len(해당문자열)-1) = recursion(해당문자열, 1, len(해당문자열)-1-1)을 통해 해당문자열의 2번째 글자와 뒤에서 2번째 글자를 비교하는 def recursion()함수를 실행하게 된다. 해당문자열이 팰린드롬이라면 끝에는 if l >= r:문을 통해 더 이상 비교할 글자가 없다면, def recursion(해당문자열) = 1로 return될 것이다.
def isPalindrome(s):
return recursion(s, 0, len(s)-1) #주어진 입력값을 recursion함수에 대입해 팰린드롬인지 판별하기 위해 입력값을 다음과 같은 형태(s, 0, len(s)-1)로 바꿔준다.
for _ in range(int(input())): #주어진 입력값만큼 다음을 반복해라.
cnt = 0 #카운트하기 위한 변수로 비어있는 숫자 cnt를 변수선언한다.
print(isPalindrome(input().rstrip()), cnt) #오른쪽 공백을 제거한 해당문자열이 isPalindrome()함수를 팰린드롬인지(1 or 0인지) 판별해 출력하고, recursion함수를 몇번 반복했는지 출력해라.
📌필요지식
1) global과 전역객체
- 프로그래밍 언어에서 변수를 분류하는 방법은 여러가지가 있습니다. 그 중에 하나로 전역변수와 지역변수의 개념이 있습니다.
일반적으로 전역변수는 프로그램에 혼란을 주기 때문에 사용을 권장하지 않습니다. 하지만, 알고리즘에선 전역변수를 사용하면 효율적으로 코딩할 수 있습니다.
1-1) global 사용방법
- 우선 전역변수를 사용하기 위해서는 함수가 필요합니다. 함수 안의 변수들은 지역변수로 함수영역 밖에서 호출해 사용할 수 없습니다.
아래 예에서는 a변수를 사용할 수 없습니다.

1-1-1) 함수 안에서 global로 전역변수 선언하기
- 함수에 사용된 a는 지역변수이기 때문에, 함수 밖의 영역에서는 호출해 사용할 수 없습니다. 사용을 하기 위해서는 아래와 같이 a를 전역변수로 선언해야 합니다.

1-1-2) 함수 밖에서 global로 전역변수 선언하기
- 함수 밖에서 global로 전역변수 선언을 했어도, 함수 안에서 전역변수 사용을 다시 한 번 명시해 주어야 합니다. 그렇지 않으면, 해당 변수는 지역변수로 처리됩니다.
아래 예에서 global a를 삭제하면 a = 1이 됩니다.

=> 결론은 함수 안이나 밖에서 전역변수를 선언하는 것보다 함수 안에서 전역변수 사용을 명시해 주는 것이 중요합니다.
