1. Persistence Framework
1-1. JDBC
- JDBC는 DB에 접근할 수 있도록 Java에서 제공하는 API
- 모든 Java의 Data Access 기술의 근간
- 모든 Persistence Framework는 내부적으로 JDBC API를 이용
- JDBC는 데이터베이스에서 자료를 쿼리하거나 업데이트하는 방법을 제공
1-2. SQL Mapper와 ORM
- ORM : 데이터베이스 객체를 자바 객체로 매핑함으로써 객체 간의 관계를 바탕으로 SQL을 자동으로 생성
- SQL Mapper : SQL을 명시해줘야 함
- ORM : 관계형 데이터베이스의 '관계'를 Object에 반영하자는 것이 목적
- SQL Mapper : 단순히 필드를 매핑시키는 것이 목적
1-3. SQL Mapper
- SQL <— 매핑 —> Object 필드
- SQL Mapper는 SQL 문장으로 직접 데이터베이스 데이터를 다룸
- Ex) Mybatis, JdbcTempletes 등
1-3-1. Mybatis
- JDBC로 처리하는 상당 부분의 코드와 파라미터 설정 및 결과 매핑을 대신해줌
- 데이터베이스 record에 원시 타입과 Map 인터페이스, 자바 POJO를 설정해서 매핑하기 위해 xml과 Annotation 사용 가능
- SQL에 대한 모든 컨트롤을 하고자 할때 매우 적합
- SQL 쿼리들이 매우 잘 최적화되어 있을 때에 유용
- 애플리케이션과 데이터베이스 간의 설계에 대한 모든 조작을 하고자 할 때는 적합하지 않음
1-4. ORM(Object-Relational Mapping)
- 데이터베이스 데이터 <— 매핑 —> Object 필드
- ORM(Object-relational mapping) : 객체는 객체대로 설계하고, 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- 객체를 통해 간접적으로 데이터베이스 데이터를 다룸
- 객체와 관계형 데이터베이스의 데이터를 자동으로 매핑해주는 것
- ORM을 이용하면 SQL Query가 아닌 직관적인 코드(메서드)로 데이터를 조작할 수 있음
- 객체 간 관계를 바탕으로 SQL 자동 생성
- Persistant API 라고도 함
- Ex) Hibernate, JPA 등
1-4-1. JPA
- Java Persistence API
- 자바 ORM 기술에 대한 API 표준 명세로, Java에서 제공하는 API
- ORM을 사용하기 위한 표준 인터페이스를 모아둔 것
- JPA 2.1 표준 명세를 구현한 구현체(= ORM Framework) : Hibernate, EclipseLink, DataNucleus, OpenJPA, TopLink Essentials 등
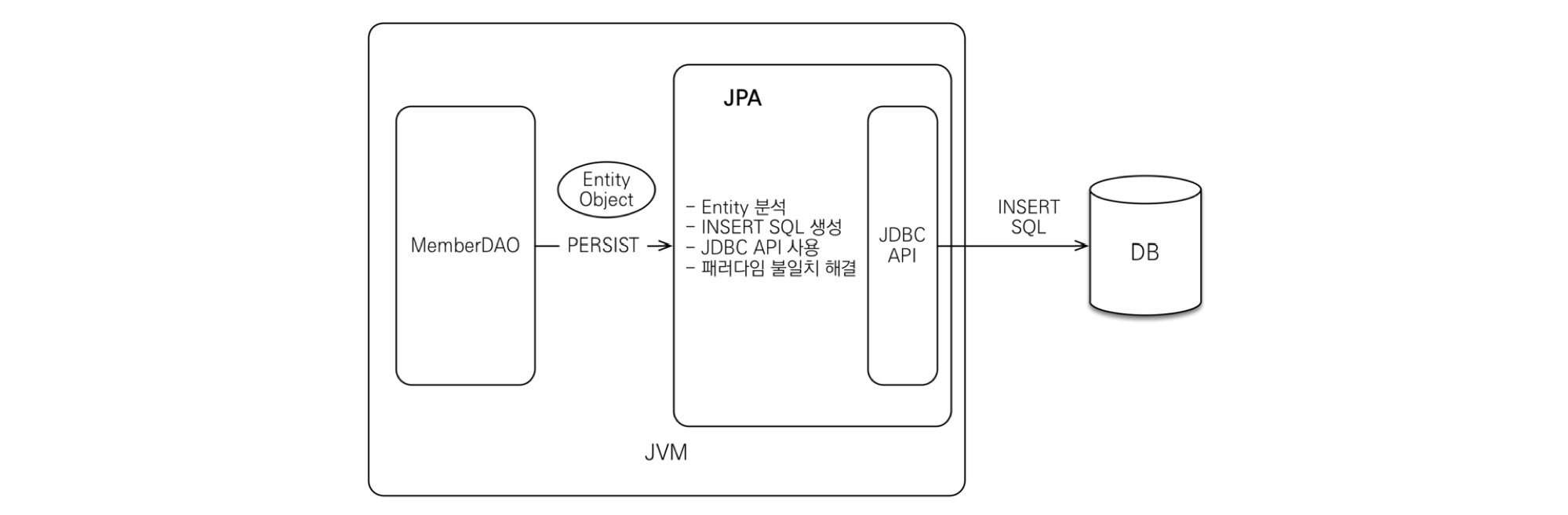
- JPA는 애플리케이션과 JDBC 사이에서 동작
- 개발자가 JPA를 사용하면, JPA 내부에서 JDBC API를 사용하여 SQL을 호출하여 DB와 통신
- 참고 https://gmlwjd9405.github.io/2019/08/04/what-is-jpa.html
2. JPA
2-1. JPA 구성 요소
- javax.persistance 패키지로 정의된 API 그 자체
- JPQL(Java Persistence Query Language)
- 객체/관계 메타데이터
2-2. JPA 장점
- SQL 중심적인 개발에서 객체 중심으로 개발
- 간단한 CRUD (객체를 변경하면 알아서 DB UPDATE Query가 실행됨)
