Character Set
아스키 코드(ASCII)
- 아스키(ASCII, American Standard Code for Information Interchange, 미국 정보 교환 표준 부호)
- 영문 알파벳을 사용하는 대표적인 문자 인코딩
- 컴퓨터와 통신장비를 비롯한 문자를 사용하는 많은 장치에서 사용
- 1Byte로 표현, bit로는 10진수 0~255로 표시
EUC-KR(MS949)
- UNIX 상에서 영문자 이외의 문자를 지원하기 위해 제안한 확장 유니코드(Extend UNIX Code) 중 한글 인코딩 방식
- 영문은 KSC5636으로 처리, 한글은 KSC5601로 처리
- 한글을 표현하는 EUC_KR의 캐릭터 셋 :
KO16KSC5601, KO16MSWIN949
KSC5601
- 한글완성형 표준 (한글 2350자 표현)
- 한국공업표준 정보처리분야의 5601번 표준안
KSC5636
- 영문자에 대한 표준
- 한국공업표준 정보처리분야의 5606번 표준안
- 기존 ASCII Code에서 역슬래시를 원() 표시로 대체
KO16KSC5601
- 한글 완성형 코드와 일치하며 일반적으로 많이 사용되는 2350자의 한글, 4888자의 한자와 히라카나, 카타카나, 그리고 영문 및 각종 기호들을 포함
KO16MSWIN949
- Windows-949 Character Set
- MS사의 Windows Codepage 949번(한글 코드 페이지)을 따른 코드셋
- KO16KSC5601을 그대로 포함하고 있으며, 추가로 현대 한글 조합으로 표현할 수 있는 모든 8822자의 한글을 추가해 포함 (KO16KSC5601의 수퍼셋(SuperSet))
- 한글은 2byte
유니코드
- 유니코드의 캐릭터 셋 :
UTF-8, UTF-16, ISO-8859-1
UTF-8
UTF-16
- 자바 기본 문자 코드
- 영문과 숫자는 1byte, 한글은 2byte
ISO-8859-1
- 서유럽 언어 표기에 필요한 US-ASCII에 없는 94개의 글자의 순차적 나열
EBCDIC 코드
- BCD코드를 확장한 코드
- 확장 2진화 10진 코드라 부름
- 8비트로 256가지 문자를 표현
- 맨 앞의 1비트를 Parity Bit로 추가하여 9비트로 사용
- Parity Bit(1) + Zone Bits(4) + Digit Bits(4)로 구성
- 한글은 2byte
EBCDIC 코드의 한글 처리
- 한글 문자는 EBCDIC의 SO(0x0E)로 시작 SI(0x0F)로 종료됨
한글a한글의 경우, SO한글aSISO한글SI으로 13byte임
변환
전각문자와 반각문자
- 전각문자 :
!@#와 같이 shift+숫자가 아닌 123abc?!과 같은 형태로 윈도우 같은 경우 자음+한자로 생성되는 특수문자 기호
- 반각문자 : 흔히 쓰는 기호
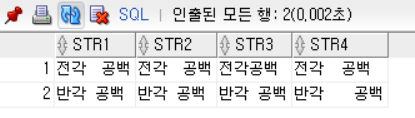
전각문자 공백 제거
- 공백 문자가 2bytes 전각문자로 되어있는 경우, Oracle의
TRIM() 함수로 제거되지 않음
REPLACE() : 전각문자 공백을 ''로 치환하여 제거TO_SINGLE_BYTE() : 2byte로 된 영문자, 숫자, 공백 등이 모두 1byte 문자로 치환됨
SELECT
'전각 공백' AS STR1
, TRIM('전각 공백') AS STR2
, REPLACE('전각 공백', ' ', '') AS STR3
, TO_SINGLE_BYTE('전각 공백') AS STR4
FROM DUAL
UNION ALL
SELECT
'반각 공백' AS STR1
, TRIM('반각 공백') AS STR2
, REPLACE('반각 공백', ' ', '') AS STR3
, TO_MULTI_BYTE('반각 공백') AS STR4
FROM DUAL;