24060_알고리즘 수업 - 병합정렬1

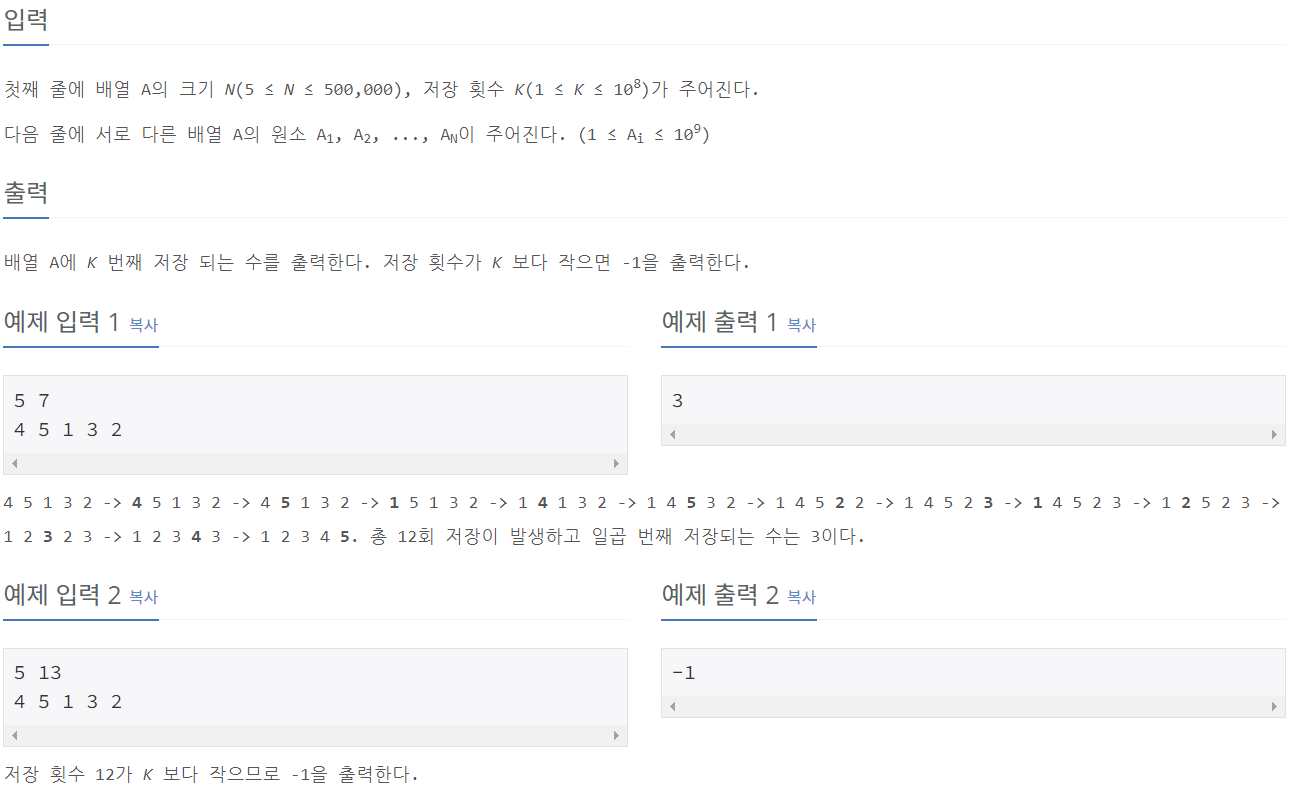
⭕풀이:
import sys
input = sys.stdin.readline
def merge_sort(L):
if len(L) == 1: #L의 길이가 1이 될 때까지 반복해라
return L
mid = (len(L) + 1) // 2
left = merge_sort(L[:mid])
right = merge_sort(L[mid:])
i, j = 0, 0
L2 = []
while i < len(left) and j < len(right):
if left[i] < right[j]:
L2.append(left[i])
ans.append(left[i])
i += 1
else:
L2.append(right[j])
ans.append(right[j])
j += 1
while i < len(left):
L2.append(left[i])
ans.append(left[i])
i += 1
while j < len(right):
L2.append(right[j])
ans.append(right[j])
j += 1
return L2
n, k = map(int, input().split())
a = list(map(int, input().split()))
ans = []
merge_sort(a)
if len(ans) >= k:
print(ans[k - 1])
else:
print(-1)⭕풀이설명
순서대로 해보자
1번째 반복
L = [5,4,1,3,2]일 때,
L의 길이는 1이 아니므로, merge_sort(L) = L이 아니다.
mid = 3이고,
left = merge_sort([5,4,1])
right = merge_sort([2,3])
-> 1번째 반복과 while문을 보았을 때, left와 right의 정확한 값을 알아야만 while문을 진행할 수가 있다.
그러므로 2번째 반복은 left와 right의 값을 구하기 위함이다.
--------------------------------------------------------------------------------------
2번째 반복
left = merge_sort([5,4,1])
right = merge_sort([2,3]) 이므로,
merge_sort([5,4,1])과 merge_sort([2,3])을 구하면 된다.
