
보안사항
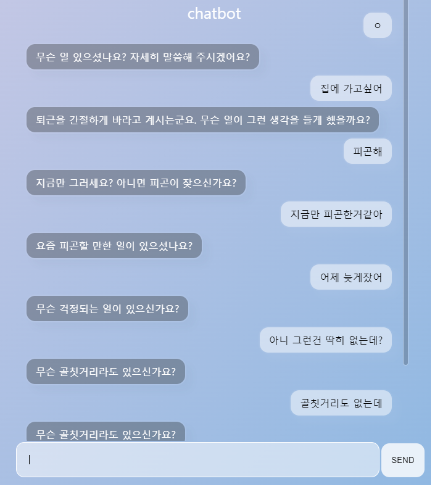
물음표살인마 같은 답변만 내놓는 챗봇이어서 수정해야겠다는 생각이 들었다.
생각해보니 데이터셋에서 사람/시스템 문장의 각 첫번째 대화만 사용해서 제작했었음.
데이터셋을 다시 보니 사람/시스템 문장이 3턴으로 이루어지고 각각 역할이 있는 거였다.
(감정 표출, 진전된 대화 / 응답, 진전된 대화, 마무리 같은 식으로)
대화를 이어나가기 위한 1번째 응답만 학습시킨 셈이어서, 모든 답변이 질문으로 돌아오는 거였음.
→ 모든 턴의 대화를 다시 임베딩시켜서 데이터 파일에 넣어줬다. 좀 더 매끄러운 대화가 이루어지게 됨.
결과
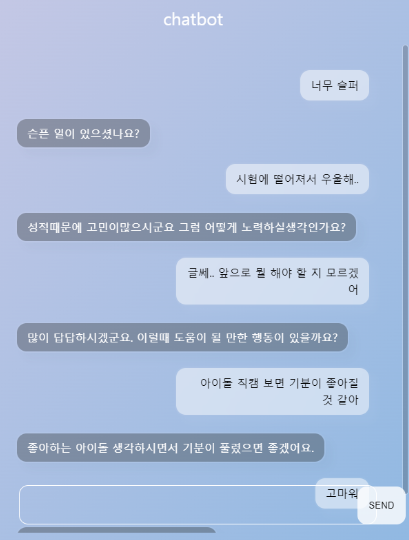
감정에 대한 대화는 좀 괜찮게 이어지는 모습을 보임.
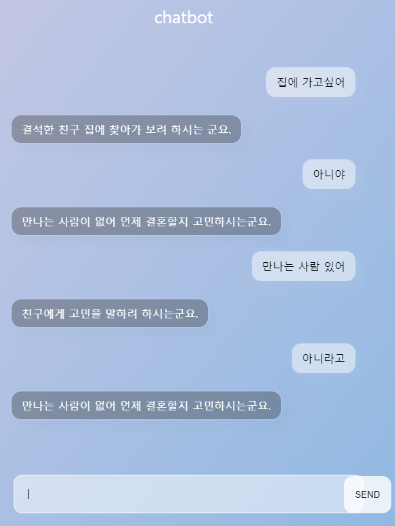
일상대화는 전혀 이어지지 않음.
→ 넣어준 데이터가 감정에 대한 대화만으로 이루어져서라고 추측.
결론
기본 모델에 직접 추가 학습을 시켜서 만든 모델을 사용했다면 좋았겠지만 시간 문제로 이미 학습되어진 SBERT 모델을 활용한 점이 아쉽게 느껴진다. STS학습까지는 시켰지만 그리 높지 않은 성능을 보였음.
또한 이번 프로젝트에서는 주어진 데이터셋의 답변 값을 기반으로 응답을 하는 챗봇을 구현했지만, 페르소나를 가진 챗봇 모델을 구축할 수 있다면 더욱 사람과 대화하는 느낌을 받을 수 있을 것 같다.
발표자료 구성
프로젝트 개요
데이터 소개
의도분류모델 실패 (CNN, RNN, LSTM)
BERT 모델 소개
모델 학습시키는 방법 설명
but 나는 이미 학습되어있는 모델로 사용했다.
챗봇 페이지 제작 과정(파이참)
결과물
결론&느낀점