- 객체 그래프를 완전히 자유롭게 탐색할 수 있음
- 지연 로딩 전략(Lazy Loading) 사용(관련된 객체를 사용하는 그 시점에 SELECT Query를 날려서 객체를 가져오는 전략)
- 동일한 트랜잭션에서 조회한 엔티티는 같음을 보장 (결과적으로, SQL을 한 번만 실행)
String memberId = "100";
Member member1 = jpa.find(Member.class, memberId);
Member member2 = jpa.find(Member.class, memberId);
member1 == member2;
- 트랜잭션을 지원하는 쓰기 지연(transactional write-behind) -> 버퍼링 기능
- [트랜잭션]을 commit 할 때까지 INSERT, UPDATE, DELETE SQL을 메모리에 쌓는다
transaction.begin();
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
transaction.commit();
transaction.begin();
changeMember(memberA);
deleteMember(memberA);
DO_BUSINESS_LOGIC_PROCESS();
transaction.commit();
2-2-1. 지연 로딩(Lazy Loading)
Member member = memberDAO.find(memberId);
Team team = member.getTeam();
String teamName = team.getName();
- memberDAO.find(memberId) : Member 객체에 대한 SELECT 쿼리 실행
- member.getTeam() 객체를 가져온 후, team.getName() 로 실제 객체를 건드리는 시점에 Team 객체에 대한 SELECT 쿼리 실행
- Member와 Team 객체 각각 따로 조회하기 때문에 네트워크를 2번 타게 됨
2-2-2. 즉시 로딩
- JOIN SQL로 한 번에 연관된 객체까지 미리 조회하는 전략
- 항상 연관된 모든 객체를 같이 가져옴
2-3. Hibernate
- JPA의 구현체 중 하나
- SQL을 직접 사용하지 않는다고 해서 JDBC API를 사용하지 않는다는 것은 아님 (Hibernate가 지원하는 메서드 내부에서는 JDBC API가 동작)
- 매우 강력한 쿼리 언어(HQL, Hibernate Query Language)를 포함하고 있음
- HQL : 완전히 객체 지향적이며 상속, 다형성, 관계등의 객체지향의 강점을 누릴 수 있음
- HQL 쿼리는 자바 클래스와 프로퍼티의 이름을 제외하고는 대소문자를 구분
- 쿼리 결과로 객체를 반환
- 프로그래머에 의해 생성되고 직접적으로 접근할 수 있음
- SQL에서는 지원하지 않는 페이지네이션이나 동적 프로파일링과 같은 향상된 기능을 제공
- 여러 테이블 작업 시 명시적인 join을 요구하지 않음
2-3-1. Hibernate 장점
- 객체지향적으로 데이터를 관리할 수 있기 때문에 비즈니스 로직에 집중 할 수 있으며, 객체지향 개발이 가능
- 테이블 생성, 변경, 관리가 쉬움
- 로직을 쿼리에 집중하기 보다 객체 자체에 집중 할 수 있음
- 빠른 개발이 가능하다.
2-3-2. Hibernate 단점
- 많은 내용이 감싸져 있기 때문에 알아야 할 것이 많음
- 잘 이해하고 사용하지 않으면 데이터 손실 또는 성능상 문제가 발생할 수 있음