우선 merge_sort([5,4,1])은
길이가 1이 아니므로, merge_sort([5,4,1]) = [5,4,1]이 아니다.
mid = 2이고,
left = merge_sort([5,4])
right = [1]이다.
-> 2번째 반복에서도 merge_sort([5,4,1])의 left값을 정확히 알 수 없어 merge_sort([5,4,1])를 구할 수 없다.
그러므로 3번째 반복은 merge_sort([5,4])을 구하기 위함이다.
--------------------------------------------------------------------------------------
3번째 반복
left = merge_sort([5,4])
right = 1 이므로,
merge_sort([5,4])를 구하면 된다.
우선 merge_sort([5,4])는
길이가 1이 아니므로, merge([5,4]) = [5,4]가 아니다.
mid = 1이고,
left = [5]
right = [4]이다.
-> 3번째 반복에서 merge([5,4])의 left와 right값을 모두 알 수 있어 아래 while문을 실행할 수 있다.
i, j =0, 0을 통해 두 그룹, left와 right의 요소값들을 순차적으로 하나씩 넣기 위해 변수선언했다.
L2는 비어 있는 리스트로 merge_sort([5,4])의 return값을 구하기 위해 변수 선언했다.
3-1번째 while문
-> left와 right의 길이(1)가 i, j(0, 0)보다 크므로, 첫 번째 while문을 반복한다.
left의 첫 번째 값이 right보다 크기 때문에 else를 실행한다.
L2 = [4]
ans = [4]
j = 1이 됐다.
-> left의 길이가 i(0)보다 크지만, right의 길이가 j(1)의 값보다 크지 않으므로, 1번째 while문은 종료된다.
3-2번째 while문
-> left의 길이가 0보다 크기 때문에 2번째 while문을 실행한다.
L2 = [5]
ans = [5]
i = 1이 됐다.
-> right의 길이가 j(1)의 값보다 크지 않으므로, 3번째 while문은 실행하지 않고, L2(=[4,5])를 return해
merge_sort([5,4])의 값은 [4,5]이다.
-> merge_sort([5,4])의 값을 알게 됐으니 merge_sort([5,4,1])를 구할 수 있게 된다.
-> 그러므로 4번째 반복은 merge_sort([5,4])의 값을 알게 됐으니 merge_sort([5,4,1])를 구하기 위함이다.
--------------------------------------------------------------------------------------
4번째 반복
left = merge_sort([5,4]) = [4,5]
right = [1] 이다.
-> left, right 모두 정확한 값을 알고 있으므로, while문을 실행할 수 있다.
i, j = 0, 0
L2 = [ ] 로 다시 변수 선언된다.
-> left와 right의 길이(2, 1)가 i, j(0, 0)보다 크므로, 첫 번째 while문을 반복한다.
left의 첫 번째 값이 right의 첫 번째 값보다 크기 때문에 else를 실행한다.
L2 = [1]
ans = [1]
j = 1이 됐다.
-> left의 길이(2)가 i(0)보다 크지만, right의 길이가 j(1)의 값보다 크지 않으므로, 1번째 while문은 종료된다.
-> left의 길이(2)가 i(0)보다 크기 때문에 2번째 while문을 실행한다.
3-2번째 while문
L2 = [1,4]
ans = [1,4]
i = 1이 됐다.
-> 여전히, left의 길이(2)가 i(1)보다 크기 때문에 2번째 while문을 한 번 더 실행한다.
3-2번째 while문 2번째 반복
L2 = [1,4,5]
ans = [1,4,5]
i = 2가 됐다.
-> left의 길이가 i(2)의 값보다 크지 않으므로, 2번째 while문을 종료하고,
right의 길이(1)가 j(1)보다 크지않으므로, 3번째 while문을 실행하지 않고, L2(=[1,4,5])를 return해
merge_sort([5,4,1])의 값은 [1,4,5]이다.
-> merge_sort([5,4,1])의 값을 알게 됐으니 merge_sort(L)의 left값, [1,4,5]을 구하게 됐다.
-> 그러므로 5번째 반복은 merge_sort([5,4,1])의 값을 알게 됐으니 merge_sort(L)의 right값인 merge_sort([3,2])를 구하기 위함이다.
--------------------------------------------------------------------------------------
5번째 반복
left =[3]
right = [2] 이다.
-> left, right 모두 정확한 값을 알고 있으므로, while문을 실행할 수 있다.
i, j = 0, 0
L2 = [ ] 로 다시 변수 선언된다.
-> left와 right의 길이(1, 1)가 i, j(0, 0)보다 크므로, 첫 번째 while문을 반복한다.
left의 첫 번째 값이 right의 첫 번째 값보다 크기 때문에 else를 실행한다.
5-1번째 while문
L2 = [2]
ans = [2]
j = 1이 됐다.
-> left의 길이(1)가 i(0)보다 크지만, right의 길이(1)가 j(1)의 값보다 크지 않으므로, 1번째 while문은 종료된다.
-> left의 길이(1)가 i(0)보다 크기 때문에 2번째 while문을 실행한다.
5-2번째 while문
L2 = [2,3]
ans = [2,3]
i = 1이 됐다.
-> left의 길이(1)가 i(1)의 값보다 크지 않으므로, 2번째 while문을 종료하고,
right의 길이(1)가 j(1)보다 크지않으므로, 3번째 while문을 실행하지 않고, L2(=[2,3])를 return해
merge_sort([3,2])의 값은 [2,3]이다.
-> merge_sort([3,2]) = merge(L)의 right값, [2,3]을 알게 됐으니 merge_sort(L)의 값을 6번째 반복은 merge_sort(L)를 구하기 위함이다.
--------------------------------------------------------------------------------------
6번째 반복
left = merge_sort([5,4,1]) = [1,4,5]
right = merge_sort([3,2]) = [3,2] 이다.
-> left, right 모두 정확한 값을 알고 있으므로, while문을 실행할 수 있다.
i, j = 0, 0
L2 = [ ] 로 다시 변수 선언된다.
-> left와 right의 길이(3, 2)가 i, j(0, 0)보다 크므로, 첫 번째 while문을 반복한다.
6-1번째 while문
L2 = [1]
ans = [1]
i = 1이 됐다.
-> 여전히 left와 right의 길이(3, 2)가 i, j(1, 0)보다 크므로, 첫 번째 while문을 반복한다.
6-1번째 while문
L2 = [1,2]
ans = [1,2]
j = 1이 됐다.
-> 여전히 left와 right의 길이(3, 2)가 i, j(1, 1)보다 크므로, 첫 번째 while문을 반복한다.
6-1번째 while문
L2 = [1,2,3]
ans = [1,2,3]
j = 2가 됐다.
-> left의 길이(3)가 i(1)보다 크지만, right의 길이(2)가 j(2)의 값보다 크지 않으므로, 1번째 while문은 종료된다.
-> left의 길이(3)가 i(1)보다 크기 때문에 2번째 while문을 실행한다.
6-2번째 while문
L2 = [1,2,3,4]
ans = [1,2,3,4]
i = 3이 됐다.
-> 여전히, left의 길이(3)가 i(2)보다 크기 때문에 2번째 while문을 실행한다.
6-2번째 while문
L2 = [1,2,3,4,5]
ans = [1,2,3,4,5]
i = 3이 됐다.
-> left의 길이(3)가 i(3)의 값보다 크지 않으므로, 2번째 while문을 종료하고,
right의 길이(2)가 j(2)보다 크지않으므로, 3번째 while문을 실행하지 않고, L2(=[1,2,3,4,5])를 return해
merge_sort([L])의 값은 [1,2,3,4,5]이다. ❌시행착오 1:
def merge_sort(list):
n = len(list) #n은 list의 길이값이다.
if n <= 1: #list의 요소값이 하나거나 없다면,
return list #list를 그대로 return한다.
mid = (n + 1) // 2 #mid는 중간값이다. -> 중간을 기준으로 두 그룹으로 나눔
g1 = merge_sort(list[:mid]) # 재귀 호출로 첫 번째 그룹을 정렬 처음 부터 mid 까지
g2 = merge_sort(list[mid:]) # 재귀 호출로 두 번째 그룹을 정렬 mid + 1 부터 끝까지
result, i, j = [], 0, 0 #result는 리스트이고, 첫 번째 그룹과 두 번째 그룹을 하나씩 result에 넣고, i와 j를 카운트로 쓰기 위해 변수선언한다.
while i < len(g1) and j < len(g2): #처음 반복일때, g1의 길이가 0보다 크고, g2의 길이가 0보다 클 때, 아래를 무한 반복해라.
if g1[i] < g2[j]: #g1의 첫 번째값(i 번째 값)이 g2의 첫 번째값(j 번째 값)보다 작다면,
result.append(g1[i]) #g1의 첫 번째 값(i 번째 값)을 result에 넣어라.
res.append(g1[i]) #g1의 첫 번째 값(i 번째 값)을 res에 넣어라.
i += 1 #그리고 i에 1을 더해라.
else: #그렇지 않고, g1의 i 번째 값이 g2의 j 번째 값보다 크다면(중복이 없기에 같은 경우는 없음),(=g1의 요소값들이 작아서 하나씩 result와 res에 넣다가, result와 res 리스트가 오름차순이 되야하기 때문에 g1의 i번째 값이 g2보다 크다면 작은 g2의 값이 먼저 result와 res에 들어가야 한다.)
result.append(g2[j]) #g2의 첫 번째 값(j 번째 값)을 result에 넣어라.
res.append(g2[j]) #g2의 첫 번째 값(j 번째 값)을 result에 넣어라.
j += 1 #그리고 j에 1을 더해라.
result.extend(g1[i:])
result.extend(g2[j:])
res.extend(g1[i:])
res.extend(g2[j:])
return result
N, M = map(int, input().split())
arr = list(map(int, input().split()))
res = []
merge_sort(arr)
print(res[M - 1]) if len(res) >= M else print(-1)❌시행착오 2:
import sys
input = sys.stdin.readline
def merge_sort(L):
if len(L) == 1: #주어진 값, L리스트에 있는 요소값이 하나 뿐이라면,
return L #그대로 리스트를 return한다.
mid = (len(L) + 1) // 2 #mid는 L리스트의 중앙값이다.(=L리스트 길이에 1을 더한 값을 2로 나눈 값의 정수부분이다.)
left = merge_sort(L[:mid]) #left는 L의 0번째 ~ 중앙값까지 포함한 리스트를 merge_sort함수로 return한 값이다.
right = merge_sort(L[mid:]) #right는 L의 중앙값 + 1번째 ~ 마지막값까지 포함한 리스트를 merge_sort함수로 return한 값이다.
i, j = 0, 0
L2 = []
while i < len(left) and j < len(right): #left가 merge_sort함수를 처음 돌릴 때, left의 길이와 right의 길이가 0보다 크면 아래를 무한 반복해라.
if left[i] < right[j]: #left의 첫 번째 값이 right의 첫 번째값보다 작으면,
L2.append(left[i]) #L2 리스트에 left의 첫 번째 값을 넣어라.
ans.append(left[i]) #ans 리스트에 left의 첫 번째 값을 넣어라.
i += 1 #그리고, i에 1을 더해라.
else: #그렇지 않고, right의 첫 번째값이 크거나 같다면,
L2.append(right[j]) #L2 리스트에 right의 첫 번째값을 넣어라.
ans.append(right[j]) #ans 리스트에 right의 첫 번째값을 넣어라.
j += 1 #그리고, j에 1을 더해라.
while i < len(left): #left의 길이만 0보다 크다면,
L2.append(left[i]) #L2 리스트에 left의 첫 번째값을 넣어라.
ans.append(left[i]) #ans 리스트에 right의 첫 번째값을 넣어라.
i += 1 #그리고, j에 1을 더해라.
while j < len(right): #right의 길이만 0보다 크다면,
L2.append(right[j]) #L2 리스트에 right의 첫 번째값을 넣어라.
ans.append(right[j]) #ans 리스트에 right의 첫 번째값을 넣어라.
j += 1 #그리고, j에 1을 더해라
return L2
n, k = map(int, input().split())
a = list(map(int, input().split()))
ans = []
merge_sort(a)
if len(ans) >= k:
print(ans[k - 1])
else:
print(-1)📌필요지식
1) 병합정렬
- 병합 정렬은 분할 정복 (Devide and Conquer) 기법과 재귀 알고리즘을 이용해서 정렬 알고리즘입니다. 즉, 주어진 배열을 원소가 하나 밖에 남지 않을 때까지 계속 둘로 쪼갠 후에 다시 크기 순으로 재배열 하면서 원래 크기의 배열로 합칩니다.
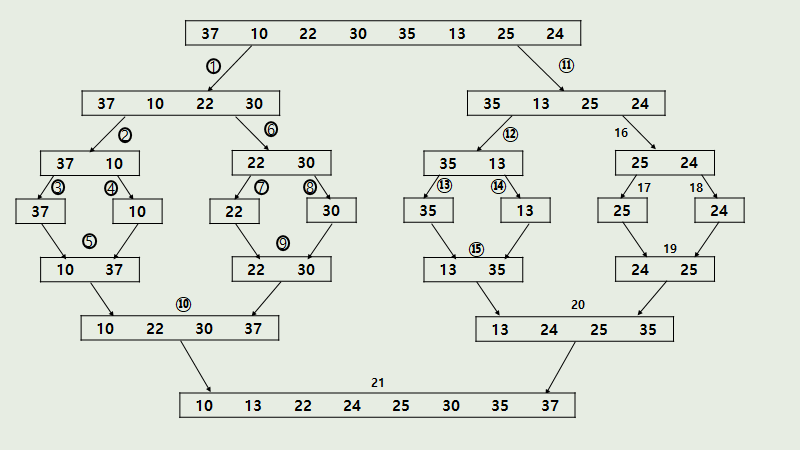
❗느낀 점
이번 문제는 이제껏 풀었던 문제 중 가자 오랜 시간, 4시간에 걸쳐 풀었던(=헤맸던) 문제였습니다. 처음에 left와 right의 값을 정확히 한 번에 구하려고, 머릿속으로 굉장히 되풀이했었는데, 이번 문제 역시 재귀함수의 사용으로 차근차근 모르는 답들에 대해 펼쳐놓고, 주어진 함수를 반복했다면 난이도 자체는 어렵지 않았던 문제였던 것 같습니다. 물론 지금에 와서 복기하는 것이기 때문에 그렇겠지만..
이번 문제는 문제 자체(=병합정렬)도 이해가 되지 않아 유튜브와 구글을 통해 개념을 익혔고, 애매했던 개념들(while문 사용방법, while문 안에서 if문, return의 정확한 뜻과 역할등)에 대해 좀 더 자세하게 알 수 있게 된 레퍼런스가 될 것 같습니다.
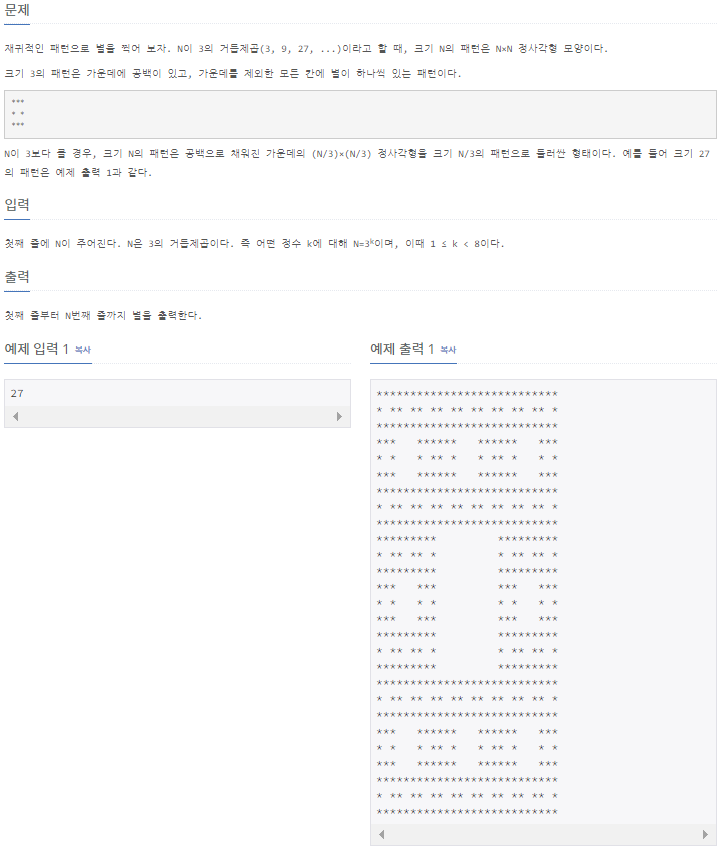
2447_ 별 찍기 10
⭕풀이:
def draw_stars(n):
if n == 1:
return ['*']
Stars = draw_stars(n // 3)
L = []
for star in Stars:
L.append(star * 3)
for star in Stars:
L.append(star + ' ' * (n // 3) + star)
for star in Stars:
L.append(star * 3)
return L
N = int(input())
print('\n'.join(draw_stars(N)))📌필요지식
1) join
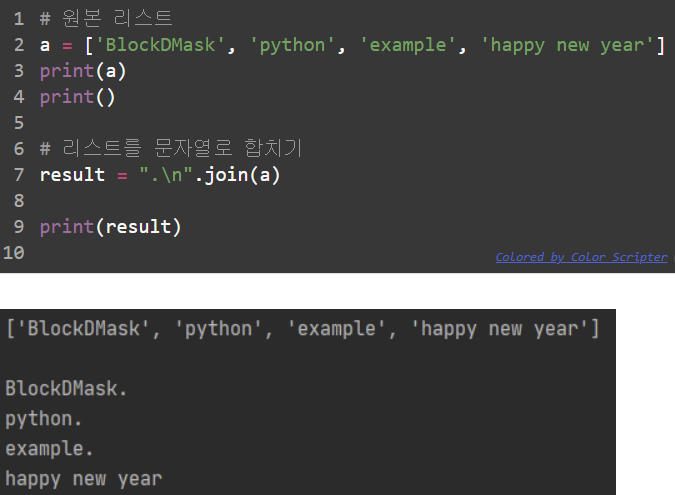
join함수는 매개변수로 들어온 리스트에 있는 요소값들 하나하나를 합쳐서 하나의 문자열로 바꾸어 반환하는 함수입니다.
1-2) ''.join(리스트)
.join(리스트)를 이용하면 매개변수로 들어온 ['a', 'b', 'c'] 이런 식의 리스트를 ['abc']의 문자열로 합쳐서 반환해 주는 함수입니다.
1-3) '구분자'.join(리스트)
'구분자'.join(리스트)를 이용하면 리스트의 값과 값 사이에 '구분자'에 들어온 구분자를 넣어서 하나의 문자열로 합쳐서 반환해 줍니다.
'_'.join(['a', 'b', 'c'])라 하면 'a_b_c'와 같은 형태로 문자열을 만들어서 반환해 줍니다.
1-4) '\n'.join(리스트)
-'\n'.join을 통해 하나씩 출력하기
11729_하노이 탑 이동 순서

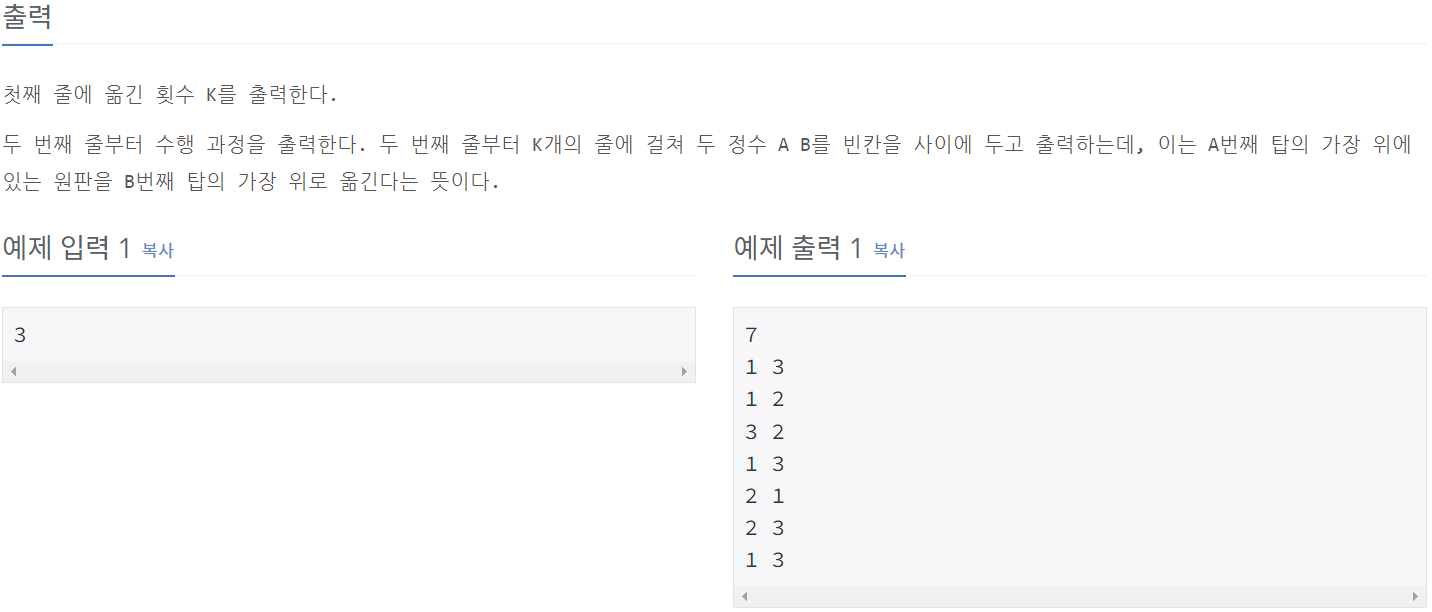
⭕풀이:
def hanoi_tower(n, start, end):
if n == 1:
print(start, end)
return
hanoi_tower(n - 1, start, 6 - start - end) # 1단계
print(start, end) # 2단계
hanoi_tower(n - 1, 6 - start - end, end) # 3단계
n = int(input())
print(2 ** n - 1)
print(hanoi_tower(n, 1, 3))⭕풀이설명
https://study-all-night.tistory.com/6
❗느낀 점
단계를 하나씩 풀 때마다 새로운 접근이 필요해 처음부터 쉽다고 느껴지진 않았지만, 기본수학 1 단계부터 문제를 파악하고, 숫자로 표현할 수 있는 공식이 필요하다는 것을 알았고, 이번 재귀 단계에서는 병합정렬이라는 개념을 통해 이론학습도 필요하다는 것을 깨달았습니다.
